[논문리뷰] CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
ICLR 2025. [Paper] [Github]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Xiaotao Gu, Yuxuan Zhang, Weihan Wang, Yean Cheng, Ting Liu, Bin Xu, Yuxiao Dong, Jie Tang
Zhipu AI | Tsinghua University
12 Aug 2024
Introduction
Diffusion model의 backbone으로 Transformers를 사용함으로써, 즉 Diffusion Transformers (DiT)를 사용함으로써 text-to-video 생성은 획기적인 수준에 도달했다.
DiT의 이러한 빠른 발전에도 불구하고, 장기적으로 일관된 동영상을 생성하는 방법은 기술적으로 불분명하다. 다음과 같은 여러 과제들이 지금까지 대체로 해결되지 않았다.
- 효율적인 동영상 데이터 모델링
- 효과적인 텍스트-동영상 정렬
- 모델 학습을 위한 고품질 텍스트-동영상 쌍 구성
본 논문에서는 길고 시간적으로 일관된 동영상을 생성하도록 설계된 대규모 DiT 모델인 CogVideoX를 소개한다. 위의 과제들을 각각 3D VAE, expert Transformer, 동영상 데이터 필터링 및 captioning 파이프라인을 개발하여 위에서 언급한 과제를 해결하였다.
첫째, 동영상 데이터를 효율적으로 사용하기 위해 공간 차원과 시간 차원을 따라 동영상을 압축하는 3D causal VAE를 설계하고 학습시킨다. 픽셀 공간에서 동영상을 1차원 시퀀스로 펼치는 것과 비교할 때 이 전략은 시퀀스 길이와 계산량을 크게 줄이는 데 도움이 된다. 각 프레임을 개별적으로 인코딩하기 위해 2D VAE를 사용하는 이전 모델들과 달리 3D VAE는 생성된 동영상의 깜빡임을 방지하여 프레임 간의 연속성을 보장힌다.
둘째, 동영상과 텍스트 간의 융합을 용이하게 하기 위해 Expert Adaptive Layernorm을 갖춘 expert Transformer를 사용한다. 동영상 생성에서 시간적 일관성을 보장하고 대규모 모션을 캡처하기 위해 3D full attention을 사용하여 시간 차원 및 공간 차원을 따라 동영상을 종합적으로 모델링한다.
셋째, 온라인에서 제공되는 대부분의 동영상 데이터는 정확한 텍스트 설명이 부족하기 때문에 저자들은 동영상 콘텐츠를 정확하게 설명할 수 있는 동영상 캡셔닝 파이프라인을 개발하였다. 이 파이프라인은 모든 동영상 데이터에 대한 새로운 텍스트 설명을 생성하는 데 사용되며, 이를 통해 CogVideoX가 정확한 semantic을 이해하는 능력이 크게 향상된다.
또한, CogVideoX의 생성 성능과 안정성을 더욱 향상시키기 위해 혼합 길이 학습과 해상도 점진적 학습을 포함한 점진적 학습 기술을 채택하였다. 나아가, 저자들은 각 data parallel rank에 다른 timestep 샘플링 간격을 설정하여 학습 loss 곡선을 안정화하고 수렴을 가속화하는 Explicit Uniform Sampling을 제안하였다.
CogVideoX는 초당 8프레임으로 6초 분량의 720×480 동영상을 생성할 수 있다.
