[논문리뷰] Generalized Decoding for Pixel, Image, and Language (X-Decoder)
CVPR 2023. [Paper] [Page] [Github]
Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, Jianfeng Gao
University of Wisconsin-Madison | UCLA | Microsoft Research at Redmond | Microsoft Cloud & AI
21 Dec 2022

Introduction
다양한 세분성 수준에서의 시각적 이해는 비전 커뮤니티에서 오랫동안 문제가 되어 왔다. 이 task는 이미지 수준 task, 영역 수준 localization task, 픽셀 수준 그룹화 task까지 다양하다. 최근까지 이러한 task들의 대부분은 특수 모델 설계를 통해 별도로 처리되어 다양한 세분성에 걸친 task의 시너지 효과가 활용되는 것을 방지했다. Transformer의 다재자능 덕분에 이제 multi-task 학습, 순차 디코딩, 통합 학습 전략을 통해 다양한 비전 및 비전-언어 task에서 학습하고 적용할 수 있는 범용 모델을 구축하는 데 대한 관심이 높아지고 있음을 목격하고 있다. 이러한 연구들은 cross-task 일반화 능력을 장려하는 것으로 나타났지만 대부분은 이미지 수준 task와 영역 수준 task의 통합을 목표로 하므로 중요한 픽셀 수준 이해가 충분히 탐구되지 않았다.
틀림없이 이미지를 픽셀 수준까지 이해하는 것은 가장 중요하면서도 어려운 문제 중 하나이다.
- 픽셀 수준 주석은 다른 유형의 주석에 비해 비용이 많이 들고 훨씬 더 부족하다.
- 모든 픽셀을 그룹화하고 open-vocabulary 방식으로 인식하는 것은 덜 연구되었다.
- 더 중요한 것은 서로 다른 두 가지 세분성의 데이터로부터 학습하는 동시에 상호 이익을 얻는 것이 중요하다는 것이다.
최근에는 다양한 측면에서 이러한 격차를 해소하려는 노력이 이루어졌다. 예를 들어, 세 가지 유형의 segmentation task를 모두 닫힌 집합으로 처리하는 통합 아키텍처 Mask2Former가 제안되었다. Open-vocabulary 인식을 지원하기 위해 많은 연구에서 CLIP이나 ALIGN과 같은 이미지 수준 비전-언어 foundation model에서 전문 모델로 풍부한 semantic 지식을 전달하거나 추출하는 방법을 연구하였다. 그러나 이러한 모든 초기 탐색은 관심 있는 특정 segmentation task에 초점을 맞추고 있으며 다양한 세분성의 task에 대한 일반화를 보여주지 않는다. 본 논문에서는 픽셀 수준과 이미지 수준의 비전-언어 이해의 통합을 위한 X-Decoder라는 일반화된 디코더를 구축하기 위해 한 단계 더 나아갔다.
일반화된 디코딩 프레임워크
본 논문은 픽셀 수준 iamge segmentation, 이미지 수준 검색, 비전-언어 task를 포함한 모든 task들을 일반적인 디코딩 절차로 공식화였다. 특히 X-Decoder는 Mask2Former의 프레임워크를 따라 멀티스케일 이미지 feature를 추출하기 위한 비전 backbone과 transformer 인코더 위에 구축되었다. 본 논문의 핵심은 디코더 설계에 있다.
- 두 가지 query의 집합을 입력으로 사용한다. 하나는 Mask2Former와 유사하게 범용 segmentation을 위한 segmentation mask를 디코딩하는 것을 목표로 하는 일반 non-semantic query이고, 다른 하나는 디코더가 다양한 언어 관련 비전 task들에 대하여 언어를 인식하도록 새로 도입된 텍스트 query이다.
- 픽셀 수준 마스크와 토큰 수준 semantic이라는 두 가지 유형의 출력을 예측하며, 이들의 다양한 조합은 관심 있는 모든 task를 원활하게 지원할 수 있다.
- 단일 텍스트 인코더를 사용하여 segmentation에서의 개념, referring segmentation에의 참조 문구, image captioning에서의 토큰, VQA에서의 질문 등 모든 task와 관련된 텍스트 코퍼스를 인코딩한다. 다양한 task의 이질적인 특성을 존중하면서 task 간의 시너지 효과를 높이고 공유된 시각적 semantic space의 학습을 가능하게 한다.
