[논문리뷰] Diffusion Models Are Real-Time Game Engines
ICLR 2025. [Paper] [Page]
Dani Valevski, Yaniv Leviathan, Moab Arar, Shlomi Fruchter
Google Research | Tel Aviv University
27 Aug 2024
Introduction
본 논문에서는 실시간으로 실행되는 신경망 모델이 복잡한 게임을 고품질로 시뮬레이션할 수 있음을 보여준다. 구체적으로, 복잡한 비디오 게임인 DOOM이 신경망에서 실시간으로 실행될 수 있으며, 동시에 원래 게임과 비슷한 시각적 품질을 달성할 수 있음을 보여준다. 정확한 시뮬레이션은 아니지만, 모델은 체력과 탄약 계산, 적 공격, 물체 손상, 문 열기 등 복잡한 게임 상태 업데이트를 수행할 수 있다.
GameNGen은 최근 몇 년 동안 신경망 모델이 이미지와 동영상을 생성하는 방식과 유사하게, 게임을 자동으로 생성하는 패러다임이다. 그러나 이러한 신경망 기반 게임 엔진을 어떻게 학습시킬 것인지, 게임을 효과적으로 생성하는 방법은 무엇인지, 그리고 인간의 입력을 어떻게 최적화하여 활용할 것인지와 같은 중요한 질문들이 여전히 남아 있다.

Interactive World Simulation
Interactive environment $\mathcal{E}$는 latent state space $\mathcal{S}$, latent space의 partial projection space $\mathcal{O}$, partial projection function $V : \mathcal{S} \rightarrow \mathcal{O}$, 일련의 action $\mathcal{A}$, transition probability function $p(s \vert a, s^\prime)$으로 구성된다 ($s, s^\prime \in \mathcal{S}, a \in \mathcal{A}$).
예를 들어, 게임 DOOM의 경우 $\mathcal{S}$는 프로그램의 동적 메모리 내용, $\mathcal{O}$는 렌더링된 화면 픽셀, $V$는 게임의 렌더링 로직, $\mathcal{A}$는 키 입력과 마우스 움직임의 집합, $p$는 플레이어의 입력을 고려한 프로그램의 로직이다.
Interactive environment $\mathcal{E}$와 초기 state $s_0 \in \mathcal{S}$가 주어지면, Interactive World Simulation은 시뮬레이션 분포 함수
\[\begin{equation} q (o_n \vert o_{< n}, a_{\le n}), \quad o_i \in \mathcal{O}, \; a_i \in \mathcal{A} \end{equation}\]이다. Observation 사이의 거리 메트릭 $D : \mathcal{O} \times \mathcal{O} \rightarrow \mathbb{R}$, policy $\pi (a_n \vert o_{< n}, a_{\le n})$, 초기 state에 대한 분포 $S_0$, 에피소드 길이에 대한 분포 $N_0$가 주어지면, interactive world simulation의 목적 함수는
\[\begin{equation} E (D (o_q^i, o_p^i)), \quad n \sim N_0, \; 0 \le i \le n, \; o_q^i \sim q, \; o_p^i \sim V(p) \end{equation}\]를 최소화하는 것이다. $o_i^q$는 environment에서 샘플링된 observation이고, $o_i^p$는 에이전트의 policy $\pi$를 시행할 때 시뮬레이션에서 얻은 observation이다. 중요한 점은, 이러한 샘플에 대한 action은 항상 environment $\mathcal{E}$와 상호 작용하는 에이전트에 의해 얻어지는 반면, observation은 $\mathcal{E}$ (teacher forcing objective) 또는 시뮬레이션 (autoregressive objective)에서 얻을 수 있다는 것이다.
본 논문에서는 항상 teacher forcing objective으로 생성 모델을 학습시킨다. 시뮬레이션 분포 함수 $q$가 주어지면 environment $\mathcal{E}$는 autoregressive하게 observation을 샘플링하여 시뮬레이션할 수 있다.
