[논문리뷰] Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
arXiv 2023. [Paper] [Github]
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, Hao Su
UC San Diego | Stanford University | Tsinghua University | UCLA | Zhejiang University
23 Oct 2023

Introduction
3D 콘텐츠 생성은 인터넷에서 가져온 광범위한 데이터셋에서 학습한 강력한 2D diffusion 생성 prior를 활용하는 새로운 뷰 생성 모델을 통해 상당한 진전을 보였다. Zero-1-to-3 (또는 Zero123)은 zero-shot의 새로운 뷰 합성을 통해 단일 이미지에서 3D로의 변환을 개척하였다. 유망한 성능에도 불구하고 생성된 이미지의 기하학적 불일치로 인해 아직 멀티뷰 이미지와 3D 장면 간의 격차가 해소되지 않았다. 최근 연구들에서는 Zero-1-to-3에 추가 레이어를 구축하여 보다 일관된 3D 결과를 얻었다. DreamFusion, ProlificDreamer, DreamGaussian과 같은 최적화 기반 방법은 일관되지 않은 모델에서 3D 표현을 추출하여 3D 결과를 얻었다. 이러한 기술은 효과적이지만 일관된 멀티뷰 이미지를 생성하는 기본 diffusion model을 사용하면 훨씬 더 잘 작동할 수 있다. 이러한 관점에서 저자들은 Zero-1-to-3를 다시 검토하고 Stable Diffusion으로부터 새로운 일관된 멀티뷰를 생성하는 기본 diffusion model을 fine-tuning하였다.
Zero-1-to-3는 각각의 새로운 뷰를 독립적으로 생성한다. Diffusion model의 샘플링 특성으로 인해 이 접근 방식은 생성된 뷰 간의 일관성이 손상되는 결과를 가져온다. 이 문제를 해결하기 위해 저자들은 객체를 둘러싼 6개의 뷰를 하나의 이미지로 타일링하는 전략을 채택하였다. 이 타일링 레이아웃을 통해 객체의 멀티뷰 이미지의 공동 분포를 올바르게 모델링할 수 있다.
Zero-1-to-3의 또 다른 문제는 Stable Diffusion이 제공하는 기존 능력의 활용도가 낮다는 것이다. 저자들은 이를 두 가지 설계 문제로 생각하였다.
- 이미지 조건을 사용하여 학습하는 동안 Zero-1-to-3는 Stable Diffusion에서 제공하는 글로벌 또는 로컬 컨디셔닝 메커니즘을 효과적으로 통합하지 않는다. 저자들은 Stable Diffusion prior의 활용을 극대화하기 위해 다양한 컨디셔닝 기술을 구현하는 신중한 접근 방식을 취했다.
- Zero-1-to-3는 학습에 축소된 해상도를 사용한다. 출력 해상도를 학습 해상도 이하로 줄이면 Stable Diffusion 모델의 이미지 생성 품질이 저하될 수 있다는 것이 널리 알려져 있다. 그러나 Zero-1-to-3는 기본 해상도인 512에서 학습할 때 불안정성에 직면하여 더 낮은 해상도인 256을 선택했다. 저자들은 이 동작에 대한 심층 분석을 수행하고 이 문제를 해결하기 위한 일련의 전략을 제안했다.
Improving Consistency and Conditioning
1. Multi-view Generation
일관된 멀티뷰 이미지 생성의 핵심은 여러 이미지의 결합 분포를 올바르게 모델링하는 것이다. Zero-1-to-3는 각 이미지의 조건부 주변 분포를 개별적으로 및 독립적으로 모델링하며, 이는 멀티뷰 이미지 간의 상관 관계를 무시한다.
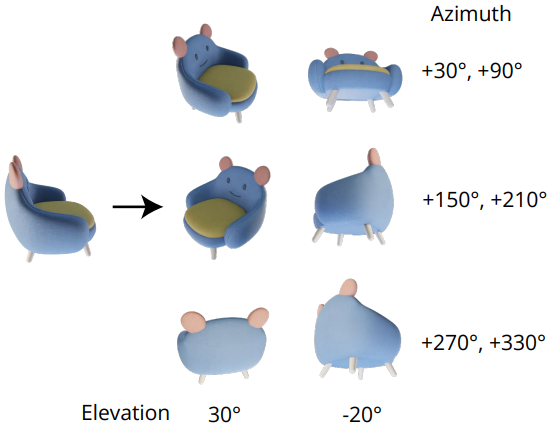
Zero123++에서는 멀티뷰 생성을 위해 위 그림과 같이 3$\times$2 레이아웃의 6개 이미지를 단일 프레임으로 타일링하는 가장 간단한 형태를 취한다.
객체 및 카메라 포즈의 맥락에서 Objaverse 데이터셋은 일반적으로 중력 축을 따라 방향이 지정됨에도 불구하고 객체를 표준 포즈로 일관되게 정렬하지 않는다는 점에 주목할 가치가 있다. 결과적으로 객체의 절대적인 방향은 광범위한다. 저자들은 절대적인 카메라 포즈에 대한 모델 학습이 객체 방향을 명확하게 하는 데 어려움을 겪을 수 있다는 것을 관찰했다. 반대로 Zero-1-to-3는 입력 뷰에 대한 상대적인 방위각(azimuth)과 고도각(elevation)을 사용하여 카메라 포즈에 대해 학습된다. 그러나 이를 위해서는 새로운 뷰 사이의 상대적인 포즈를 결정하기 위해 입력 뷰의 고도각을 알아야 한다. 결과적으로 다양한 기존 파이프라인에는 추가 고도각 추정 모듈이 통합되어 파이프라인에 추가 오차가 발생한다.
이러한 문제를 해결하기 위해 고정된 절대적인 고도각과 상대적인 방위각을 새로운 뷰 포즈로 사용하여 추가 고도각 추정 없이 방향 모호성을 제거한다. 보다 구체적으로, 6개의 포즈는 아래쪽으로 30도, 위쪽으로 20도의 인터리빙 고도로 구성되며, 각 포즈에 대해 30도에서 시작하여 60도씩 증가하는 방위각과 결합된다.
2. Consistency and Stability: Noise Schedule
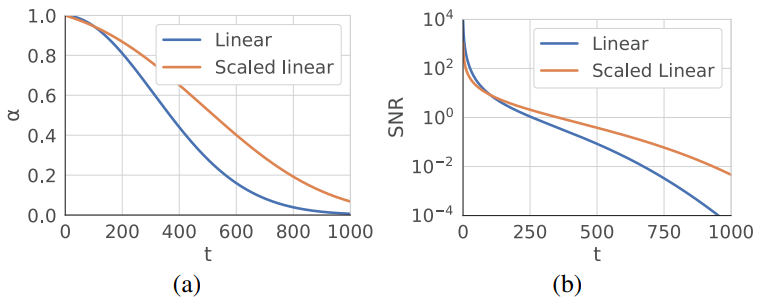
Stable Diffusion의 원래 noise schedule, 즉 scaled-linear schedule은 로컬한 디테일에 중점을 두지만 위 그림과 같이 신호 대 잡음비(SNR)가 낮은 step이 거의 없다. 이러한 낮은 SNR step은 초기 denoising step에서 발생하며, 이는 콘텐츠의 전체 저주파 구조를 결정하는 데 중요하다. 학습이나 inference 중에 이 step의 step 수가 줄어들면 구조적 변형이 더 커질 수 있다. 이 설정은 단일 이미지 생성에 적합하지만 멀티뷰 사이의 글로벌한 일관성을 보장하는 모델의 능력을 제한한다.

