[논문리뷰] Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
ICLR 2025 (Spotlight). [Paper] [Github] [HuggingFace]
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, Guilin Liu
NVIDIA | Georgia Tech | UMD | HKPU
28 Aug 2024
Introduction
최근 연구에 따르면 더 강력한 비전 인코더 설계가 LMM hallucination을 완화하고 OCR과 같은 해상도에 민감한 task를 개선하는 데 중요하다. 따라서 여러 연구들이 비전 인코더의 능력을 향상시키는 데 중점을 두었다. 예를 들어, 비전 인코더의 사전 학습 데이터와 파라미터를 확장하거나 이미지를 저해상도 패치로 나눈다. 그러나 이러한 접근 방식은 일반적으로 대규모 학습 리소스를 도입한다.
효율적이면서도 강력한 전략은 서로 다른 task와 입력 해상도로 사전 학습된 비전 인코더를 혼합하는 것이다. 여러 연구에서 이러한 “mixture-of-vision-encoder”는 효과적인 것으로 나타났다. 그러나 엄격한 ablation을 통한 design space에 대한 자세한 연구는 아직 부족하며, 저자들은 이 영역을 다시 살펴보고자 하였다. 어떤 비전 인코더 조합을 선택해야 하는지, 다양한 expert들을 어떻게 융합해야 하는지, 더 많은 비전 인코더에 따라 학습 전략을 어떻게 조정해야 하는지와 같은 질문은 아직 답이 나오지 않았다.
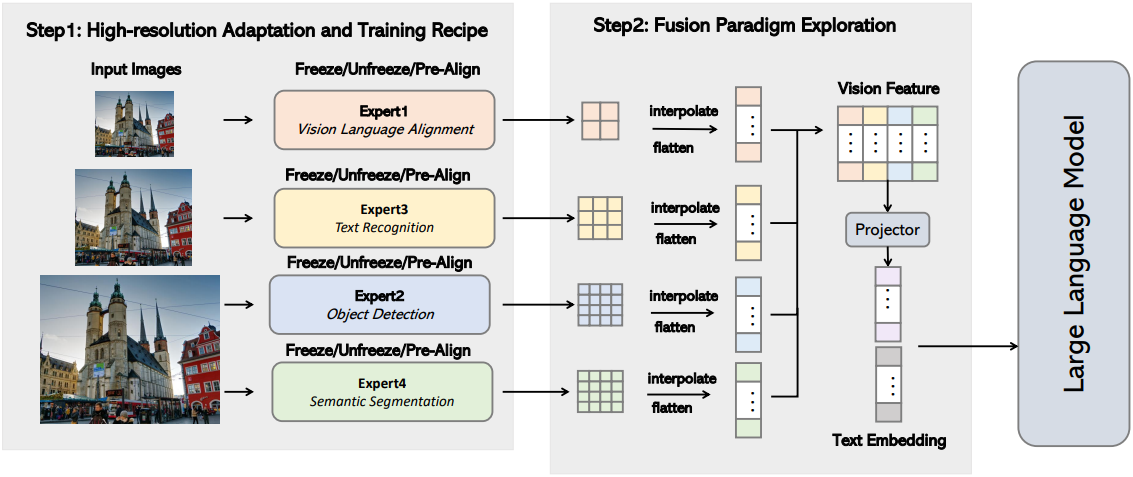
위의 질문에 답하기 위해, 저자들은 개선된 LMM 인식을 위한 mixture-of-vision-encoder design space를 체계적으로 조사하였다. Design space에 대한 탐색은 다음 단계로 구성된다.
- 다양한 비전 인코더 벤치마킹 및 더 높은 해상도 적응을 위한 레시피 탐색
- 비전 인코더 융합 전략 간의 비교
- 여러 비전 인코더의 최적 조합에 대한 점진적 식별
- 개선된 vision expert pre-alignment 및 데이터 혼합
저자들은 라운드 로빈 방식을 사용하여 추가 vision expert를 통합하였다. 기본 CLIP 인코더부터 시작하여 각 라운드에서 가장 좋은 개선을 보인 expert를 하나씩 추가한다.