The CogVideoX Architecture
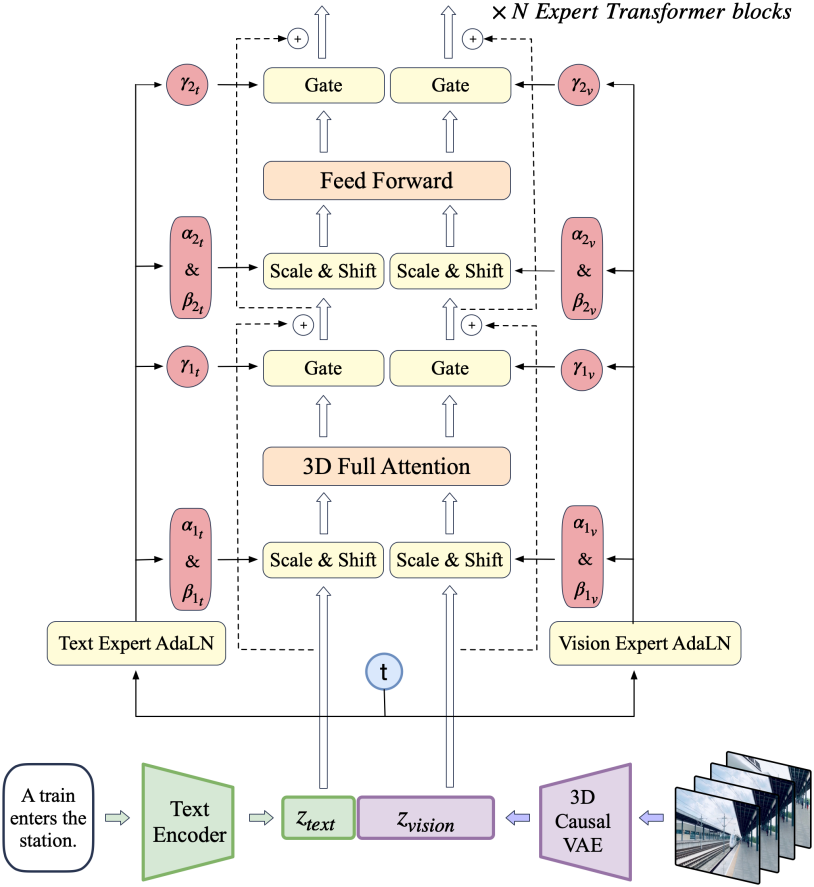
- 동영상과 텍스트 입력이 주어지면, 3D causal VAE로 동영상을 latent space로 압축한다.
- Latent 데이터는 patchify되어 긴 시퀀스 $z_\textrm{vision}$로 펼쳐진다.
- T5를 사용하여 텍스트 입력을 텍스트 임베딩 $z_\textrm{text}$로 인코딩한다.
- $z_\textrm{text}$와 $z_\textrm{vision}$은 시퀀스 차원을 따라 concat된다.
- Concat된 임베딩은 expert transformer block의 스택에 입력된다.
- 모델 출력은 unpatchify되어 원래 latent 모양으로 복원된다.
- 3D causal VAE 디코더를 사용하여 디코딩되어 동영상을 재구성한다.
1. 3D Causal VAE
동영상은 공간 정보뿐만 아니라 상당한 시간 정보도 포함하며, 일반적으로 이미지보다 훨씬 더 많은 데이터 볼륨을 생성한다. 저자들은 동영상 데이터 모델링의 계산적 과제를 해결하기 위해 MAGVIT-v2의 3D VAE를 기반으로 하는 동영상 압축 모듈을 구현하였다. 아이디어는 3D convolution을 통합하여 공간적, 시간적으로 동영상을 압축하는 것이다. 이를 통해 이미지 VAE와 비교했을 때 동영상 재구성의 품질과 연속성이 크게 향상되어 더 높은 압축률을 달성하는 데 도움이 된다.

위 그림은 3D VAE의 구조이며, 인코더, 디코더, latent space regularizer로 구성된다. Gaussian latent space는 KL regularizer에 의해 제한된다. 인코더와 디코더는 대칭적으로 배열된 4개의 stage로 구성되어 있으며, 각각 ResNet block들의 스택으로 2배 다운샘플링 및 업샘플링을 수행한다. 인코더의 처음 두 다운샘플링과 디코더의 마지막 두 업샘플링은 시공간 차원에 모두 적용되는 반면, 인코더의 마지막 다운샘플링과 디코더의 첫 번째 업샘플링느 공간 차원에만 적용된다. 이를 통해 3D VAE는 시간 차원에서 4배, 공간 차원에서 8$\times$8 압축을 달성할 수 있다.
