[논문리뷰] DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
ICCV 2025. [Paper] [Page] [Github]
Ruowen Zhao, Junliang Ye, Zhengyi Wang, Guangce Liu, Yiwen Chen, Yikai Wang, Jun Zhu
Tsinghua University | Nanyang Technological University | ShengShu
19 Mar 2025

Introduction
Autoregressive한 메쉬 생성 방법은 두 가지 중요한 과제에 직면한다.
- 사전 학습에는 여러 가지 어려움이 있다. Transformer를 위한 3D 메쉬를 tokenization하는 것은 종종 지나치게 긴 시퀀스를 생성하여 계산 비용을 증가시킨다. 또한, geometry가 좋지 않은 저품질 메쉬는 학습 안정성을 더욱 저하시켜 loss를 급증시킨다.
- 기존 방법은 출력을 인간의 선호도에 맞춰 조정하는 메커니즘이 부족하여 예술적으로 정교한 메쉬를 생성하는 데 한계가 있다. 또한, 생성된 메쉬는 구멍, 누락된 부분, 중복된 구조와 같은 기하학적 결함을 보이는 경우가 많다.
본 논문에서는 autoregressive 메쉬 생성을 위한 더욱 정교하고 효과적인 사전 학습 프레임워크를 제안하는 것을 목표로 히였다. 학습 효율을 높이기 위해, geometry 디테일 손실 없이 시퀀스 길이를 72%까지 줄이는 개선된 메쉬 tokenization 알고리즘을 도입하여 학습 계산 비용을 크게 절감하였다. 또한, 데이터 로딩 속도를 높이고 학습 중 부하 분산을 개선하는 특별히 설계된 데이터 패키징 전략을 제안하였다. 또한, 학습 데이터의 품질을 보장하기 위해 geometry가 좋지 않거나 혼돈스러운 구조를 가진 메쉬를 필터링하는 데이터 큐레이션 전략을 개발하였다. 이러한 개선을 통해, 저자들은 topology 생성을 위한 대규모 transformer 모델을 성공적으로 사전 학습시켰으며, 500M에서 1B 파라미터로 scaling하였다.
사전 학습된 topology 생성 모델의 성능을 더욱 향상시키기 위해, 저자들은 3D autoregressive 모델에 Direct Preference Optimization (DPO)를 적용하여 모델 출력을 인간의 선호도에 맞춰 조정했다. 먼저, 사전 학습된 모델을 사용하여 쌍별 학습 데이터를 생성하고, 인간의 평가와 3D geometry metric을 주석으로 사용하였다. 이후, 강화 학습(RL)을 활용하여 선호도 레이블이 있는 샘플로 모델을 fine-tuning하였다. 이러한 개선을 통해 프레임워크는 512의 quantization 해상도에서 최대 3만 개의 면(face)을 포함하는 다양하고 고품질의 메쉬를 생성할 수 있다.