End-to-end 학습 패러다임
본 논문은 일반화된 디코더 설계를 통해 supervision의 모든 세분성에서 학습할 수 있는 end-to-end 사전 학습 방법을 제안하였다. Panoptic segmentation, referring segmentation, 이미지-텍스트 쌍의 세 가지 유형의 데이터를 통합한다. 이미지-텍스트 쌍에서 세밀한 supervision을 추출하기 위해 pseudo-labeling 기술을 사용하는 이전 연구들과 달리 X-Decoder는 의미 있는 몇 가지 segmentation 후보를 직접 그룹화하고 제안하므로 해당 영역을 캡션에 설명된 내용에 쉽게 매핑할 수 있다. 한편, referring segmentation은 픽셀 수준 디코딩을 전자와, semantic query를 후자와 공유함으로써 일반 segmentation과 image captioning을 연결한다.
광범위한 segmentation 및 VL task에 대한 강력한 zero-shot 및 task별 전환 가능성
제한된 양의 분할 데이터와 수백만 개의 이미지-텍스트 쌍으로 사전 학습된 X-Decoder는 zero-shot 및 open-vocabulary 방식으로 다양한 task를 지원한다. 구체적으로, 광범위한 영역에서 세 가지 유형의 segmentation task 모두에 직접 적용되어 7개 데이터셋의 10개 설정에 대한 새로운 SOTA를 달성하였다. 특정 task로 전환할 때 X-Decoder는 이전 연구들에 비해 일관된 우월성을 나타낸다. 또한, 모델 설계에서 부여된 유연성 덕분에 모델이 새로운 task 구성과 효율적인 fine-tuning을 지원할 수 있다는 몇 가지 흥미로운 속성이 있다.
X-Decoder
1. Formulation
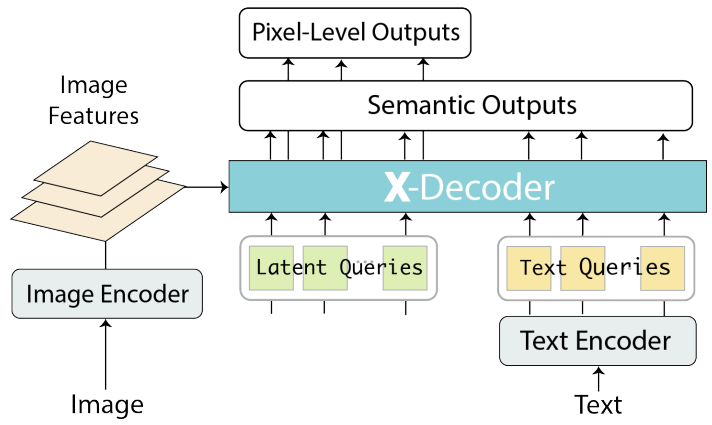
본 논문의 모델은 위 그림에 표시된 인코더-디코더 아키텍처의 일반적인 설계를 따른다. 입력 이미지 $I \in \mathbb{R}^{H \times W \times 3}$이 주어지면 먼저 이미지 인코더 \(\textrm{Enc}_I\)를 사용하여 feature $Z$를 추출한다. 그런 다음 텍스트 인코더 \(\textrm{Enc}_T\)를 사용하여 text query $T$를 길이가 $n$인 $Q^t = \langle q_1^t, \ldots, q_n^t \rangle$로 인코딩한다. 시각적 feature, 텍스트 query, $m$개의 non-semantic query (latent query) $Q^h = \langle q_1^h, \ldots, q_m^h \rangle$가 출력을 예측하기 위해 X-Decoder에 공급된다.
여기서 $O^p$와 $O^s$는 각각 픽셀 수준 마스크와 토큰 수준 semantic이다. 위 식에서 다양한 비전 및 비전-언어 task에 대한 X-Decoder의 일반화 능력을 강화하는 세 가지 중요한 디자인에 주목한다.
X-Decoder에 대한 두 가지 유형의 query와 출력을 정의한다.
앞에서 설명한 것처럼 디코더에 대한 query는 각각 일반 비전 및 비전-언어 task를 수행하는 latent query $Q^h$와 텍스트 query $Q^t$로 분류되며 이들의 조합은 referring segmentation, VQA 등과 같은 다양한 언어 인식 task를 추가로 지원할 수 있다. 마찬가지로 출력은 픽셀 수준 마스크 $O^p$와 semantic 임베딩 $O^s$로 분류된다. 단순히 다른 조합을 사용함으로써 동일한 파라미터 집합을 사용하여 X-Decoder를 다양한 task에 적용할 수 있다.
모든 task의 텍스트 코퍼스를 인코딩하기 위해 단일 텍스트 인코더 \(\textrm{Enc}_T\)를 사용한다.