본 논문은 LMM에서 여러 비전 인코더를 활용한 첫 번째 논문은 아니지만, 몇 가지 흥미로운 새로운 결과를 도출하였다.
- LMM 학습 중에 비전 인코더를 고정 해제하는 것이 중요하다. 이는 비전 인코더를 고정하는 LLaVA나 여러 비전 인코더를 고려하는 다른 연구들과는 대조된다.
- 간단한 channel concatenation이 간단하면서도 경쟁력 있는 융합 전략으로 돋보이며, 최고의 효율성과 성능을 제공한다.
- 추가 vision expert를 통합하면 일관된 성능 개선이 발생한다. 비전 인코더가 고정 해제되면 개선이 특히 두드러진다.
- 저자들은 텍스트에 정렬되지 않은 vision expert들이 함께 학습되기 전에 고정된 LLM으로 개별적으로 fine-tuning되는 pre-alignment 단계를 제안하였다. 이 단계는 mixture-of-vision-encoder 디자인에서 LMM 성능을 상당히 향상시킨다.
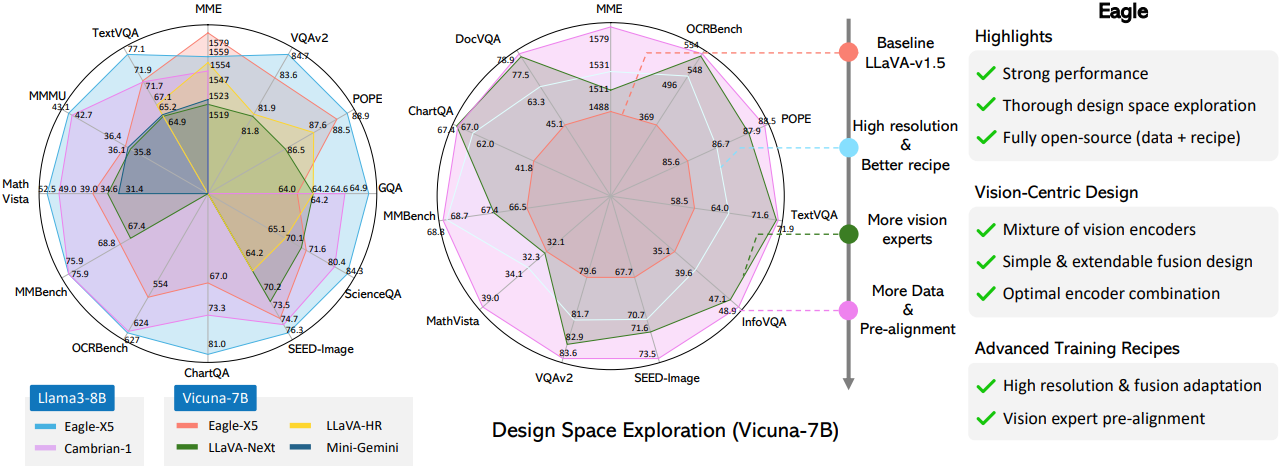
저자들은 이러한 결과들을 Eagle이라는 LMM으로 통합하였다. Eagle은 다양한 벤치마크에서 SOTA 성능을 달성하고 OCR과 문서 이해 task에서 명백한 이점을 보여준다.
Design space exploration
1. Base setup
저자들은 LLaVA의 모델 아키텍처를 기반으로 채택했으며, LLM, 비전 인코더, projector로 구성된다. Projector는 비전 인코더의 visual embedding을 text embedding space로 projection한다.
- 학습 데이터
- 사전 학습
- LLaVA-1.5와 동일한 사전 학습 데이터 사용
- 이미지-텍스트 쌍 59.5만 개
- Fine-tuning
- 여러 task들에서 데이터를 수집하고 이를 멀티모달 대화로 변환 (LLaVA-1.5, Laion-GPT4V, ShareGPT-4V, DocVQA, synDog-EN, ChartQA, DVQA, and AI2D)
- 샘플 93.4만 개
- 사전 학습
- 구현 디테일:
- 사전 학습: batch size 256, 1 epoch, projector layer만 업데이트
- fine-tuning: batch size 128, 1 epoch
- LLM: Vicuna-7B
- learning rate: 사전 학습은 $10^{-3}$, fine-tuning은 $2 \times 10^{-5}$
2. Stronger CLIP encoder
저자들은 CLIP 모델로 탐색을 시작하였다. 많은 기존 LMM은 사전 학습된 CLIP 해상도 (ex. 224$\times$224, 336$\times$336)를 입력 해상도로 사용하는 경향이 있다. 이러한 경우 인코더는 종종 OCR 및 문서 이해와 같은 해상도에 민감한 task에 중요한 디테일을 캡처하지 못한다.