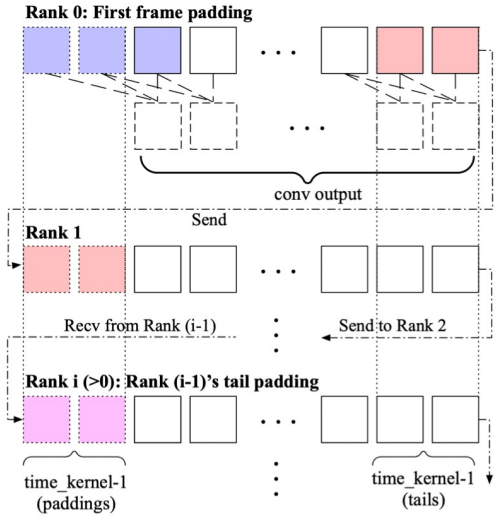
위 그림에 표시된 것처럼 모든 padding을 convolution space의 시작 부분에 두는 temporally causal convolution을 채택한다. 이렇게 하면 미래 정보가 현재 또는 과거 예측에 영향을 미치지 않는다. 프레임 수가 많은 동영상을 처리하면 과도한 GPU 메모리 사용이 발생하므로 3D convolution에 대해 시간 차원에서 context parallelism (CP)을 적용하여 여러 장치에 계산을 분산한다. Convolution의 인과적 특성으로 인해 각 rank는 단순히 길이가 $k-1$인 세그먼트를 다음 rank로 보낸다. ($k$는 temporal kernel size)
실제 구현 시에는 먼저 더 낮은 해상도와 더 적은 프레임에서 3D VAE를 학습시켜 계산을 절약한다. 저자들은 더 높은 해상도의 인코딩이 자연스럽게 일반화되는 반면, 인코딩할 프레임 수를 늘리는 것은 매끄럽게 작동하지 않는다는 것을 관찰하였다. 따라서 짧은 동영상에서 먼저 학습시키고 긴 동영상에서 CP로 fine-tuning하는 2단계 학습 프로세스를 수행한다. 두 단계의 학습 모두 L2 loss, LPIPS perceptual loss, 3D discriminator의 GAN loss를 함께 활용한다.
2. Expert Transformer
Patchify
3D causal VAE는 $T \times H \times W \times C$ 모양의 동영상 latent 벡터를 인코딩한다. 그런 다음 이 latent 벡터를 공간 차원에 따라 patchify하여 길이가 $T \cdot \frac{H}{p} \cdot \frac{W}{p}$인 시퀀스 $z_\textrm{vision}$을 생성한다. 이미지와 동영상의 공동 학습을 위해 시간 차원을 따라 patchify하지 않는다.
3D-RoPE
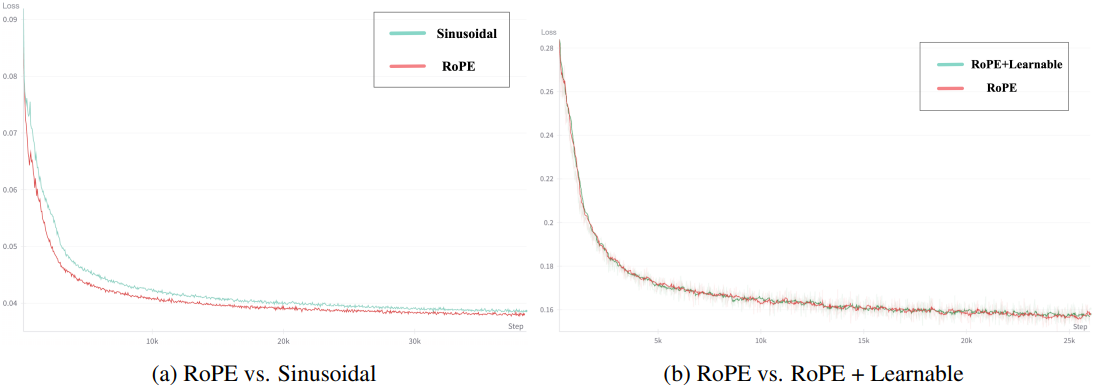
Rotary Position Embedding (RoPE)은 LLM에서 토큰 간 관계를 효과적으로 포착하는 것으로 입증된 상대적 위치 인코딩으로, 특히 긴 시퀀스를 모델링하는 데 탁월하다. 동영상 데이터에 RoPE를 사용하기 RoPE를 3D-RoPE로 확장한다. 동영상 텐서의 각 latent는 3D 좌표 $(x, y, t)$로 표현할 수 있다. 좌표의 각 차원에 1D-RoPE를 독립적으로 적용한 다음 채널 차원을 따라 concat하여 최종 3D-RoPE 인코딩을 얻는다.