저자들은 이를 실증적으로 검증하기 위해 Stable Diffusion 2 $v$-prediction 모델에서 LoRA 모델을 fine-tuning하여 프롬프트 “a police car”에 따라 빈 흰색 이미지를 overfitting하는 toy task를 수행하였다. 결과는 위 그림에 나와 있다. 놀랍게도 scaled-linear schedule을 사용하면 LoRA 모델이 이 간단한 task에 overfitting될 수 없다. 이미지가 약간 하얗게 변했을 뿐이다. 대조적으로, linear schedule을 사용하는 LoRA 모델은 프롬프트에 관계없이 빈 흰색 이미지를 성공적으로 생성한다. 이를 통해 noise schedule이 새로운 글로벌 요구 사항에 적응하는 모델의 능력에 중요한 영향을 미친다는 것을 알 수 있다.
고해상도 이미지는 동일한 절대적인 수준의 독립적인 noise에 노출될 때 저해상도 이미지에 비해 noise가 덜하다. 이 현상은 고해상도의 자연 이미지는 근처 픽셀에서 더 높은 수준의 중복성을 나타내는 경향이 있으므로 동일한 수준의 독립적인 noise로 파괴되는 정보가 적기 때문에 발생한다. 결과적으로 Zero-1-to-3 학습에서 더 낮은 해상도를 사용하는 것을 noise schedule의 수정으로 해석하여 3D 일관성 멀티뷰 생성의 글로벌 요구 사항에 더 중점을 둘 수 있다. 이는 또한 더 높은 해상도에서의 Zero-1-to-3 학습의 불안정성 문제를 설명한다.

