[논문리뷰] Aligning and Prompting Everything All at Once for Universal Visual Perception
CVPR 2024. [Paper] [Github]
Yunhang Shen, Chaoyou Fu, Peixian Chen, Mengdan Zhang, Ke Li, Xing Sun, Yunsheng Wu, Shaohui Lin, Rongrong Ji
Tencent Youtu Lab | School of Computer Science and Technology | East China Normal University| Key Laboratory of Multimedia Trusted | Xiamen University
4 Dec 2023
Introduction
LLM이 입증한 강력한 transfer 능력을 고려하여 많은 연구들은 범용적인 vision task를 수행하기 위해 고급 vision foundation model (VFM)을 구축하려고 시도했다.
일반적으로 기존 VFM은 크게 세 가지 그룹으로 분류된다.
- DINO나 iBOT과 같이 self-supervised learning을 통해 visual feature를 학습하고, CLIP과 같은 weakly-supervised learning으로 텍스트-이미지를 정렬하는 것이다. 이 방법들은 downstream task를 위한 개별 어댑터가 필요한 경우가 많다.
- GLIP, UNINEXT, GroundingDINO와 같이 인스턴스 인식 작업에 대한 영역 및 텍스트 표현을 정렬한다. 문제를 region-word fusion을 통한 visual grounding 문제로 공식화하기 때문에 한 번에 많은 수의 카테고리와 문구에 대해 사용할 수 없다.
- SAM, X-Decoder, OpenSeeD, SEEM과 같이 일반적인 segmentation task에 중점을 둔다. 그러나 전경 물체는 object-level instance segmentation을 수행하는 반면 배경 물체는 class-level semantic segmentation에 해당하기 때문에 일반적으로 전경 물체와 배경 물체 사이의 세분성 불일치로 인해 어려움을 겪는다.
위의 문제를 해결하는 VFM을 개발하기 위해 본 논문에서는 효율적이고 프롬프팅 가능한 인식 모델을 탐색하고 detection, segmentation, grounding에 대한 다양한 semantic 개념을 처리하였다. Vision-language fusion의 막대한 계산 비용을 해결하기 위해 gated cross-modality intersection을 통해 간결한 문장 표현을 집계하고 어휘 및 문장의 개념을 공통 embedding space에 효율적으로 적용한다.
또한 전경 물체와 배경 물체의 세분성 불일치를 해결하기 위해 category-level segmentation을 instance-level 목적 함수로 분해하여 하나의 instance segmentation task로 구성함으로써 세분성을 균등화한다. 그런 다음 inference 중에 instance-level 패턴을 category-level로 다시 projection할 준비가 된다. 전경과 배경 사이의 불일치를 제거함으로써 thing과 stuff를 수동으로 구별하지 않고 학습한다.
이를 위해 본 논문은 instance-level의 영역-문장 상호 작용과 매칭 패러다임을 통해 foundation vision task를 수행하는 인식 모델인 APE를 제안하였다. APE는 세 가지 관점에서 실제 시나리오에서 APE의 실용성을 극대화하는 몇 가지 중요한 능력을 가진다.
- Task 일반화: DETR 프레임워크를 기반으로 구축되어 모든 물체, 영역, 부분에 대한 레이블, bounding box, 마스크의 예측을 수행한다.
- 데이터 다양성: Object detection, segmentation, visual grounding을 포함하는 광범위한 데이터 소스에 대해 한 번에 학습된다.
- 효과적인 프롬프팅: Word-level 프롬프트 임베딩으로 집계되는 vocabulary 및 문장 설명에 대한 수천 개의 텍스트 프롬프트로 쿼리하는 것이 가능하다.