Expert Transformer Block
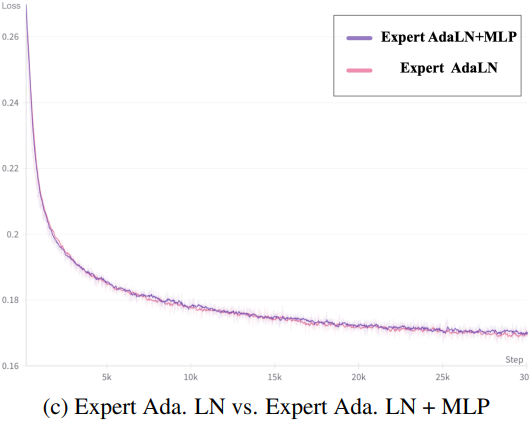
시각적 정보와 semantic 정보를 더 잘 정렬하기 위해 입력 단계에서 텍스트와 동영상의 임베딩을 concat한다. 그러나 이 두 모달리티의 feature space는 상당히 다르며 임베딩의 스케일도 다를 수 있다. 동일한 시퀀스 내에서 더 잘 처리하기 위해 Expert Adaptive Layernorm을 사용하여 각 모달리티를 독립적으로 처리한다.
DiT에 따라 diffusion process의 timestep $t$를 변조 모듈의 입력으로 사용한다. 그런 다음 Vison Expert AdaLN과 Text Expert AdaLN은 이 변조 메커니즘을 각각 vision hidden state와 text hidden state에 적용한다. 이 전략은 추가 파라미터를 최소화하면서 두 feature space의 정렬을 촉진한다.
3D Full Attention

이전 연구에서는 종종 분리된 spatial attention과 temporal attention을 사용하여 계산 복잡도를 줄이고 text-to-image 모델에서 fine-tuning을 용이하게 했다. 그러나 위 그림에서 볼 수 있듯이 이러한 분리된 attention은 광범위한 암시적 시각 정보 전송을 요구하여 학습 복잡도를 크게 증가시키고 크게 움직이는 물체의 일관성을 유지하기 어렵게 만든다.
본 논문은 LLM에서의 long-context training의 성공과 FlashAttention의 효율성을 고려하여 3D 텍스트-동영상 하이브리드 attention 메커니즘을 제안하였다. 이 메커니즘은 더 나은 결과를 얻을 뿐만 아니라 다양한 병렬 가속 방법에 쉽게 적용할 수 있다.
Training CogVideoX
학습 중에 이미지와 동영상을 혼합하여 각 이미지를 단일 프레임 동영상으로 취급한다. 또한, 해상도 관점에서 점진적 학습을 사용한다. Diffusion 설정의 경우, LDM에서 사용되는 noise schedule을 따르는 v-prediction과 zero SNR을 채택한다. 또한 학습 안정성에 도움이 되는 Explicit Timestep Sampling 방법을 사용한다.
1. Frame Pack
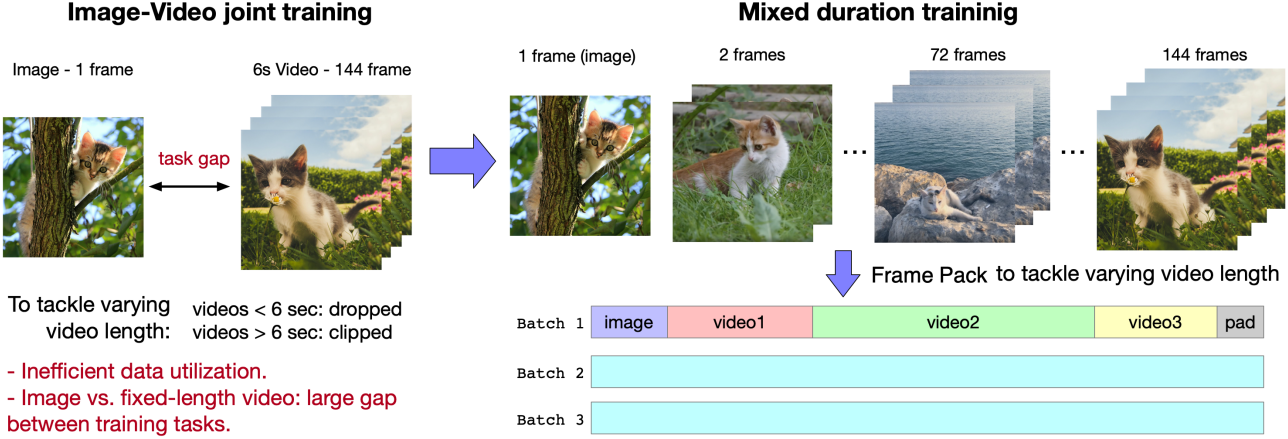
이전 동영상 학습 방법은 종종 고정된 수의 프레임을 가진 이미지와 동영상의 공동 학습을 포함한다. 그러나 이 접근 방식은 일반적으로 두 가지 문제로 이어진다.
