[논문리뷰] ZIM: Zero-Shot Image Matting for Anything
ICCV 2025 (Highlight). [Paper] [Page] [Github]
Beomyoung Kim, Chanyong Shin, Joonhyun Jeong, Hyungsik Jung, Se-Yun Lee, Sewhan Chun, Dong-Hyun Hwang, Joonsang Yu
NAVER Cloud, ImageVision
1 Nov 2024

Introduction
Segmentation foundation model인 Segment Anything Model (SAM)의 등장으로 image segmentation이 상당한 진전을 이루었다. SAM은 10억 개의 micro-level segmentation 레이블이 포함된 SA1B 데이터셋에서 학습되었으며, 그 광범위성 덕분에 SAM은 광범위한 task에 걸쳐 효과적으로 일반화할 수 있다. 비주얼 프롬프트로 구동되는 강력한 zero-shot 능력은 zero-shot interactive segmentation의 SOTA를 재정의하고 보다 복잡한 task를 해결하기 위한 새로운 길을 열었다.
이러한 성과에도 불구하고 SAM은 종종 세밀한 정밀도로 마스크를 생성하는 데 어려움을 겪는다. 이러한 한계를 해결하기 위해 최근 연구에서는 SAM을 image matting task로 확장하여 매우 세부적인 경계와 개별 머리카락 가닥과 같은 복잡한 디테일을 캡처하는 데 중점을 두었다. 이러한 접근 방식은 공개 matting 데이터셋에서 SAM을 fine-tuning하여 향상된 마스크 정밀도를 달성하였다.

그러나 이 fine-tuning 프로세스는 SAM의 zero-shot 잠재력을 훼손할 수 있다. 이는 대부분의 공개 matting 데이터셋이 위 그림에서 볼 수 있듯이 micro-level 레이블이 아닌 macro-level 레이블만 포함되어 있기 때문이다. Macro-level 레이블로 fine-tuning하면 SAM이 이 macro-level 세분성에 overfitting되어 micro-level 세분성에서 일반화하는 능력을 망각하게 될 수 있다. 게다가 micro-level의 matte 레이블이 있는 대규모 matting 데이터셋이 부족하여 효과적인 zero-shot matting model을 개발하는 데 상당한 장애물이 된다.
본 논문에서는 Zero-shot Image Matting (ZIM) 모델을 소개한다. 이 모델은 강력한 zero-shot 능력을 유지하면서도 고품질 micro-level matting 마스크를 생성한다. 이 도메인의 핵심 과제는 주석을 달기 위해 비용이 많이 들고 노동 집약적인 광범위한 micro-level 레이블이 있는 matting 데이터셋이 필요하다는 것이다.
이를 위해 저자들은 모든 segmentation 레이블을 자세한 matte 레이블로 변환하는 새로운 레이블 변환 방법을 제안하였다. 보다 안정적인 레이블 변환을 위해 Spatial Generalization Augmentation (SGA)과 Selective Transformation Learning (STL)이라는 두 가지 효과적인 전략을 사용하여 노이즈를 줄이고 충실도가 높은 matte 레이블을 생성하였다. 그런 다음 SA1B-Matte라는 새로운 데이터셋을 구성하였다. 여기에는 제안된 변환기를 통해 SA1B 데이터셋에서 segmentation 레이블을 변환하여 생성된 광범위한 micro-level 레이블들이 포함된다. SA1B-Matte 데이터셋에서 SAM을 학습시킴으로써 SAM의 zero-shot 능력을 유지하면서 micro-level의 세분성을 갖춘 효과적인 foundation matting model을 도입하였다.
효과적인 interactive image matting을 더욱 보장하기 위해, 저자들은 robust하고 세부적인 feature map을 캡처하는 것을 방해하는 SAM의 네트워크 아키텍처를 개선하였다. 구체적으로, SAM은 간단한 두 개의 transposed convolutional layer가 있는 픽셀 디코더를 사용하여 stride가 4인 mask feature map들을 생성하는데, 이는 체커보드 아티팩트에 취약하고 종종 디테일을 캡처하는 데 부족하다.
