[논문리뷰] DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
ECCV 2024 (Oral). [Paper] [Page] [Github]
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Xintao Wang, Tien-Tsin Wong, Ying Shan
The Chinese University of Hong Kong | Tencent AI Lab | Peking University
18 Oct 2024
Introduction
최근, text-to-video (T2V) 생성 모델은 텍스트 프롬프트에서 다양하고 생생한 동영상을 만드는 데 놀라운 성공을 거두었다. 이는 이미지 애니메이션을 위해 강력한 동영상 생성 능력을 활용하는 잠재력을 조사하도록 영감을 주었다.
본 논문의 핵심 아이디어는 조건부 이미지를 통합하여 T2V diffusion model의 동영상 생성 프로세스를 제어하는 것이다. 그러나 이미지 애니메이션의 목표를 달성하는 것은 여전히 쉬운 일이 아니다. 이는 시각적 컨텍스트 이해와 디테일 보존이 모두 필요하기 때문이다. 최근 연구에서는 이미지의 visual guidance를 통해 동영상을 생성할 수 있도록 하는 시도가 있었지만, 안타깝게도 덜 포괄적인 이미지 주입 메커니즘으로 인해 이미지 애니메이션에 적합하지 않아 갑작스러운 시간적 변화나 입력 이미지와의 낮은 시각적 일치가 발생한다.
본 논문은 이러한 과제를 해결하기 위해 텍스트와 정렬된 컨텍스트 표현과 visual detail guidance (VDG)로 구성된 듀얼 스트림 이미지 주입 패러다임을 제안하였다. 이를 통해 video diffusion model (VDM)이 디테일이 보존된 동적 콘텐츠를 보완적인 방식으로 합성할 수 있다. 이 접근 방식을 DynamiCrafter라고 부른다.
이미지가 주어지면, 특별히 설계된 컨텍스트 학습 네트워크를 통해 먼저 이미지를 텍스트와 정렬된 풍부한 컨텍스트 표현 공간에 projection한다. 구체적으로, 네트워크는 텍스트와 정렬된 이미지 feature를 추출하기 위한 사전 학습된 CLIP 이미지 인코더와 diffusion model에 대한 적응을 더욱 촉진하기 위한 학습 가능한 query transformer로 구성된다. 풍부한 컨텍스트 feature는 cross-attention layer를 통해 모델에 의해 사용되며, 그런 다음 gated fusion을 통해 텍스트 조건부 feature와 결합된다.
학습된 컨텍스트 표현은 시각적 디테일을 텍스트 정렬과 교환하여 이미지 컨텍스트의 semantic 이해를 용이하게 하며, 이를 통해 합리적이고 생생한 역학을 합성할 수 있다. 보다 정확한 시각적 디테일을 보완하기 위해, 전체 이미지를 초기 noise와 concatenate하여 diffusion model에 추가로 공급한다. 이 듀얼 스트림 주입 패러다임은 그럴듯한 동적 콘텐츠와 입력 이미지에 대한 시각적 적합성을 모두 보장한다.
DynamiCrafter는 다른 방법들보다 눈에 띄는 우월성을 보였으며, 최신 상업용 데모와도 비슷한 성능을 보였다. 이미지 애니메이션 외에도 DynamiCrafter는 스토리텔링 동영상 생성, 반복되는 동영상 생성, 생성 프레임 보간과 같은 애플리케이션을 지원하도록 쉽게 조정할 수 있다.
Method
본 논문은 정지 이미지가 주어지면 이미지의 모든 시각적 콘텐츠를 상속하고 자연스러운 역학을 보여주는 짧은 동영상 클립을 생성하기 위해 이미지를 애니메이션화하는 것을 목표로 한다. 정지 이미지는 결과 프레임 시퀀스의 임의의 위치에 나타날 수 있다. 이러한 과제는 시각적 적합성이 매우 필요한 특수한 종류의 이미지 조건부 동영상 생성으로 볼 수 있다. 본 논문은 사전 학습된 VDM의 generative prior를 활용하여 이 과제를 해결하였다.