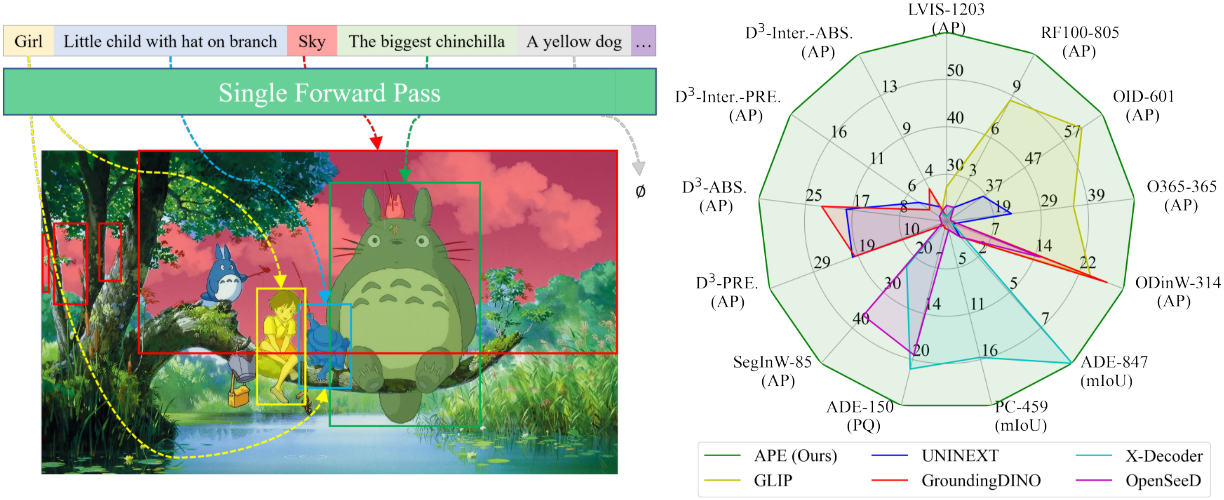
APE는 160개 이상의 데이터셋을 기반으로 한 다양한 시각적 인식 task에서 하나의 모델로 SOTA 또는 경쟁력 있는 성능을 달성하였다. 이를 통해 VFM으로서의 APE의 일반화와 실용성이 입증되었다.
Method

APE는 이미지 feature 추출을 위한 vision backbone, 텍스트 feature 추출을 위한 언어 모델, cross-modality fusion을 적용한 trasnformer 인코더 및 디코더로 구성된다. APE는 주어진 이미지에 대한 일련의 점수, 박스, 마스크와 많은 수의 vocabulary와 문장을 포함할 수 있는 프롬프트 집합을 출력해야 한다.
이를 위해 먼저 비전-언어 상호 작용을 효율적으로 수행하기 위해 컴팩트한 텍스트 임베딩을 구성한다. 이를 통해 한 번의 forward pass에서 대규모 개념을 APE에 표시할 수 있다. 그런 다음 class-level 학습을 object-level 목적 함수로 분해하여 전경 물체와 배경 물체의 세분성을 균등화한다. 마지막으로, 공개적으로 사용 가능한 detection, segmentation, grounding 데이터를 수집하여 vision-language alignment를 진행한다.
1. Description Prompting at Scale
최근 많은 통합 학습 패러다임이 detection 및 grounding 데이터를 동시에 학습시켜 다양한 object-level 인식 task에 대한 강력한 transfer 능력을 보여주었다. 이전 연구들에서는 region classifier를 word-region alignment로 대체하여 object detection을 grounding으로 재구성했다. 그러나 이러한 방식은 텍스트 프롬프트에서 수천 개의 토큰을 사용한 확장이 어렵다. 주된 이유는 두 가지이다.
- 최대 512개의 토큰을 포함하는 문장만 인코딩할 수 있는 BERT와 같은 양방향 언어 모델을 사용한다.
- 고차원의 단어와 영역 간에 cross-modality multi-head attention을 수행하기 위해 vision-language fusion에 크게 의존하고 있으며 계산 비용이 많이 든다.
실용적인 해결 방법은 긴 텍스트 프롬프트를 여러 프롬프트로 분할하고 모델을 여러 번 쿼리하는 것이다. 그러나 이러한 해결 방법은 본질적인 문제를 해결하지 못한다.
본 논문은 많은 수의 vocabulary와 문장을 동시에 효율적으로 유도하기 위해 object detection을 grounding 문제로 재구성하는 패러다임을 뒤집었다. 오히려 두 task를 동일하게 통합하기 위해 visual grounding을 object detection으로 재구성하였다. 이를 바탕으로 저자들은 텍스트 프롬프트, cross-modality fusion, vision-language alignment 전략을 다시 설계하였다.
Independent Prompt
이전 방법들은 물체의 클래스가 주어지면 모든 vocabulary를 하나의 프롬프트로 연결하였다.
