[논문리뷰] Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
CVPR 2024. [Paper]
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
KAIST | Adobe
5 Apr 2024

Introduction
Text-to-image (T2I) 생성 모델을 커스터마이징하는 데 상당한 진전이 있었지만, 여러 개인화된 개념을 결합한 이미지를 생성하는 것은 여전히 어려운 일이다. 여러 방법들은 여러 개념에 대한 모델을 공동으로 학습시키거나 커스터마이징된 모델을 병합하여 두 개 이상의 개인화된 개념이 있는 장면을 생성할 수 있는 능력을 제공한다. 그러나 종종 의미적으로 관련된 개념들(ex. 고양이와 개)을 생성하지 못하고 세 개 이상의 개념을 넘어서는 확장에 어려움을 겪는다.
본 논문는 inference 시에 커스터마이징된 T2I diffusion model들을 합성하기 위한 튜닝이 필요 없는 방법을 제안하였다. 구체적으로, 처음부터 개인화된 이미지를 생성하는 대신 프로세스를 두 단계로 나눈다. 먼저, 입력 프롬프트의 semantic과 일치하는 템플릿 이미지를 만든 다음, 새로운 개념 융합 전략을 사용하여 이 템플릿 이미지를 개인화한다. 융합 전략은 개인화되지 않은 템플릿 이미지와 region concept guidance를 입력으로 사용하여 템플릿의 구조적 디테일을 유지하면서 대상 개념의 외형과 스타일을 통합하는 편집된 이미지를 생성한다. 이 융합 방식은 개념 디테일을 특정 공간 영역에 주입하여 생성된 이미지에서 여러 개념을 합성할 수 있도록 하며, 서로 다른 주제에 걸쳐 외형을 혼합하지 않는다.
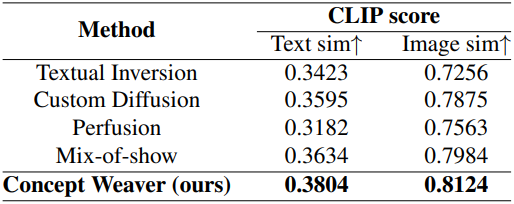
본 논문의 방법인 Concept Weaver는 의미적으로 관련된 개념의 외형을 혼합하지 않고 이미지를 합성할 수 있다. 또한, 두 개 이상의 개념을 원활하게 처리할 수 있으며, 생성된 이미지가 입력 프롬프트의 semantic을 밀접하게 따라 높은 CLIP 점수를 달성하였다. Full fine-tuning과 LoRA 모두에 사용할 수 있으므로 아키텍처에 대한 robustness가 있어 계산 효율성이 더 높다.
Method
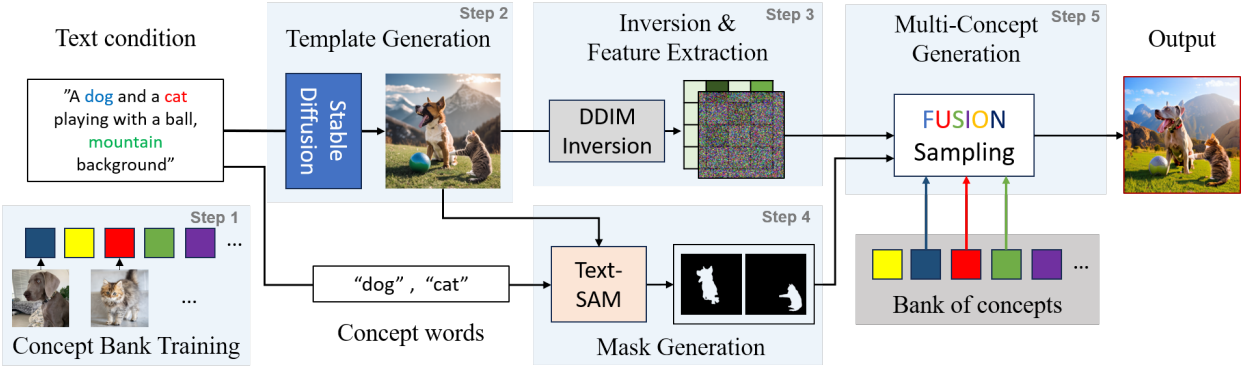
기존 모델은 복잡한 다중 개념 이미지를 생성하는 데 어려움을 겪는다. Concept Weaver는 계단식 생성 프로세스를 사용하여 이를 해결하였다.
