[논문리뷰] Meshtron: High-Fidelity, Artist-Like 3D Mesh Generation at Scale
arXiv 2024. [Paper] [Page]
Zekun Hao, David W. Romero, Tsung-Yi Lin, Ming-Yu Liu
NVIDIA
12 Dec 2024
Introduction
메쉬 생성을 크고 사실적인 메쉬로 scaling하는 것은 어려운 일이다. 면이 $N$개이고 면당 vertex기 $n$개인 3D 메쉬를 표현하는 가장 일반적인 방법은 $3nN$개의 좌표의 메쉬 시퀀스로 flatten하는 것이다. 3.2만 개의 면을 가진 삼각형 메쉬의 경우, 이는 28.8만 개의 토큰 시퀀스를 생성한다. 이 길이의 시퀀스를 생성하는 것은 효율성과 robustness 측면에서 모두 어려움을 겪는다. 이러한 한계를 해결하기 위해, 최근 논문들은 메쉬를 표현하는 데 필요한 토큰이 더 적은 컴팩트한 표현을 개발하는 데 중점을 두고 있다. 그럼에도 불구하고 사실적인 고품질 메쉬를 생성하는 데에는 여전히 부족하다.
본 논문에서는 컴팩트한 표현을 개발하는 대신, scalability 문제의 근본 원인인 Transformer의 quadratic cost를 해결하여 더욱 scalable하고 robust한 메쉬 생성 모델을 설계하는 데 중점을 두었다. 기존 방법은 global self-attention에 크게 의존하기 때문에 디테일한 물체에 필요한 긴 메쉬 시퀀스를 다룰 때 엄청난 비용이 발생한다.
저자들은 메쉬 시퀀스가 단순히 토큰의 시퀀스가 아닌 더 많은 구조를 가지고 있으며, 좌표, vertex, 면 수준의 추상화에서 동등하게 표현될 수 있음을 인식했다. 또한, 메쉬 시퀀스가 구성되는 방식에서 각 면과 vertex 내의 종료 좌표가 시작 좌표보다 예측하기 어려운 주기적 패턴을 식별하였다. 이러한 통찰력을 바탕으로 Transformer를 계층적인 Hourglass Transformer로 대체하였다. Hourglass 아키텍처는 vertex와 면에 맞춰 추상화 수준이 높아지면서 정보를 계층적으로 요약함으로써 메쉬 시퀀스에 강력한 inductive bias를 도입한다. 또한, 각 vertex와 면 그룹의 생성하기 어려운 마지막 토큰을 더 깊은 레이어를 통해 처리하여 계산 리소스를 효율적으로 할당한다.
저자들은 적절한 컨디셔닝을 사용하면 메쉬 생성 시 학습 과정에서 전체 메쉬 시퀀스에 접근할 필요가 없음을 관찰했다. 대신, sliding window 방식을 사용하여 부분적인 메쉬 시퀀스를 학습하고 inference 과정에서 완전한 메쉬 시퀀스를 생성할 수 있다. 이를 통해 학습 과정에서 계산 및 메모리 비용을 크게 절감하는 동시에 inference 속도도 향상된다. 또한, 나중 좌표가 메쉬 시퀀스에서 미리 정의된 순서를 준수해야 하는 robust한 샘플링 전략을 도입했다. 이를 통해 생성된 메쉬 시퀀스가 현실적인 구조를 유지하도록 보장하여 더욱 일관되고 안정적인 메쉬 생성을 가능하게 하였다.