“Girl. Sky. …”
해당 개념 임베딩은 문장의 다른 단어와의 관계를 기반으로 모델링된다. 전체 프롬프트 임베딩 \(P_\textrm{voc} \in \mathbb{R}^{1 \times l \times d}\)는 시퀀스 길이가 $l$이고 임베딩 차원이 $d$이다. 마찬가지로 $n$개의 문장 설명에 대한 프롬프트들에서 임베딩 $P_\textrm{sen} \in \mathbb{R}^{n \times l \times d}$를 얻는다.
Vocabulary 간의 상관관계가 필요하지 않으며 개별 개념을 모델링하는 것만으로도 다양한 케이스를 식별하는 데 충분하다. 따라서 vocabulary나 문장의 개별 개념을 독립적인 텍스트 프롬프트로 혼합하여 텍스트 임베딩을 계산한다. 따라서 다음과 같이 텍스트 프롬프트 집합을 구성한다.
[“Girl”, “Sky”, “Little child with hat on branch”, “The big chinchilla”, …]
여기서 개념의 수는 텍스트 모델의 입력 시퀀스 길이에 의해 제한되지 않는다. 이러한 프롬프트들은 CLIP이나 Llama와 같은 방향성 언어 모델에 직접 입력되어 $n$개의 독립적인 텍스트 프롬프트에 대해 프롬프트 임베딩 \(\{P_\textrm{voc}, P_\textrm{sen}\} \in \mathbb{R}^{n \times l \times d}\)를 얻는다.
Sentence-level Embeddings
계산 복잡도와 메모리 사용량을 줄이기 위해 word-level 표현을 sentence-level 프롬프트 임베딩으로 더욱 압축한다. 구체적으로 word-level 임베딩 \(\{P_\textrm{voc}, P_\textrm{sen}\}\)에 대하여 시퀀스 길이 차원에 평균을 취해 sentence-level 임베딩 \(\{\bar{P}_\textrm{voc}, \bar{P}_\textrm{sen}\} \in \mathbb{R}^{n \times d}\)로 집계한다.
\[\begin{equation} \bar{P}_{n, d} = \frac{1}{l} \sum_{j=0}^l P_{n,j,d} \end{equation}\]Word-level 프롬프트 임베딩이 더 세분화된 정보를 가질 수 있지만 sentence-level 프롬프트 임베딩이 비슷한 성능을 제공한다고 한다.
Gated Cross-modality Interaction
원래의 융합에는 일반적으로 학습해야 할 vocabulary가 수천 개 있는 open-vocabulary detection을 위한 multi-head attention이 포함된다. 저자들은 vision-language fusion에서 다양한 유형의 프롬프트를 제한하기 위해 gated cross-modality intersection을 제안하였다.
이미지 feature와 대규모 vocabulary 간의 상호작용에는 엄청나게 많은 비용이 든다. 대신, all-zero 토큰 \(\bar{P}_\textrm{zero} \in \mathbb{R}^{1 \times 1 \times d}\)는 주어진 모든 vocabulary에 대한 특수 텍스트 임베딩 및 입력 역할을 한다. 비전 feature에 언어 정보가 주입되지 않으므로 융합 프로세스가 정적이다. \(\bar{P}_\textrm{zero}\)는 기본 개념을 인식하고 비전 feature \(\hat{V}_\textrm{voc}\)를 약간 튜닝하고 원래 언어 feature \(\bar{P}_\textrm{voc}\)을 유지하기 위한 명시적인 명령을 제공할 수 있다. 문장 프롬프트의 경우 \(\bar{P}_\textrm{sen}\)이 비전 feature $V$에 주입되어 새로운 비전 feature \(\hat{V}_\textrm{sen}\)와 언어 feature \(\hat{P}_\textrm{sen}\)을 동적으로 업데이트한다.
제안된 gated fusion은 두 가지 장점이 있다.
- 학습 및 inference 중에 수천 개의 카테고리를 모델링하고 단 한 번의 forward pass만으로 수백 개의 grounding 문장을 융합하는 것이 가능하다.
- 이전 연구들에서는 융합 모듈을 사용한 detection 데이터의 학습이 새로운 카테고리에 대한 zero-shot 일반화를 손상시킬 수 있음을 보여주었다. Gated intersection은 detection을 위한 융합을 명시적으로 금지함으로써 이러한 퇴화를 방지한다.
