[논문리뷰] Imagen Video: High Definition Video Generation with Diffusion Models
arXiv 2022. [Paper] [Page]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, Tim Salimans
Google Research, Brain Team
5 Oct 2022

Introduction
본 논문은 텍스트에서 동영상을 생성하는 것을 목표로 한다. 동영상 생성에 대한 이전 연구들은 제한된 데이터셋에서 학습된 autoregressive model, autoregressive prior을 사용하는 laten-varient model, 보다 최근에는 non-autoregressive latent-variable 접근 방식에 중점을 두었다. Diffusion model은 중간 해상도의 동영상 생성 가능성도 보여주었다.
본 논문에서는 높은 프레임 충실도, 강력한 시간적 일관성 및 깊은 언어 이해로 고화질 동영상을 생성할 수 있는 video diffusion model을 기반으로 하는 text-to-video 생성 시스템인 Imagen Video를 소개한다. Imagen Video는 초당 24프레임의 64프레임 128$\times$128 동영상을 생성하는 이전 연구에서 초당 24프레임의 128프레임 1280$\times$768 고화질 동영상을 생성하도록 확장된다. Imagen Video의 아키텍처는 간단하다. 고정된 T5 텍스트 인코더, 기본 video diffusion model, 인터리브된 공간 및 시간적 super-resolution (SR) diffusion model로 구성된다.
Imagen Video
Imagen Video는 video diffusion model의 계단식 모델이며, 텍스트 조건부 동영상 생성, 공간적 SR, 시간적 SR을 수행하는 7개의 하위 모델로 구성된다. 전체 계단식 모델에서 Imagen Video는 초당 24프레임으로 128프레임($\approx$ 5.3초)의 고화질 1280$\times$768 동영상(약 1억 2600만 픽셀)을 생성한다.
1. Diffusion Models
연속 시간에서의 diffusion model은 데이터 $x \sim p(x)$에서 시작하는 forward process $q(z \vert x)$를 따르는 latent $z = {z_t \vert t \in [0, 1]}$$를 갖는 생성 모델이다. Forward process는 Markovian 구조를 만족하는 Gaussian process이다.
\[\begin{equation} q(z_t \vert x) = \mathcal{N}(z_t; \alpha_t x, \sigma_t^2 I), \quad q(z_t \vert z_s) = \mathcal{N}(z_t; (\alpha_t / \alpha_s) z_s, \sigma_{t \vert s}^2 I) \\ \textrm{where} \; \quad 0 \le s < t \le 1, \quad \sigma_{t \vert s}^2 = (1 - e^{\lambda_t - \lambda_s}) \sigma_t^2, \quad \lambda_t = \log [\alpha_t^2 / \sigma_t^2] \end{equation}\]본 논문에서는 이산 시간 ancestral sampler를 사용하며, reverse process 엔트로피의 하한 및 상한에서 유도된 샘플링 분산을 사용한다. Forward process는 다음과 같이 역순으로 설명할 수 있다.
\[\begin{equation} q(z_s \vert z_t, x) = \mathcal{N} (z_s; \tilde{\mu}_{s \vert t} (z_t, x), \tilde{\sigma}_{s \vert t}^2 I) \\ \textrm{where} \quad \tilde{\mu}_{s \vert t} (z_t, x) = e^{\lambda_t - \lambda_s} (\alpha_s / \alpha_t) z_t + (1 - e^{\lambda_t - \lambda_s} \alpha_s) x \\ \textrm{and} \quad \tilde{\sigma}_{s \vert t}^2 = (1 - e^{\lambda_t - \lambda_s}) \sigma_s^2 \end{equation}\]$z_1 \sim \mathcal{N}(0, 1)$에서 시작하여 ancestral sampler는 다음 규칙을 따른다.
\[\begin{equation} z_s = \tilde{\mu}_{s \vert t} (z_t, \hat{x}_\theta (z_t)) + \sqrt{(\tilde{\sigma}_{s \vert t}^2)^{1 - \gamma}(\tilde{\sigma}_{t \vert s}^2)^\gamma} \epsilon \end{equation}\]$\gamma$는 sampler의 stochasity를 조절하는 hyperparameter이다. $\epsilon$은 Gaussian noise이다.