이를 완화하기 위해, 저자들은 ViTMatte에서 영감을 받은 계층적 feature pyramid 디자인을 사용하여 보다 정교해진 픽셀 디코더를 구현하였으며, 이를 통해 보다 robust하고 풍부한 마스크 feature 표현을 가능하게 하였다. 또한 Mask2Former 프레임워크에서 영감을 받아, 모델이 비주얼 프롬프트로 지정된 영역에 초점을 맞출 수 있도록 하여 interactive matting 성능을 개선하는 prompt-aware masked attention 메커니즘을 도입하였다.
저자들은 zero-shot matting model을 검증하기 위해 3,000개의 고품질 micro-level matte 레이블로 구성된 MicroMat-3K라는 새로운 test set을 제시하였다. 이 데이터셋에 대한 실험은 SAM이 강력한 zero-shot 능력을 보여주지만 정밀한 마스크 출력을 제공하는 데 어려움을 겪는다는 것을 보여준다. 기존 matting model은 제한된 zero-shot 성능을 보여준다. 반면, ZIM은 강력한 zero-shot 능력을 유지할 뿐만 아니라 마스크 생성에서 뛰어난 정밀도를 제공한다.
Methodology
1. Constructing the Zero-Shot Matting Dataset
동기
효과적인 zero-shot matting을 위해서는 micro-level의 matte 레이블을 갖춘 데이터셋이 필수적이다. 그러나 micro-level에서 레이블을 수동으로 주석 처리하는 것은 막대한 인력과 비용이 요구된다.
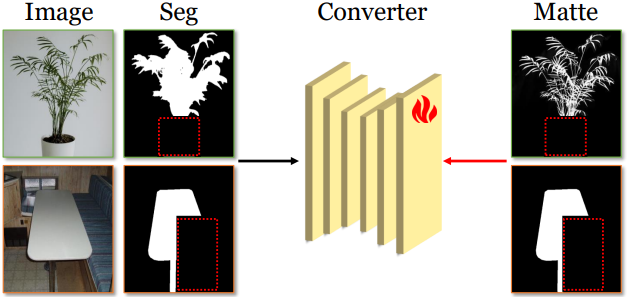
이를 해결하기 위해, 저자들은 어떤 segmentation 레이블도 matte 레이블로 변환할 수 있는 혁신적인 레이블 변환기를 제안하였다. 먼저, image matting 공개 데이터셋을 수집하여 변환기를 학습시킨다. 이 데이터셋들은 matte 레이블만 제공하기 때문에, 이미지 처리 기술 (ex. thresholding, resolution downscaling, Gaussian blurring, dilation, erosion, convex hull transformation)을 사용하여 matte 레이블로부터 대략적인 segmentation 레이블을 유도한다. 레이블 변환기는 이미지와 segmentation 레이블을 입력으로 받아, 이에 상응하는 matte 레이블을 생성하도록 학습된다.
과제
이 접근 방식은 두 가지 주요 과제를 제기한다.
- 보지 못한 패턴에 대한 일반화. 공개 matting 데이터셋은 주로 전체 초상화나 큰 물체 마스크와 같은 macro-level의 레이블을 포함하고 있다. 따라서, 이러한 데이터셋에서 학습된 변환기는 micro-level의 물체에 대한 일반화에 어려움을 겪는 경우가 많다. 이러한 한계로 인해 micro-level의 segmentation에 적용할 때 노이즈가 섞인 matte 레이블을 생성하게 된다.
- 불필요하게 디테일한 표현. 자동차나 상자와 같은 일부 물체는 디테일한 표현이 필요하지 않은 경우가 많다. 그러나 레이블 변환기가 항상 segmentation 레이블을 디테일한 matte 레이블로 변환하도록 학습되었기 때문에, 종종 디테일한 표현이 필요하지 않은 물체에 불필요한 노이즈를 함께 생성하게 된다.
