[논문리뷰] MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
ICLR 2025. [Paper] [Page] [Github]
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, Chi Zhang
S-Lab, Nanyang Technological University | Shanghai AI Lab | Fudan University | Peking University | University of Chinese Academy of Sciences | SenseTime Research | Stepfun | Westlake University
14 Jun 2024
Introduction
현재 3D 산업은 메쉬 기반 파이프라인에 주로 의존하는 반면, 3D 에셋산 제작 방식은 일반적으로 대체 3D 표현을 사용하고 있다. 따라서 다른 3D 표현을 메쉬로 변환하는 데 상당한 노력이 기울여지고 있으며, 어느 정도 성공을 거두고 있다. 이러한 방식으로 생성된 메쉬는 아티스트가 직접 제작한 메쉬(Artist-Created Meshes, AM)와 유사한 형태를 보이지만, AM에 비해 토폴로지 품질이 현저히 낮다. 기존 방법들은 기하학적 특성을 완전히 무시하고 3D 형상을 재구성하기 위해 dense한 면에 의존한다. 3D 산업에서 이러한 메쉬를 사용하면 세 가지 심각한 문제가 발생한다.
- 변환된 메쉬는 일반적으로 AM에 비해 훨씬 더 많은 면을 포함하기 때문에 저장, 렌더링, 시뮬레이션에서 상당한 비효율성을 초래한다.
- 변환된 메쉬는 3D 파이프라인의 후처리 및 downstream task를 복잡하게 만든다. 혼란스럽고 비효율적인 토폴로지로 인해 이러한 메쉬를 최적화하는 데 있어 어려움이 크게 증가한다.
- 기존 방법들은 날카로운 모서리와 평평한 표면을 표현하는 데 어려움을 겪어 과도하게 매끄럽고 울퉁불퉁한 아티팩트가 발생한다.
본 논문에서는 앞서 언급한 문제들을 해결하여 3D 산업에서 자동 생성된 3D 에셋의 적용을 용이하게 하는 것을 목표로 한다. 이를 위해, 메쉬 추출을 생성 문제로 구성함으로써 기존의 접근 방식과 차별화하며, 주어진 3D 에셋에 맞춰진 AM을 생성하는 모델을 학습시킨다. 본 논문의 방법으로 생성된 메쉬는 AM의 형태와 토폴로지 품질을 모방하며, 위 문제들로부터 자유롭고, 생성된 메쉬를 3D 산업 파이프라인에 원활하게 통합할 수 있다.
그러나 이러한 모델을 학습하는 데는 상당한 어려움이 따른다. 첫 번째 어려움은 데이터셋을 구성하는 것이다. 모델 학습을 위해서는 쌍으로 구성된 형상 조건과 AM이 필요하다. 형상 조건은 inference 과정에서 조건으로 사용되기 위해 가능한 한 다양한 3D 표현에서 효율적으로 도출되어야 한다. 또한, 3D 형상을 정확하게 표현하고 모델에 삽입 가능한 feature로 효율적으로 처리될 수 있을 만큼 충분한 정밀도를 가져야 한다. 저자들은 여러 장단점을 비교한 후, 명시적이고 연속적인 표현, 대부분의 3D 표현에서 도출하기 쉬운 점, 그리고 이미 완성된 포인트 클라우드 인코더의 가용성을 고려하여 포인트 클라우드를 선택했다.
저자들은 Objaverse와 ShapeNet에서 고품질 AM을 필터링하였다. AM에서 직접 포인트 클라우드를 샘플링하면 샘플링된 포인트 클라우드의 정밀도가 지나치게 높고, 자동 생성된 3D 에셋은 유사한 품질의 포인트 클라우드를 제공할 수 없어 학습과 inference 시에 도메인 간 격차가 발생한다. 이 문제를 해결하기 위해 AM의 형상 품질을 의도적으로 손상시킨다. 먼저 AM에서 SDF를 추출하고, 이를 더 coarse한 메쉬로 변환한 후, 이 coarse한 메쉬에서 포인트 클라우드를 샘플링하여 학습과 inference 사이의 조건 도메인 간 격차를 줄인다.