공통 텍스트 인코더는 referring segmentation, 이미지-텍스트 검색, image captioning task에서 각각 참조 문구, 텍스트 설명, 이미지 캡션을 각각 인코딩하는 데 사용된다. 또한, segmentation에서 마스크 분류를 $O^s$와 프롬프트된 텍스트 개념의 텍스트 임베딩 간의 마스크-텍스트 매칭 문제로 재구성한다. 모든 텍스트 코퍼스에 대한 텍스트 인코더를 공유하면 다양한 task의 지식을 최대한 교환하고 더 풍부하고 일관된 semantic space를 배울 수 있다.
이미지와 텍스트 인코더를 완전히 분리한다.
이전의 많은 통합 인코더-디코더 모델에서는 이미지와 텍스트가 인코더 측에서 융합되었다. 이 디자인은 글로벌한 이미지-텍스트 contrastive learning뿐만 아니라 생성적 사전 학습에도 다루기 어렵다. 대조적으로, 이미지와 텍스트 인코더를 완전히 분리하고 출력을 모두 query로 사용함으로써 X-Decoder는 이미지 내 supervision과 이미지 간 supervision 모두에서 학습할 수 있다. 이는 더 강력한 픽셀 수준 표현을 학습하고 다양한 task의 세분성을 지원하는 데 필수적이다.
2. Unification of Tasks
위의 설계를 기반으로 X-Decoder를 사용하면 다양한 query 조합을 입력으로 사용하여 다양한 비전 및 비전-언어 task을 원활하게 통합할 수 있다.
Generic Segmentation
이 task에는 입력으로 사용되는 텍스트 query가 없다. 따라서 식은 다음과 같이 된다.
\[\begin{equation} \langle O^p, O^s \rangle = \textrm{XDec} (Q^h; Z) \end{equation}\]여기서 $O^p$, $O^s$는 $Q^h$와 동일한 크기를 갖는다. 위 식은 Mask2Former로 축소되지만 마스크 분류를 위해 마스크-텍스트 매칭을 사용하므로 open-vocabulary 용량을 갖는다.
Referring Segmentation
입력으로 latent query와 텍스트 query가 모두 필요하므로 기존 식을 사용한다. 일반 segmentation과 유사하게 latent query에 해당하는 처음 $m$개의 디코딩된 출력만 사용한다. Referring segmentation은 언어로 컨디셔닝된 일반 segmentation로 간주될 수 있다.
Image-Text Retrieval
X-Decoder의 분리된 이미지와 텍스트 인코더를 사용하면 이미지 간 검색이 간단해진다. 구체적으로, 디코더에 latent query만 제공하고 이미지의 semantic 표현을 얻는다.
\[\begin{equation} O^s = \textrm{XDec} (Q^h; Z) \end{equation}\]여기서 $O^s$는 $Q^h$와 길이가 같고 $O^s$의 마지막 토큰은 이미지와 텍스트 간의 유사성을 계산하는 데 사용된다.
Image Captioning and VQA
두 task 모두에 대해 X-Decoder는 latent query와 텍스트 query를 모두 사용하고 출력을 디코딩한다.
\[\begin{equation} O^s = \textrm{XDec} ( \langle Q^h, Q^t \rangle; Z) \end{equation}\]여기서 $O^s$는 $Q^t$와 크기가 동일하며 마스크는 예측되지 않는다. 두 task 사이에는 두 가지 약간의 차이점이 있다. 첫째, 캡션 예측은 인과적 마스킹 (causal masking) 전략을 따르는 반면 VQA는 그렇지 않다. 둘째, 캡션 작성을 위해 $O^s$의 모든 출력을 사용하지만 VQA에 대한 답변을 예측하는 데는 마지막 출력만 사용한다.
