[논문리뷰] Multi-Concept Customization of Text-to-Image Diffusion (Custom Diffusion)
CVPR 2023. [Paper] [Page] [Github]
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, Jun-Yan Zhu
Carnegie Mellon University | Tsinghua University | Adobe Research
8 Dec 2022

Introduction
최근 출시된 text-to-image 모델은 이미지 생성의 분기점을 나타낸다. 텍스트 프롬프트를 쿼리하기만 하면 사용자는 전례 없는 품질의 이미지를 생성할 수 있다. 이러한 시스템은 다양한 개체, 스타일, 장면을 생성할 수 있으며, 무엇이든 모든 것을 생성할 수 있을 것처럼 보인다.
그러나 그러한 모델의 다양하고 일반적인 능력에도 불구하고 사용자는 종종 자신의 개인 생활에서 특정 개념을 합성하기를 원한다. 예를 들어 가족, 친구, 애완동물과 같은 사랑하는 사람이나 새 소파나 최근에 방문한 정원과 같은 개인적인 물건과 장소는 흥미로운 개념을 만든다. 이러한 개념은 본질적으로 개인적이므로 대규모 모델 학습 중에는 보이지 않는다. 사후에 텍스트를 통해 이러한 개념을 설명하는 것은 다루기 힘들고 충분한 충실도로 개인적인 개념을 생성할 수 없다.
이는 모델 커스텀화에 대한 필요성을 유발한다. 사용자가 제공하는 이미지가 거의 없는 상황에서 기존의 text-to-image diffusion model을 새로운 개념으로 보강할 수 있어야 한다. Fine-tuning된 모델은 일반화하고 기존 개념으로 합성하여 새로운 변형을 생성할 수 있어야 한다. 이는 몇 가지 문제를 제기한다. 첫째, 모델은 기존 개념의 의미를 잊거나 변경하는 경향이 있다. 예를 들어 “moongate” 개념을 추가할 때 “moon”의 의미가 손실된다. 둘째, 이 모델은 소수의 학습 샘플에 overfitting되어 샘플링 변동을 줄이는 경향이 있다.
또한, 저자들은 단일 개별 개념에 대한 튜닝을 넘어 확장하고 여러 개념을 함께 합성하는 능력인 compositional fine-tuning이라는 더 어려운 문제를 연구하였다. 합성 생성의 개선은 최근 연구에서 연구되었다. 그러나 여러 개의 새로운 개념을 합성하는 것은 보지 못한 개념을 혼합하는 것과 같은 추가적인 문제를 야기한다.
본 논문에서는 text-to-image diffusion model을 위한 fine-tuning 기법인 Custom Diffusion을 제안한다. 본 논문의 방법은 계산 및 메모리 효율적이다. 위에서 언급한 문제를 극복하기 위해 모델 가중치의 작은 부분 집합, 즉 텍스트에서 cross-attention 레이어의 latent feature로의 key와 value 매핑을 식별한다. 이를 fine-tuning하면 새 개념으로 모델을 업데이트하기에 충분하다. 모델 망각을 방지하기 위해 타겟 이미지와 유사한 캡션이 있는 작은 실제 이미지 세트를 사용한다. 또한 fine-tuning 중에 augmentation을 도입하여 수렴 속도를 높이고 결과를 개선한다. 여러 개념을 주입하기 위해 동시에 또는 개별적으로 학습한 다음 병합하는 학습을 지원한다.
Method

본 논문의 모델 fine-tuning 방법은 위 그림과 같이 모델의 cross-attention 레이어에서 가중치의 작은 부분 집합만 업데이트한다. 또한 실제 이미지의 정규화 세트를 사용하여 타겟 개념의 몇 가지 학습 샘플에 대한 overfitting을 방지한다.
1. Single-Concept Fine-tuning
사전 학습된 text-to-image diffusion model이 주어지면, 4개의 이미지와 해당 텍스트 설명이 주어진 모델에 새로운 개념을 포함하는 것을 목표로 한다. Fine-tuning된 모델은 텍스트 프롬프트를 기반으로 새로운 개념으로 새로운 생성을 허용하면서 이전 지식을 유지해야 한다. 업데이트된 text-to-image 매핑이 사용 가능한 몇 가지 이미지에 쉽게 overfitting될 수 있으므로 이는 어려울 수 있다.