- 양방향 attention을 사용하는 두 입력 유형 사이에 상당한 격차가 있으며, 이미지는 한 프레임을 가지고 있는 반면 동영상은 수십 개의 프레임을 가지고 있다. 이런 방식으로 학습된 모델은 토큰 수에 따라 두 가지 생성 모드로 갈라지고 좋은 일반화를 갖지 못하는 경향이 있다.
- 고정된 길이로 학습하려면 짧은 동영상을 버리고 긴 동영상을 잘라야 하며, 이로 인해 다양한 수의 프레임을 가진 동영상을 완전히 활용할 수 없다.
저자들은 이러한 문제를 해결하기 위해 혼합 길이 학습을 선택했다. 즉, 서로 다른 길이의 동영상을 함께 학습시키는 것이다. 그러나 batch 내의 데이터 모양이 일관되지 않아 학습이 어렵다. Patch’n Pack에서 영감을 얻어 서로 다른 길이의 동영상을 동일한 batch에 배치하여 각 batch 내의 모양이 일관되도록 한다. 이 방법을 Frame Pack이라고 한다.
2. Resolution Progressive Training
CogVideoX의 학습 파이프라인은 저해상도 학습, 고해상도 학습, 고품질 동영상 fine-tuning의 세 단계로 나뉜다. 이미지와 마찬가지로 인터넷의 동영상에는 일반적으로 상당한 양의 저해상도 동영상이 포함된다. 점진적 학습은 다양한 해상도의 동영상을 효과적으로 활용할 수 있다. 또한, 처음에 저해상도로 학습시키면 모델에 coarse한 모델링 능력을 제공한 다음 고해상도 학습을 통해 디테일을 포착하는 능력을 향상시킬 수 있다. 직접적인 고해상도 학습과 비교했을 때, 점진적 학습은 전체 학습 시간을 줄이는 데 도움이 될 수도 있다.
Extrapolation of Position Code

저해상도 위치 인코딩을 고해상도로 조정할 때, 저자들은 interpolation과 extrapolation이라는 두 가지 다른 방법을 고려하였다. 위 그림은 두 가지 방법의 효과를 보여준다. Interpolation은 글로벌 정보를 더 효과적으로 보존하는 반면, extrapolation은 로컬한 디테일을 더 잘 유지한다. RoPE가 상대적 위치 인코딩이라는 점을 감안할 때, 저자들은 픽셀 간의 상대적 위치를 유지하기 위해 extrapolation을 선택했다.
High-Quality Fine-Tuning
필터링된 사전 학습 데이터에는 여전히 자막, 워터마크, 낮은 비트레이트 동영상과 같은 일정 비율의 더러운 데이터가 포함되어 있다. 저자들은 최종 단계의 fine-tuning을 위해 전체 데이터셋의 20%를 차지하는 더 높은 품질의 동영상 데이터 부분집합을 선택했다. 이 단계에서는 생성된 자막과 워터마크를 효과적으로 제거하고 시각적 품질을 약간 개선했다. 그러나 모델의 semantic 능력이 약간 저하되었다.
3. Explicit Uniform Sampling
DDPM에서는 loss를 다음과 같이 정의한다.
여기서 $t$는 1과 $T$ 사이에 균일하게 분포된다. 일반적인 관행은 데이터 병렬 그룹의 각 rank에 대해 1과 $T$ 사이의 값을 균일하게 샘플링하는 것이며, 이는 이론적으로 위 식과 동일하다. 그러나 실제로 이러한 랜덤 샘플링에서 얻은 결과는 종종 충분히 균일하지 않으며, loss의 크기는 timestep과 관련이 있으므로 loss에 상당한 변동이 발생할 수 있다.