Spatial Generalization Augmentation (SGA)
저자들은 변환기의 다양한 segmentation 레이블에 대한 일반화 능력을 향상시키기 위해 SGA를 설계했다. 이 접근 방식은 학습 데이터에 변화를 주기 위해 무작위 컷아웃 기법을 적용한다. 학습 중에는 segmentation 레이블과 matte 레이블이 동일한 영역에서 무작위로 잘린다. 변환기를 불규칙하고 불완전한 입력 패턴에 노출시킴으로써, 이 augmentation 기법은 변환기가 다양한 공간 구조와 보지 못한 패턴에 적응하도록 강제하여 일반화 능력을 향상시킨다.
Selective Transformation Learning (STL)
저자들은 디테일한 표현이 필요하지 않은 물체에 대한 불필요한 변환을 방지하기 위해 STL을 도입했다. 이 기법은 변환기가 디테일한 matte 변환이 필요한 물체에만 선택적으로 집중하고, 세밀한 변환이 필요 없는 물체에 대해서는 이를 생략할 수 있도록 한다.

이를 위해, 저자들은 공개 segmentation 데이터셋에서 coarse한 물체 마스크를 수집하여 학습 과정에 포함시켰다. 학습 중에는 변환이 필요 없는 샘플에 대해, 실제 matte 레이블을 원래 segmentation 레이블과 동일하게 설정하여 변환기에게 변환이 필요하지 않음을 학습시킨다. 이러한 선택적 접근 방식은 출력 노이즈를 줄이고, 세부 변환이 필요할 때만 적용되도록 보장한다.
학습
저자들은 matting task에서 일반적으로 사용되는 표준 loss function을 채택하였다. 즉, L1 loss와 gradient loss의 선형 결합을 사용하여 GT와 예측된 matte 간의 픽셀별 차이를 최소화한다.
\[\begin{aligned} L &= L_{\ell 1} + \lambda L_\textrm{grad} \\ L_{\ell 1} &= \vert M - M^\prime \vert \\ L_\textrm{grad} &= \vert \nabla_x (M) - \nabla_x (M^\prime) \vert + \vert \nabla_y (M) - \nabla_y (M^\prime) \vert \end{aligned}\]($M$은 실제 matte 레이블, $M^\prime$은 예측된 matte 레이블)
또한, 학습 중에 SGA의 무작위 적용을 제어하기 위해 확률 파라미터 $p$를 설정했다.
SA1B-Matte 데이터셋
레이블 변환기를 학습한 후, 변환기를 사용하여 SA1B 데이터셋의 segmentation 레이블을 matte 레이블로 변환하여 새로운 SA1B-Matte 데이터셋을 구성한다. Macro-level의 레이블로 구성된 기존 공개 matting 데이터셋과 비교했을 때, SA1B-Matte 데이터셋은 micro-level의 레이블이 있는 대규모 image matting 데이터셋으로, zero-shot matting model을 개발하기 위한 이상적인 기반을 제공한다.
2. ZIM: Zero-Shot Image Matting Model

개요
ZIM은 SAM의 네트워크 아키텍처를 기반으로 하며, 네 가지 구성 요소로 구성된다.
- 이미지 인코더: 입력 이미지에서 이미지 feature를 추출하여 stride가 16인 이미지 임베딩을 생성한다.
- 프롬프트 인코더: 포인트 또는 박스 입력을 프롬프트 임베딩으로 인코딩한다. 프롬프트 임베딩은 학습 가능한 토큰 임베딩과 concat되어 ViT의 [cls] 토큰과 유사한 역할을 한다.