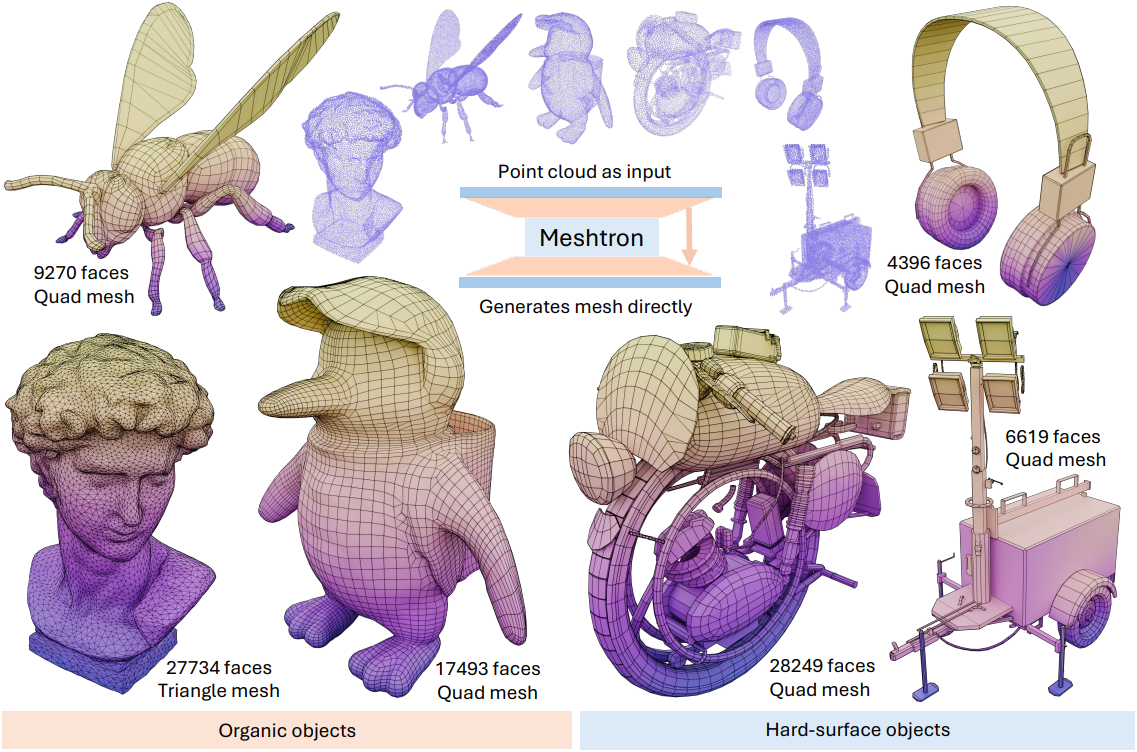
본 논문에서 제안한 모델인 Meshtron은 기존 방법보다 학습 메모리 사용량을 50% 이상 절감하고 처리량을 2.5배 향상시켰다. 이러한 효율성 덕분에 간단한 분산 데이터 병렬 (DDP) 셋업을 사용하여 최대 6.4만 개의 면과 1,024 레벨의 vertex 좌표 해상도를 갖는 메쉬를 생성할 수 있는 1.1B autoregressive 모델을 학습시켰다. Meshtron은 상세한 geometry, 고품질 topology, 높은 다양성을 특징으로 하는 메쉬를 생성하는 전례 없는 역량을 보여주었다. 또한 포인트 클라우드를 기반으로 하며, 학습 중 추가되는 컨디셔닝 입력을 통해 메쉬 밀도나 quad-dominant 생성을 제어할 수 있다.
Method
1. Hierarchical mesh modeling with hourglass transformers
메쉬 생성을 일반적인 시퀀스 생성 문제로 다룰 수 있지만, 그렇게 하면 메쉬 시퀀스의 고유한 구조를 간과하게 되며, 이 구조를 활용하여 더욱 효과적인 모델을 구축할 수 있다.
\[\begin{aligned} \textbf{M} &= \{\textbf{f}^1, \ldots, \textbf{f}^N\} \\ &= \{\textbf{v}_1^1, \textbf{v}_2^1, \textbf{v}_3^1, \ldots, \textbf{v}_1^N, \textbf{v}_2^N, \textbf{v}_3^N\} \\ &= \{v_1^1 x, v_1^1 y, v_1^1 z, v_2^1 x, v_2^1 y, v_2^1 z, \ldots, v_2^N x, v_2^N y, v_2^N z, v_3^N x, v_3^N y, v_3^N z\} \\ \end{aligned}\]위 식에서 볼 수 있듯이, 메쉬 토큰은 2단계 계층 구조를 따른다. 3개의 토큰은 vertex를 나타내고, 3개의 vertex, 즉 9개의 토큰은 삼각형을 형성한다. 텍스트 토큰과 달리, 개별 메쉬 토큰은 제한된 정보를 담고 있으며 해당 계층 그룹에서 처리될 때만 의미를 갖는다. 메쉬 토큰을 응집력 있는 계층적 단위로 취급함으로써 모델은 메쉬 시퀀스의 구조를 더 잘 포착하여 이해 및 생성을 향상시킬 수 있다.