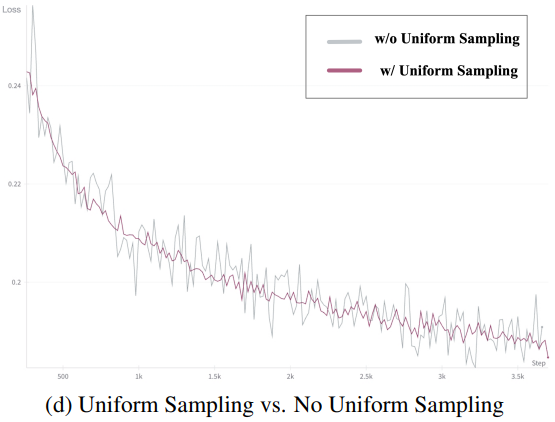
따라서 본 논문은 Explicit Uniform Sampling을 사용하여 1에서 $T$까지의 범위를 $n$개의 간격으로 나누는 것을 제안하였다. 여기서 $n$은 rank의 개수이다. 그런 다음 각 rank는 해당 간격 내에서 균일하게 샘플링한다. 이 방법은 timestep의 보다 균일한 분포를 보장한다. Explicit Uniform Sampling으로 학습한 loss 곡선은 눈에 띄게 더 안정적이다.
또한, 저자들은 Explicit Uniform Sampling을 사용한 후 모든 timestep에서의 loss가 더 빨리 감소하는 것을 발견했는데, 이는 이 방법이 loss 수렴을 가속화할 수 있음을 나타낸다.
4. Data
저자들은 동영상 필터와 recaptioning 모델을 통해 텍스트 설명이 있는 비교적 고품질의 동영상 클립 컬렉션을 구성하였다. 필터링 후 약 3,500만 개의 클립이 남으며, 각 클립의 평균 길이는 약 6초이다.
동영상 필터링
동영상 생성 모델은 세상의 동적 정보를 학습해야 하지만, 필터링되지 않은 동영상 데이터는 주로 두 가지 이유로 노이즈가 심하다.
- 동영상은 인간이 만든 것이므로 인위적인 편집으로 인해 실제 동적 정보가 왜곡될 수 있다.
- 카메라 흔들림이나 열악한 장비 등의 촬영 중 문제로 인해 동영상 품질이 크게 떨어질 수 있다.
저자들은 동영상의 본질적인 품질 외에도 동영상 데이터가 모델 학습을 얼마나 잘 지원하는지도 고려하였다. 결과적으로 다음과 같은 일련의 부정적인 레이블을 정의했다.
- 편집 영상: 재편집이나 특수효과 등 명백히 인위적인 처리를 거친 영상.
- 모션 연결 부족: 이미지 전환이 일어나고 모션 연결이 부족한 영상. 일반적으로 이미지를 인위적으로 이어붙이거나 편집한 영상.
- 저품질: 영상이 선명하지 않거나 카메라 흔들림이 심한 엉성한 촬영 영상.
- 강의 영상: 교육 콘텐츠, 강의, 라이브 스트리밍 토론 등 적은 동작으로 지속적으로 대화하는 사람에 주로 초점을 맞춘 영상.
- 텍스트가 지배적인 영상: 눈에 보이는 텍스트가 상당히 많거나 주로 텍스트 콘텐츠에 초점을 맞춘 영상.
- 노이즈가 많은 영상: 휴대전화나 컴퓨터 화면에서 녹화된 노이즈가 많은 영상.
저자들은 20,000개의 동영상 데이터 샘플을 샘플링하고 각각에 부정적인 태그가 있는지에 대한 레이블을 붙였다. 그런 다음 이러한 주석들을 사용하여 Video-LLaMA에 기반한 여러 필터를 학습시켜 저품질 동영상 데이터를 걸러냈다.
또한, 모든 학습 동영상의 optical flow 점수와 이미지 미적 점수를 계산하고, 학습 중에 threshold 범위를 동적으로 조정하여 생성된 동영상의 유동성과 미적 품질을 보장한다.