Region-sentence Alignment
MDETR은 텍스트 프롬프트에서 각 물체를 참조하는 토큰들의 범위를 예측하였다. 이를 word-region alignment라고 한다. 실용적인 관점에서 보면 프롬프트의 각 단어를 감지할 필요가 없을 수도 있다. 대신 본 논문에서는 카테고리나 문장인 전체 프롬프트에 해당하는 개체를 예측한다.
구체적으로, 물체 임베딩 $\hat{O}$와 프롬프트 임베딩 \(\{\bar{P}_\textrm{voc}, \bar{P}_\textrm{sen}\}\) 사이의 정렬 점수 $S$를 다음과 같이 계산한다. ‘
\[\begin{equation} S = \hat{O} \cdot (\bar{P}_\textrm{voc}, \bar{P}_\textrm{sen})^\top \in \mathbb{R}^{n \times m} \end{equation}\]제안된 gated cross-modality intersection에서는 vocabulary의 프롬프트 임베딩이 업데이트되지 않기 때문에 detection 카테고리는 비전-언어 공통 embedding space의 고정 앵커이다.
Sentence-level 임베딩에서 세밀한 정보의 손실을 보상하기 위해 관련 없는 추가 프롬프트를 negative query로 적용하여 모델이 대상 프롬프트를 면밀히 살펴보고 negative를 거부하도록 한다. 구체적으로, history embedding bank를 유지하고 여러 임베딩을 negative로 선택한 후 positive embedding과 concatenate한다.
2. Thing-stuff-equalizing Alignment
MaskFormer와 Mask2Former는 쿼리 기반 transformer 아키텍처로 thing과 stuff에 대한 segmentation task를 통합하고 mask classification을 수행하였지만, detection 성능이 만족스럽지 않다. 반면에 MaskDINO는 Mask2Former의 mask classification 아이디어를 채택하여 DINO에 segmentation branch를 구성하였다. 그러나 MaskDINO는 thing과 stuff를 두 그룹으로 나누어 수동으로 식별해야 한다. 따라서 일반적인 segmentation 데이터를 SA-1B와 같은 클래스에 구애받지 않는 대규모 데이터와 통합하는 것은 어렵다.
이를 위해 저자들은 배경의 세분성이 전경의 세분성과 동일해지는, 즉 모델이 thing과 stuff의 차이를 인식하지 못하는 간단한 방법을 설계했다. Stuff 카테고리가 instance-level 예측을 잘못 유도할 수 있기 때문에 stuff 영역은 연결이 끊긴 여러 인스턴스로 합성되며, 이는 독립적인 샘플로 처리되고 object-level 목적 함수로 정렬된다.
학습 중에 연결된 성분의 부분 집합이 GT 인스턴스인 stuff 마스크 주석에 connected-component labeling을 적용한다. Inference의 경우 동일한 stuff 카테고리의 모든 예측을 최종 결과와 결합한다. 예측 점수 $S \in \mathbb{R}^{q \times c}$와 마스크 $M \in \mathbb{R}^{q \times h \times w}$가 주어지면 최종 semantic mask $\hat{M} \in \mathbb{R}^{c \times h \times w}$는 다음과 같이 누적된다.
\[\begin{equation} \hat{M}_{c,h,w} = \sum_{i=1}^q S_{i,c} M_{i,h,w} \end{equation}\]여기서 $q$와 $c$는 각각 쿼리와 카테고리의 수이다.
3. Single-Stage Training with Diversity Data
Training Objective
다양한 task를 동시에 해결하는 foundation model을 구축하기 위해 task별 fine-tuning 없이 단일 단계로 학습된다. 목적 함수는 각각 인코더와 디코더에 대한 classification loss, localization loss, segmentation loss의 선형 결합이다.
\[\begin{equation} \mathcal{L} = \underbrace{\mathcal{L}_\textrm{class} + \mathcal{L}_\textrm{bbox} + \mathcal{L}_\textrm{giou}}_{\textrm{encoder and decoder}} + \underbrace{\mathcal{L}_\textrm{mask} + \mathcal{L}_\textrm{dice}}_{\textrm{last layer of decoder}} \end{equation}\]\(\mathcal{L}_\textrm{class}\)는 인코더의 전경 및 배경 영역을 분류하고 디코더의 언어 및 비전 임베딩을 정렬하기 위한 focal loss이다. \(\mathcal{L}_\textrm{bbox}\)와 \(\mathcal{L}_\textrm{giou}\)는 box regression에 대한 L1 loss와 GIOU loss이다. \(\mathcal{L}_\textrm{mask}\)와 \(\mathcal{L}_\textrm{dice}\)는 마스크 segmentation을 위한 cross-entropy loss와 dice loss로, 디코더의 마지막 출력에만 적용된다.