Method
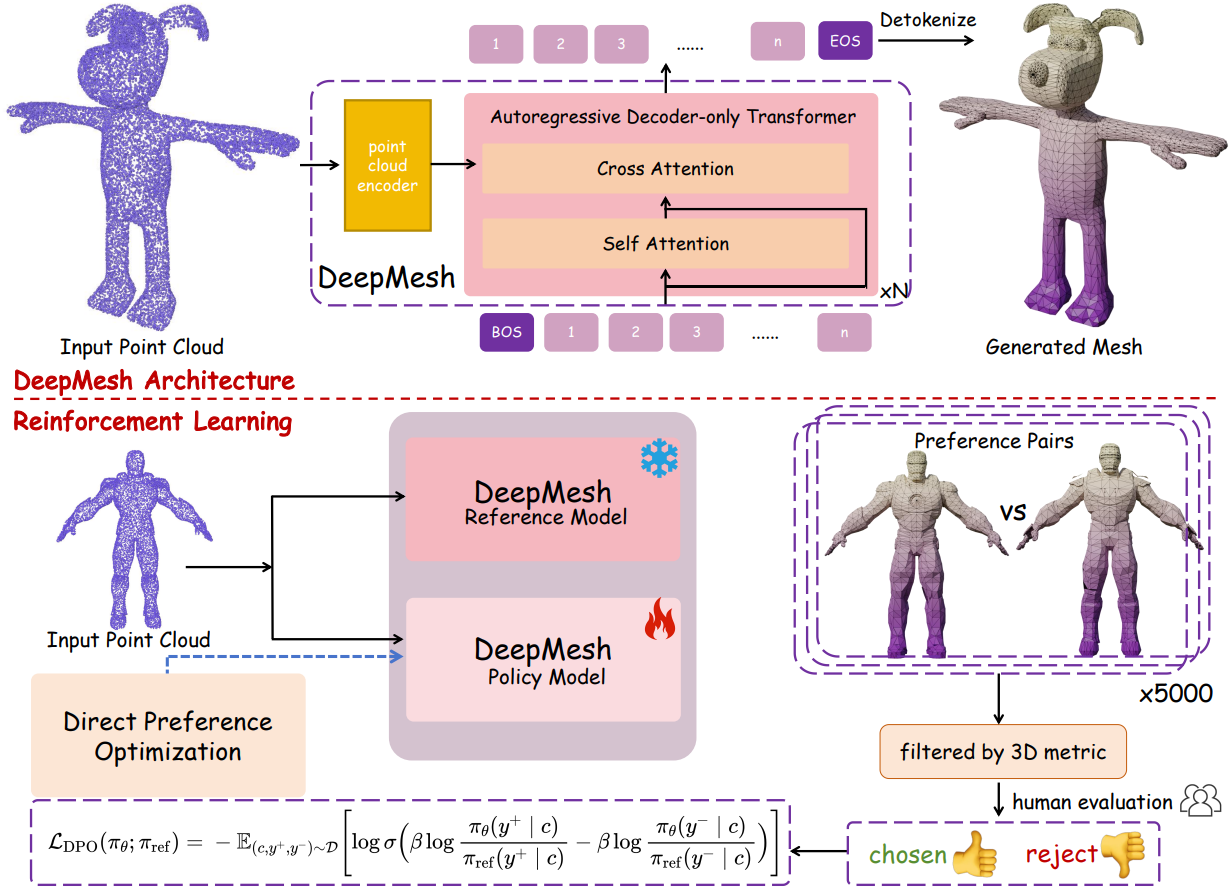
1. Tokenization Algorithm
텍스트와 유사하게, 메쉬는 autoregressive 모델로 처리하기 위해 discrete한 토큰으로 변환되어야 한다. 기존의 메쉬 tokenization 방식에서는 연속적인 vertex 좌표를 공간 해상도 $r$의 bin으로 quantization한 후 $r$개의 카테고리로 분류한다. Quantization 후, 삼각형 메쉬는 각각 세 개의 discretize된 3D vertex 좌표를 갖는 면들의 시퀀스로 처리된다. 그러나 이러한 표현 방식은 각 vertex가 연결된 면의 개수만큼 나타나기 때문에 상당한 중복성을 초래한다.
최근 BPT는 local-aware face traversal과 block-index 좌표 인코딩을 통해 128 해상도에서 약 74%의 SOTA 압축률을 갖는 압축 메쉬 표현을 제안했다. 그러나 BPT는 고해상도에서 vocabulary가 급격히 증가하기 때문에 저해상도 메쉬에만 효과적으로 작동하며, 이로 인해 학습의 어려움과 비용이 증가한다. 이러한 한계를 해결하기 위해, 저자들은 block-wise indexing을 개선하여 고해상도 메쉬를 더 잘 처리하도록 하였다.
BPT와 유사하게, 먼저 메쉬 면을 연결성에 따라 로컬 패치로 나누어 중복성을 최소화한다. 이러한 로컬 순회는 각 면이 이전 면의 짧은 컨텍스트에만 의존하도록 하여 면 토큰 간의 long-range dependency를 방지하고 학습의 어려움을 완화한다. 그런 다음, 면의 각 vertex 좌표를 정렬하고 quantization한 후, XYZ 순서로 flatten하여 완전한 토큰 시퀀스를 형성한다. 시퀀스 길이를 더욱 줄이기 위해 전체 좌표계를 3개의 계층적 블록으로 분할하고, 각 블록 내에서 quantization된 좌표를 offset으로 인덱싱한다. Quantization된 좌표가 정렬됨에 따라 이웃 정점들이 동일한 offset 인덱스를 공유하는 경우가 많다. 따라서 길이를 더 줄이기 위해 동일한 값을 가진 인덱스를 병합한다.