동영상 캡션
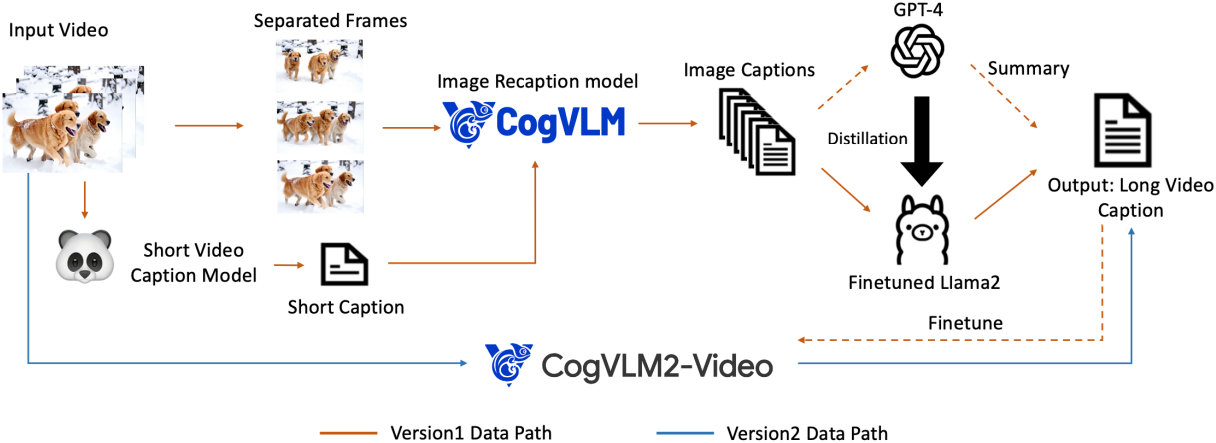
일반적으로 대부분의 동영상 데이터에는 텍스트 설명이 제공되지 않으므로 동영상 데이터를 텍스트 설명으로 변환하여 text-to-video 모델에 필수적인 학습 데이터를 제공해야 한다. 현재 Panda70M, COCO Caption, WebVid와 같은 일부 동영상 캡션 데이터셋이 있지만, 캡션은 일반적으로 매우 짧고 동영상의 콘텐츠를 포괄적으로 설명하지 못한다.
저자들은 고품질 동영상 캡션 데이터를 생성하기 위해 Dense Video Caption Data Generation 파이프라인을 구축하였다. 아이디어는 이미지 캡션에서 동영상 캡션을 생성하는 것이다.
- 동영상 captioning 모델인 Panda70M을 사용하여 동영상에 대한 짧은 캡션을 생성한다.
- 그런 다음 이미지 recaptioning 모델 CogVLM을 사용하여 동영상 내 각 프레임에 대한 고밀도 이미지 캡션을 만든다.
- GPT-4를 사용하여 모든 이미지 캡션을 요약하여 최종 동영상 캡션을 생성한다.
- 이미지 캡션에서 동영상 캡션으로의 생성을 가속화하기 위해 GPT-4에서 생성된 요약 데이터를 사용하여 Llama 2 모델을 fine-tuning하여 대규모 동영상 캡션 데이터 생성을 가능하게 한다.
위의 파이프라인은 CogVideoX 모델을 학습하는 데 사용되는 캡션 데이터를 생성한다. 동영상 recaptioning을 더욱 가속화하기 위해, 앞서 언급한 파이프라인에서 생성된 고밀도 캡션 데이터를 사용하여 CogVLM2-Video와 Llama 3를 기반으로 하는 end-to-end 동영상 이해 모델 CogVLM2-Caption을 fine-tuning한다. CogVLM2-Caption에서 생성된 동영상 캡션 데이터는 차세대 CogVideoX를 학습하는 데 사용된다.
Empirical Evaluation
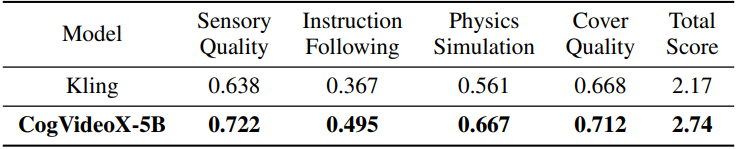
1. Automated Metric Evaluation
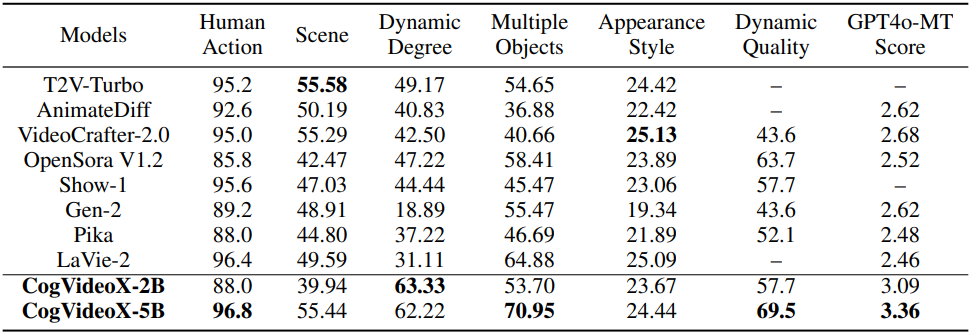
2. Human Evaluation