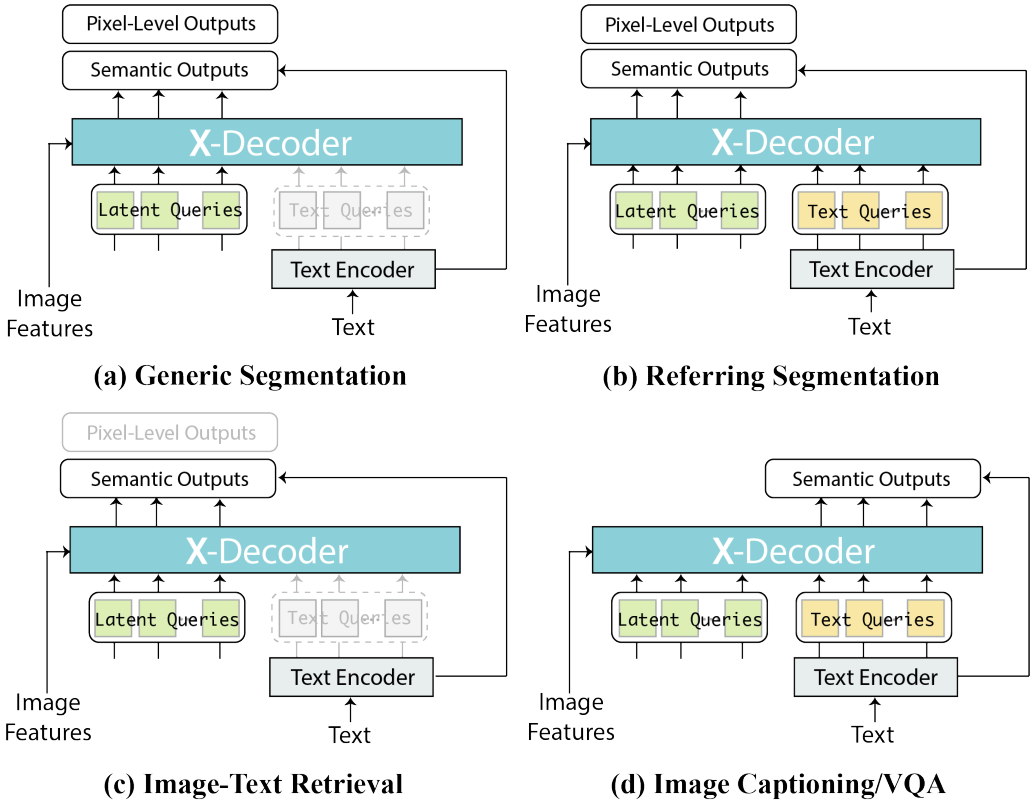
각 task에 대한 X-Decoder의 적응은 위 그림에 자세히 설명되어 있다. 이러한 통합을 기반으로 query와 loss의 적절한 조합을 사용하여 모든 task로 X-Decoder를 사전 학습할 수 있으며, 별도의 추가 head 없이 개별 task에 대해 추가로 fine-tuning할 수 있다. 이전 연구들은 통합을 위해 순차 디코딩 인터페이스를 활용했다. 그러나 본 논문에서는 인터페이스보다는 기능에 의한 통합을 제안한다. 즉, 개별 task에 대해 나머지 부분을 변경하지 않고 유지하면서 다양한 task의 공통 부분을 최대한 공유한다.
3. Unified Architecture
Mask2Former를 따라 디코더 아키텍처를 구축한다. 이미지 $I \in \mathbb{R}^{H \times W \times 3}$가 주어지면 $L$개의 레이어들에서 계층적 시각적 feature를 추출한다.
\[\begin{equation} Z = \textrm{Enc}_I (I) = \langle z_l \rangle_{l=1}^L \end{equation}\]여기서 $z^l \in \mathbb{R}^{H_l \times W_l \times d}$이고 \(\{H_l, W_l\}\)은 레벨 $l$의 feature map 크기이고 $d$는 feature 차원이다. 이러한 계층적 feature map은 다양한 스케일에서 픽셀 수준을 이해하는 데 중요하다.
모든 task을 위한 하나의 디코더 XDec
시각적 feature $Z$가 주어지면 X-Decoder는 transformer 레이어 스택을 사용하여 query를 구체화하고 출력을 렌더링한다. 레이어 $l$에서는 먼저 시각적 feature들을 cross-attend한 다음 latent query와 텍스트 query 사이에서 self-attention을 수행한다.
\[\begin{aligned} \langle \hat{Q}_{l-1}^h, \hat{Q}_{l-1}^t \rangle &= \textrm{CrossAtt} (\langle Q_{l-1}^h, Q_{l-1}^t \rangle; Z) \\ \langle Q_l^h, Q_l^t \rangle &= \textrm{SelfAtt} (\langle \hat{Q}_{l-1}^h, \hat{Q}_{l-1}^t \rangle) \end{aligned}\]먼저 모든 query가 시각적 feature들에 cross-attend하도록 한다. Latent query의 경우 Mask2Former에서와 같이 masked cross-attention 메커니즘을 사용하고 텍스트 query에 대해서는 완전한 attend한다. 그런 다음 task들의 시너지를 촉진하기 위해 self-attention 메커니즘을 구체적으로 설계한다.
- 마지막 latent query를 사용하여 글로벌 이미지 표현을 추출하고 나머지는 일반 분할을 위해 추출한다.
- Image captioning의 경우 각 텍스트 query는 query 자체, 이전 query, 모든 latent query에 attend할 수 있다.
- Referring segmentation의 경우 latent query는 모든 텍스트 query에 attend하여 이를 언어 조건으로 사용한다.