- Stage 1: 각 개념에 대하여 T2I 모델을 개인화한다.
- Stage 2: 제공된 프롬프트를 사용하여 T2I 모델이나 실제 소스에서 개인화되지 않은 ‘템플릿 이미지’를 선택한다.
- Stage 3: 템플릿 이미지에서 latent 표현을 추출한다.
- Stage 4: 대상 개념에 해당하는 템플릿 이미지의 특정 영역을 식별하고 분리한다.
- Stage 5: Latent 표현, 타겟 영역, 개인화된 모델을 결합하여 템플릿 이미지를 재구성하고 지정된 개념을 주입한다.
Step 1: Concept Bank Training
이 단계에서는 사전 학습된 T2I 모델을 fine-tuning하여 각 대상 개념을 concept bank에 포함시킨다. 다양한 커스터마이징 전략 중에서 residual network나 self-attention layer를 변경하지 않는 Custom Diffusion을 활용한다. Custom Diffusion은 U-Net 모델 $\epsilon_\theta$의 cross-attention layer만 fine-tuning한다. 구체적으로, 텍스트 조건 $p \in \mathbb{R}^{s \times d}$와 self-attention feature $f \in \mathbb{R}^{(h \times w) \times c}$에 대하여, cross-attention layer는 $Q = W^q f$, $K = W^k p$, $V = W^v p$로 구성된다.
Cross-attention layer의 key와 value 가중치 파라미터 $W^k$와 $W^v$만 fine-tuning한다. 또한 개념 단어 앞에 배치되는 modifier token $[V^\ast]$을 사용한다 (ex. $[V^\ast]$ dog). 방법이 cross-attention layer에만 관련된 경우 임의의 개인화 방법을 통합할 수 있으므로 자연스럽게 효율적인 LoRA 기반 fine-tuning 방법으로 접근 방식을 확장할 수 있다.
Step 2: Template Image Generation
저자들의 핵심 통찰력 중 하나는 다중 개념 생성 프로세스를 계단식으로 연결하는 것이다. 주어진 프롬프트에서 대상 개념으로 커스터마이징할 수 있는 템플릿 이미지에서 시작한다. 템플릿 이미지를 얻기 위해 기존 T2I 모델에 의존할 수 있지만 실제 이미지가 주어진 경우에는 실제 이미지에도 의존할 수 있다. 템플릿 이미지는 프롬프트에서 원하는 특정 배경을 가진 물체를 포함해야 한다. 실제로는 Stable Diffusion XL을 사용하여 템플릿 이미지를 생성한다.
Step 3: Inversion and Feature Extraction
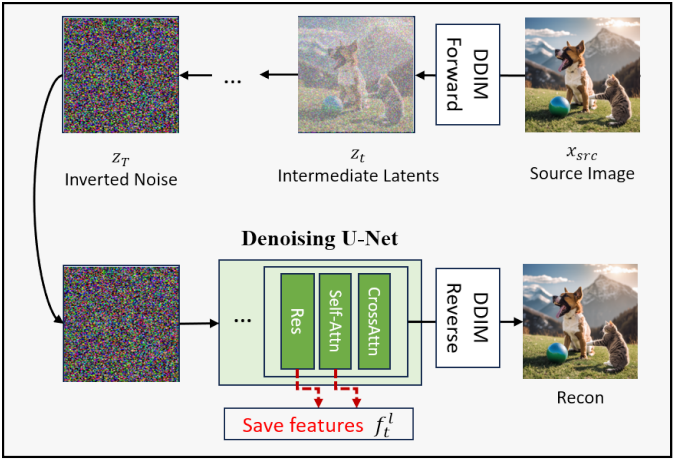
템플릿 이미지를 생성한 후, latent 표현을 얻기 위해 inversion process를 적용한다. 이 단계에서는 plug-and-play diffusion (PNP)에서 제안된 이미지 inversion 및 feature 추출 방식을 차용한다.