- Transformer 디코더: 이미지와 토큰 임베딩을 사용하여 출력 토큰 임베딩을 생성한다. 토큰에 대한 self-attention, token-to-image cross-attention, MLP layer, 이미지 임베딩을 업데이트하는 image-to-token cross-attention의 네 가지 연산을 수행한다.
- 픽셀 디코더: stride 2로 출력 이미지 임베딩을 업샘플링한다.
마지막으로 모델은 업샘플링된 이미지 임베딩과 출력 토큰 임베딩 간의 내적을 계산하여 matte 마스크를 생성한다.
동기
SAM은 segmentation task에서 성공을 거두었지만, 두 개의 간단한 transposed convolutional layer로 구성된 픽셀 디코더는 특히 물체 경계 근처에 배치된 여러 개의 포인트나 부정확한 물체 영역 구분이 있는 박스 프롬프트와 같이 어려운 비주얼 프롬프트를 처리할 때 체커보드 아티팩트를 생성하는 경향이 있다. 또한 stride가 4인 업샘플링 임베딩은 더 세밀한 mask feature 표현의 이점을 얻는 image matting에는 종종 부족하다.
계층적 픽셀 디코더
이러한 한계를 해결하기 위해 multi-level feature pyramid 디자인을 가진 계층적 픽셀 디코더를 도입한다. 픽셀 디코더는 입력 이미지를 가져와 일련의 간단한 convolutional layer를 사용하여 stride 2, 4, 8에서 여러 해상도의 feature map을 생성한다. 이미지 임베딩은 순차적으로 업샘플링되고 각 해상도에서 대응되는 feature map과 concat된다. 디코더는 매우 가볍게 설계되었으며, SAM의 원래 픽셀 디코더와 비교하여 V100 GPU에서 10ms의 계산 오버헤드만 추가된다.
계층적 디자인은 두 가지 주요 목적을 달성한다.
- 이전 및 더 깊은 네트워크 레이어 간에 multi-level skip connection을 통합함으로써 계층적 디코더는 공간적 디테일을 점진적으로 정제하면서 높은 수준의 semantic 정보를 보존한다. 이를 통해 보다 정확한 matte 출력을 제공하고 체커보드 아티팩트의 잠재적 위험을 줄여 아키텍처를 까다로운 입력 프롬프트에 더욱 robust하게 만든다.
- 디코더가 SAM의 coarse한 stride 4가 아닌 stride 2로 고해상도 feature map을 robust하게 생성할 수 있도록 한다. 이 더 세밀한 해상도는 높은 공간적 정밀도가 필요한 image matting에서 자세한 matte 출력을 얻는 데 필수적이다.
Prompt-Aware Masked Attention
저자들은 interactive matting 성능을 더욱 높이기 위해 Mask2Former에서 영감을 받은 Prompt-Aware Masked Attention 메커니즘을 제안하였다. 이 메커니즘을 사용하면 모델이 비주얼 프롬프트 (ex. 포인트, 상자)를 기반으로 이미지 내의 관련 영역에 동적으로 초점을 맞춰 관심 영역에 더 많은 attention을 할 수 있다.
박스 프롬프트의 경우, 특정 bounding box 영역을 나타내는 binary attention mask $\mathcal{M}^b$를 생성한다. \(\mathcal{M}^b \in \{0, -\infty\}\)는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{M}^b (x, y) = \begin{cases}0 & \textrm{if} \; (x,y) \in \textrm{box region} \\ -\infty & \textrm{otherwise}\end{cases} \end{equation}\]이는 모델이 박스 프롬프트 내의 영역을 우선시하도록 강제한다.
포인트 프롬프트의 경우 표준 편차가 $\sigma$인 2D Gaussian map 분포를 사용하여 soft attention mask $\mathcal{M}^p$를 생성한다. \($\mathcal{M}^p$ \in [0, 1]\)는 관심 지점 주변 영역을 부드럽게 가중하여 주변 영역으로 부드럽게 전환되도록 한다.