MeshGPT를 바탕으로, VQ-VAE를 사용하여 메쉬 vocabulary를 학습하고, 이 vocabulary에 대한 decoder-only transformer를 학습시켜 메쉬를 생성한다. 형태 조건을 주입하기 위해, 학습된 VQ-VAE에서 얻은 메쉬 토큰을 LLM의 언어 토큰으로 취급하고, 사전 학습된 인코더를 사용하여 포인트 클라우드를 shape feature로 인코딩한 후, 이를 메쉬 토큰 공간으로 projection시킨다. 이러한 형태 토큰은 메쉬 토큰 시퀀스의 시작 부분에 배치되어 다음 토큰 예측의 형태 조건으로 효과적으로 사용된다. 예측 후, 예측된 메쉬 토큰은 VQ-VAE 디코더를 통해 다시 메쉬로 디코딩된다.
메쉬 생성 품질을 더욱 향상시키기 위해, 저자들은 robust한 메쉬 디코딩을 위한 새로운 디코더를 개발했다. VQ-VAE의 디코더는 인코더의 실제 토큰 시퀀스로만 학습되기 때문에, 생성된 토큰 시퀀스를 디코딩할 때 도메인 차이가 발생할 수 있다. 이 문제를 완화하기 위해, robust한 디코딩을 위한 보조 정보로 VQ-VAE 디코더에 형태 조건을 주입하고, VQ-VAE 학습 후 fine-tuning한다. 이 fine-tuning 과정은 decoder-only transformer에서 발생할 수 있는 저품질 토큰 시퀀스를 시뮬레이션하기 위해 메쉬 토큰 시퀀스에 노이즈를 추가하는 과정을 포함하며, 이를 통해 디코더가 이러한 저품질 시퀀스에 robust하게 동작하도록 한다.
MeshAnything 모델은 다양한 3D 표현 방식의 3D 에셋을 AM으로 변환하여 AM의 적용을 크게 용이하게 한다. 또한, 기존 방법과 유사하거나 유사한 정밀도 지표를 달성하면서도 훨씬 적은 면과 더욱 정교한 토폴로지를 갖는 AM을 생성한다.
Method

1. Shape Encoding for conditional generation
MeshAnything은 $p(\mathcal{M} \vert \mathcal{S})$를 학습하는 것을 목표로 하므로, 각 메쉬 $\mathcal{M}$과 그에 대응하는 형상 조건 $\mathcal{S}$를 연결해야 한다. $\mathcal{S}$에 적합한 3D 표현을 선택하는 것은 간단하지 않으며, 다음 조건을 충족해야 한다.
- 다양한 3D 표현에서 쉽게 추출할 수 있어야 한다. 이를 통해 학습된 모델을 다양한 3D 에셋 생산 파이프라인과 통합할 수 있다.
- Overfitting을 방지하기 위한 data augmentation에 적합해야 한다. 학습 중 $\mathcal{S}$의 효과를 보장하기 위해 $\mathcal{M}$에 적용된 모든 data augmentation은 $\mathcal{S}$에도 동등하게 적용 가능해야 한다.
- 조건으로서 모델에 효율적이고 편리하게 입력되어야 한다. 모델이 형상 정보를 이해하고 효율적인 학습을 유지하기 위해 $\mathcal{S}$는 쉽고 효과적으로 feature로 인코딩되어야 한다.
첫 번째와 두 번째를 고려할 때, $\mathcal{S}$는 명시적 표현이어야 한다. 세 번째를 고려하면, feature로 쉽게 인코딩할 수 있는 명시적 3D 표현은 voxel과 포인트 클라우드이다. 두 표현 모두 적합하지만, voxel은 일반적으로 형상을 정확하게 표현하기 위해 고해상도가 필요하며, 고해상도 voxel을 feature로 처리하는 데는 계산 비용이 많이 든다. 또한, voxel은 discrete한 표현이기 때문에 포인트 클라우드에 비해 data augmentation에 대한 정확도가 떨어진다. 따라서 저자들은 $\mathcal{S}$의 표현으로 포인트 클라우드를 선택했다. 포인트 클라우드의 표현력을 향상시키기 위해 포인트 클라우드 표현에 normal도 포함시켰다.