구체적으로, 소스 이미지 $x_\textrm{src}$에서 DDIM forward process를 사용하여 noisy latent space $z_T$를 생성한다. $z_T$에서 DDIM reverse process를 사용하여 소스 이미지를 정확하게 재구성할 수 있다. Reverse process 동안 각 timestep $t$에서 U-Net의 $l$번째 layer의 feature $f_t^l$를 추출한다. 이러한 feature에는 residual layer의 중간 출력과 self-attention activation이 포함된다. PNP diffusion에서 제안한 대로, $l = 4$에서 ResNet 출력을 추출하고 $l = 4, 7, 9$에서 self-attention map을 추출한다. Inversion process 동안 레퍼런스 텍스트 조건 $p_\textrm{src}$를 사용한다.
Step 4: Mask Generation
Inversion으로 얻은 latent와 미리 계산된 feature를 통해 후속 생성 프로세스의 구조적 정보를 가이드할 수 있다. 그러나 구조적인 guidance를 사용하면 각 대상 개념의 개념별 편집을 보장할 수 없으며 생성된 이미지는 종종 혼합된 개념을 생성한다. 따라서 템플릿 이미지의 특정 영역에 개인화된 생성 모델을 적용하는 masked guidance를 사용한다.
마스크 영역을 얻기 위해 SAM을 활용한다. 먼저 사전 학습된 Grounding DINO로 주어진 텍스트 프롬프트에 대한 bounding box 영역을 얻는다. 그런 다음 ‘개’, ‘고양이’ 등과 같은 개념별 단어에 해당하는 bounding box 영역을 얻는다. $N$개의 서로 다른 개념에 대해 개념별 마스크 $M_1, \ldots, M_N$을 추출하고 마스킹되지 않은 영역을 배경 마스크 \(M_\textrm{bg} = (M_1 \cup \ldots \cup M_N)^c\)로 설정한다.
저자들은 얻은 dense한 마스크를 직접적으로 사용할 때 최종 출력이 종종 변형된 출력을 생성한다는 것을 발견했다. 따라서 dense한 마스크를 사용하는 대신 dilated mask를 사용한다. 개념의 겹치는 영역 간의 혼동을 방지하기 위해 원래 dense한 마스크를 그러한 겹치는 영역에만 유지한다.
Step 5: Multi-Concept Fusion
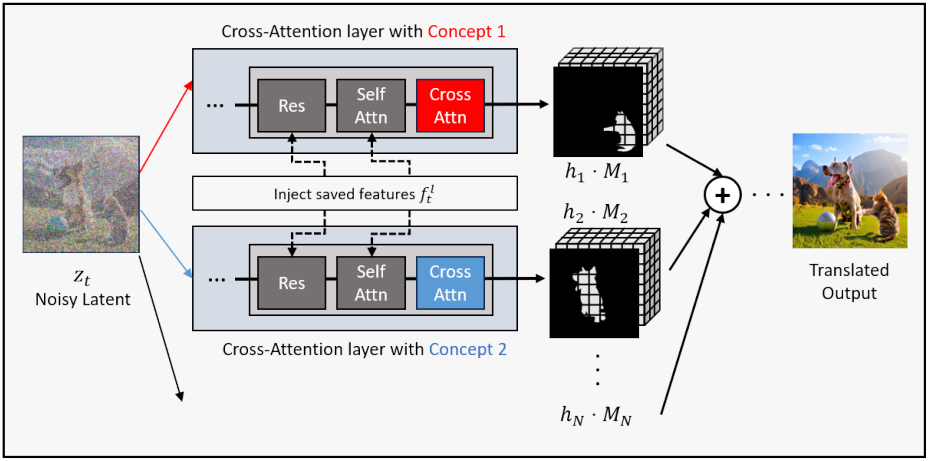
본 논문의 목표는 공동 학습 단계 없이 이미지를 생성하는 것이므로, 통합 샘플링 프로세스에서 단일 개념으로 개인화된 여러 모델을 결합할 수 있는 새로운 샘플링 프로세스를 사용한다.
Noisy latent $z_T$에서 시작하여 latent에서 noise를 제거한다. 구체적으로 fine-tuning된 단일 개념 모델에 대한 파라미터 집합이 이미 포함된 concept bank가 있다고 가정한다. 생성을 위해 $N$개의 개념을 선택하는 경우, 이의 가중치 파라미터를 $\theta_1, \ldots, \theta_N$이라 하자. 또한, 파라미터가 \(\theta_\textrm{bg}\)인 배경 생성을 위한 개념 하나를 선택한다. 선택된 모델을 사용하여 다중 개념 융합 샘플링을 시작한다.