Attention mask는 Transformer 디코더의 cross-attention block에 통합된다. 구체적으로 attention mask는 attention map을 다음과 같이 변조한다.
\[\begin{equation} X_l = \begin{cases} \textrm{softmax}(\mathcal{M}^b + Q_l K_l^\top) V_l + X_{l-1} & (\textrm{box prompt}) \\ \textrm{softmax}(\mathcal{M}^p \odot Q_l K_l^\top) V_l + X_{l-1} & (\textrm{point prompt}) \end{cases} \end{equation}\]($\odot$은 element-wise multiplication, $X_l$은 디코더의 $l$번째 레이어에 있는 query feature map, $Q_l$, $K_l$, $V_l$은 $l$번째 레이어에 있는 query, key, value 행렬)
이 메커니즘은 비주얼 프롬프트에 따라 모델의 attention을 동적으로 조정하여 프롬프트 기반의 interactive matting 성능을 향상시킨다.
학습
SA1B-Matte 데이터셋을 사용하여 ZIM 모델을 학습시킨다. 각 GT matte 레이블에 대해 주어진 최소-최대 좌표에서 박스 프롬프트를 추출한다. 여기서 박스 프롬프트의 크기는 학습 중에 원래 크기의 최대 10%까지 무작위로 변경된다. 또한, 무작위로 positive 포인트 프롬프트와 negative 포인트 프롬프트를 샘플링한다. 모델은 변환기를 학습할 때 사용한 loss와 동일한 loss를 사용하여 최적화된다.
MicroMat-3K: Zero-Shot Matting Test Set
저자들은 zero-shot interactive matting 모델을 평가하기 위해 MicroMat-3K라는 새로운 test set을 도입하였다. MicroMat-3K는 micro-level의 matte 레이블과 페어링된 3,000개의 고해상도 이미지로 구성되어 있어 다양한 수준의 디테일에서 다양한 matting model을 테스트하기 위한 포괄적인 벤치마크를 제공한다. 두 가지 유형의 matte 레이블이 포함된다.
- Fine-grained label은 복잡한 디테일을 포착하는 것이 중요한 zero-shot matting 성능을 주로 평가한다.
- Coarse-grained label은 여전히 zero-shot matting task에 필수적인 zero-shot segmentation model과 비교할 수 있도록 한다. 또한, 미리 정의된 positive/negative 포인트 프롬프트들과 대화형 시나리오를 평가하기 위한 박스 프롬프트들을 제공한다.
Experiments
- 구현 디테일
- 입력 크기: 1024$\times$1024
- optimizer: AdamW
- 레이블 변환기
- MGMatting 기반 (backbone: Hiera-base-plus)
- learning rate: 0.001 (cosine decay)
- batch size: 16 / iteration: 50만
- $p$ = 0.5, $\lambda$ = 10
- ZIM
- SAM과 동일한 이미지 인코더 & 프롬프트 인코더
- 사전 학습된 SAM을 SA1B-Matte의 1%로 fine-tuning
- learning rate: 0.00001 (cosine decay)
- batch size: 16 / iteration: 50만
- $\lambda$ = 10, $\sigma$ = 21
1. Results
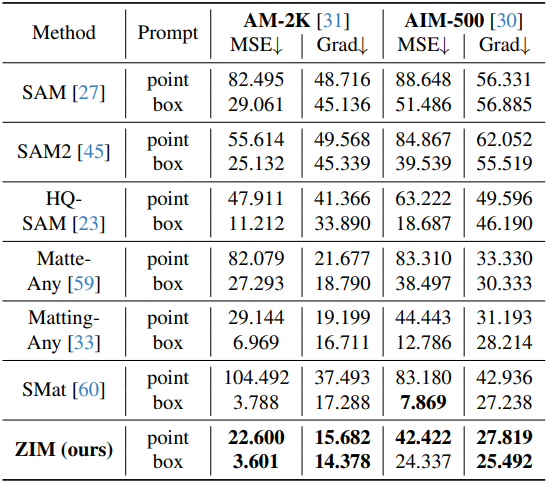
다음은 MicroMat-3K test set에서 기존 방법들과 비교한 결과이다.