본 논문에서는 Latent Diffusion Model (LDM)을 기반으로 하는 backbone 모델로 Stable Diffusion을 backbone 모델로 사용한다. LDM은 먼저 인코더-디코더를 실행하여 입력 이미지를 복구할 수 있도록 VAE, PatchGAN, LPIPS의 하이브리드 목적 함수를 사용하여 이미지를 latent 표현으로 인코딩한다. 그런 다음 cross-attention을 사용하여 모델에 텍스트 조건을 주입하여 latent 표현에 대한 diffusion model을 학습한다.
Learning objective of diffusion models
Diffusion model은 원래 데이터 분포 $q(x_0)$와 $p_\theta (x_0)$를 근사화하는 것을 목표로 하는 생성 모델 클래스이다.
\[\begin{equation} p_\theta (x_0) = \int [p_\theta (x_T) \prod p_\theta^t (x_{t-1} \vert x_t)] dx_{1:T} \\ x_t = \sqrt{\alpha_t} x_0 + \sqrt{1 - \alpha_t} \epsilon \end{equation}\]여기서 $x_1$에서 $x_T$는 forward Markov chain의 latent 변수이다. 이 모델은 고정 길이의 (일반적으로 1000) Markov chain의 reverse process를 학습한다. Timestep $t$에서 noisy한 이미지 $x_t$가 주어지면 모델은 $x_{t-1}$을 얻기 위해 입력 이미지의 noise를 제거하는 방법을 학습한다. Diffusion model의 목적 함수는 다음과 같이 단순화할 수 있다.
\[\begin{equation} \mathbb{E}_{\epsilon, x, c, t} [w_t \| \epsilon - \epsilon_\theta (x_t, c, t) \|] \end{equation}\]여기서 $\epsilon_\theta$는 모델 예측이고 $w_t$는 loss에 대한 시간 종속 가중치이다. 모델은 timestep $t$로 컨디셔닝되며 다른 modality $c$ (ex. 텍스트)로 추가로 컨디셔닝될 수 있다. Inference하는 동안 랜덤 가우시안 이미지 (또는 latent) $x_T$는 모델을 사용하여 고정된 timestep에 대해 denoise된다.
Fine-tuning의 목표에 대한 순진한 기준선은 주어진 텍스트-이미지 쌍에 대해 loss를 최소화하기 위해 모든 레이어를 업데이트하는 것이다. 이것은 대규모 모델에 대해 계산적으로 비효율적일 수 있으며 몇 개의 이미지에 대해 학습할 때 쉽게 overfitting으로 이어질 수 있다. 따라서 fine-tuning task에 충분한 최소한의 가중치를 식별하는 것을 목표로 한다.
Rate of change of weights
저자들은 loss를 사용하여 타겟 데이터셋에서 fine-tuning된 모델의 각 레이어에 대한 파라미터의 변화를 분석하였다.
\[\begin{equation} \Delta_l = \frac{\| \theta'_l - \theta_l \|}{\theta_l} \end{equation}\]여기서 \(\theta'_l\)과 $\theta_l$은 레이어 $l$의 업데이트된 파라미터와 사전 학습된 파라미터이다. 이 파라미터는 세 가지 유형의 레이어에서 가져온다.
- Cross-attention (텍스트와 이미지 사이)
- Self-attention (이미지 자체)
- 나머지 파라미터 (convolutional block, normalization layer)
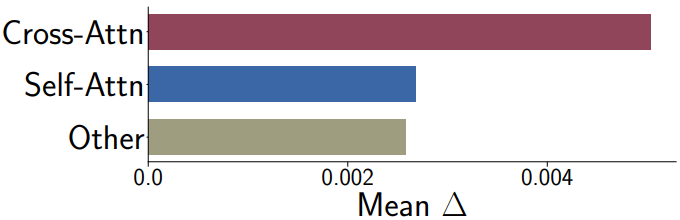
위 그림은 모델이 “moongate” 이미지에서 fine-tuning될 때 세 카테고리에 대한 평균 $\Delta_l$을 보여준다. 다른 데이터셋에 대해서도 유사한 플롯을 관찰할 수 있다. 보다시피 cross-attention 레이어 파라미터는 나머지 파라미터에 비해 상대적으로 높은 $\Delta$를 갖는다. 또한 cross-attention 레이어는 모델의 총 파라미터 수의 5%에 불과하다. 이는 fine-tuning 조정 중에 중요한 역할을 한다는 것을 의미하며 이를 본 논문의 방법에서 활용한다.