또는 deterministic DDIM sampler를 샘플링에 사용할 수 있다. 이 sampler는 probability flow ODE에 대한 수치 적분 규칙으로, denoising model을 사용하여 표준 정규 분포의 샘플을 동영상 데이터 분포의 샘플로 deterministic하게 변환할 수 있는 방법을 설명한다. DDIM sampler는 빠른 샘플링을 위한 progressive distillation에 유용하다.
2. Cascaded Diffusion Models and Text Conditioning
Cascaded Diffusion Model은 diffusion model을 고해상도 출력으로 확장하는 효과적인 방법으로 클래스 조건부 ImageNet과 text-to-image 생성에서 성공을 거두었다. Cascaded diffusion model은 저해상도로 이미지나 동영상을 생성한 후 일련의 SR diffusion model을 통해 이미지나 동영상의 해상도를 순차적으로 높인다. Cascaded diffusion model은 각 하위 모델을 상대적으로 단순하게 유지하면서 매우 높은 차원의 문제를 모델링할 수 있다. Imagen은 고정된 대규모 언어 모델의 텍스트 임베딩로 컨디셔닝하여 텍스트 설명에서 고품질 1024$\times$1024 이미지를 생성할 수 있음을 보여주었다. 본 논문에서는 이 접근 방식을 동영상 생성으로 확장한다.
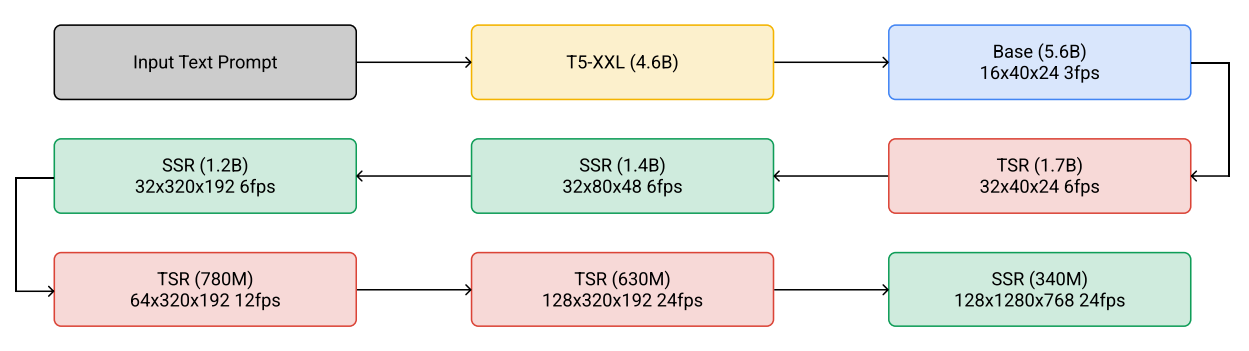
위 그림은 Imagen Video의 전체 계단식 파이프라인을 요약한 것이다. Imagen Video는 1개의 고정된 텍스트 인코더, 1개의 기본 video diffusion model, 3개의 SSR(spatial SR), 3개의 TSR(temporal SR) 모델로 구성되며, 총 116억 개의 diffusion model 파라미터가 사용된다. 이러한 모델을 학습하는 데 사용되는 데이터는 spatial resizing과 frame skipping을 통해 적절한 공간 및 시간 해상도로 처리된다. 생성 시 SSR 모델은 모든 입력 프레임의 공간 해상도를 높이는 반면 TSR 모델은 입력 프레임 사이의 중간 프레임을 채워 시간 해상도를 높인다. 모든 모델은 동시에 전체 프레임 블록을 생성한다. 예를 들어 SSR 모델은 독립 프레임에서 SR을 수행할 때 발생하는 아티팩트를 겪지 않는다.
계단식 모델의 한 가지 이점은 각 diffusion model을 독립적으로 학습할 수 있어 7개 모델 모두를 병렬로 학습할 수 있다는 것이다. 또한, SR 모델은 범용 동영상 SR 모델이며, 본 논문에서 제시한 것 이외의 생성 모델에서 실제 동영상이나 샘플에 적용할 수 있다.