단순한 접근 방식 중 하나는 compositional diffusion과 유사하게 여러 score 추정치를 혼합하는 것이다. 각 timestep $t$에서 하나의 score 추정치는 다음과 같이 표현된다.
\[\begin{equation} \epsilon_\textrm{fuse} = \sum_i^N \epsilon_{\theta_i} (z_t, t, p_{+i}) M_i + \epsilon_{\theta_\textrm{bg}} (z_t, t, p_{+\textrm{bg}}) M_\textrm{bg} \end{equation}\]여기서 \(\epsilon_{\theta_i} (z_t, t, p_{+i})\)는 $i$번째 개념의 모델 출력이고 $M_i$는 각 개념에 해당하는 마스크 영역이다. 그러나 score 추정치를 단순하게 혼합하면 생성된 출력의 개념이 매끄럽게 혼합되지 않기 때문에 성능이 제한적이다.
저자들은 현실적인 개념 융합을 위한 다양한 기술을 도입하여 이 문제를 해결하였다.
첫째, 미리 계산된 feature $f_t^l$를 U-net 모델에 주입한다. 개념과 관련된 파라미터는 cross-attention layer와만 관련이 있으므로 $f_t^l$는 residual layer와 self-attention layer와는 관련이 없다. 따라서 $f_t^l$를 U-net 모델에 주입하면 커스텀 개념의 표현을 저하시키지 않고 전체 샘플링 단계에 통합된 구조적 정보를 제공할 수 있다.
둘째, 모든 네트워크에 동일한 텍스트 조건 입력을 사용하면 심각한 아티팩트가 생성되고 개념 누출 문제가 발생한다. 즉, 개념의 외형이 무차별적으로 섞인다. 따라서 각 개념에 대한 텍스트 컨디셔닝 전략을 사용하며, 텍스트 조건 입력 $p_{+i}$는 단 하나의 modifier token만 포함하는 문장이다.
예를 들어, [c1] dog, [c2] cat, [bg] mountain background을 결합하는 경우 프롬프트는 다음과 같다.
$p_\textrm{base}$ = “A dog and a cat playing with a ball, mountain background”
$p_{+1}$ = “A [c1] dog playing with a ball, mountain background”
$p_{+2}$ = “A [c2] cat playing with a ball, mountain background”
$p_{+\textrm{bg}}$ = “A dog and a cat playing with a ball, [bg] mountain background”
다르게 구성된 텍스트 조건을 통해 타겟 영역에서 개념별 이미지를 샘플링할 수 있다.
셋째, cross-attention layer의 feature space에서 서로 다른 개념을 혼합한다. $i$번째 개념에 대한 파라미터 \(\theta_i\)와 프롬프트 $p_{+i}$를 사용하여 $l$번째 cross-attention layer와 timestep $t$에서 출력 feature $h_i^{l,t}$를 추출할 수 있다. 각 개념에 대해 추출된 feature를 사용하여 다음과 같이 혼합 feature를 계산할 수 있다.
\[\begin{equation} h_\textrm{fuse}^{l,t} = \sum_i^N h_i^{l,t} M_i + h_\textrm{bg}^{l,t} M_\textrm{bg} \end{equation}\]또한 저자들은 샘플링 과정에서 concept-free feature를 제거하기 위한 concept-free suppression 방법을 제안하였다. 구체적으로, 기본 텍스트 조건 $p_\textrm{base}$를 사용하여 fine-tuning되지 않은 모델 \(\epsilon_{\theta_\textrm{base}}\)에서 cross-attention feature \(h_\textrm{base}^{l,t}\)를 계산하고, 다음과 같은 초기 융합 feature를 사용하여 concept-free feature징을 외삽한다.
\[\begin{equation} h_\textrm{fuse}^{l,t} = (1 + \lambda) [ \sum_i^N h_i^{l,t} M_i + h_\textrm{bg}^{l,t} M_\textrm{bg} ] - \lambda h_\textrm{base}^{l,t} \end{equation}\]그런 다음, 다음과 같이 융합된 score 추정치를 계산한다.
\[\begin{equation} \epsilon_\textrm{fuse} = \epsilon_\theta (z_t, t; h_\textrm{fuse}^t; f_t) \end{equation}\]즉, cross-attention layer에서는 융합된 feature \(h_\textrm{fuse}^t\)를 사용하고, self-attention layer와 residual layer에서는 미리 계산된 feature $f_t$를 사용한다.