증가된 입력 해상도를 처리하기 위한 일반적인 관행은 입력 이미지를 타일로 나누어 별도로 인코딩하는 타일링을 사용하는 것이다. 또 다른 간단한 방법은 입력 해상도를 직접 확대하고 필요한 경우 ViT 모델의 위치 임베딩을 보간하는 것이다. 저자들은 이 두 가지 접근 방식을 다른 해상도에서 고정/고정 해제된 비전 인코더와 비교했으며, 그 결과는 아래 표와 같다.
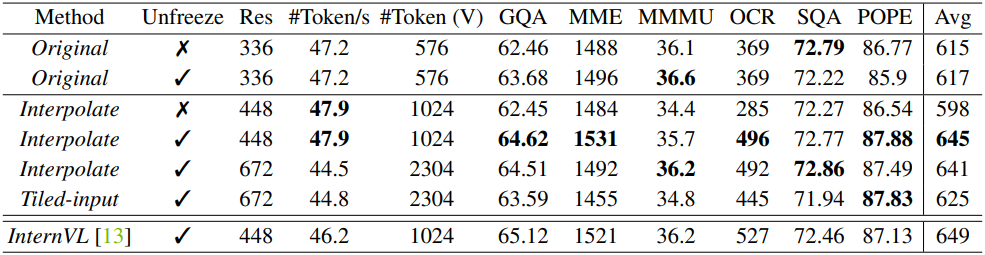
결과를 요약하면 다음과 같다.
- CLIP 인코더를 고정 해제하면 CLIP 사전 학습 해상도와 다른 더 높은 LMM 입력 해상도로 보간할 때 상당한 개선이 이루어진다. 해상도가 동일하게 유지되는 경우에도 성능 저하가 없다.
- CLIP 인코더가 고정된 경우 더 높은 LMM 입력 해상도로 직접 조정하면 성능이 상당히 저하된다.
- 비교된 전략 중에서 고정 해제된 CLIP 인코더를 사용하고 448$\times$448로 직접 보간하는 것이 성능과 비용 측면에서 효과적이고 효율적인 것으로 나타났다.
- 최상의 CLIP 인코더는 상당히 작은 모델 크기와 더 적은 사전 학습 데이터에도 불구하고 성능 면에서 InternVL에 가깝다.
CLIP-448을 사용하면 설정을 LLaVA-HR, InternVL과 일치시킬 수 있으며, CLIP 인코더는 유사하게 448$\times$448 입력을 받고 1024개의 패치 토큰을 출력하도록 적응된다. 이후 탐색에서는 학습 중에 입력 해상도를 확장하고 비전 인코더를 고정 해제하는 이 간단한 전략을 고수하였다.
3. Vision experts
저자들은 다양한 task와 해상도에 대해 사전 학습된 vision expert를 통해 고해상도 적응에 대한 결과를 검증하였다. 사용된 vision expert들은 아래 표와 같다.
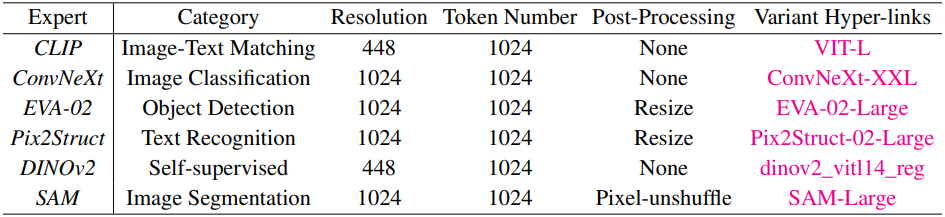
Bilinear interpolation과 pixel shuffle을 사용하여 각 비전 인코더의 출력 2D feature map의 크기를 조정하여 비주얼 토큰 수가 1024가 되도록 하였다.