학습을 위해 GT 메쉬에서 포인트 클라우드를 얻으려면 $\mathcal{M}$의 표면에서 직접 포인트 클라우드를 샘플링하면 된다. 하지만 이 방법은 inference 과정에서 문제가 발생한다. 자동 생성된 3D 에셋의 표면은 AM의 표면보다 coarse하기 때문이다. 예를 들어, AM에서는 평평한 평면에서 일련의 포인트를 샘플링하는 반면, 자동 생성된 3D 에셋은 표면이 고르지 않아 학습과 inference 사이에 도메인 간 격차가 발생한다.
따라서, 학습 과정에서 GT $\mathcal{M}$에서 추출된 $\mathcal{S}$가 inference 과정에서 추출된 $\mathcal{S}$와 유사한 도메인을 갖도록 해야 한다. 도메인을 더 가깝게 만들기 위해, AM으로부터 의도적으로 coarse한 메쉬를 구성한다. 먼저 $\mathcal{M}$에서 SDF를 추출한 다음, Marching Cubes를 사용하여 GT 토폴로지를 파괴하는 비교적 coarse한 메쉬로 변환한다. 마지막으로, coarse한 메쉬에서 포인트 클라우드와 그 normal을 샘플링한다. 이러한 접근 방식은 일반적으로 AM의 면 수가 적고 각 면이 여러 점을 샘플링할 수 있기 때문에 overfitting을 방지하는 데에도 도움이 된다. 네트워크는 점들이 동일 평면에 있는지 여부를 판단하여 GT 토폴로지를 쉽게 인식할 수 있다.
거의 모든 3D 표현은 Marching Cubes를 사용하여 coarse한 메쉬로 변환하거나 포인트 클라우드로 샘플링할 수 있으므로, 학습 및 추론 과정에서 $\mathcal{S}$의 도메인이 일관되게 유지된다. $\mathcal{S}$로 추출된 포인트 클라우드를 $\mathcal{M}$과 쌍으로 연결하여 학습용 데이터 \(\{(\mathcal{M}_i, \mathcal{S}_i)\}_i\)를 생성한다.
2. VQ-VAE with Noise-Resistant Decoder
MeshGPT를 따라, 임베딩 vocabulary를 학습시키기 위해 VQ-VAE를 먼저 학습시킨다. Graph convolutional network와 ResNet을 각각 인코더와 디코더로 사용하는 MeshGPT와 달리, 인코더와 디코더 모두에 동일한 구조를 가진 transformer를 사용한다. VQ-VAE를 학습시킬 때, 메쉬는 discretize되어 일련의 삼각형 면으로 입력된다.
\[\begin{equation} \mathcal{M} := (f_1, f_2, \ldots, f_N) \end{equation}\]($f_i$는 각 면의 vertex 좌표, $N$은 $\mathcal{M}$에 있는 면의 수)
그런 다음, 인코더 $E$는 각 면에 대한 feature 벡터를 추출한다.
\[\begin{equation} \mathcal{Z} = (z_1, z_2, \ldots, z_N) = E(\mathcal{M}) \end{equation}\]($z_i$는 $f_i$의 feature 벡터)
추출된 면은 codebook $\mathcal{B}$를 사용하여 $\mathcal{T}$로 quantize된다.
\[\begin{equation} \mathcal{T} = \textrm{RQ} (\mathcal{Z}; \mathcal{B}) \end{equation}\]마지막으로, 재구성된 메쉬는 각 vertex 좌표에 대한 logit을 예측하여 디코더 $D$를 통해 $\mathcal{T}$에서 디코딩된다.
\[\begin{equation} \hat{\mathcal{M}} = D(\mathcal{Z}) \end{equation}\]VQ-VAE는 예측된 vertex 좌표 logit에 대한 cross-entropy loss와 vector quantization의 commitment loss를 고려하여 end-to-end로 학습된다. VQ-VAE 학습 후, VQ-VAE의 인코더-디코더는 transformer 학습을 위한 tokenizer와 detokenizer로 처리된다.