Imagen과 유사하게, 입력 텍스트 프롬프트로 컨디셔닝하기 위해 고정된 T5-XXL 텍스트 인코더의 컨텍스트 임베딩을 활용한다. 이러한 임베딩은 생성된 동영상과 텍스트 프롬프트 간의 일치에 매우 중요하다.
3. Video Diffusion Architectures
이미지 생성을 위한 diffusion model은 일반적으로 denoising model \(\hat{x}_\theta\)를 나타내기 위해 2D U-Net 아키텍처를 사용한다. 이는 각 해상도에서 여러 layer의 spatial attention과 spatial convolution으로 구성된 멀티스케일 모델이며, 동일한 해상도에서 레이어 간 shortcut과 결합된다. Video diffusion model은 동영상 프레임 사이의 종속성을 캡처하기 위해 spatial attention과 spatial convolution layer 사이에 temporal attention과 temporal convolution layer를 사용하여 2D diffusion model 아키텍처를 시공간 분리가 가능한 방식으로 3D로 일반화하는 동영상 U-Net을 도입했다.

본 논문은 동영상 U-Net 아키텍처를 기반으로 한다. Video diffusion model에 따라 각 denoising model \(\hat{x}_\theta\)는 여러 동영상 프레임에서 동시에 작동하므로 한 번에 동영상 프레임의 전체 블록을 생성하며, 프레임 autoregressive 접근법과 비교하여 생성된 동영상의 시간적 일관성을 캡처한다. SSR과 TSR 모델은 SR3와 Palette와 동일하게 noisy한 데이터 $z_t$에 upsampling된 컨디셔닝 입력을 채널 축으로 연결하여 입력 동영상을 컨디셔닝한다. Concatenation 전 공간적 upsampling은 bilinear resizing을 사용하여 수행되고, concatenation 전 시간적 upsampling은 프레임을 반복하거나 빈 프레임을 채워서 수행된다.
가장 낮은 프레임 수와 공간 해상도로 데이터를 생성하는 파이프라인의 첫 번째 모델인 base video model은 temporal attention을 사용하여 시간에 따라 정보를 혼합한다. 반면에 SSR과 TSR 모델은 temporal attention 대신 temporal convolution을 사용한다. Imagen Video는 base model의 temporal attention을 통해 장기적인 시간 종속성을 모델링할 수 있으며, SSR과 TSR 모델의 temporal convolution을 통해 upsampling 중에 로컬한 시간 일관성을 유지할 수 있다. TSR과 SSR 모델의 목적이 높은 프레임 속도와 공간 해상도에서 작동하는 것이기 때문에 temporal convolution을 사용하면 temporal attention에 비해 메모리와 계산 비용이 절감된다.
초기 실험에서 저자들은 SSR과 TSR 모델에서 temporal convolution 대신 temporal attention을 사용할 때 상당한 개선을 찾지 못했다. 저자들은 모델에 대한 컨디셔닝 입력에 이미 상당한 양의 시간적 상관 관계가 존재하기 때문이라고 가정하였다.
본 논문의 모델은 또한 spatial attention과 spatial convolution을 사용한다. Base model과 처음 두 개의 SSR 모델에는 spatial convolution 외에도 spatial attention이 있다. 이것이 샘플 충실도를 향상시키는 것으로 나타났다. 그러나 더 높은 해상도로 이동함에 따라 fully convolutional 아키텍처로 전환하여 1280$\times$768 해상도 데이터를 생성하기 위해 메모리 및 컴퓨팅 비용을 최소화한다. 파이프라인에서 가장 높은 해상도의 SSR 모델은 학습 시 메모리 효율성을 위해 임의의 저해상도 spatial crop에 대해 학습된 fully convolutional model이며, 저자들은 샘플링 시 모델이 전체 해상도로 쉽게 일반화됨을 발견했다.