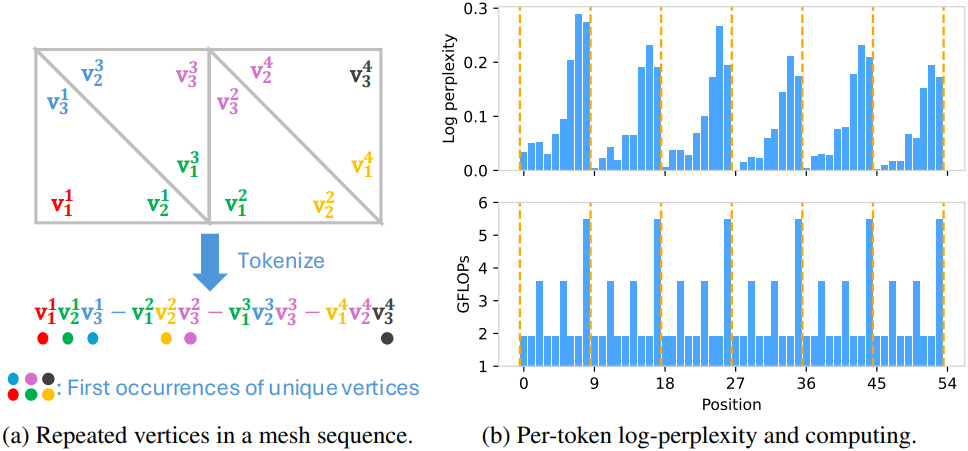
메쉬 시퀀스의 계층적 구조 외에도, 메쉬 시퀀스를 구성하는 데 사용되는 순서로 인해 토큰 생성 시에 독특한 반복적 패턴이 관찰된다. 각 삼각형 내의 초기 토큰은 나중 토큰보다 생성하기가 더 쉬운데, 이는 평균 perplexity 값이 낮기 때문이다. 마찬가지로, 각 vertex 내에서 나중에 생성되는 토큰은 예측하기 어려운 경향이 있다. 이러한 패턴은 인접한 삼각형 간의 vertex 공유로 인해 발생하며, 이로 인해 메쉬 시퀀스에 토큰이 반복 생성되기 때문이다.
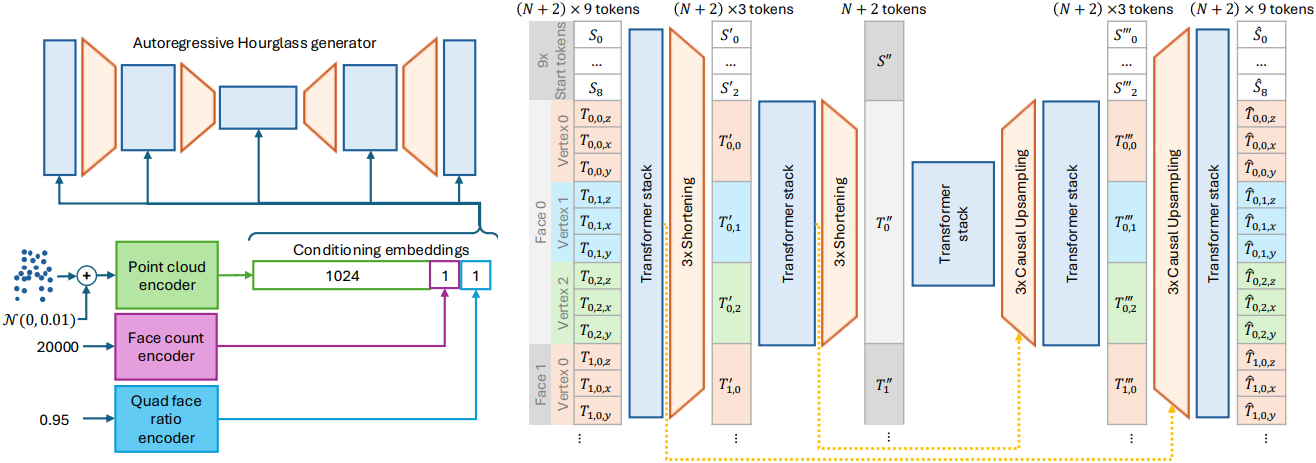
따라서 저자들은 여러 추상화 레벨에서 입력을 처리하도록 설계된 Hourglass Transformer 아키텍처에 주목하였다. 이 아키텍처는 각 레벨에서 여러 개의 Transformer 스택을 사용하며, 이러한 계층적 레벨을 연결하기 위해 인과성을 보존하는 shortening layer와 upsampling layer에 의해 레벨 간 전환이 관리된다. Shortening layer는 토큰 임베딩 그룹을 하나의 임베딩으로 압축한다. Upsampling layer는 하나의 임베딩을 여러 토큰으로 다시 확장하여 이 프로세스를 shortening layer의 반대 연산을 한다. 확장된 시퀀스는 U-Net과 유사하게 residual connection을 통해 이전 레벨의 고해상도 시퀀스와 결합된다.