Model fine-tuning
Cross-attention 블록은 조건 feature, 즉 text-to-image diffusion model의 경우 텍스트 feature에 따라 네트워크의 latent feature를 수정한다. 주어진 텍스트 feature $c \in \mathbb{R}^{s \times d}$와 latent 이미지 feature $f \in \mathbb{R}^{(h \times w) \times l}$에 대하여, single-head cross-attention 연산은 $Q = W^q f$, $K = W^k c$, $V = W^v c$로 구성되며, value feature에 대한 가중 합으로 계산된다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = \textrm{Softmax} \bigg( \frac{QK^\top}{\sqrt{d'}} \bigg) V \end{equation}\]여기서 $W^q$, $W^k$, $W^v$는 입력을 각각 query feature, key feature, value feature에 매핑하고 $d’$는 key feature와 query feature의 출력 차원이다. 그런 다음 latent feature가 attention 블록 출력으로 업데이트된다. Fine-tuning task는 주어진 텍스트에서 이미지 분포로의 매핑을 업데이트하는 것을 목표로 하며 텍스트 feature는 cross-attention 블록의 $W^k$와 $W^v$에만 입력된다. 따라서 fine-tuning 프로세스 중에 diffusion model의 $W^k$와 $W^v$의 파라미터만 업데이트한다. 이는 새로운 텍스트-이미지 쌍 개념으로 모델을 업데이트하기에 충분하다. 아래 그림은 cross-attention 레이어와 학습 가능한 파라미터의 인스턴스를 보여준다.
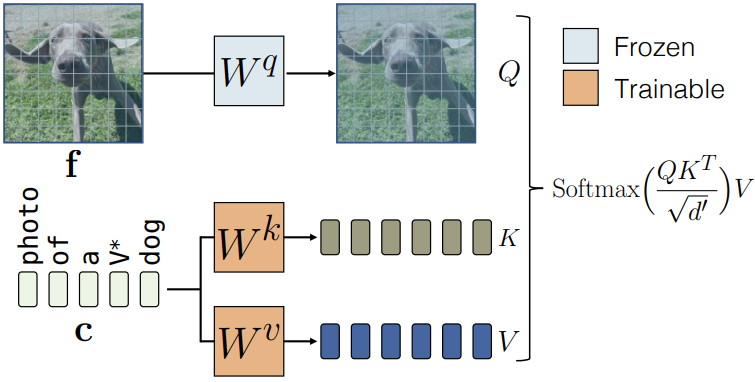
Text encoding
타겟 개념 이미지가 주어지면 텍스트 캡션도 필요하다. 텍스트 설명이 있는 경우 이를 텍스트 캡션으로 사용한다. 타겟 개념이 일반 카테고리의 고유한 인스턴스인 개인화 관련 사용 사례의 경우 (ex. pet dog) 새로운 modifier 토큰 임베딩을 도입한다 ($V^\ast$ dog). 학습 중에 $V^\ast$는 드물게 발생하는 토큰 임베딩으로 초기화되고 cross-attention 파라미터와 함께 최적화된다.
Regularization dataset

타겟 개념과 텍스트 캡션 쌍을 fine-tuning하면 언어 드리프트 문제가 발생할 수 있다. 예를 들어, “moongate”에 대한 학습은 위 그림과 같이 이전에 학습된 시각적 개념과 “moon” 및 “gate”의 연관성을 잊어버리는 모델로 이어질 것이다. 이를 방지하기 위해, LAION-400M 데이터셋에서 타겟 텍스트 프롬프트와 높은 유사도를 가진 캡션을 가진 200개의 정규화 이미지 세트를 선택한다. 이 유사도는 CLIP 텍스트 인코더 feature space에서 0.85 이상의 임계값을 가져야 한다.
2. Multiple-Concept Compositional Fine-tuning
Joint training on multiple concepts
여러 개념으로 fine-tuning하기 위해 각 개별 개념에 대한 학습 데이터셋을 결합하고 본 논문의 방법과 공동으로 학습시킨다. 타겟 개념을 나타내기 위해, 거의 발생하지 않는 서로 다른 토큰으로 초기화된 서로 다른 modifier 토큰 $V_i^\ast$를 사용하고 각 레이어에 대한 cross-attention key 및 value 행렬과 함께 이를 최적화한다. 가중치 업데이트를 cross-attention key 및 value 파라미터로 제한하면 모든 가중치를 fine-tuning하는 DreamBooth와 같은 방법에 비해 두 가지 개념을 합성하는 데 훨씬 더 나은 결과를 얻을 수 있다.