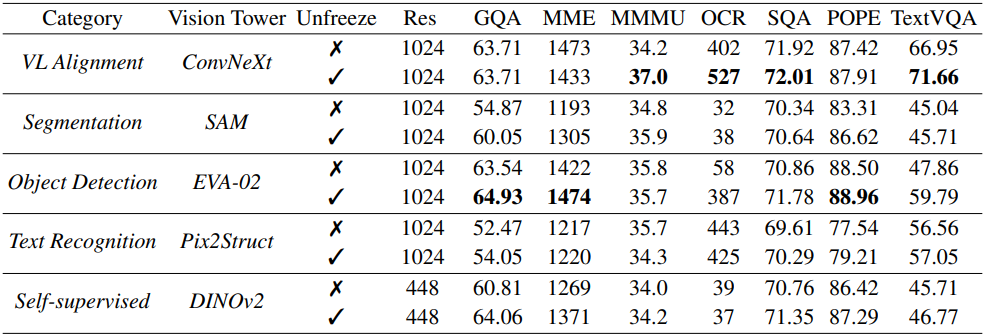
위 표의 결과는 task별 비전 인코더를 갖춘 LMM이 사전 학습 도메인에서 최적의 성능을 달성한다는 것을 보여준다.
4. Fusion strategy
기존 LMM 프레임워크는 비전 인코더들을 앙상블하기 위한 다양한 융합 전략을 제안했으며, 도메인별 강점을 활용할 수 있기를 기대했다. 모든 경우에 비전 인코더의 융합으로 LMM 성능이 향상되었다고 보고되었지만, LMM 아키텍처 혁신의 일부로서 융합 전략의 역할은 분리되지 않았다. 따라서 융합 전략 자체에서 얼마나 많은 개선이 이루어졌는지와 다양한 인코더의 개선된 표현에서 얼마나 많은 개선이 이루어졌는지 완전히 명확하지 않다.
기존의 인기 있는 융합 전략은 다음의 몇 가지 카테고리로 표현될 수 있다.

- Sequence Append: 여러 backbone들의 비주얼 토큰들을 더 긴 시퀀스로 직접 append
- Channel Concatenation: 시퀀스 길이를 늘리지 않고 채널 차원을 따라 비주얼 토큰을 concatenate
- LLaVA-HR: 혼합 해상도 어댑터를 사용하여 저해상도 비전 인코더에 고해상도 feature를 주입
- MiniGemini: CLIP 토큰을 저해상도 쿼리로 사용하여 동일한 위치의 local window에서 다른 고해상도 비전 인코더에 cross-attention
- Deformable Attention: MiniGemini의 window attention을 deformable attention로 대체
저자들은 기본 인코더 조합으로 “CLIP+ConvNeXt”와 “CLIP+ConvNeXt+SAM”을 선택하여 비교를 수행하였다.
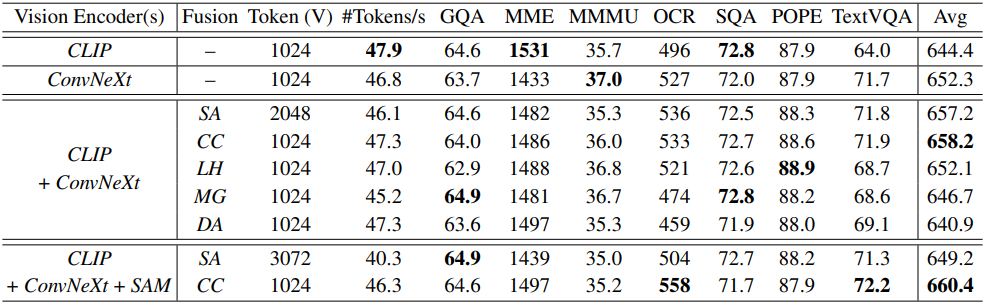
LLaVA-HR, Mini-Gemini, Deformable Attention과 같은 “주입 기반” 방법은 일반적으로 TextVQA 및 OCRBench에서 경쟁력이 떨어지며 비전 인코더로 ConvNeXt만 사용하는 것보다 성능이 떨어진다. 그럴듯한 설명은 CLIP feature가 비주얼 토큰에서 계속해서 지배적인 역할을 한다는 것이다.