Method
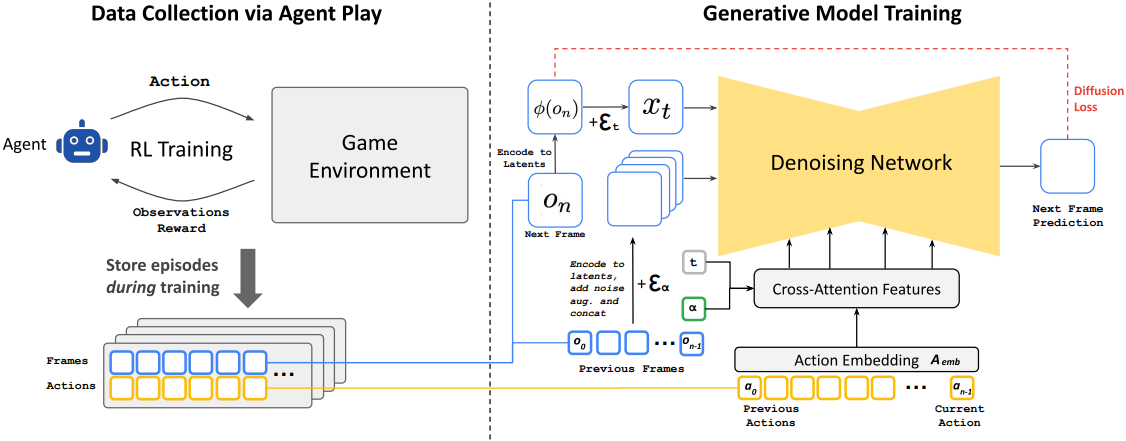
GameNGen은 위의 설정에서 게임을 시뮬레이션하는 방법을 학습하는 diffusion model이다. Teacher forcing objective를 사용하여 이 모델에 대한 학습 데이터를 수집하기 위해, 먼저 environment와 상호 작용하도록 별도의 모델(에이전트)을 학습시킨다. 에이전트와 생성 모델은 순서대로 학습된다. 학습 중에 에이전트의 모든 action 및 observation \(\mathcal{T}_\textrm{agent}\)는 유지되고, 두 번째 단계에서 생성 모델의 학습 데이터셋이 된다.
1. Data Collection via Agent Play
저자들의 최종 목표는 인간 플레이어가 시뮬레이션과 상호 작용하는 것이며, 이를 위한 policy $\pi$는 인간 게임 플레이의 policy이다. 이를 직접 샘플링할 수 없으므로 자동 에이전트에게 플레이하도록 가르쳐서 근사화한다. 게임 점수를 최대화하려는 일반적인 RL과 달리, 인간 플레이와 유사한 학습 데이터를 생성하거나 적어도 다양한 시나리오에서 충분한 다양한 예를 포함하여 학습 데이터 효율성을 최대화하는 것이 목표이다. 이를 위해, 저자들은 간단한 reward function을 설계하였으며, GameNGen에서 environment에 따라 달라지는 유일한 부분이다.
전체 학습 프로세스에 걸쳐 에이전트의 학습 궤적을 기록하며, 다양한 플레이 기술 수준을 포함한다. 이 기록된 궤적들은 생성 모델을 학습시키는 데 사용되는 데이터셋 \(\mathcal{T}_\textrm{agent}\)가 된다.
2. Training the Generative Diffusion Model
저자들은 사전 학습된 text-to-image diffusion model인 Stable Diffusion v1.4를 재활용하였다. 모델 $f_\theta$를 궤적 \(\mathcal{T} \sim \mathcal{T}_\textrm{agent}\), 즉 이전 action $a_{< n}$과 observation $o_{< n}$의 시퀀스에 대해 컨디셔닝하고 모든 텍스트 컨디셔닝을 제거한다. 구체적으로, action을 컨디셔닝하기 위해 각 action에서 임베딩 \(\mathcal{A}_\textrm{emb}\)를 하나의 토큰으로 학습하고 텍스트의 cross-attention을 이 인코딩된 action 시퀀스로 바꾼다. Observation을 컨디셔닝하기 위해 오토인코더 $\phi$를 사용하여 latent space에 인코딩하고, 채널 차원으로 noise가 더해진 latent 데이터에 concat한다.
Velocity parameterization을 통해 diffusion loss를 최소화하도록 모델을 학습시킨다.