Constrained optimization to merge concepts
본 논문의 방법은 텍스트 feature에 해당하는 key 및 value projection 행렬만 업데이트하므로 이후에 이를 병합하여 여러 fine-tuning 개념으로 생성할 수 있다. 집합 \(\{W_{0, l}^k, W_{0,l}^v\}_{l=1}^L\)을 사전 학습된 모델의 모든 $L$개의 cross-attention 레이어에 대한 key 및 value 행렬이라 하고, 집합 \(\{W_{n, l}^k, W_{n, l}^v\}_{l=1}^L\)을 추가된 개념 \(n \in \{1, \cdots, N\}\)에 해당하는 업데이트된 행렬이라 하자. 후속 최적화가 모든 레이어와 key-value 행렬에 적용되므로 \(\{k, v\}\)와 레이어 $l$을 생략하자. 합성 목적 함수를 다음과 같은 제약 조건이 있는 최소 제곱 문제로 공식화한다.
\[\begin{equation} \hat{W} = \underset{W}{\arg \min} \| WC_\textrm{reg}^\top - W_0 C_\textrm{reg}^\top \|_F \quad \textrm{s.t.} \quad WC^\top = V \\ \textrm{where} \quad C = [c_1 \cdots c_N]^\top \quad \textrm{and} \quad V = [W_1 c_1^\top \cdots W_N c_N^\top]^\top \end{equation}\]여기서 $C \in \mathbb{R}^{s \times d}$는 차원 $d$의 텍스트 feature이다. 이들은 모든 $N$개의 개념에 걸쳐 $s$개의 타겟 단어로 컴파일되며 각 개념에 대한 모든 캡션이 flatten되고 concat된다. 유사하게, $C_\textrm{reg} \in \mathbb{R}^{s_\textrm{reg} \times d}$는 정규화를 위해 1000개의 임의로 샘플링된 캡션의 텍스트 feature로 구성된다. 