Sequence append는 channel concatenation과 비슷한 성능을 보이지만 시퀀스 길이가 늘어나면서 더 많은 비전 인코더를 처리해야 하는 과제에 직면한다. 따라서 성능, 확장성, 효율성을 고려하여 Channel Concatenation을 융합 전략으로 선택하였다.
5. Vison-language Pre-Alignment
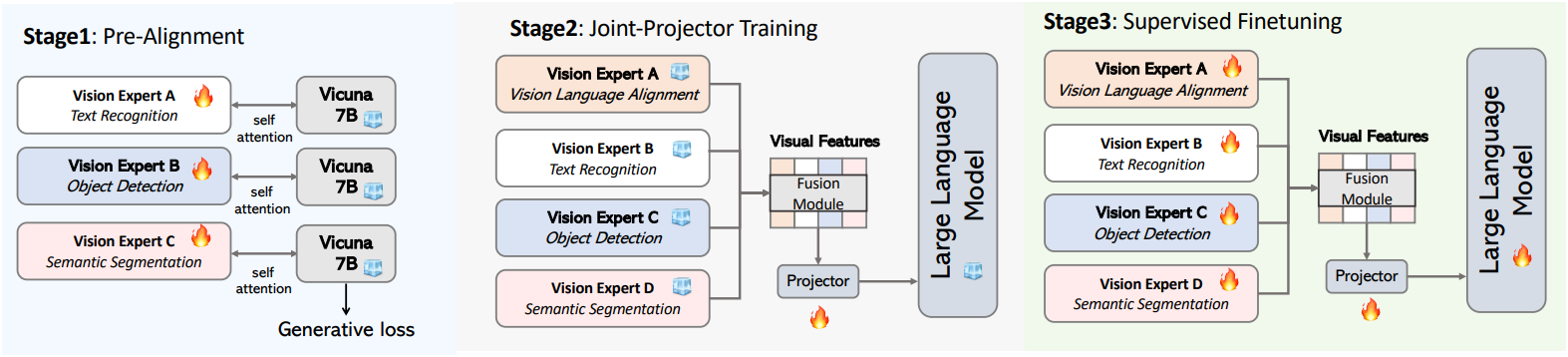
비전 task에 대해서만 사전 학습된 비전 backbone들은 vision language alignment에 대해서만 사전 학습된 인코더에 비해 경쟁력이 떨어진다. 이는 LLM과 통합할 때 표현 불일치가 발생하기 때문일 수 있다. 또한, 서로 다른 인코더를 결합할 때 이러한 인코더 간에 차이가 발생하여 학습 프로세스에 어려움이 발생한다. 저자들은 이러한 feature 불일치를 해결하기 위해, 각 비전 인코더를 동일한 LLM에 먼저 정렬하여 비전 feature와 언어 feature 사이의 더 나은 시너지를 촉진하는 Pre-Alignment 학습 단계를 제안하였다.
LLaVA의 원래 pre-alignment 전략에서처럼 projector가 여러 vision expert를 동시에 정렬하도록 학습시키는 대신, 먼저 next-token-prediction supervision을 사용하여 각 expert의 표현을 더 작은 언어 모델(Vicuna-7B)과 정렬한다. Pre-alignment를 사용하면 전체 학습 프로세스가 세 단계로 구성된다.
- 언어 모델을 고정한 상태에서 SFT (supervised fine-tuning) 데이터에서 각 사전 학습된 vision expert를 각자의 projector로 학습시킨다.
- 첫 번째 단계의 모든 vision expert를 결합하고 이미지-텍스트 쌍 데이터로 projector만 학습시킨다.
- SFT 데이터에서 전체 모델을 학습시킨다.