\[\begin{equation} \mathcal{L} = \mathbb{E}_{t, \epsilon, T} [\| v(\epsilon, x_0, t) - v_{\theta^\prime} (x_t, t, \{\phi (o_{i<n})\}, \{\mathcal{A}_\textrm{emb} (a_{i<n})\}) \|_2^2] \\ \textrm{where} \quad T = \{o_{i \le n}, a_{i \le n}\} \sim \mathcal{T}_\textrm{agent}, \; x_0 = \phi (o_n), \; t \sim \mathcal{U}(0,1), \; \epsilon \sim \mathcal{N}(0,I), \\ x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \; v(\epsilon, x_0, t) = \sqrt{\vphantom{1} \bar{\alpha}_t} \epsilon - \sqrt{1 - \bar{\alpha}_t} x_0 \end{equation}\]Mitigating Auto-Regressive Drift Using Noise Augmentation

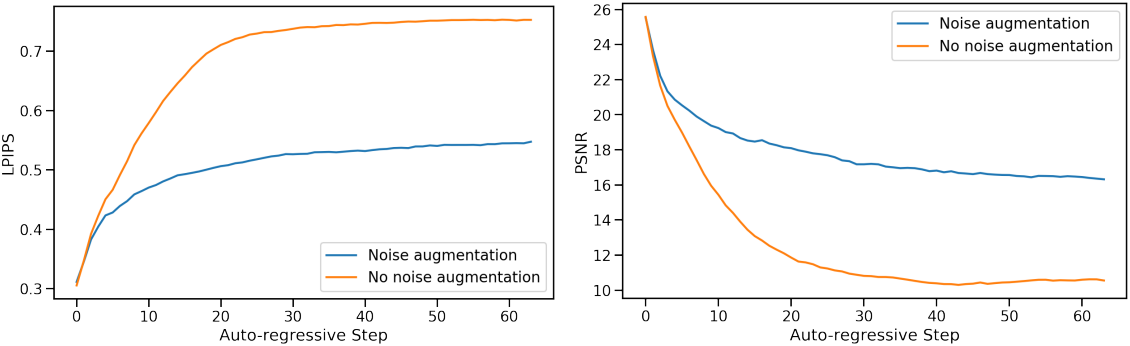
위 그림에서 볼 수 있듯이, teacher forcing과 autoregressive 샘플링을 사용한 학습 간의 domain shift는 오차가 축적되고 샘플 품질이 빠르게 저하된다. 이를 피하기 위해, cascaded diffusion model을 따라 학습 시에 인코딩된 프레임에 다양한 양의 Gaussian noise를 추가하여 컨텍스트 프레임을 손상시키고 noise level을 모델에 입력으로 제공한다. 이를 위해 noise level $\alpha$를 균일하게 샘플링하고 이를 discretize한 다음 각 버킷에 대한 임베딩을 학습시킨다. 이를 통해 네트워크는 이전 프레임에서 샘플링된 정보를 수정할 수 있으며, 시간이 지남에 따라 프레임 품질을 유지하는 데 중요하다. Inference 중에 추가된 noise level을 제어하여 품질을 극대화할 수 있지만 noise를 추가하지 않아도 결과가 상당히 개선된다.
Latent Decoder Fine-tuning
8$\times$8 픽셀 패치를 4개의 latent 채널로 압축하는 Stable Diffusion v1.4의 사전 학습된 오토인코더는 게임 프레임을 예측할 때 아티팩트를 생성하여 작은 디테일, 특히 하단 막대 HUD에 영향을 미친다. 사전 학습된 지식을 활용하면서 이미지 품질을 개선하기 위해, 대상 프레임 픽셀에 대해 계산된 MSE loss를 사용하여 오토인코더의 디코더만 학습시킨다. 중요한 점은 이 fine-tuning 프로세스가 U-Net fine-tuning과 완전히 별도이며, 특히 autoregressive 생성은 영향을 받지 않는다는 것이다.
3. Inference
4 step의 DDIM 샘플링을 사용하였다. 과거 observation에 대한 조건 $o_{< n}$에만 classifier-free guidance를 적용하였으며, 가중치가 클수록 autoregressive 샘플링으로 인해 아티팩트가 증가하기 때문에 상대적으로 작은 가중치인 1.5를 사용하였다. 과거 action에 대한 classifier-free guidance는 품질 향상에 별 도움이 되지 않았다고 한다.
또한 저자들은 극단적인 예측이 수용되는 것을 방지하고 오차 누적을 줄이기 위해 4개의 샘플을 병렬로 생성하고 결과를 결합하는 실험을 했다. 샘플의 평균을 사용하는 것은 하나의 프레임을 샘플링하는 것보다 성능이 약간 더 나빴고, 중간값에 가장 가까운 샘플을 선택하는 것은 미미하게 더 나은 성능을 보였다. 둘 다 하드웨어 요구 사항을 4배로 늘리기 때문에 저자들은 이를 사용하지 않기로 했다.
오토인코더와 denoising step 모두 TPU-v5에서 10ms가 소요되기 때문에, 한 프레임 생성에 총 50ms가 소요된다 (20 FPS).