또한 Hourglass 아키텍처는 시퀀스 내 토큰의 위치에 따라 계산을 다르게 할당하는 정적 라우팅 메커니즘을 제공한다. Shortening factor가 $s$인 경우, 시퀀스의 모든 $s$번째 토큰만 내부 Transformer 스택을 통과하고, 다른 토큰들은 이를 우회한다. 이러한 선택적 라우팅을 통해 모델은 미리 지정된 입력 구조에 따라 계산을 효율적으로 분산할 수 있다.
Meshtron의 backbone은 두 개의 shortening layer를 갖는 Hourglass Transformer로 설계되었으며, 각 레이어는 시퀀스를 3배씩 줄인다. 그 결과, shortening된 레이어는 메쉬의 vertex와 면을 나타내는 토큰 그룹에 해당하는 3단계 모델이 생성된다. 메쉬의 구조적 패턴에 맞춰 아키텍처를 조정함으로써, Meshtron은 기존 방법들이 사용하던 아키텍처보다 더 효과적으로 리소스를 할당한다.
2. Training on truncated sequences and inference with sliding-window
메쉬 시퀀스는 토큰 수가 수십만 개에서 수십만 개에 이를 정도로 매우 길 수 있다. 따라서 Hourglass 아키텍처의 메모리 및 연산량 절감 효과에도 불구하고 전체 메쉬 시퀀스에 대한 학습은 여전히 엄청나게 비쌀 수 있다. 또한, 시퀀스 길이의 편차가 크기 때문에 고급 병렬화 기술을 적용하더라도 효율적인 학습 환경을 구현하는 데 어려움을 겪는다.
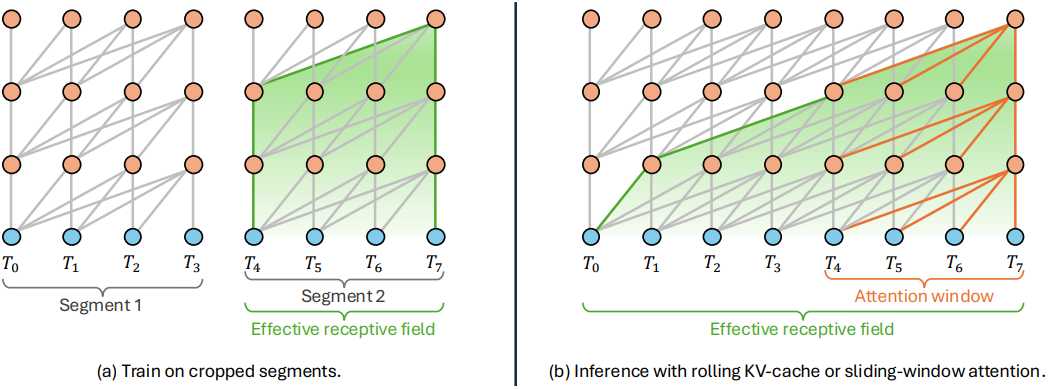
메쉬 시퀀스의 순서는 삼각형을 아래에서 위로, 레이어별로 정렬하여 시퀀스 내 인접 삼각형의 locality를 향상시킨다. 따라서 적절한 글로벌 조건을 가정하면, 후속 삼각형 생성에는 인접 토큰의 정보, 특히 인접 삼각형의 vertex 위치만 필요하다. 이 특별한 속성 덕분에 효율적인 학습과 inference를 위해 sliding window 방식을 채택할 수 있다. 구체적으로, 학습 중 컴퓨팅 및 메모리 소비를 크게 줄이기 위해 고정 길이의 잘린 메쉬 시퀀스 세그먼트로 모델을 학습시킨다. 그런 다음 inference 중에 attention window와 동일한 버퍼 크기를 가진 rolling KV cache를 사용하여 선형 복잡도를 달성한다. 중요한 점은 inference 중에 캐싱된 임베딩이 현재 attention window 외부에서 정보를 전달하기 때문에 학습과 inference 사이에 약간의 불일치가 있지만, 성능에 부정적인 영향을 미치지 않고 이전 컨텍스트를 다시 계산할 필요 없이 효율적인 생성이 가능하다.