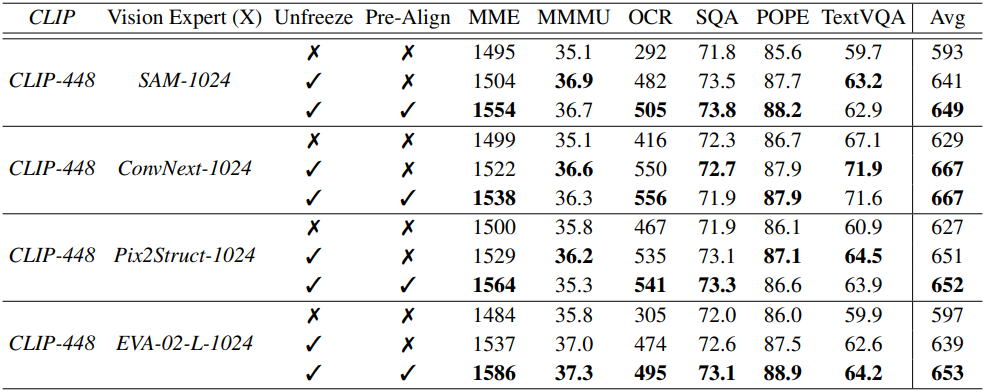
위 표에서 볼 수 있듯이, SFT 중에 vision expert를 고정 해제하면 언어 모델에 맞게 vision expert를 업데이트하여 성능을 개선하는 데 도움이 되지만, pre-alignment 전략은 각 vision expert의 고유한 편향을 더 효과적으로 완화하고 학습 프로세스를 안정화하여 결과적으로 전반적인 성능을 개선한다.
6. Extension to multi-experts
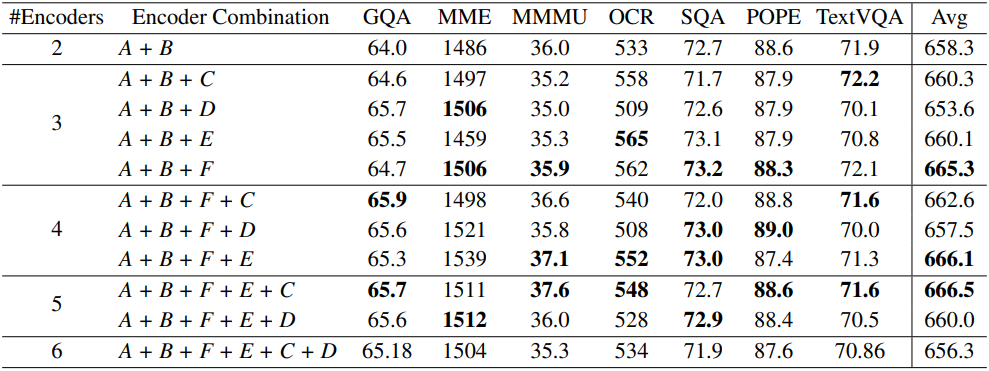
저자들은 한계를 뛰어넘기 위해 더 많은 vision expert를 통합하는 것을 고려하였다. 체계적이고 원칙적인 방식으로 검색을 수행하기 위해 추가 vision expert를 통합하기 위한 step-by-step greedy 전략을 채택하였다.
A, B, C, D, E, F는 각각 CLIP, ConvNeXt, SAM, DINOv2, Pix2Struct, EVA-02-L이며, 라운드 로빈 방식을 채택하였다. 저자들은 먼저 두 개의 최고 성능 비전 인코더인 CLIP과 ConvNeXt를 기반으로 사용하고 매번 비전 인코더를 하나씩 점진적으로 추가하였다. 각 라운드에서 가장 성능이 좋은 비전 인코더 조합은 다음 라운드를 위해 유지된다.
일반적으로 추가 비전 인코더를 도입하면 성능이 향상된다. 이는 다양한 인코더의 뚜렷한 장점을 보존하고 활용할 수 있음을 나타낸다. 예를 들어 EVA-02 인코더를 통합하면 POPE 벤치마크의 메트릭이 향상된다. 또한 vision expert의 가장 좋은 조합이 CLIP, ConvNeXt, SAM, Pix2Struct, EVA-02임을 보여주며, 이 레시피를 최종 모델에 사용한다.
Experiments

SFT 데이터를 구성하는 데이터 소스들은 위 표와 같다.