Training Data
APE를 다양한 주석 유형을 가진 10개의 데이터셋으로 학습시킨다.
- Objective detection: MS COCO, Objects365, OpenImages, long-tailed LVIS
- Image segmentation: MS COCO, LVIS, SA-1B
- Visual grounding: Visual Genome, RefCOCO/+/g, GQA, Flickr30K, PhraseCut
저자들은 다양한 데이터를 처리하고 단일 단계 학습을 위해 다중 데이터셋과 다중 task 학습에 대한 세 가지 원칙을 제안하였다.
- 주석이 잘 달린 detection 및 segmentation 데이터는 모든 classification loss, localization loss, 픽셀 수준의 주석이 있는 경우 segmentation loss까지 학습하는 데 사용된다.
- LVIS나 OpenImages와 같은 federated dataset의 경우 federated loss는 디코더의 \(\mathcal{L}_\textrm{class}\)에 통합된다.
- SA-1B의 경우 디코더의 \(\mathcal{L}_\textrm{class}\)를 학습하는 데 사용하지 않는다.
- Grounding 데이터는 디코더에서 \(\mathcal{L}_\textrm{class}\)를 학습하는 데에만 사용된다. 대부분의 grounding 데이터는 철저하게 주석을 달지 않으며 종종 정확하지 않기 때문이다.
- RefCOCO/+/g와 같이 segmentation 주석이 있는 grounding 데이터의 경우 디코더의 모든 loss를 학습하는 데 사용된다.
- 데이터셋에 100,000개 이상의 이미지가 있으면 데이터셋 샘플링 비율을 1.0으로 설정하고 그렇지 않으면 0.1로 설정한다.
Image-centri Grounding Samples
이전 방법은 \(\{I, T, B\}\) 형식의 grounding 샘플을 구성하였다. 여기서 $I$는 이미지이고, $T$는 $I$의 인스턴스를 설명하는 문구이며, $B$는 bounding box이다. 그러나 이미지의 모든 주석이 한꺼번에 학습되는 detection 학습과 비교할 때 영역 중심 형식은 모델이 각 샘플에 대해 단일 인스턴스로 supervise되므로 grounding 학습이 비효율적이다.
APE는 한 번의 forward pass로 여러 프롬프트를 처리하는 것이 가능하다. 따라서 \(\{I, (T_i, B_i), \ldots, (T_n, B_n)\}\)의 이미지 중심 형식으로 grounding 샘플을 수집한다. 이미지 중심 형식은 모델이 동일한 양의 supervision을 받는 동안 학습 iteration을 크게 줄인다. 예를 들어 Visual Genome에는 이미지당 평균 92개의 설명과 bounding box 쌍이 있다. 제안된 이미지 중심 형식을 사용하면 기존 형식에 비해 92배의 속도 향상을 가져온다. 학습 중에 동일한 물체를 참조하는 여러 문구를 방지하기 위해 모든 bounding box에 랜덤 점수로 NMS를 적용한다.
Experiments
1. One Model Weight for All
다음은 여러 데이터셋에서 open-vocabulary detection 성능을 비교한 표이다. “$\varnothing$”은 task가 모델 능력 밖임을 나타낸다.
- APE (A): DETA 위에 ViT-L 기반으로 구축한 모델. COCO, LVIS, Objects365, OpenImages, Visual Genome로 학습.
- APE (B): APE (A) + Visual Genome 영역 설명 + RefCOCO/+/g.
- APE (C): APE (B) + SA-1B.
- APE (D): APE (C) + GQA, PhraseCut, Flickr30k.