1. Image Dynamics from Video Diffusion Priors
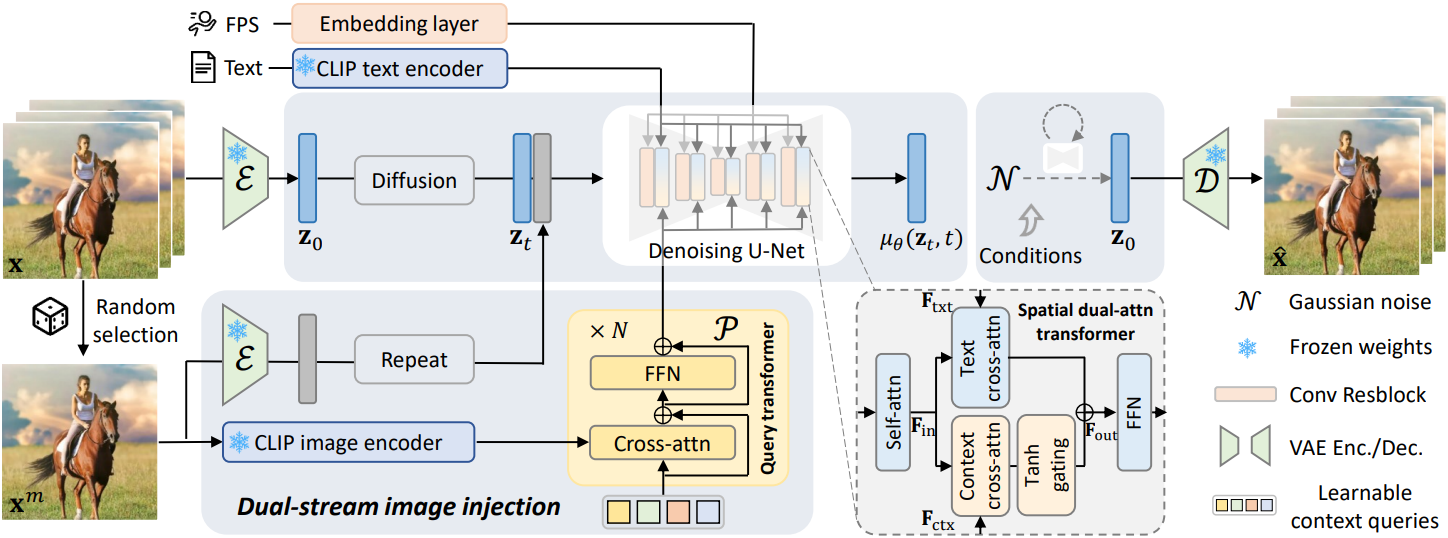
오픈 도메인 T2V diffusion model은 텍스트 설명을 조건으로 다양한 동적 시각적 콘텐츠를 모델링한 것으로 가정한다. T2V generative prior로 정지 이미지를 애니메이션화하려면 시각적 정보를 포괄적인 방식으로 동영상 생성 프로세스에 주입해야 한다. T2V 모델은 컨텍스트 이해를 위해 이미지를 소화해야 하며, 이는 역학 합성에 중요하다. 또한, 생성된 동영상에서 시각적 디테일이 보존되어야 한다. 이러한 통찰력을 바탕으로 저자들은 텍스트와 정렬된 컨텍스트 표현과 visual detail guidance로 구성된 듀얼 스트림 조건부 이미지 주입 패러다임을 제안하였다.
텍스트와 정렬된 컨텍스트 표현
이미지 컨텍스트를 사용하여 동영상 생성을 안내하기 위해, 이미지를 텍스트와 정렬된 embedding space에 projection하여 동영상 모델이 이미지 정보를 활용할 수 있도록 한다. 텍스트 임베딩이 사전 학습된 CLIP 텍스트 인코더로 구성되므로, CLIP 이미지 인코더를 사용하여 입력 이미지에서 이미지 feature를 추출한다. CLIP 이미지 인코더의 글로벌 semantic 토큰 \(\mathbf{f}_\textrm{cls}\)는 이미지 캡션과 잘 정렬되어 있지만, 주로 semantic 레벨에서 시각적 콘텐츠를 나타내며 이미지 전체를 포착하지 못한다.