4. $v$-prediction
Progressive distillation 논문을 따라 $v$-prediction parameterization
\[\begin{equation} v_t := \alpha_t \epsilon - \sigma_t x \end{equation}\]를 사용한다. $v$-parameterization은 diffusion process 전반에 걸쳐 수치적 안정성에 특히 유용하여 모델의 progressive distillation을 가능하게 한다. 파이프라인에서 높은 해상도로 작동하는 모델의 경우 $v$-parameterization가 고해상도 diffusion model에서 발생하는 color shifting 아티팩트를 피하고 동영상 생성 시 $\epsilon$-prediction을 사용할 때 나타나는 일시적인 color shifting을 피한다. $v$-parameterization를 사용하면 샘플 품질 지표를 더 빠르게 수렴할 수 있다는 이점도 있다.
5. Conditioning Augmentation
모든 TSR과 SSR 모델에 noise conditioning augmentation을 사용한다. Noise conditioning augmentation는 클래스 조건부 생성과 text-to-image 모델을 위한 cascaded diffusion model에 중요하다. 특히, 계단식 모델에서 한 단계의 출력과 다음 단계 학습에 사용되는 입력 사이의 도메인 차이에 대한 민감도를 줄임으로써 계단식 모델에서 서로 다른 모델의 병렬 학습을 용이하게 한다.
Cascaded diffusion model을 따라 학습 중 컨디셔닝 입력 동영상에 임의의 신호 대 잡음비(SNR)로 Gaussian noise augmentation을 적용하고 이 샘플링된 SNR을 모델에도 제공한다. 샘플링 시 3 또는 5와 같은 고정된 SNR을 사용하여 대부분의 구조를 보존하면서 이전 단계에서 샘플의 아티팩트를 제거하는 데 도움이 되는 소량의 augmentation을 나타낸다.
6. Video-Image Joint Training
Imagen Video 파이프라인의 모든 모델을 공동으로 학습하는 video diffusion model을 따른다. 학습하는 동안 개별 이미지는 단일 프레임 동영상으로 처리된다. 개별 독립 이미지를 동영상과 동일한 길이의 시퀀스로 패킹하고 계산 경로를 마스킹하여 temporal convolution residual block을 우회한다. 유사하게 temporal attention map에 마스킹을 적용하여 cross-frame temporal attention을 비활성화한다. 이 전략을 사용하면 사용 가능한 동영상 텍스트 데이터셋보다 훨씬 더 크고 다양한 이미지-텍스트 데이터셋에서 동영상 모델을 학습하는 데 사용할 수 있다.
저자들은 video diffusion model과 일관되게 이미지와의 공동 학습이 동영상 샘플의 전반적인 품질을 크게 향상시키는 것을 관찰했다. 공동 학습의 또 다른 흥미로운 결과물은 이미지에서 동영상으로의 지식 전달이다. 예를 들어, 자연 동영상 데이터에 대한 학습을 통해 모델은 자연 환경에서 역학을 학습할 수 있지만 모델은 이미지 학습을 통해 다양한 이미지 스타일에 대해 학습할 수 있다. 결과적으로 이 공동 학습을 통해 모델은 다양한 스타일로 흥미로운 동영상 역학을 생성할 수 있다.
Classifier Free Guidance
저자들은 classifier free guidance가 주어진 텍스트 프롬프트를 존중하는 고충실도 샘플을 생성하는 데 중요하다는 것을 발견했다. 이는 text-to-image model에 대한 이전 결과와 일치한다.
조건부 생성 모델에서 데이터 $x$는 신호 $c$에 조건부로 생성되며, $c$는 텍스트 프롬프트의 맥락화된 임베딩을 나타내며 조건부 diffusion model은 $c$를 denoising model \(\hat{x}_\theta (z_t, c)\)에 대한 추가 입력으로 사용하여 학습시킬 수 있다. 학습 후 다음 식을 사용하여 denoising \(\hat{x}_\theta (z_t, c)\)를 조정하여 샘플 품질을 개선할 수 있다.
\[\begin{equation} \tilde{x}_\theta (z_t, c) = (1 + w) \hat{x}_\theta (z_t, c) - w \hat{x}_\theta (z_t) \end{equation}\]여기서 $w$는 guidance 강도이다. \(\hat{x}_\theta (z_t, c)\)는 conditional model이고 \(\hat{x}_\theta (z_t) = \hat{x}_\theta (z_t, c = \emptyset)\)은 unconditional model이다. Unconditional model은 $c$를 제거하여 conditional model과 공동으로 학습된다. \(\tilde{x}_\theta (z_t, c)\)는 가능한 픽셀값 범위로 클리핑된다. 위 식에 선형 변환을 하여 $v$-space와 $\epsilon$-space에서 동등하게 수행할 수 있다.