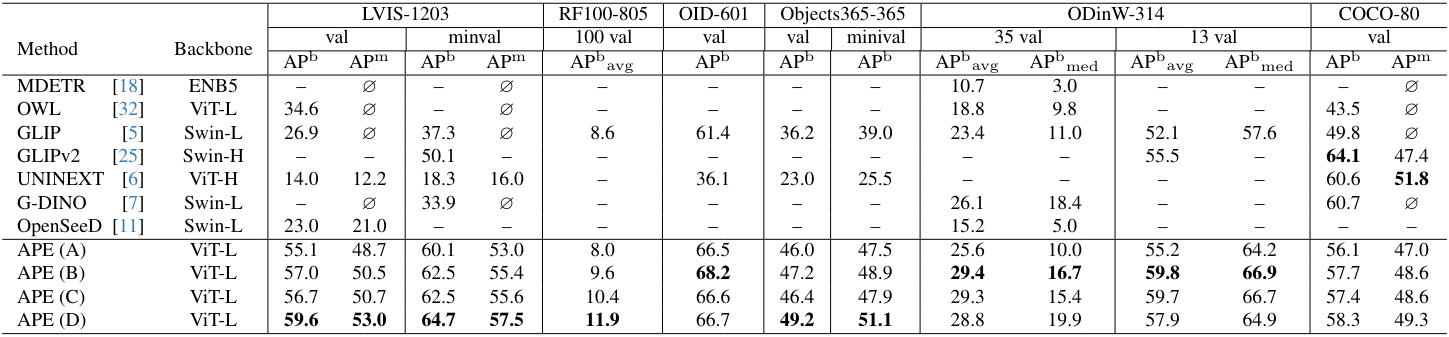
다음은 여러 데이터셋에서 open-vocabulary segmentation 성능을 비교한 표이다.

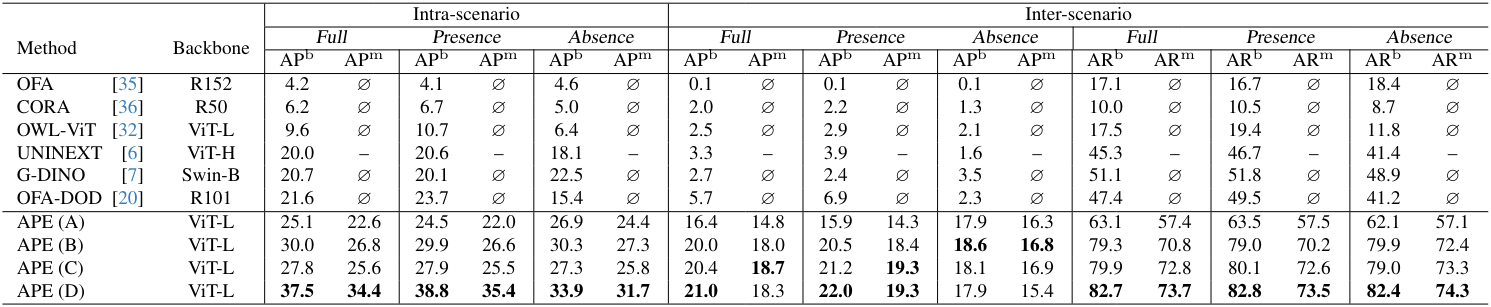
다음은 D3 데이터셋에서 visual grounding 성능을 비교한 표이다.