보다 완전한 정보를 추출하기 위해, 조건부 이미지 생성 task에서 높은 충실도를 보여준 CLIP 이미지 ViT에서 마지막 레이어의 전체 비주얼 토큰 \(\mathbf{F}_\textrm{vis} = \{\mathbf{f}^i\}_{i=1}^K\)을 사용한다. 텍스트 임베딩과의 정렬을 촉진하기 위해, 즉 denoising U-Net에서 해석할 수 있는 컨텍스트 표현을 얻기 위해, 학습 가능한 경량 모델 $\mathcal{P}$를 사용하여 \(\mathbf{F}_\textrm{vis}\)를 최종 컨텍스트 표현 \(\mathbf{F}_\textrm{ctx} = \mathcal{P}(\mathbf{F}_\textrm{vis})\)로 변환한다.
저자들은 $\mathcal{P}$로 query transformer 아키텍처를 채택했다. Query transformer는 cross-attention과 feed-forward network (FFN)의 $N$개 층으로 구성되어 있으며, cross-attention 메커니즘을 통한 모달리티 간 표현 학습에 능숙하다.
그 후, 텍스트 임베딩 \(\mathbf{F}_\textrm{txt}\)와 컨텍스트 임베딩 \(\mathbf{F}_\textrm{ctx}\)는 이중 cross-attention layer를 통해 U-Net 중간 feature \(\mathbf{F}_\textrm{in}\)과 상호 작용한다.
\[\begin{equation} \mathbf{F}_\textrm{out} = \textrm{Softmax} (\frac{\mathbf{Q} \mathbf{K}_\textrm{txt}^\top}{\sqrt{d}}) \mathbf{V}_\textrm{txt} + \lambda \cdot \textrm{Softmax} (\frac{\mathbf{Q} \mathbf{K}_\textrm{ctx}^\top}{\sqrt{d}}) \mathbf{V}_\textrm{ctx} \\ \textrm{where} \; \mathbf{Q} = \mathbf{F}_\textrm{in} \mathbf{W}_\mathbf{Q}, \; \mathbf{K}_\textrm{txt} = \mathbf{F}_\textrm{txt} \mathbf{W}_\mathbf{K} \; \mathbf{V}_\textrm{txt} = \mathbf{F}_\textrm{txt} \mathbf{W}_\mathbf{V} \\ \qquad \mathbf{K}_\textrm{ctx} = \mathbf{F}_\textrm{ctx} \mathbf{W}_\mathbf{K}^\prime, \; \mathbf{V}_\textrm{ctx} = \mathbf{F}_\textrm{ctx} \mathbf{W}_\mathbf{V}^\prime \end{equation}\]특히 $\lambda$는 텍스트로 컨디셔닝된 feature와 이미지로 컨디셔닝된 feature를 융합하는 계수이며, Tanh gating을 통해 계산되고 각 레이어에 대해 적응적으로 학습할 수 있다. 이 디자인은 레이어에 따라 이미지 조건들을 흡수하는 모델의 능력을 용이하게 하는 것을 목표로 한다. U-Net의 중간 레이어는 모양이나 포즈와 더 관련이 있고 양 끝의 레이어는 외형과 더 관련이 있으므로 이미지 feature는 모양에 비교적 덜 영향을 미치는 반면 주로 동영상의 외형에 영향을 미칠 것으로 예상된다.
$\lambda$에 대한 관찰 및 분석
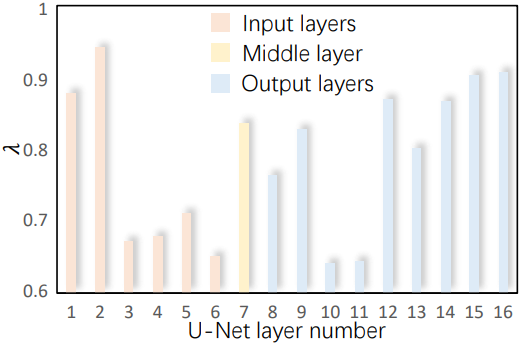
위 그래프는 서로 다른 레이어에서 학습된 $\lambda$를 보여주며, 이는 이미지 정보가 중간 레이어보다 양 끝의 레이어에 더 큰 영향을 미친다는 것을 나타낸다. 저자들은 더 자세히 알아보기 위해 중간 레이어에서 $\lambda$를 수동으로 변경하였다.