- 구현 디테일
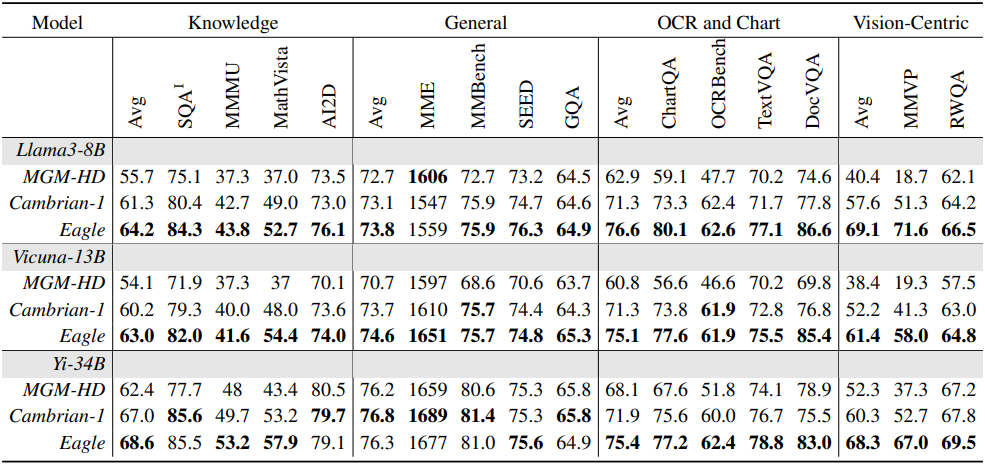
- LLM: Vicuna-v1.5-7B, Llama3-8B, Vicuna-v1.5-13B
- 비전 인코더
- Eagle-X4: CLIP, ConvNeXt, Pix2Struct, EVA-02
- Eagle-X5: Eagle-X4 + SAM
1. Main results
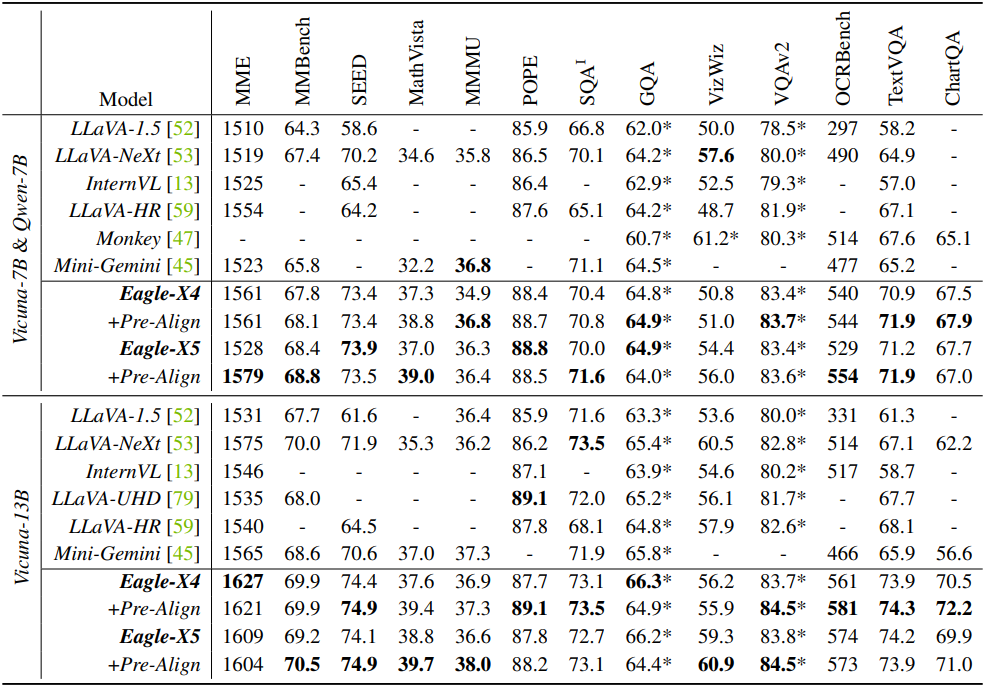
다음은 고급 학습 데이터 레시피를 사용한 결과이다.
다음은 vision expert 수에 따른 결과를 비교한 것이다. “baseline”은 CLIP+ConvNext만을 사용한 Eagle이고, “more vision experts”는 Eagle-X5 모델이다.