다음은 AM-2K와 AIM-500에서 기존 방법들과 비교한 결과이다.
2. Ablation Study
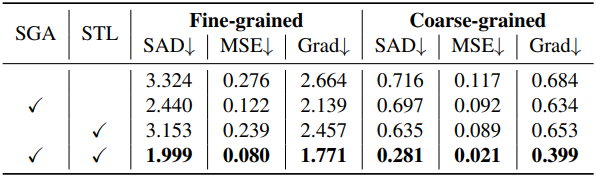
다음은 (왼쪽) SGA와 (오른쪽) STL에 대한 ablation 결과이다.

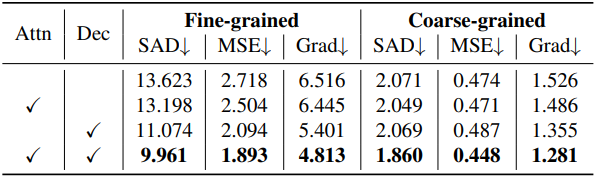
다음은 prompt-aware masked attention (Attn)과 계층적 픽셀 디코더 (Dec)에 대한 ablation 결과이다.
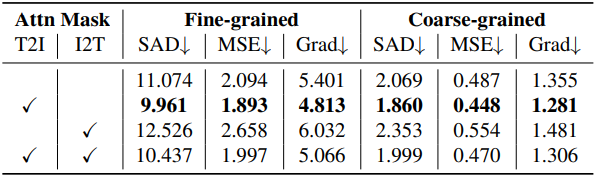
다음은 token-to-image (T2I)와 image-to-token (I2T) cross-attention layer에 대한 ablation 결과이다.
Downstream Task
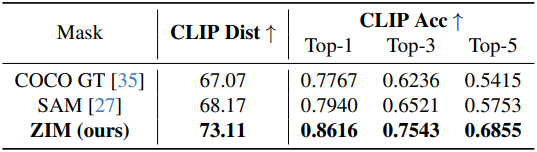
1. Image Inpainting
다음은 이미지 인페인팅에 대한 결과이다.

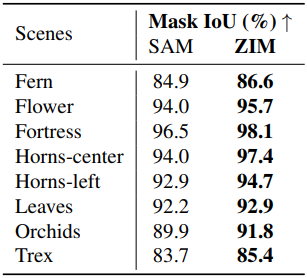
2. 3D Object Segmentation with NeRF
다음은 SA3D를 사용한 3D segmentation 결과를 SAM과 비교한 것이다.

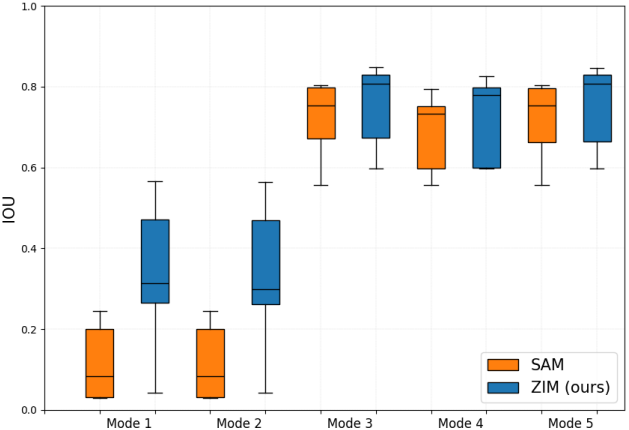
다음은 NVOS 데이터셋에서의 IoU를 비교한 표이다.
3. Medical Image Segmentation
다음은 5가지 의료 이미지 데이터셋에서 ZIM과 SAM의 성능을 비교한 결과이다.