직관적으로, 위 식은 원래 모델의 행렬을 업데이트하여 $C$의 타겟 캡션에 있는 단어가 fine-tuning된 개념 행렬에서 얻은 값에 일관되게 매핑되도록 하는 것을 목표로 한다. 위의 목적 함수는 $C_\textrm{reg}$가 퇴화되지 않고 솔루션이 존재한다고 가정할 때 Lagrange multipliers를 사용하여 다음과 같이 closed-form으로 풀 수 있다.
\[\begin{equation} \hat{W} = W_0 + v^\top d \\ d = C (C_\textrm{reg}^\top C_\textrm{reg})^{-1} \\ v^\top = (V - W_0 C^\top) (d C^\top)^{-1} \end{equation}\]공동 학습에 비해 이 최적화 기반 방법은 각 개별 fine-tuning 모델이 있는 경우 더 빠르다. 저자들이 제안한 방법은 단일 장면에서 두 가지 새로운 개념의 일관된 생성으로 이어진다.
Experiments
- 데이터셋
- 10가지 타겟 데이터셋 (moongate, barn, tortoise plushy, teddy-bear, wooden pot, dog, cat, flower, table, chair)
- 101개의 개념으로 구성된 CustomConcept101
- 학습 디테일
- Step 수: 단일 개념의 경우 250 step, 이중 개념의 경우 500 step
- Batch size: 8
- Learning rate: 8 \times 10^{-5}
- 0.4배에서 1.4배로 랜덤하게 resize 후 resize 비율에 맞춰 프롬프트 “very small”, “far away”, “zoomed in”, “close up”을 추가
1. Fine-tuning Results
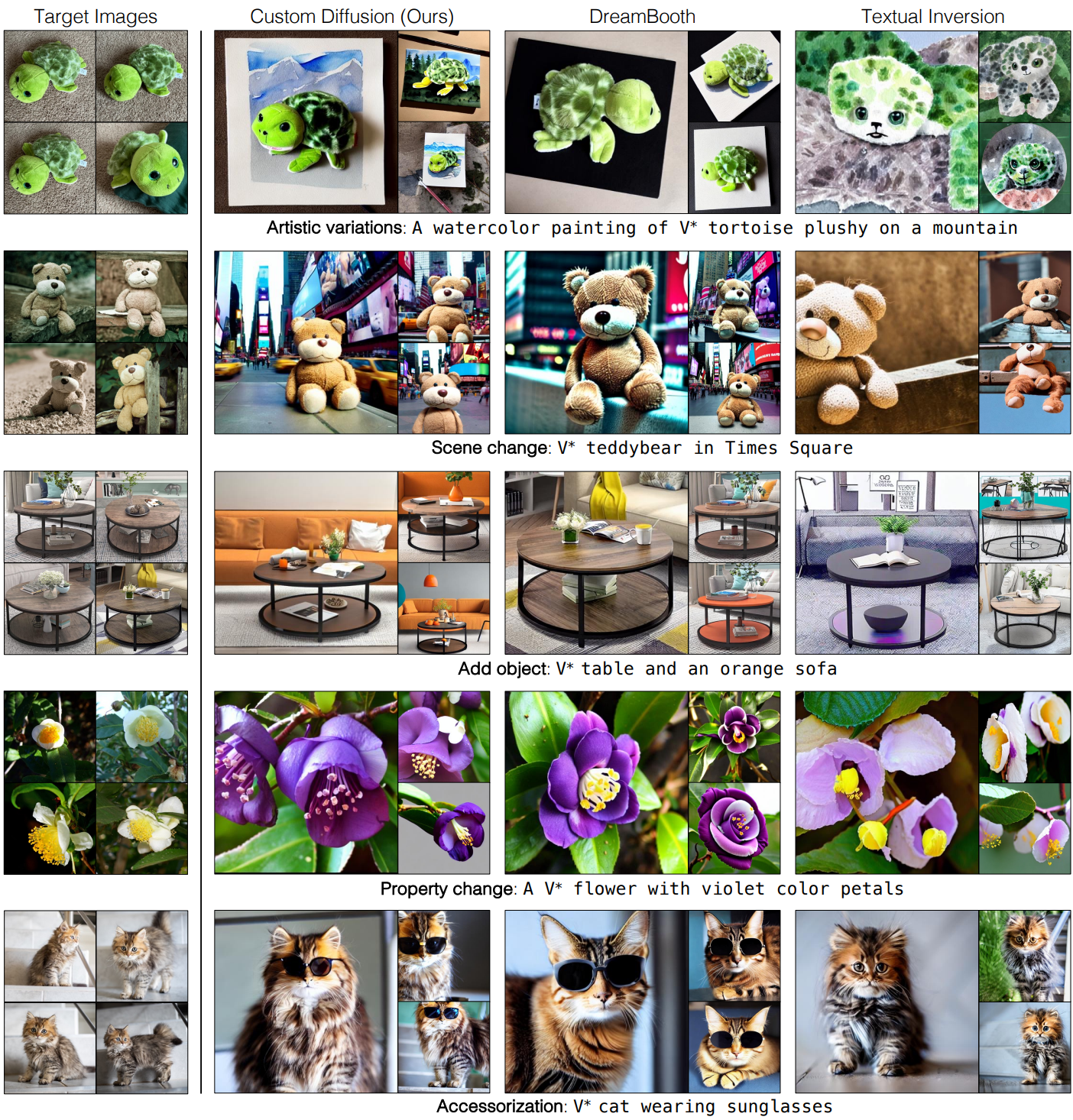
다음은 단일 개념 fine-tuning의 결과이다.
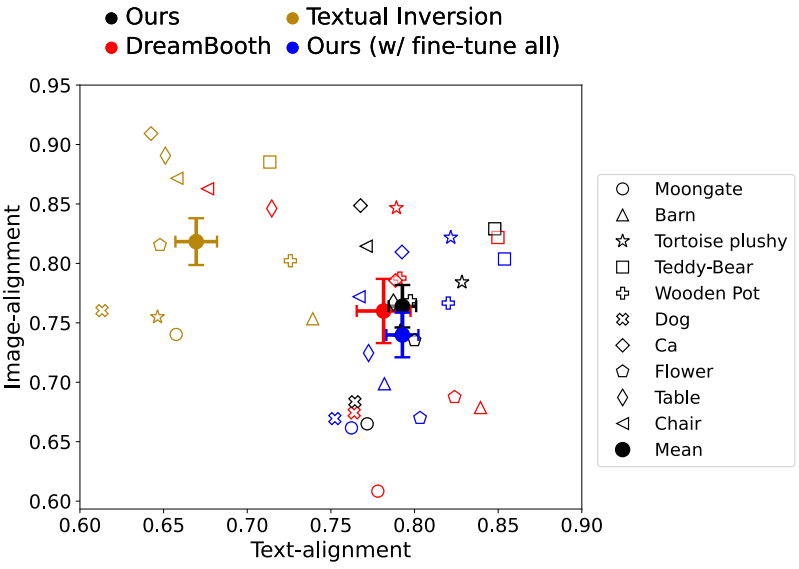
다음은 단일 개념 fine-tuning에 대한 text-alignment와 image-alignment를 비교한 그래프이다.