3. Global conditioning on truncated sequences with cross-attention
기존 방법들은 포인트 클라우드와 같은 조건의 임베딩을 메쉬 시퀀스의 시작 부분에 연결하여 조건부 생성을 수행한다. 그러나 본 논문에서는 잘린 메쉬 시퀀스에 대한 학습을 포함하기 때문에, 조건부 신호를 미리 추가하는 것은 조건부 신호를 소수의 메쉬 세그먼트에만 적용하거나, 학습 및 inference 과정에서 복잡한 concat 전략을 필요로 한다. 이러한 한계를 극복하기 위해, 본 논문에서는 cross-attention을 사용하여 시퀀스 내 위치와 관계없이 모든 메쉬 세그먼트를 글로벌 조건부 신호로 컨디셔닝한다. 이를 통해 본 모델은 학습 및 inference 과정에서 로컬 정보와 글로벌 정보를 효과적으로 결합하여 리소스 사용량을 낮추면서도 정확한 예측을 수행할 수 있다.
Meshtron은 포인트 클라우드를 조건으로 메쉬를 생성하도록 설계되었다. Michelangelo의 Perceiver 인코더를 통해 입력 포인트 클라우드를 1,024개의 임베딩으로 인코딩한다. 또한 triangulation 전에 메쉬에서 면의 개수와 quad face의 비율을 조건으로 생성을 컨디셔닝한다. 이러한 변수를 통해 inference 중 메쉬 밀도와 quad-dominant를 제어할 수 있다. 각 변수는 MLP를 통해 하나의 임베딩으로 인코딩되고, 컨디셔닝을 위해 포인트 클라우드 임베딩에 concat된다. Llama 3를 따라 Transformer 스택의 4번째 레이어마다 cross-attention layer를 사용하여 메인 모델과 컨디셔닝 임베딩 간의 상호 작용을 가능하게 하였다.
4. Robust mesh generation with mesh sequence ordering enforcement
Robust한 생성을 보장하기 위해, 생성된 메쉬 시퀀스가 생성된 순서를 준수하도록 강제한다. 구체적으로, 각 면 내의 vertex 좌표가 사전식 오름차순을 따르고, 이후 면의 좌표 또한 이전 면을 기준으로 사전식 오름차순을 따르도록 생성을 제한한다. 또한, 시퀀스 종료 토큰이 새 면의 시작 부분에만 나타나도록 제한한다. 이러한 제약은 일관되지 않은 시퀀스 생성을 방지하여 출력이 데이터 분포 내에 유지되도록 한다.
저자들은 생성 프로세스를 시뮬레이션하여 validation 데이터셋을 기반으로 순서 적용 알고리즘을 벤치마킹하였다. 각 토큰에 대해 N-way categorical distribution에서 이전 토큰을 기반으로 시퀀스 순서를 위반하는 유효하지 않은 카테고리의 수를 계산하였다. 본 알고리즘은 1,024레벨 quantization에서 32%, 128레벨 quantization에서 27%의 유효하지 않은 예측을 방지하여 모델의 샘플 공간을 효과적으로 좁히고 생성 품질과 robustness를 모두 향상시킨다.
Experiments
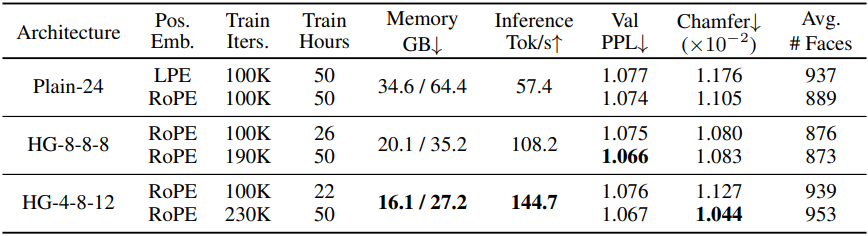
1. Hourglass vs plain Transformer
다음은 Transformer 아키텍처에 따른 성능을 비교한 결과이다.