이러한 설계를 통해 향상된 알고리즘은 약 72%의 압축률을 달성하여 시퀀스 길이를 크게 줄이고 고해상도 데이터셋에 대한 학습을 더욱 용이하게 한다. 또한, 모델이 학습해야 하는 vocabulary 크기도 훨씬 작아져 학습 효율이 크게 향상되었다.
2. Pre-training of DeepMesh
2.1 Data Curation
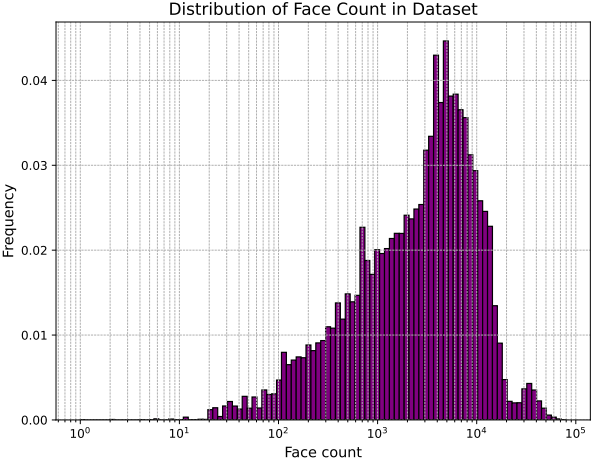
학습 데이터의 품질은 모델 성능을 근본적으로 좌우한다. 그러나 기존 3D 데이터셋은 품질 변동성이 매우 크며, 많은 샘플이 불규칙한 topology, 과도한 파편화, 또는 극심한 기하학적 복잡성을 포함하고 있다. 이 문제를 완화하기 위해, 저자들은 기하학적 구조와 시각적 충실도를 기반으로 품질이 낮은 메쉬를 필터링하는 데이터 큐레이션 전략을 제안하였다. 위 그림에서 볼 수 있듯이, 큐레이션된 데이터셋의 면 개수 분포는 고품질 메쉬 컬렉션임을 보여준다.
2.2 Truncated Training and Data Packaging
본 데이터셋에는 고해상도 메쉬가 널리 분포되어 있어 긴 토큰 시퀀스가 생성되고, 이는 학습 중 계산 비용을 크게 증가시킨다. 이 문제를 해결하기 위해 Meshtron의 truncated training 방식을 도입하여 효율성을 향상시켰다. 구체적으로, 입력 토큰 시퀀스를 먼저 고정 크기의 context window로 분할하고, 길이가 부족한 세그먼트에는 padding을 적용한다. 그런 다음, sliding window 메커니즘을 사용하여 window를 단계적으로 이동하고, 각 window가 적용된 세그먼트를 그에 따라 학습시킨다. 각 batch 내 시퀀스 길이의 차이로 인해 truncated training에서 발생하는 불필요한 sliding을 줄이기 위해, 면 개수를 기준으로 학습 메쉬를 분류하고, 각 GPU에서 각 batch에 면 개수가 유사한 메쉬를 할당한다. 이 전략은 학습 중 부하 분산을 개선하고 중복 계산을 줄일 수 있다.
2.3 Model Architecture
DeepMesh의 핵심 구조는 autoregressive transformer로, 각 레이어는 self-attention layer, cross-attention layer, feed-forward network로 구성된다. 포인트 클라우드 조건부 생성을 위해 Michelangelo 기반의 Perceiver 인코더를 사용한다. 그런 다음, 포인트 클라우드 feature들은 cross-attention을 통해 통합된다. 학습 속도를 높이기 위해 Hourglass Transformer를 채택했는데, 이는 성능을 유지하면서 메모리를 50% 절약할 수 있다.