Experiments
- 에이전트 학습
- PPO
- replay buffer 크기: 512
- discount factor: $\gamma$ = 0.99
- entropy coefficient: 0.1
- 아키텍처
- feature network: CNN (160$\times$120 $\rightarrow$ 512차원 벡터)
- actor, critic: 각각 2-layer MLP head
- batch size: 64
- epoch: 10
- learning rate: $1 \times 10^{-4}$
- 총 1,000만 environment step
- PPO
- Diffusion model 학습
- 이미지 해상도: 320$\times$256
- 컨텍스트 길이: 64 (과거 예측과 action을 각각 64개씩 조건으로 사용)
- batch size
- U-Net 학습: 128
- 디코더 fine-tuning: 2,048
- optimizer: Adafactor (weight decay X, gradient clipping = 1.0)
- learning rate: $2 \times 10^{-5}$
- training step: 70만
- classifier-free guidance 확률: 0.1
- noise augmentation: 최대 noise level = 0.7, 임베딩 버킷 10개
- GPU: TPU-v5e 128개
1. Simulation Quality
- PSNR: 29.43
- LPIPS: 0.249
- FVD: 114.02 (16 프레임), 186.23 (32 프레임)
- 인간 평가 (vs. 실제 게임): 42% (16 프레임), 40% (32 프레임)
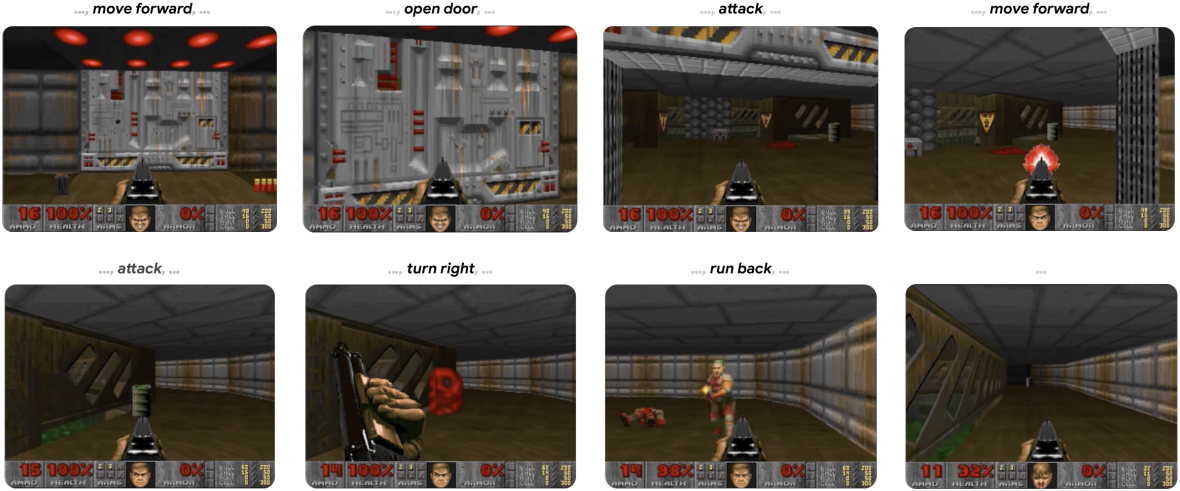
다음은 모델 예측과 GT를 비교한 것이다.

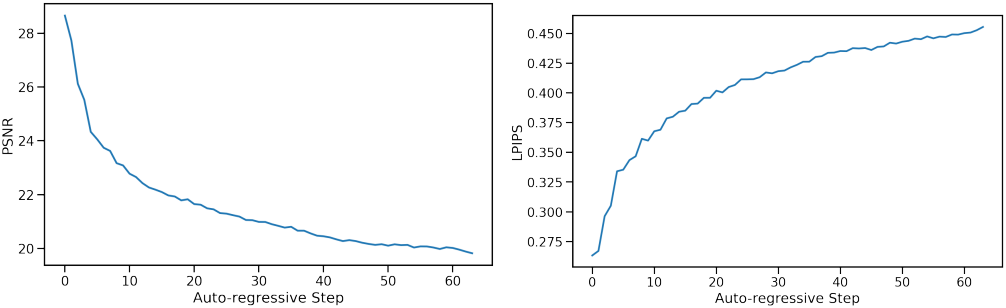
다음은 프레임별 PSNR과 LPIPS를 비교한 그래프이다.
2. Ablations
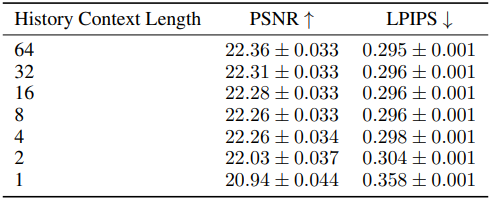
다음은 컨텍스트 길이에 대한 ablation 결과이다.
다음은 noise augmentation에 대한 ablation 결과이다.
다음은 에이전트의 policy가 생성한 데이터셋과 랜덤 policy가 생성한 데이터셋을 난이도에 따라 비교한 결과이다.