\[\begin{equation} \tilde{v}_\theta (z_t, c) = (1 + w) \hat{v}_\theta (z_t, c) - w \hat{v}_\theta (z_t) \\ \tilde{\epsilon}_\theta (z_t, c) = (1 + w) \hat{\epsilon}_\theta (z_t, c) - w \hat{\epsilon}_\theta (z_t) \end{equation}\]$w > 0$의 경우 이 조정은 $c$에 대한 컨디셔닝 효과를 과도하게 강조하는 효과가 있으며, 일반 조건부 모델의 샘플링에 비해 다양성은 낮지만 품질은 더 높은 샘플을 생성하는 경향이 있다.
Large Guidance Weights
큰 guidance 가중치를 사용할 때 \(\tilde{x}_\theta (z_t, c)\)는 train-test 불일치를 방지하기 위해 모든 샘플링 step에서 픽셀 값의 가능한 범위로 다시 project되어야 한다. 큰 guidance 가중치를 사용하는 경우 값을 올바른 범위로 클리핑하면 생성된 동영상에서 상당한 채도 아티팩트가 발생한다. Imagen은 dynamic thresholding을 사용하여 이 채도 문제를 완화한다. 특히 동적 클리핑은 동적으로 선택한 임계값 $s$로 이미지를 클리핑한 다음 $s$로 스케일링하는 연산을 포함한다.
동적 클리핑이 채도에 도움이 될 수 있지만 초기 실험에서는 충분하지 않았다고 한다. 따라서 저자들은 높은 guidance 가중치와 낮은 guidance 가중치 사이를 진동하도록 실험하여 이러한 채도 문제에 상당한 도움이 된다는 것을 발견했다. 이 샘플링 기술을 oscillating guidance라고 한다. 구체적으로, 초기 샘플링 step의 특정 수에 대해 일정한 높은 guidance 가중치를 사용하고 이어서 높은 guidance 가중치와 낮은 guidance 가중치 사이를 진동한다. 이 진동은 샘플링 과정에서 큰 가중치(ex. 15)와 작은 가중치(ex. 1)를 반복하여 간단하게 구현할 수 있다. 저자들은 샘플링 시작 시 일정한 높은 guidance 가중치가 텍스트를 강조하는 모드를 중단하는 데 도움이 되며, 높은 guidance 가중치와 낮은 guidance 가중치 사이를 진동하면 높은 guidance 가중치가 강력한 텍스트 일치를 유지하는 동시에 낮은 guidance 가중치 채도 아티팩트를 제한하는 데 도움이 된다고 가정하였다. 그러나 80$\times$48 공간 해상도를 초과하는 모델에 oscillating guidance를 적용할 때 샘플 충실도가 개선되지 않고 더 많은 시각적 아티팩트가 관찰되었다. 따라서 base model과 처음 두 개의 SR model에만 oscillating guidance를 적용한다.
7. Progressive Distillation with Guidance and Stochastic Samplers
Progressive distillation은 diffusion model의 빠른 샘플링을 가능하게 한다. 이 방법은 학습된 deterministic DDIM sampler가 지각 품질을 크게 잃지 않고 샘플링 step이 훨씬 적은 diffusion model로 distill한다. Distillation이 반복될 때마다 $N$ step DDIM sampler가 $N/2$ step의 새 모델로 distill된다. 이 절차는 반복할 때마다 필요한 샘플링 step을 반으로 나누어 이 절차를 반복한다.
On distillation of guided diffusion models 논문은 guidance를 통해 이 접근 방식을 sampler로 확장하고 distillation model과 함께 사용할 새로운 stochastic sampler를 제안하였다. 저자들은 이 접근 방식이 동영상 생성에도 매우 잘 작동함을 보여준다. 2단계 distillation 접근 방식을 사용하여 classifier free guidance로 DDIM sampler를 distill한다.