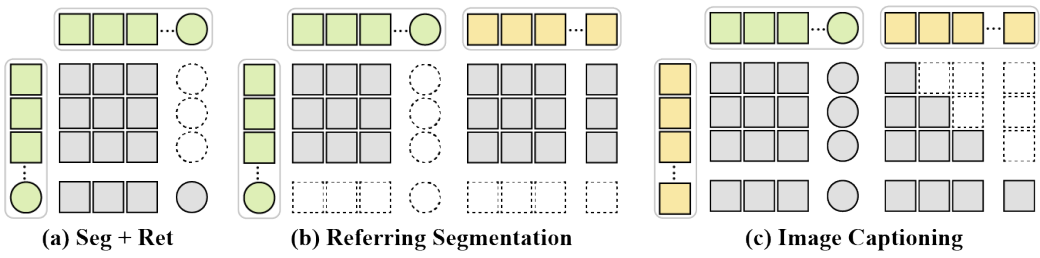
이러한 규칙을 기반으로 X-Decoder의 self-attention 결과는 위 그림과 같다.
X-Decoder의 출력도 픽셀별 마스크와 semantic 출력의 두 가지 유형으로 분류된다. X-Decoder는 항상 $m$개의 latent query에 대해서만 마스크를 생성한다. 즉, 모든 latent query에 대해
\[\begin{equation} O^p = \{o_1^p, \ldots, o_m^p\} \in \{0, 1\}^{m \times H \times W} \end{equation}\]이다. Semantic 출력의 경우 X-Decoder는 마스크 인식과 캡션 생성을 위해 latent query와 텍스트 query 모두에 대한 출력을 예측한다
\[\begin{equation} O^s = \{o_1^s, \ldots, o_{m+n}^s\} \in \mathbb{R}^{(m+n) \times d} \end{equation}\]모든 task을 위한 하나의 인코더 \(\textrm{Enc}_T\)
텍스트 인코더는 여러 개의 transformer 레이어로 구성된다. 문구나 캡션과 같은 텍스트가 주어지면 이를 상용 토크나이저를 사용하여 이산 토큰으로 변환한 다음 텍스트 인코더로 보낸다. 출력이 캡션 디코딩과 호환되는지 확인하기 위해 인과적 마스킹 (causal masking)을 적용한다. 분할을 위해 클래스 이름을 텍스트 프롬프트가 있는 문구로 변환하고 (ex. “dog” $\rightarrow$ “an image of dog”) 위와 같이 문구를 인코딩한다.
4. End-to-End Pre-training
출력에 대응되는 두 가지 유형의 loss를 사용하여 end-to-end 방식으로 X-Decoder를 학습한다.
Semantic Loss
Semantic 출력에는 세 가지 task에 각각 해당하는 세 가지 loss이 있다. 이미지-텍스트 검색의 경우 언어-이미지 contrastive loss를 CLIP과 같이 계산한다. 텍스트를 $\hat{q}^t$로 표현하기 위해 텍스트 인코더에서 $Q^t$의 마지막 유효한 토큰 feature를 취하고 X-Decoder에서 파생된 $O^s$의 마지막 항목을 $\hat{o}^s$로 취한다. 결과적으로 $B$개의 이미지-텍스트 쌍의 minibatch에 대해 $B$ 쌍의 feature \(\langle \hat{q}_i^t, \hat{o}_i^s \rangle_{i=1}^B\)을 얻는다. 그런 다음 $B \times B$ feature 쌍 사이의 내적을 계산하여 선호도 행렬 \(S_\textrm{it} \in \mathbb{R}^{B \times B}\)를 얻고 양방향 cross-entropy loss를 계산한다.
\[\begin{equation} \mathcal{L}_\textrm{it} = \textrm{CE} (S_\textrm{it}, y_\textrm{it}) + \textrm{CE} (S_\textrm{it}^\top, y_\textrm{it}) \end{equation}\]여기서 \(y_\textrm{it}\)는 \(S_\textrm{it}\)의 대각선 원소에 해당하는 클래스 레이블다.
마스크 분류의 경우 “배경”을 포함한 모든 $C$개의 클래스 이름을 $C$개의 텍스트 query로 인코딩하고 각 클래스에서 마지막 유효한 토큰 feature를 가져와 개념을 나타낸다. 그 후, 처음 $(m-1)$개의 latent query에 해당하는 디코더 출력을 취하고 이러한 출력과 개념 임베딩 사이의 내적을 계산하여 선호도 행렬 \(S_\textrm{cls} \in \mathbb{R}^{(m-1) \times C}\)를 얻고 loss \(\mathcal{L}_\textrm{cls} = \textrm{CE} (S_\textrm{cls}, y_\textrm{cls})\)를 계산한다. 여기서 $y_\textrm{cls}$는 ground-truth 클래스이다.