3. Performance Enhancement by DPO
사전 학습된 모델은 고품질 메쉬를 생성할 수 있지만, 미관상 좋지 않거나 geometry가 불완전한 경우가 종종 발생한다. 결과를 더욱 향상시키기 위해 Direct Preference Optimization (DPO)를 사용하여 출력을 사람의 선호도에 맞춰 조정하였다. 또한, 선호도 데이터셋을 큐레이션하기 위한 포괄적인 주석 파이프라인을 개발하여 결과의 전반적인 품질을 향상시켰다.
3.1 Score Standard
메쉬 품질은 기하학적 무결성과 시각적 매력도라는 두 가지 요소에 의해 주로 영향을 받는다. 따라서 본 논문에서는 이 두 가지 측면을 종합적으로 고려하는 아티스트 수준의 메쉬 생성을 위한 채점 기준을 제안하였다. 기하학적 무결성은 생성된 메쉬의 완전성과 정확성에 중점을 둔다. 구체적으로, 생성된 메쉬와 실제 메쉬 간의 유사도를 측정하기 위해 Chamfer Distance와 같은 3D metric을 사용한다. Chamfer Distance가 낮을수록 정확도가 높고 기하학적 표현이 더욱 완벽함을 나타낸다. 반면, 시각적 매력도는 일반적인 와이어프레임과 표면 디테일을 포함한 메쉬의 미적 품질을 평가한다. 메쉬의 시각적 품질을 평가하는 모델이 없기 때문에, 저자들은 자원봉사자들을 모집하여 다양한 메쉬를 비교하고 주관적인 선호도를 기반으로 시각적으로 더 매력적인 메쉬를 선정했다. 이러한 인간 피드백 수집 방식은 기존 metric에서 간과하기 쉬운 미적 판단을 포착한다.
3.2 Preference Pair Construction
저자들은 제안된 채점 기준을 사용하여 선호도 쌍 데이터셋을 구축하였다. 각 입력 포인트 클라우드에 대해, 모델은 두 개의 서로 다른 메쉬를 생성하고 다음과 같은 방법으로 선호도 쌍이 선택된다.
- 두 메쉬 모두 미리 정의된 threshold 이상의 Chamfer Distance를 보이는 경우, 두 메쉬는 모두 제외된다.
- 한 메쉬가 높은 기하학적 충실도를 보이는 반면 다른 메쉬는 부족한 경우, 더 우수한 메쉬를 positive로 지정한다.
- 두 메쉬가 모두 기하학적 기준을 충족하는 경우, 미적 선호도에 따라 positive와 negative가 결정된다.
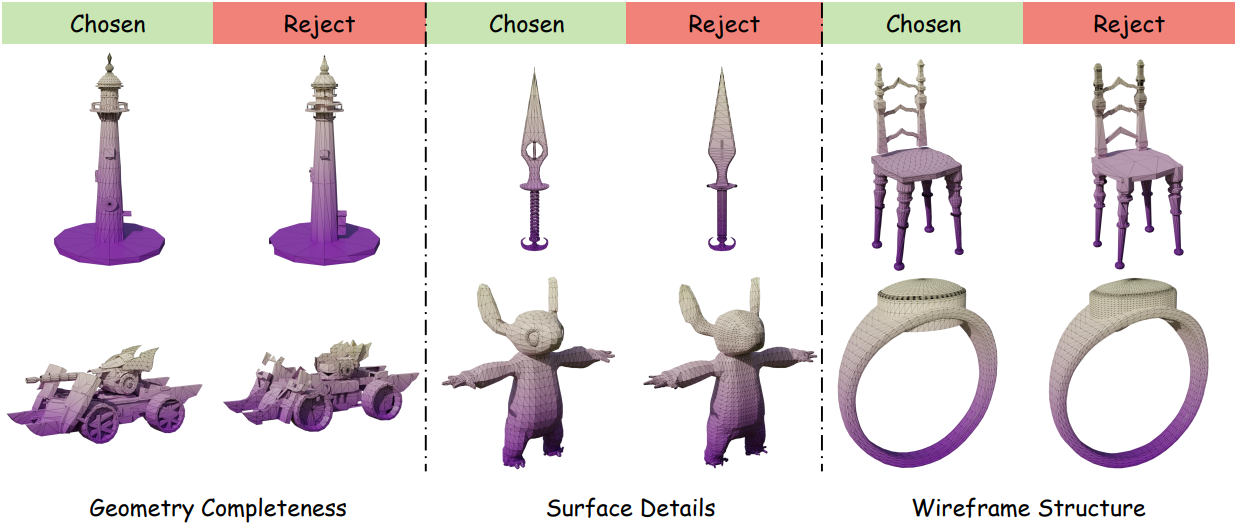
위 그림은 수집된 데이터 쌍의 몇 가지 예를 보여주며, 각각은 기하학적 구조와 외관적 매력도를 기준으로 구분된다. 저자들은 총 5,000개의 선호도 쌍을 수집했다.