첫 번째 stage에서는 결합 계수가 guidance 가중치에 의해 결정되는 단일 differential model을 학습하며, 공동으로 학습된 conditional 및 unconditional diffusion model의 결합된 출력과 일치시킨다. 그런 다음 해당 단일 모델에 progressive distillation을 적용하여 두 번째 stage에서 더 적은 샘플링 step이 필요한 모델을 생성한다. Distillation 후 stochastic $N$-step sampler를 사용한다. 각 step에서 먼저 원래 step 크기의 두 배 (즉, $N/2$ step sampler와 동일한 step 크기)로 하나의 deterministic DDIM 업데이트를 적용한 다음 수행한다. 이 접근 방식을 사용하여 지각 품질의 눈에 띄는 손실 없이 모델당 단 8개의 샘플링 단계로 7개의 모든 video diffusion model을 distill할 수 있다.
Experiments
1. Unique Video Generation Capabilities
다음은 Image Video의 다양한 예술적 스타일로 역동성을 생성하는 능력을 보여주는 프레임 스냅샷이다.

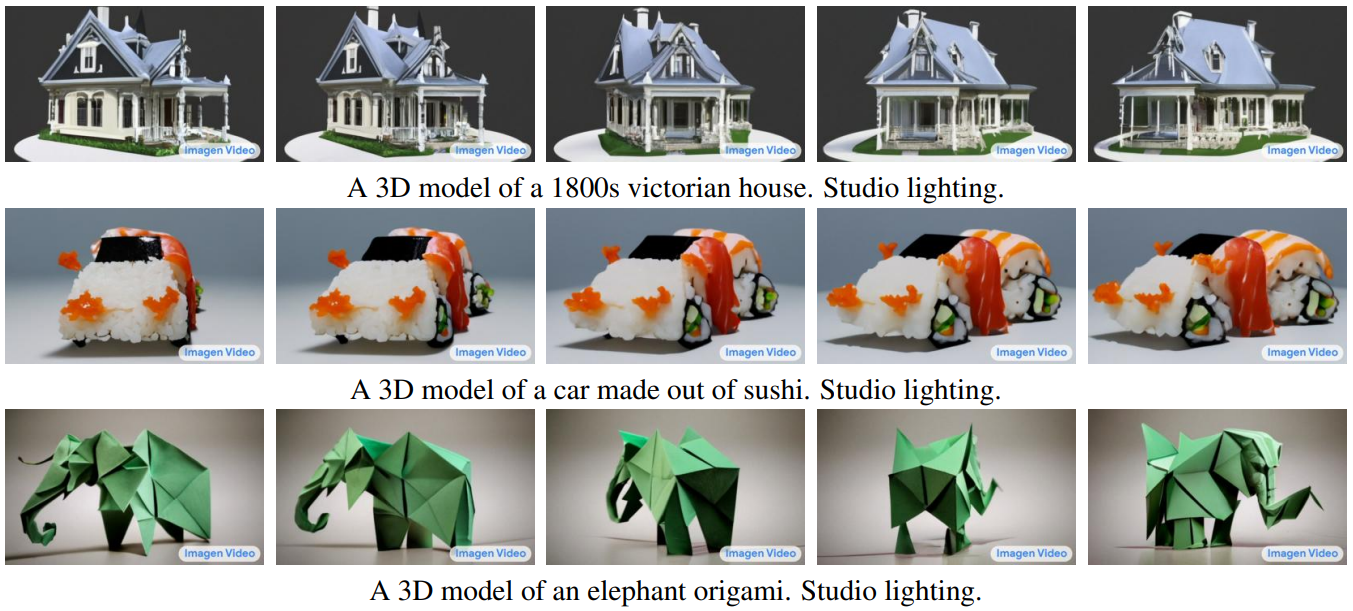
다음은 Image Video의 3D 구조에 대한 이해를 보여주는 프레임 스냅샷이다.