Image captioning의 경우 먼저 텍스트 인코더에서 크기가 $V$인 vocabulary의 모든 토큰에 대한 임베딩을 추출한다. X-Decoder의 마지막 $n$개의 semantic 출력이 주어지면 모든 토큰 임베딩으로 내적을 계산하여 선호도 행렬 \(S_\textrm{cap} \in \mathbb{R}^{n \times V}\)를 얻는다. 그런 다음 실제 다음 토큰의 id $y_\textrm{cap}$을 사용하여 cross-entropy loss \(\mathcal{L}_\textrm{cap} = \textrm{CE} (S_\textrm{cap}, y_\textrm{cap})\)를 계산한다.
Mask Loss
$m$개의 latent query에서 파생된 예측 $\langle O^p, O^s \rangle$이 주어지면 Hungarian matching을 사용하여 처음 $(m − 1)$개의 출력과 일치하는 엔트리를 ground-truth 주석에서 찾는다. 그 후에는 binary crossentropy loss \(\mathcal{L}_\textrm{bce}\)와 dice loss \(\mathcal{L}_\textrm{dice}\)를 사용하여 mask loss를 계산한다. 위의 4가지 loss를 결합하여 X-Decoder를 사전 학습한다.
Experiments
- 데이터셋
- Panoptic & referring segmentation: COCO2017
- 이미지-텍스트 쌍: Conceptual Captions, SBU Captions, Visual Genome, COCO Captions
- 구현 디테일
- 시각적 인코더: Focal-T (latent query 100개, 디코더 레이어 10개)
- deformable encoder를 적용하지 않음 (open-vocabulary 설정에서 일반화가 잘 되지 않음)
- 텍스트 인코더: DaViT-B/L
- minibatch: segmentation은 32, 이미지-텍스트 쌍은 1024
- 이미지 해상도: segmentation은 1024, 이미지-텍스트 쌍은 224
- epoch 수: 50
- optimizer: AdamW
1. Task-Specific Transfer
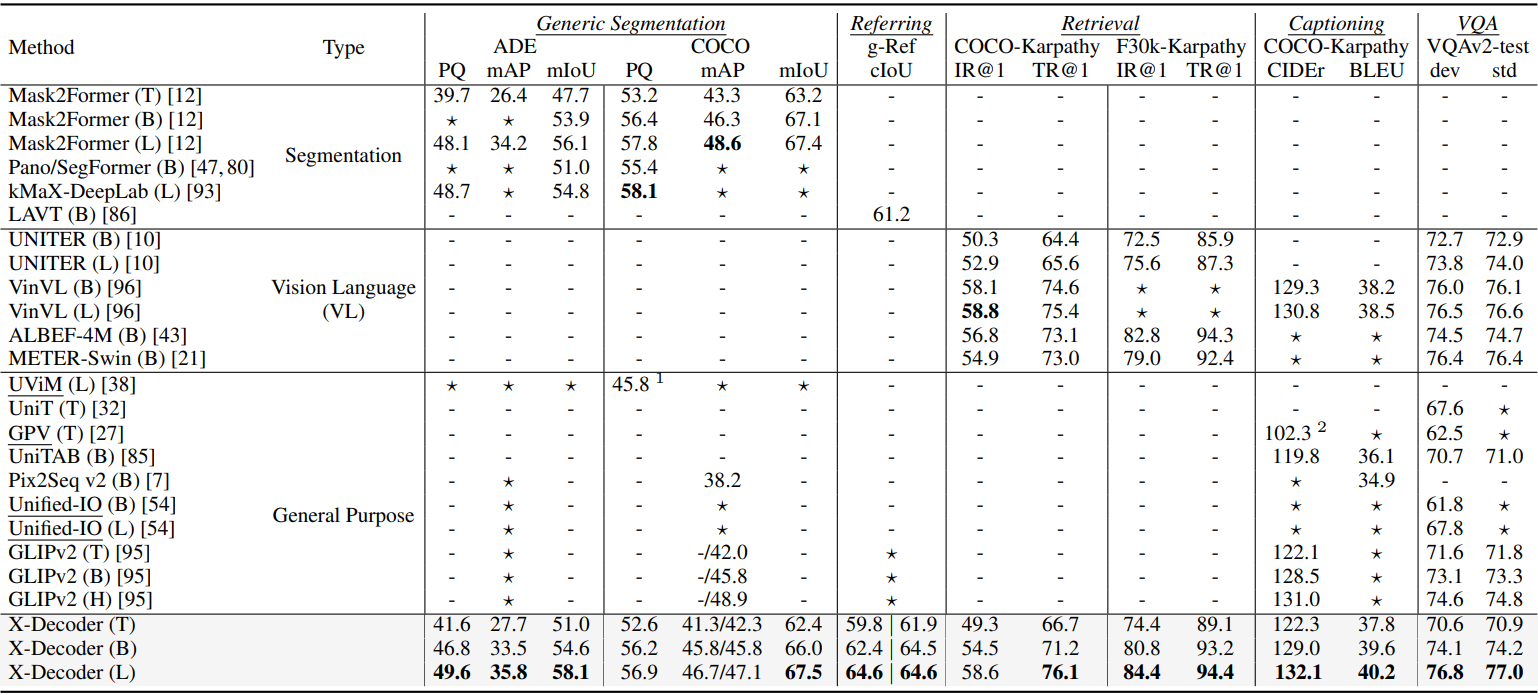
다음은 다양한 segmentation 및 VL task에 대한 X-Decoder의 task별 transfer 결과이다.
