[AI소식] gpt2-chatbot
LLM 리더보드인 LMSYS에 gpt2-chatbot이라는 정체불명의 LLM이 등장했는데 특정 벤치마크에서 GPT-4보다 성능이 좋다고 한다.
“⚔️ Arena (battle)”의 경우 벤치마킹을 위해 블라인드 처리되어 있으며 “💬 Direct Chat”을 통해 직접 사용해 볼 수 있다.
이와 관련하여 OpenAI CEO인 샘 올트먼이 트윗을 게시했다.
i do have a soft spot for gpt2
— Sam Altman (@sama) April 30, 2024
그리고 5월 14일 GPT-4o가 출시되었으며, OpenAI 연구원인 William Fedus가 트윗을 통해 gpt2-chatbot는 GPT-4o임을 밝혔다.
GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot 🙂. Here’s how it’s been doing. pic.twitter.com/xEE2bYQbRk
— William Fedus (@LiamFedus) May 13, 2024
또한 LMSYS Arena에서의 테스트 결과(ELO)를 함께 공개하였는데, 기존 1위였던 GPT 4 Turbo의 1253점보다 57점을 앞선 1310점을 기록하며 새로운 SOTA가 되었다.
성능 및 특징
누군가가 rentry에 관련 내용과 LMSYS의 여러 결과들을 정리해 두었다.
- 다양한 도메인의 평균 출력 품질은 최소 GPT-4 및 Claude Opus와 같은 고급 모델과 동일한 수준에 있다.
- 메시지 개수 제한은 시간당 1000개이며 (일일 24,000개 메시지) 이는 gpt-4-1106-preview의 10배이다. 출력 품질을 고려할 때 대규모 컴퓨팅 능력 및/또는 매우 효율적인 모델임을 의미할 수 있다.
- OpenAI의 tiktoken 토크나이저를 사용하는 것으로 보인다. 이는 gpt2-chatbot과 기타 여러 모델에 대한 특수 토큰의 효과를 비교하여 확인되었다.
- 보조 명령(assistant instruction)을 추출한 결과 GPT-4 아키텍처를 기반으로 하며 “Personality: v2”를 사용한다.
- 디테일한 연락처를 요구하면 GPT-3.5/4보다 더 자세하게 OpenAI의 연락처 정보를 제공한다.
- 스스로를 GPT-4 기반이라 주장하며, 자신을 “ChatGPT” 또는 “a ChatGPT”로 부른다. 일반적으로 OpenAI 모델로 생성된 데이터셋으로 학습된 다른 모델들이 혼란스러운 답변을 하는 것과는 구별되게 스스로를 표현하는 방식이 다르다.
- OpenAI 모델들과 동일한 프롬프트 삽입 (prompt injection) 취약점을 보인다.
- 한 번도 OpenAI가 아닌 다른 단체에 속해 있다고 주장한 적이 없다.
- Anthropic, Meta, Mistral, Google 등의 모델들은 동일한 프롬프트에 대해 gpt2-chatbot과 다른 출력을 일관되게 출력한다.
- 수정된 CoT(Chain-of-Thought)와 같은 기술의 영향을 많이 받는 것으로 보인다.
GPT-4o 출시 전 추측들
gpt2-chatbot이 공개된 이후 정체를 둘러싼 여러 추측들이 나오고 있다.
- GPT-4.5의 초기 버전
- MoE (Mixture of Experts)와 비슷한 것을 사용하여 여러 LLM을 하나로 합친 모델
- 이름대로 GPT-2를 기반으로 새로운 기술이 적용된 모델
- 최근 LMSYS를 후원하고 있는 MBZUAI의 논문에서 GPT-2 아키텍처의 세부 사항을 심층적으로 연구했는데, 짧은 학습 기간 동안 지식 저장 측면에서 GPT-2가 LLaMA/Mistral 아키텍처와 일치하거나 심지어 능가한다고 한다.
- LMSYS가 학습을 위해 LMSYS를 통해 생성된 데이터를 활용하였다면, gpt2-chatbot이 스스로를 GPT-4로 식별하는 강한 경향이 GPT-4에서 생성된 데이터를 주로 활용하였기 때문이라고 설명할 수 있다.
- 더 큰 Phi-3 버전 (아마도 14B)
the perfect TikZ unicorn is one of the top criteria for AGI
— ChatGPT (@ChatGPTapp) May 3, 2024
예시
아래는 rentry에 있는 Claude 3 Opus와의 비교 예시이다. (왼쪽: Claude 3 Opus / 오른쪽: gpt2-chatbot)
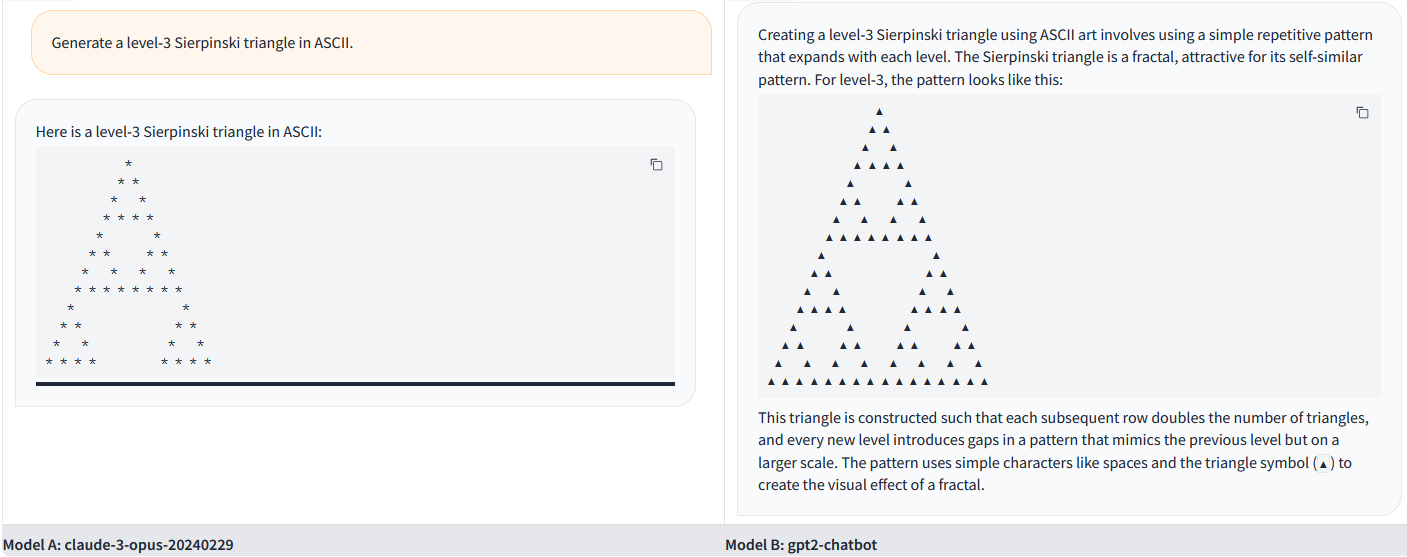
프롬프트는 Generate a level-3 Sierpinski triangle in ASCII.이며, Claude 3 Opus보다 더 정확하고 자세한 결과를 보인다.