2. Ablations on Unified Detection and Grounding
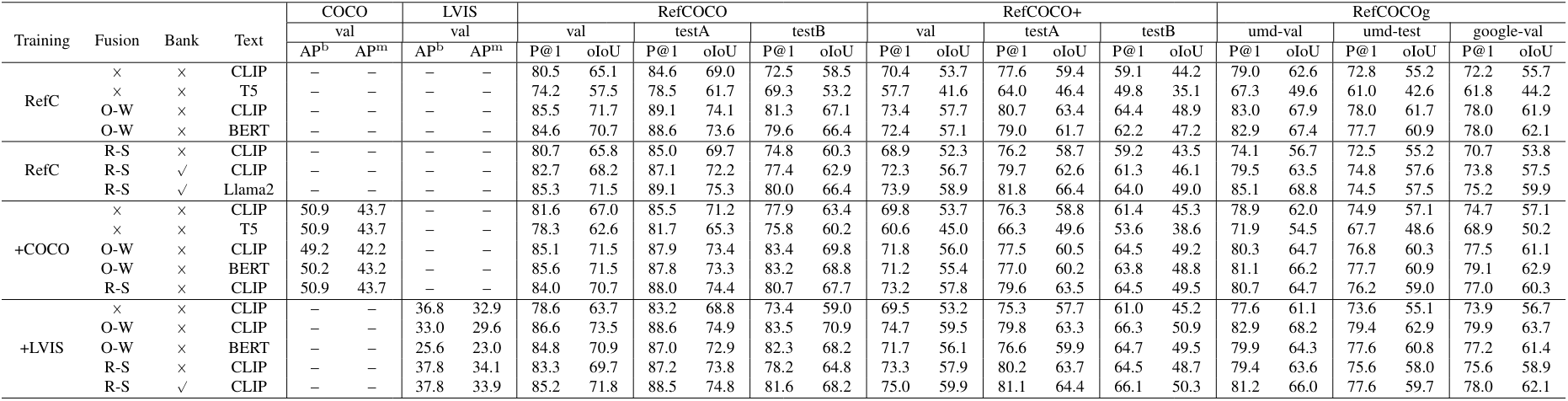
다음은 통합된 detection과 grounding에 대한 ablation 결과이다. (O-W: object-word fusion. R-S: region-sentence fusion)
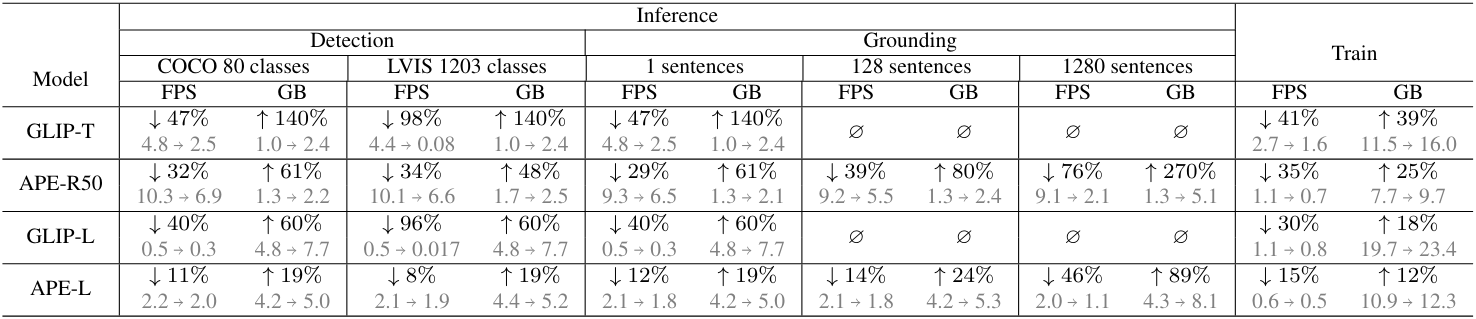
다음은 cross-modality 상호 작용에 대하여 감소된 속도(FPS)와 증가된 메모리(GB) 비율 측면에서 계산 비용을 비교한 표이다.
3. Ablations on Thing-stuff-equalizing Alignment
다음은 다양한 학습 데이터를 활용한 thing-stuff 균등화 학습에 대한 ablation 결과이다.

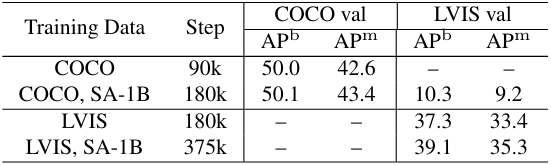
다음은 SA-1B 데이터셋 사용에 대한 ablation 결과이다.
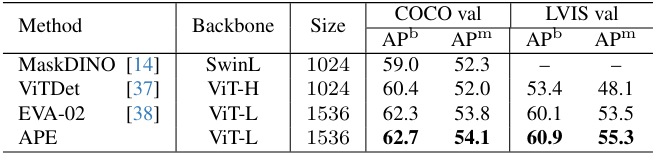
4. Performance on Single Dataset
다음은 추가 학습 데이터 없이 하나의 벤치마크에서 instance segmentation 성능을 추가로 평가한 표이다.