다음은 다양한 fine-tuning 전략에 대한 성능을 완전히 fine-tuning된 모델과 비교한 표이다.
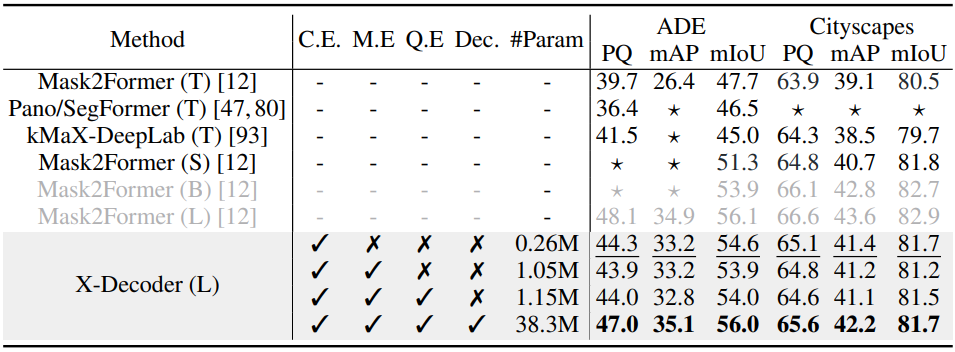
2. Zero-Shot Transfer
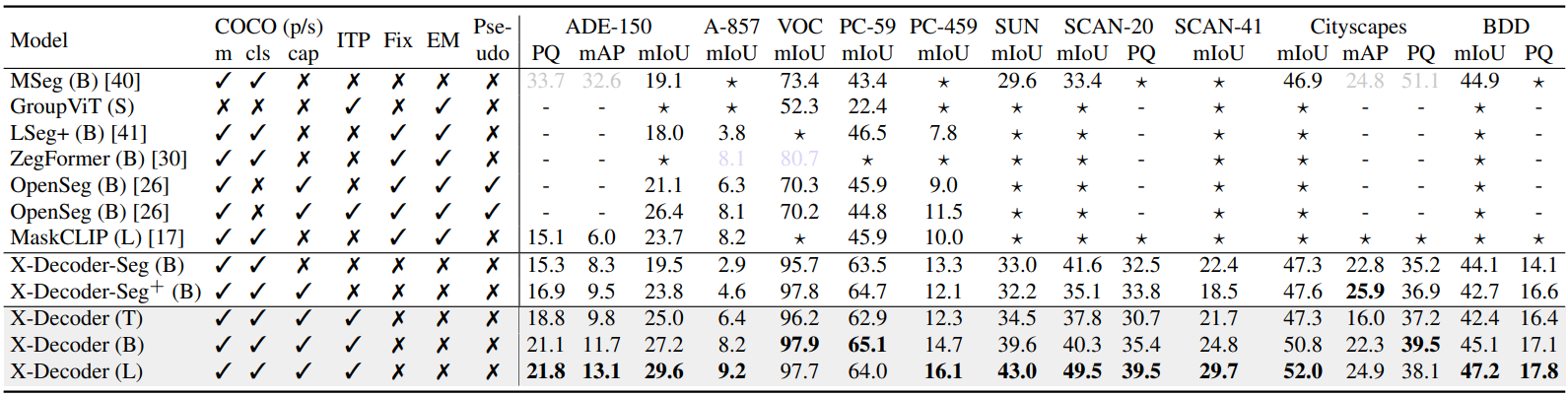
다음은 다양한 도메인의 10가지 설정에서 일반적으로 사용되는 7개의 segmentation 데이터셋에 대해 zero-shot 방식으로 모델을 평가한 결과이다.