위 그림에 나와 있듯이 $\lambda$를 늘리면 프레임 간 움직임이 억제되고 $\lambda$를 줄이면 물체의 모양을 유지하는 데 어려움이 있다. 이러한 관찰 결과는 기대한 바와 일치할 뿐만 아니라 이미지 조건부 diffusion model에서 풍부한 컨텍스트 정보가 U-Net의 특정 중간 레이어에 영향을 미쳐 모델이 모션이 있는 경우에도 입력과 유사한 물체의 모양을 유지할 수 있음을 시사한다.
Visual detail guidance (VDG)

풍부한 정보가 담긴 컨텍스트 표현을 통해 VDM은 입력 이미지와 매우 유사한 동영상을 생성할 수 있다. 그러나 위 그림에서 볼 수 있듯이 사소한 불일치가 여전히 발생할 수 있다. 이는 주로 사전 학습된 CLIP 이미지 인코더가 시각적 feature와 언어적 feature를 정렬하도록 설계되었기 때문에 입력 이미지 정보를 완전히 보존할 수 있는 능력이 제한적이기 때문이다.
저자들은 시각적 일치성을 높이기 위해 동영상 모델에 이미지의 추가 시각적 디테일을 제공할 것을 제안하였다. 구체적으로 조건부 이미지를 프레임별 초기 noise와 concat하여 일종의 guidance로 denoising U-Net에 공급한다. 따라서 제안된 듀얼 스트림 이미지 주입 패러다임에서 VDM은 입력 이미지의 글로벌 컨텍스트와 로컬 디테일을 보완적인 방식으로 통합한다.
Discussion
더욱 유익한 컨텍스트 표현이 제공되는 경우 텍스트 프롬프트가 필요한 이유는 무엇인가? 텍스트와 정렬된 컨텍스트 표현을 사용하지만, 텍스트 임베딩보다 더 광범위한 정보를 전달하므로 T2V 모델이 적절하게 소화하기 어려울 수 있다. 예를 들어 모양 왜곡이 발생할 수 있다. 추가 텍스트 프롬프트는 모델이 이미지 정보를 효율적으로 활용할 수 있도록 하는 글로벌 컨텍스트를 제공할 수 있다. 또한 정지 이미지에는 일반적으로 여러 가지 잠재적인 동적 변형이 포함되므로 텍스트 프롬프트는 사용자 선호도에 맞게 조정된 동적 콘텐츠 생성을 효과적으로 가이드할 수 있다.
VDG가 완전한 이미지를 제공하는데, 풍부한 컨텍스트 표현이 필요한 이유는 무엇인가? 사전 학습된 T2V 모델은 semantic 제어 공간 (텍스트 임베딩)과 보완적인 랜덤 공간 (초기 noise)으로 구성된다. 랜덤 공간은 저수준 정보를 효과적으로 통합하지만, 각 프레임의 noise를 고정된 이미지와 concat하면 잠재적으로 공간적 오정렬이 발생하여 모델을 제어할 수 없는 방향으로 잘못 유도할 수 있다. 이와 관련하여 이미지 임베딩에서 제공하는 정확한 시각적 컨텍스트는 시각적 디테일의 안정적인 활용에 도움이 될 수 있다.
3. Training Paradigm
조건부 이미지는 각각 컨텍스트 제어와 VDG에서 역할을 하는 두 개의 보완적인 스트림을 통해 통합된다. 이를 협력적인 방식으로 조절하기 위해, 저자들은 세 단계로 구성된 전담 학습 전략을 고안하였다.
- 이미지 컨텍스트 표현 네트워크 $\mathcal{P}$를 학습시킨다.