요약하자면, 모델의 noise에 대해 scaled-linear schedule에서 linear-schedule로 전환해야 한다. 그러나 이러한 변화는 사전 학습된 모델을 새로운 schedule에 맞게 조정하는 또 다른 잠재적인 문제를 야기한다. 위 그림은 Stable Diffusion 2의 schedule을 scaled-linear에서 linear로 바꾸었을 때 프롬프트 “a blue clock with black numbers”에 대한 $v$-prediction(왼쪽)과 $\epsilon$-prediction(오른쪽)의 결과이다. 다행히도 $x_0$-prediction과 $\epsilon$-prediction과 달리 $v$-prediction 모델은 schedule을 교환할 때 매우 강력하다. 또한 $v$-prediction이 본질적으로 안정적이라는 것도 이론적으로 뒷받침된다. 따라서 저자들은 Stable Diffusion 2 $v$-prediction 모델을 fine-tuning을 위한 기본 모델로 활용하기로 결정했다.
3. Local Condition: Scaled Reference Attention
Zero-1-to-3에서는 컨디셔닝 이미지 (하나의 뷰 입력)가 feature 차원에서 로컬 이미지 컨디셔닝을 위해 denoising되는 입력과 concatenate된다. 이로 인해 입력 이미지와 타겟 이미지 사이에 잘못된 픽셀 단위의 공간적 대응이 적용된다.
본 논문은 적절한 로컬 컨디셔닝 입력을 제공하기 위해 스케일링된 버전의 Reference Attention을 사용할 것을 제안한다.
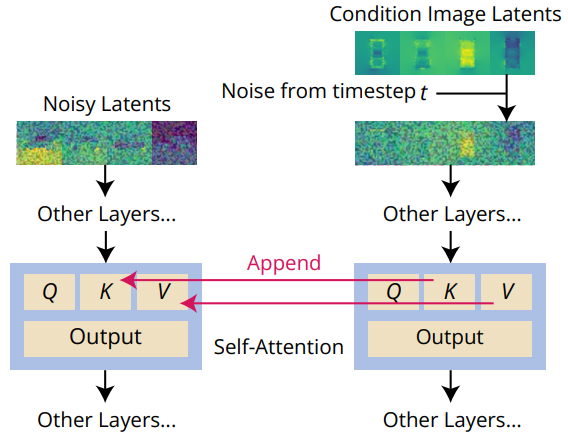
위 그림에서 볼 수 있듯이 Reference Attention은 추가 레퍼런스 이미지에서 denoising UNet 모델을 실행하고 모델 입력을 denoising할 때 레퍼런스 이미지의 self-attention key와 value 행렬을 해당 attention 레이어에 추가하는 연산이다. Denoising 입력과 동일한 수준의 Gaussian noise가 레퍼런스 이미지에 추가되어 UNet이 현재 noise 수준에서 denoising을 위한 관련 feature에 attend할 수 있다.