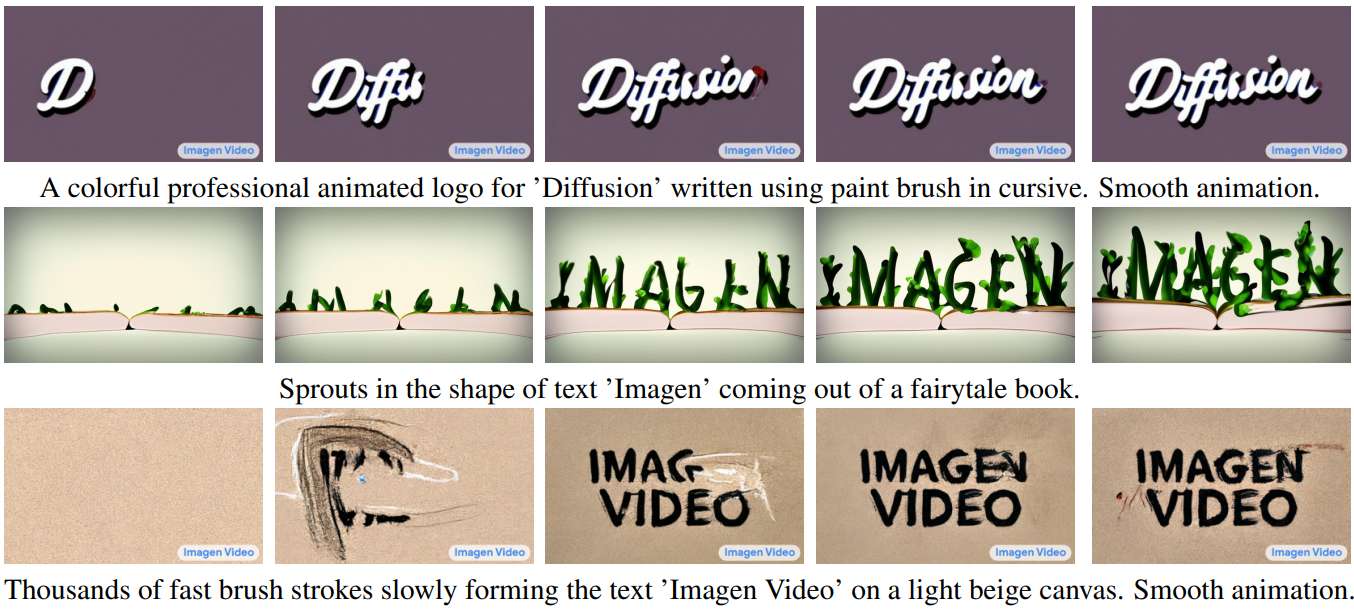
다음은 Image Video의 다양한 스타일과 역학으로 다양한 텍스트를 렌더링하는 능력을 보여주는 프레임 스냅샷이다.
2. Scaling
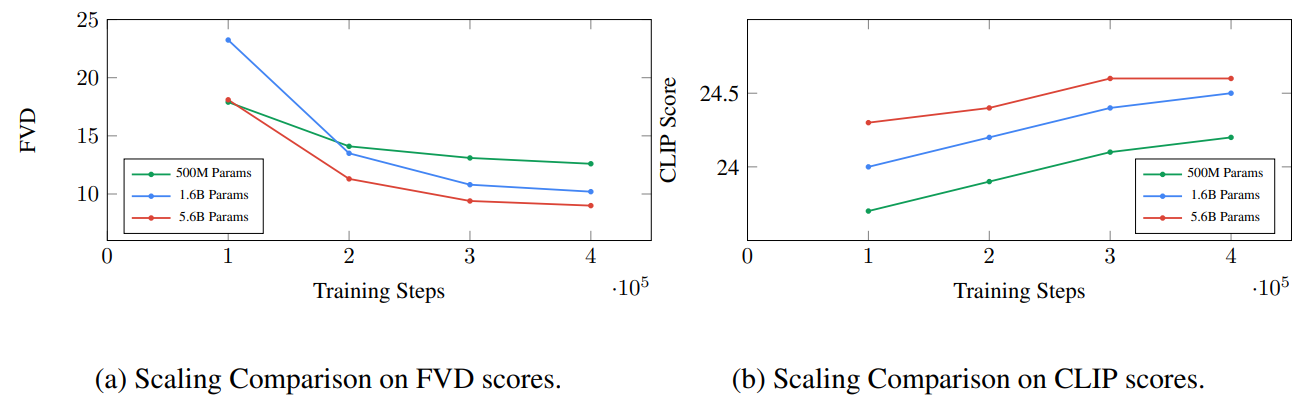
위 그래프는 base video model이 동영상 U-Net의 파라미터수 수를 확장함으로써 많은 이점을 얻을 수 있음을 보여준다. 이미지-텍스트 샘플 품질 점수로 측정할 때 diffusion model 스케일링의 이점이 제한적임을 확인할 수 있다. 저자들은 동영상 모델링이 현재 모델 크기에서 성능이 아직 포화되지 않은 더 어려운 task라는 결론을 내렸다.