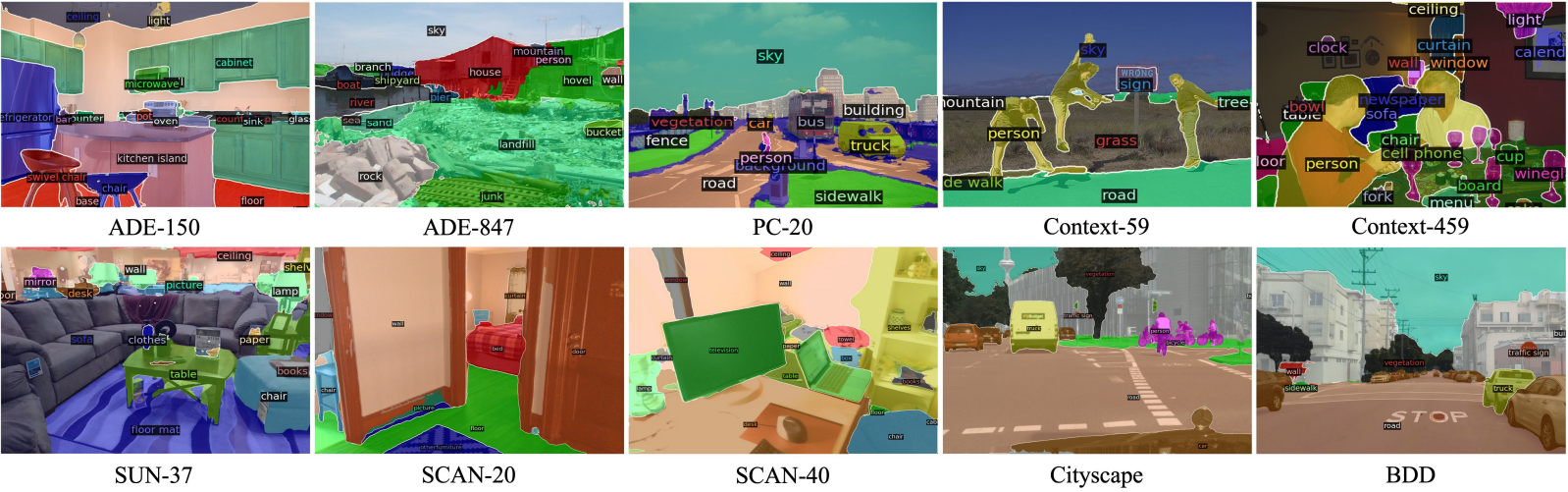
다음은 7개의 데이터셋의 10가지 설정에 대한 zero-shot semantic segmentation 결과이다.
3. Model Inspection
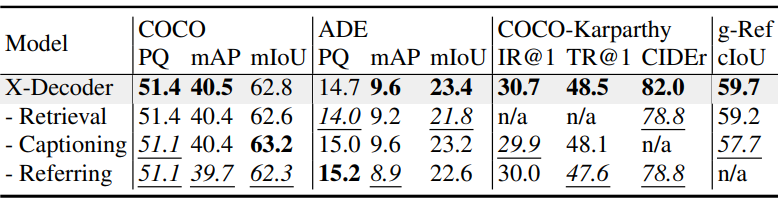
다음은 사전 학습 task에 대한 ablation 결과이다.
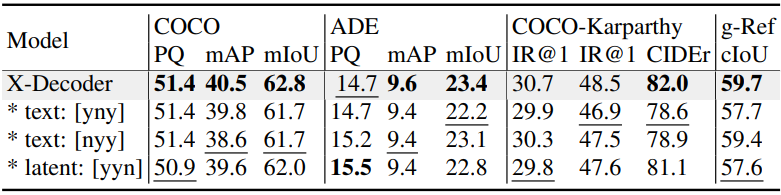
다음은 query 주입에 대한 ablation 결과이다.
다음은 VL batch size에 대한 ablation 결과이다.

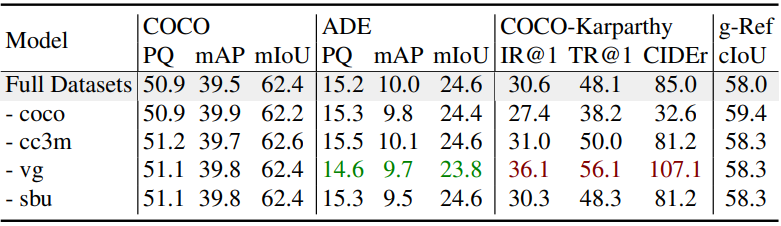
다음은 비전-언어 데이터셋에 대한 ablation 결과이다.
4. Task Composition
다음은 별도의 아키텍처나 가중치 변경 없이 영역 기반 검색 (위)과 참조 기반 captioning (아래)을 수행한 결과이다.