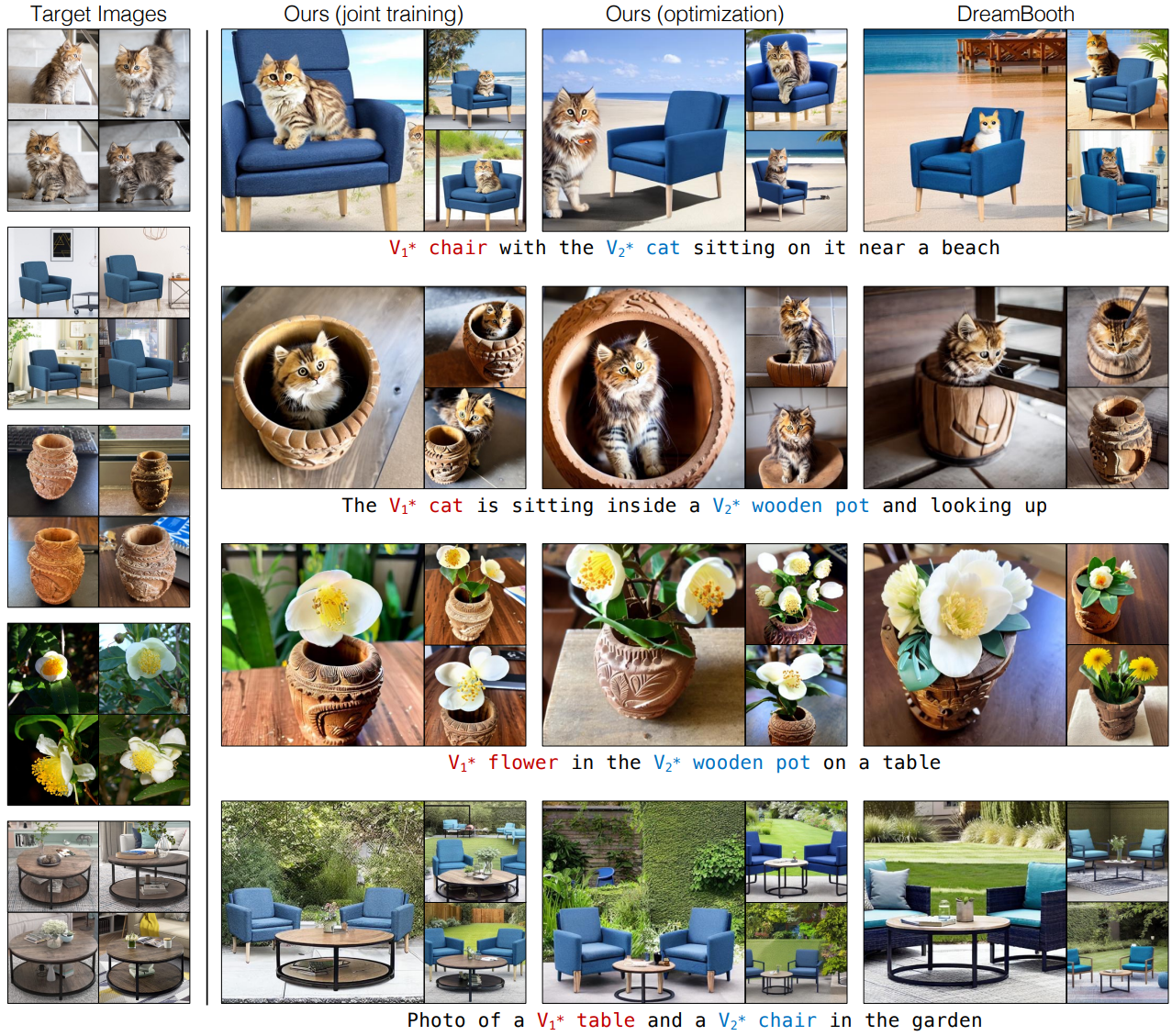
다음은 다중 개념 fine-tuning의 결과이다.