3. Comparing Prediction Parameterizations
다음은 80$\times$48 $\rightarrow$ 320$\times$192 동영상 SSR task에서 $\epsilon$-prediction과 $v$-prediction 간의 비교를 보여준다.

$\epsilon$-parameterization이 $v$-parameterization보다 더 나쁜 생성을 생성한다는 것이 분명하다.
다음은 학습 step에 따라 두 parameterization 사이의 정량적 비교를 보여주는 그래프이다.
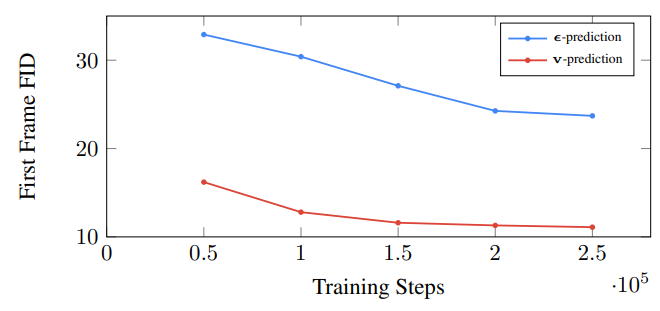
$v$-parameterization이 $\epsilon$-parameterization보다 훨씬 더 빠르게 수렴하는 것을 확인할 수 있다.
4. Perceptual Quality and Distillation
다음은 본 논문의 모델과 distillation 버전의 샘플에 대한 지각 품질 지표(CLIP score와 CLIP R-Precision)를 나타낸 표이다.
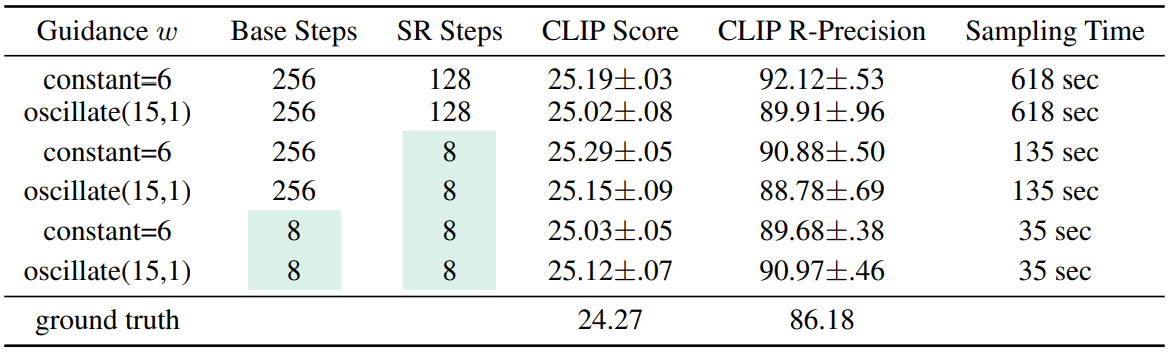
저자들은 distillation이 샘플링 시간과 지각 품질 사이에서 매우 유리한 균형을 제공한다는 것을 발견했다. Distill된 계단식 모델은 원래 모델의 샘플과 비슷한 품질의 동영상을 생성하면서 약 18배 더 빠르다. FLOP의 관점에서 distillation model은 약 36배 더 효율적이다. 원래 계단식 모델은 각 모델을 두 번 병렬로 평가하여 classifier free guidance를 적용하는 반면, distillation model은 guidance 효과를 하나로 distill했기 때문에 그렇지 않다.
아래 그림은 원본 모델(왼쪽)과 distillation 모델(오른쪽)의 샘플이다.

Videos Generated from Various Text Prompts