모델에서 미리 계산된 feature는 이미지의 구조적 측면에만 영향을 미치는 반면, 융합된 feature는 개념별 semantic 정보에만 관여한다. 이러한 명확한 구분은 이 둘 간에 충돌이 없음을 보장한다. 결과적으로, 이 접근 방식은 템플릿 이미지의 전체 구조를 유지하고 동시에 커스텀 개념에 맞춰 물체의 semantic을 변경하는 두 가지 뚜렷한 목표를 효과적으로 달성한다. 이러한 기능을 통해 특정 요구 사항에 따라 이미지를 미묘하고 정확하게 조작할 수 있다.
조건부 score 추정만 사용하면 적절한 생성된 출력을 생성할 수 없다. 따라서 negative prompt 전략을 사용하여 출력 생성 이미지에 negative prompt $p_\textrm{neg}$에 설명된 원치 않는 속성이 포함되지 않도록 한다.
\[\begin{equation} \epsilon = \omega \cdot \epsilon_\textrm{fuse} + (1 - \omega) \cdot \epsilon_{\theta_\textrm{base}} (z_t, t, p_\textrm{neg}; f_t) \end{equation}\]Experiments
- 구현 디테일
- 전체 프로세스는 RTX3090 GPU (VRAM 24GB) 1개에서 약 60초 소요
- Stage 1
- 사전 학습된 Stable Diffusion V2.1에서 fine-tuning 시작
- 각 모델마다 500 step
- learning rate: $1 \times 10^{-5}$
- Step 2
- 모델: Stable Diffusion XL
- 샘플링 step: 50
- 이미지 해상도: 1024$\times$1024
- 실제 이미지를 템플릿 이미지로 사용 가능
- Step 4
- langSAM의 파이프라인을 따름
- Step 3 & 5
- Plug-and-Play diffusion의 공식 소스코드 사용
- backbone: Stable Diffusion V2.1
- 이미지 해상도: 768$\times$768
1. Multi-Concept Generation Results
다음은 여러 개념에 대한 생성 결과를 비교한 것이다.

다음은 더 복잡한 생성 결과이다.

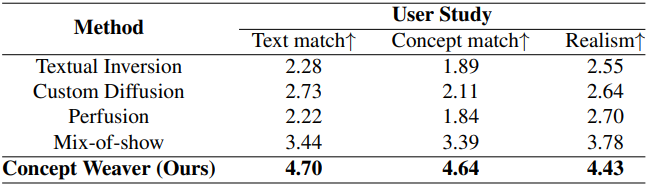
다음은 user study 결과이다.
2. Ablation Study
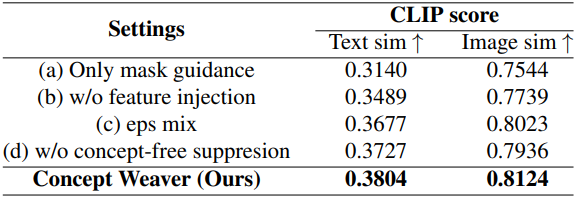
다음은 ablation 결과이다.

3. Applications and Potential Extensions
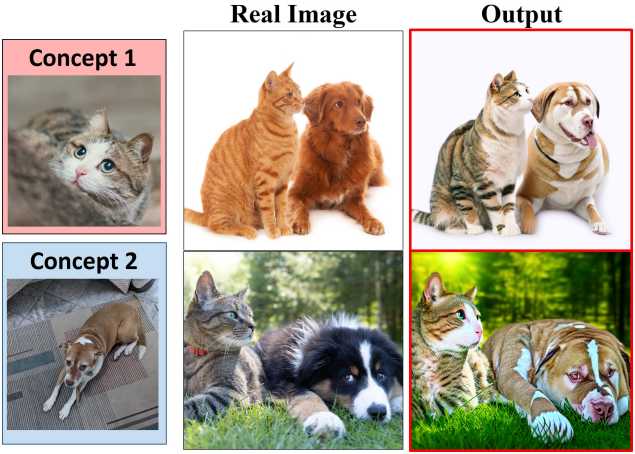
다음은 실제 이미지를 커스터마이징한 예시들이다.
다음은 LoRA fine-tuning으로 확장한 예시이다.