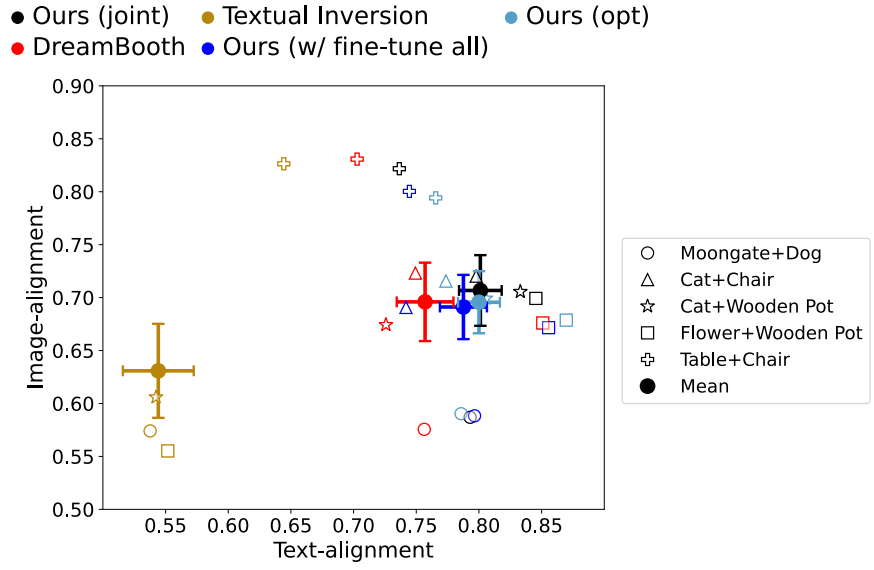
다음은 다중 개념 fine-tuning에 대한 text-alignment와 image-alignment를 비교한 그래프이다.
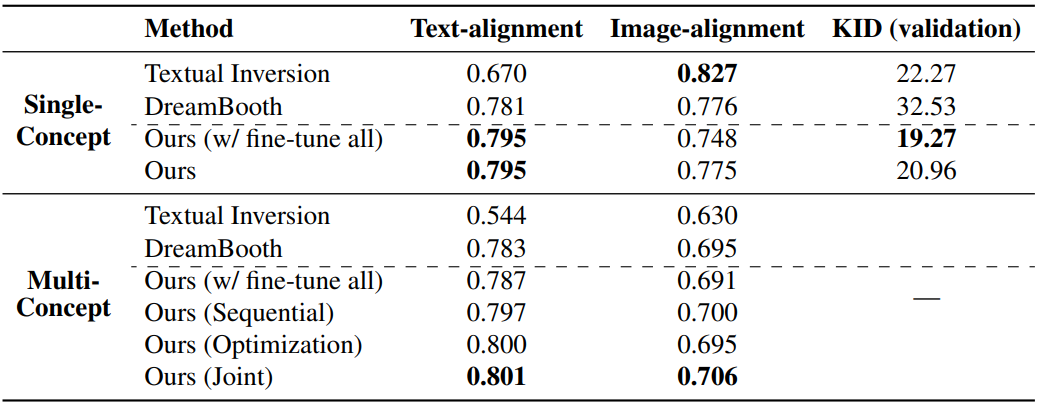
다음은 정량적으로 비교한 표이다.
2. Human Preference Study
다음은 Textual Inversion, DreamBooth와의 선호도를 비교한 표이다.

3. Ablation and Applications
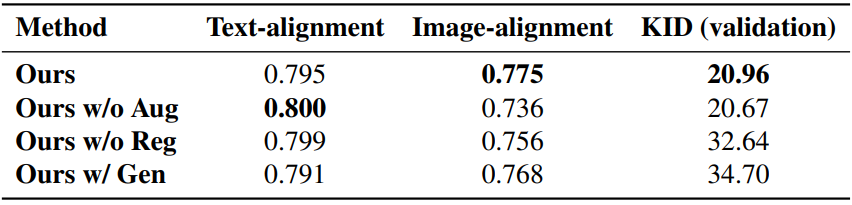
다음은 ablation study 결과이다.
다음은 예술적 스타일에 대한 결과이다.

다음은 Prompt-to-Prompt를 사용한 이미지 편집 결과이다.