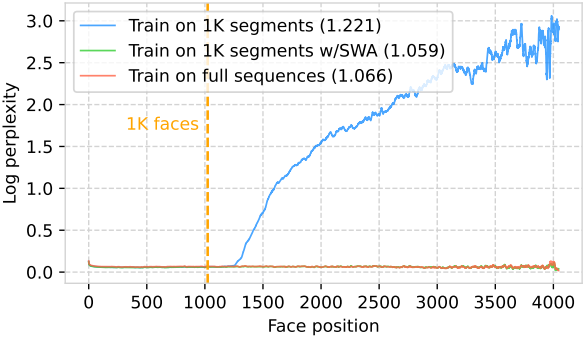
2. Generating full mesh sequences with models trained on truncated data
다음은 학습에 사용된 시퀀스 길이에 따른 성능을 비교한 결과이다. (SWA: sliding window attention)

3. Scaling meshtron to 64k faces
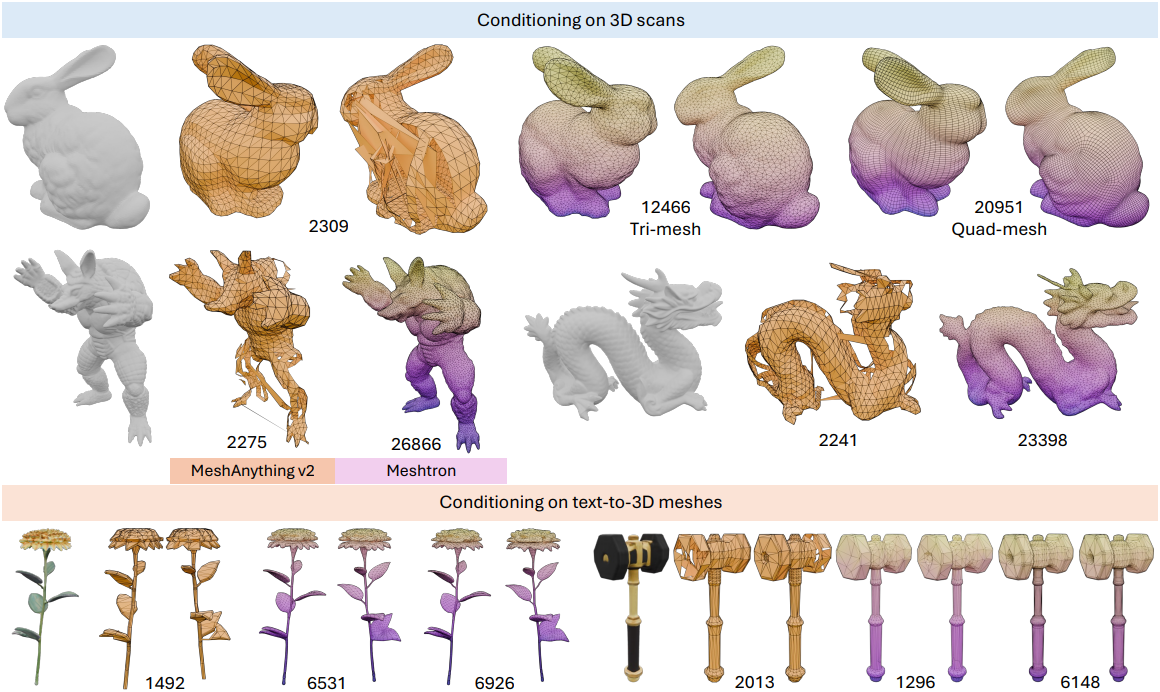
다음은 포인트 클라우드를 조건으로 생성한 메쉬를 비교한 결과이다.

다음은 3D 스캔이나 text-to-3D 모델로 얻은 메쉬에서 포인트 클라우드를 샘플링한 다음 Meshtron으로 메쉬를 생성한 예시들이다.