Fine-tuning 없이도 Reference Attention은 이미 diffusion model을 가이드하여 레퍼런스 이미지와 유사한 의미론적 내용과 텍스처를 공유하는 이미지를 생성할 수 있다. 저자들은 fine-tuning을 하면 latent를 스케일링할 때 Reference Attention이 더 잘 작동하는 것을 관찰했다. 위 그림은 레퍼런스 latent가 5배로 스케일링될 때 모델이 컨디셔닝 이미지와 가장 높은 일관성을 달성한다는 것을 보여준다 (ShapeNet Cars 데이터셋).
4. Global Condition: FlexDiffuse
원래 Stable Diffusion에서 글로벌 조건은 텍스트 임베딩에서만 발생한다. Stable Diffusion은 CLIP을 텍스트 인코더로 사용하고 모델 latent와 토큰별 CLIP 텍스트 임베딩 간의 cross-attention을 수행한다. 결과적으로 CLIP 이미지와 텍스트 공간 사이의 정렬을 활용하여 글로벌 이미지 컨디셔닝에 대한 prior를 재사용할 수 있다.
본 논문은 fine-tuning 범위를 최소화하면서 글로벌 이미지 컨디셔닝을 모델에 통합하기 위해 FlexDiffuse에 도입된 linear guidance 메커니즘의 학습 가능한 변형을 제안하였다. $L \times D$ 모양의 원래 프롬프트 임베딩 $T$에서 시작한다. 여기서 $L$은 토큰의 길이이고 $D$는 토큰 임베딩의 차원이다. 그런 다음 원래 프롬프트 임베딩에 $D$ 모양의 CLIP 글로벌 이미지 임베딩 $I$와 학습 가능한 글로벌 가중치 세트 \(\{w_i\}_{i=1,\ldots,L}\)를 곱한 값을 더한다.
\[\begin{equation} T_i^\prime = T_i + w_i \cdot I, \quad i = 1, 2, \ldots, L \end{equation}\]FlexDiffuse의 linear guidance를 사용하여 가중치를 다음과 같이 초기화한다.
\[\begin{equation} w_i = \frac{i}{L} \end{equation}\]실제 출시된 Zero123++ 모델에서는 텍스트 조건이 없으므로 빈 프롬프트를 인코딩하여 $T$를 얻는다.

위 그림은 글로벌 조건이 있거나 없는 학습된 Zero123++ 모델의 결과이다. 제안된 글로벌 조건이 없는 경우 생성된 콘텐츠의 품질은 입력 이미지에 해당하는 보이는 영역에 대해 만족스러운 수준으로 유지된다. 그러나 모델이 객체의 글로벌한 semantic을 추론하는 능력이 부족하기 때문에 보이지 않는 영역의 경우 생성 품질이 크게 저하된다.
Experiments
- 데이터: 랜덤한 HDRI 환경 조명으로 렌더링된 Objaverse 데이터
- 학습 디테일
- Stable Diffusion Image Variations 모델의 단계별 학습 일정을 채택하여 fine-tuning 범위를 더욱 줄이고 Stable Diffusion에서 최대한 많은 prior를 보존
- 첫 번째 단계
- Self-attention 레이어와 Stable Diffusion의 cross-attention 레이어의 KV 행렬만 fine-tuning
- optimizer: AdamW
- learning rate: $7 \times 10^{-5}$ (cosine annealing schedule, 1000 warm-up steps)
- warp-up: 1000 step
- 두 번째 단계
- 전체 UNet을 fine-tuning
- learning rate: $5 \times 10^{-6}$ (2000 warm-up steps)
- 학습 과정을 보다 효율적으로 만들기 위해 Min-SNR 가중치 전략을 사용
1. Comparison to the State of the Art
Image to Multi-view
다음은 다른 방법들과 image to multi-view에 대한 정성적 결과를 비교한 것이다.

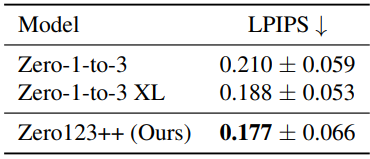
다음은 validation split에서의 정량적 결과이다.
Text to Multi-view
다음은

2. Depth ControlNet for Zero123++
저자들은 기본 Zero123++ 모델 외에도 ControlNet으로 구축된 Zero123++의 깊이 제어 버전도 출시하였다. 타겟 RGB 이미지에 해당하는 정규화된 선형 깊이 이미지를 렌더링하고 깊이를 통해 형상에 대한 Zero123++를 제어하도록 ControlNet을 학습시켰다. 학습된 모델은 validation split에서 0.086의 우수한 LPIPS를 달성하였다.
다음은 깊이 제어 Zero123++에서 생성된 두 가지 예시이다.