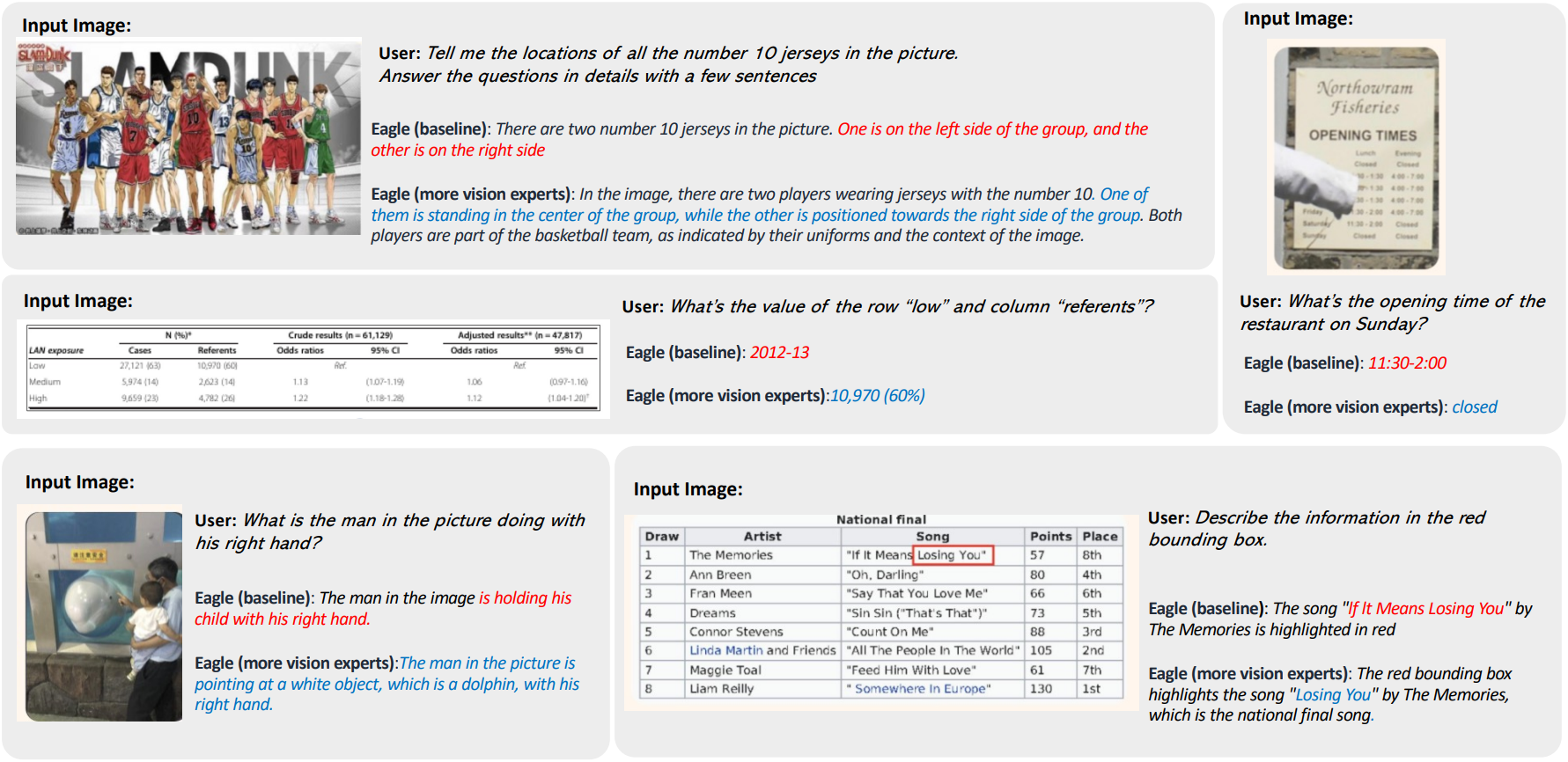
다음은 OCR과 문서 이해 task에 대한 예시이다.

다음은 VQA task에 대한 예시이다.
다음은 Cambrian-1 학습 데이터를 사용한 결과이다.