3.3 Direct Preference Optimization
DPO는 생성 모델을 인간의 선호도에 맞춰 조정하는 데 사용된다. Positive 레이블 $y^{+}$와 negative 레이블 $y^{-}$가 있는 생성된 샘플 쌍을 학습함으로써, 모델은 더 높은 확률로 positive 샘플을 생성하는 방법을 학습한다. DPO의 objective function은 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{DPO} (\pi_\theta; \pi_\textrm{ref}) = -\mathbb{E}_{(c, y^{+}, y^{-}) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta (y^{+} \vert c)}{\pi_\textrm{ref} (y^{+} \vert c)} - \beta \log \frac{\pi_\theta (y^{-} \vert c)}{\pi_\textrm{ref} (y^{-} \vert c)} \right) \right] \end{equation}\]저자들은 구축된 선호도 쌍 데이터셋을 사용하여 모델을 fine-tuning시키고, 위의 loss function을 적용하여 기하학적 충실도와 미적 매력 모두에 맞춰 출력을 정렬하였다. 또한, 학습 효율성을 유지하기 위해 사전 학습 단계에서 사용한 것과 동일한 truncated training 전략을 채택하여 데이터셋의 고해상도 메쉬에서 생성된 긴 토큰 시퀀스를 처리한다.
Experiments
- 데이터셋: ShapeNetV2, ABO, HSSD, Objaverse, Objaverse-XL
- 구현 디테일
- GPU: NVIDIA A800 128개에서 4일 소요
- 더 나은 일반화를 위해 0◦, 90◦, 180◦, 270◦로 랜덤 회전
- 포인트 클라우드: 16,384개
- learning rate: $10^{-4}$에서 $10^{-5}$로 코사인으로 감소
- 컨텍스트 길이: 9천 토큰
- temperature: 0.5
1. Qualitative Results
다음은 포인트 클라우드를 조건으로 생성한 메쉬를 비교한 결과이다.

다음은 이미지를 조건으로 생성한 예시들이다.

다음은 동일한 포인트 클라우드에 대한 다양한 생성 예시들이다.

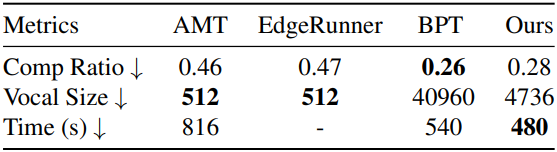
2. Quantitative Results
다음은 다른 방법들과 정량적으로 비교한 결과이다.
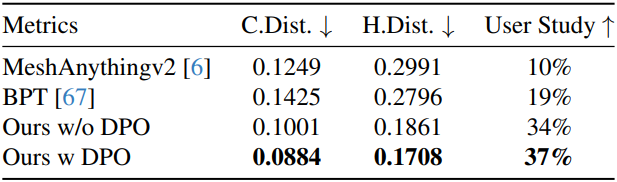
3. Ablation Study
다음은 DPO에 대한 ablation study 결과이다.

다음은 tokenization에 대한 ablation study 결과이다. (AMT는 MeshAnything V2의 tokenization)