그러나 생성 결과에는 불완전성이 있을 수 있다. 이 문제를 해결하기 위해, VQ-VAE 디코더는 형상 조건을 입력으로 사용할 수 있다. Transformer에서 생성된 토큰 시퀀스의 작은 불완전성은 디코더를 통해 잠재적으로 보정될 수 있다. 따라서 기본 VQ-VAE 학습을 완료한 후, 추가적인 디코더 fine-tuning 단계를 추가하여 형상 정보를 transformer 디코더에 주입한다. 그런 다음, codebook 샘플링 logit에 랜덤 Gumbel noise를 추가하여 inference 과정에서 transformer에서 생성된 토큰 시퀀스의 잠재적 불완전성을 시뮬레이션한다. 디코더는 동일한 cross-entropy loss로 독립적으로 업데이트되어 불완전한 토큰 시퀀스에 직면하더라도 정제된 메쉬를 생성하도록 학습된다.
3. Shape-Conditioned Autoregressive Transformer
Transformer에 형태 조건을 추가하기 위해, 먼저 포인트 클라우드 인코더 $\mathcal{P}$를 사용하여 포인트 클라우드를 고정 길이의 토큰 시퀀스로 인코딩한 다음, 이를 VQ-VAE의 임베딩 시퀀스 $\mathcal{T}$ 앞에 concat하여 transformer의 최종 입력 임베딩 시퀀스로 만든다.
\[\begin{equation} \mathcal{T}^\prime = \textrm{concat} (\mathcal{P} (\mathcal{S}), \mathcal{T}) \end{equation}\]Michelangelo의 사전 학습된 포인트 인코더를 차용하고, linear projection layer를 추가하여 출력 feature를 $\mathcal{T}$와 동일한 latent space에 projection한다. 학습 과정에서 Michelangelo의 포인트 인코더는 고정된다. 새로 추가된 projection layer와 cross-entropy loss를 적용한 transformer만 업데이트한다.
Inference 시에는 $\mathcal{P} (\mathcal{S})$를 transformer에 입력하고, transformer가 후속 시퀀스 $\hat{\mathcal{T}}$를 생성하도록 한다. $\hat{\mathcal{T}}$는 noise-resistant decoder에 입력되어 메쉬를 재구성한다.
\[\begin{equation} \hat{\mathcal{M}} = D (\mathcal{T}) \end{equation}\]Next-token prediction loss를 사용하여 transformer를 학습시킨다. 각 시퀀스에 대해 포인트 클라우드 토큰 뒤에 <bos> 토큰을, 메쉬 토큰 뒤에 <eos> 토큰을 추가하여 3D 메쉬의 끝을 식별한다.
Experiments
- 구현 디테일
- 모델
- VQ-VAE 인코더/디코더: BERT
- Transformer: OPT-350M
- residual vector quantization
- depth: 3
- codebook 크기: 8,192
- 포인트 인코더
- 출력 토큰 길이: 257 (형태 정보 256, semantic 정보 1)
- 포인트 클라우드에서 4,096개 샘플링
- batch size: GPU당 8
- GPU
- VQ-VAE: A100 8개에서 12시간
- Transformer: A100 8개에서 4일
- 모델
1. Qualitative Experiments
다음은 다양한 3D 표현으로부터 생성한 메쉬들이다.

2. Quantitative Experiments
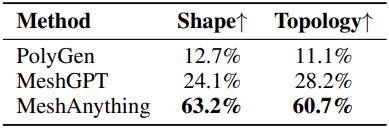
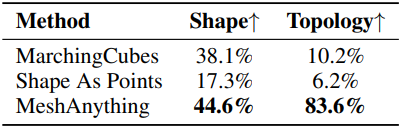
다음은 user study 결과이다.
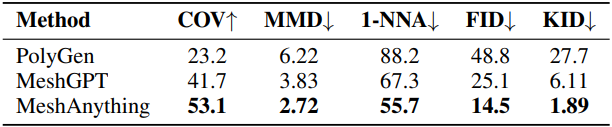
다음은 정량적 평가 결과이다.