- $\mathcal{P}$를 T2V 모델에 적응시킨다.
- VDG와 공동으로 fine-tuning한다.
T2V 모델에 호환되는 방식으로 이미지 정보를 제공하기 위해, 즉 입력 이미지에서 텍스트 정렬된 시각 정보를 추출하기 위해 컨텍스트 표현 네트워크 $\mathcal{P}$를 학습시킨다. $\mathcal{P}$가 수렴하기 위해 수많은 최적화 단계를 거친다는 사실을 고려하여, T2V 모델 대신 가벼운 T2I 모델을 기반으로 $\mathcal{P}$를 학습시켜 이미지 컨텍스트 학습에 집중한다.
그런 다음 $\mathcal{P}$와 T2V 모델의 spatial layer를 공동으로 학습시켜 T2V 모델에 적응시킨다. T2V에 대한 호환되는 컨텍스트 컨디셔닝 브랜치를 설정한 후, 공동 fine-tuning을 위해 프레임별 noise와 입력 이미지를 concat한다. 여기서 사전 학습된 T2V 모델의 시간적 사전 지식을 방해하는 것을 피하기 위해 $\mathcal{P}$와 VDM의 spatial layer만 fine-tuning한다.
또한, 다음의 두 가지 고려 사항에 따라 동영상 프레임을 무작위로 선택한다.
- 네트워크가 concat된 이미지를 특정 위치의 프레임에 매핑하는 shortcut을 학습하는 것을 방지하기 위함
- 특정 프레임에 대한 지나치게 엄격한 정보를 제공하지 않도록 컨텍스트 표현을 더 유연하게 강제하기 위함 (즉, T2I 기반 context learning의 목적)
Experiment
- 데이터셋: WebVid10M (256$\times$256)
- 구현 디테일
- T2V 모델 VideoCrafter와 T2I 모델 Stable-Diffusion-v2.1 (SD) 기반
- $\mathcal{P}$ 학습
- step: 100만
- learning rate: $1 \times 10^{-4}$
- 유효 mini-batch 크기: 64
- $\mathcal{P}$를 T2V 모델에 적응 & 공동 fine-tuning
- step: 적응 10만 / fine-tuning 30만
- learning rate: $5 \times 10^{-5}$
- 유효 mini-batch 크기: 64
- Inference
- DDIM sampler 적용
- multi-condition classifier-free guidance 사용
Multi-condition classifier-free guidance:
\[\begin{aligned} \hat{\epsilon}_\theta (\mathbf{z}_t, \mathbf{c}_\textrm{img}, \mathbf{c}_\textrm{txt}) &= \epsilon_\theta (\mathbf{z}_t, \varnothing, \varnothing) \\ &+ s_\textrm{img} (\epsilon_\theta (\mathbf{z}_t, \mathbf{c}_\textrm{img}, \varnothing) - \epsilon_\theta (\mathbf{z}_t, \varnothing, \varnothing)) \\ &+ s_\textrm{txt} (\epsilon_\theta (\mathbf{z}_t, \mathbf{c}_\textrm{img}, \mathbf{c}_\textrm{txt}) - \epsilon_\theta (\mathbf{z}_t, \mathbf{c}_\textrm{img}, \varnothing)) \end{aligned}\]저자들은 Perceptual Input Conformity (PIC)라는 새로운 metric을 도입하였다. PIC는 다음과 같이 계산할 수 있다.
\[\begin{equation} \textrm{PIC} = \frac{1}{L} \sum_l (1 - D (\textbf{x}^\textrm{in}, \textbf{x}^l)) \end{equation}\]$\mathbf{x}^\textrm{in}$, $\mathbf{x}^l$, $L$은 각각 입력 이미지, 동영상 프레임, 동영상 길이이며, $D (\cdot, \cdot)$은 perceptual distance인 DreamSim이다.
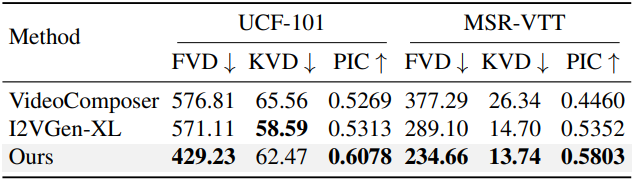
1. Quantitative Evaluation
다음은 UCF-101와 MSR-VTT에서 오픈 도메인 image-to-video 생성 방법들과 정량적으로 비교한 결과이다.
2. Qualitative Evaluation
다음은 다른 방법들과 시각적으로 비교한 결과이다.

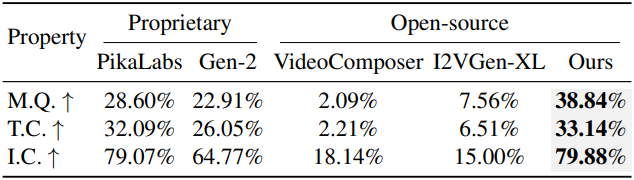
다음은 Motion Quality, Temporal Coherence, Input Conformity에 대한 user study 결과이다.
3. Ablation Studies
다음은 듀얼 스트림 이미지 주입과 학습 패러다임에 대한 ablation 결과이다.


다음은 1단계 적응 단계와 2단계 적응 전략을 시각적으로 비교한 결과이다.

다음은 여러 학습 패러다임에 대하여 시각적으로 비교한 결과이다.

4. Discussions on Motion Control using Text
이미지는 일반적으로 여러 잠재적인 역학과 연관되기 때문에 텍스트는 사용자 선호도에 맞게 조정된 동적 콘텐츠 생성을 보완적으로 가이드할 수 있다. 그러나 기존 대규모 데이터셋의 캡션은 많은 수의 장면 설명 단어와 적은 수의 역학/모션 설명의 조합으로 구성되어 모델이 학습하는 동안 역학/모션을 간과할 가능성이 있다. 장면 설명은 이미 이미지 조건에 포함되어 있기 때문에 모션 설명은 텍스트 조건으로 처리하여 모델을 분리된 방식으로 학습하고 모델에 역학에 대한 더 강력한 텍스트 기반 제어를 제공해야 한다.
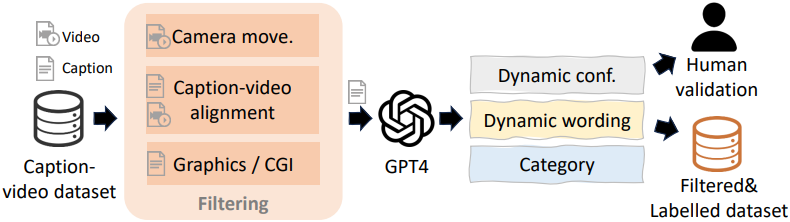
저자들은 분리된 학습을 위해 위 그림에서 볼 수 있듯이 WebVid10M 데이터셋을 필터링하고 다시 주석을 달아 데이터셋을 구성하였다. 그런 다음 이 데이터셋를 사용하여 모델 DynamiCraterDCP를 학습시켰다.
다음은 텍스트를 사용한 동작 제어를 통해 얻은 다양한 방법으로 얻은 이미지 애니메이션 결과를 시각적으로 비교한 것이다.

5. Applications

- 스토리텔링: ChatGPT를 사용하여 스토리 스크립트와 해당 이미지를 생성한다. 그런 다음 DynamiCrafter를 사용하여 스토리 스크립트로 이미지를 애니메이션화하여 스토리텔링 동영상을 생성할 수 있다.
- 반복되는 동영상 생성: 약간의 수정을 통해 반복되는 동영상 생성을 용이하게 하도록 조정될 수 있다. 학습 중에는 \(\textbf{x}^1\)과 \(\textbf{x}^L\)을 모두 VDG로 제공하고 다른 프레임은 비워둔다. Inference 시에는 둘 다 입력 이미지로 설정한다.
- 프레임 보간: 입력 이미지 \(\textbf{x}^1\)과 \(\textbf{x}^L\)을 다르게 설정하여 중간 프레임을 생성할 수 있다.