[논문리뷰] Large Language Models are Zero-Shot Reasoners
NeurIPS 2022. [Paper] [Github]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa
The University of Tokyo | Google Research
24 May 2022

Introduction
언어 모델의 크기를 확장하는 것은 최근 NLP 혁명의 핵심 요소였다. LLM의 성공은 in-context few-shot 또는 zero-shot 학습에 기인한다. 몇 가지 예(few-shot) 또는 task를 설명하는 명령(zero-shot)에 모델을 간단히 컨디셔닝하여 다양한 task를 해결할 수 있다. 언어 모델을 컨디셔닝하는 방법을 “prompting”이라고 하며, 수동 또는 자동으로 프롬프트를 설계하는 것이 NLP에서 화제가 되었다.
1,000억 개 이상의 파라미터 규모의 LLM조차도 느리고 여러 단계의 추론을 필요로 하는 task에서는 어려움을 겪었다. 이러한 단점을 해결하기 위해 질문-답변 예제가 아닌 단계별 추론 예제를 LLM에 제공하는 chain of thought (CoT) prompting이 제안되었다. CoT는 모델이 복잡한 추론을 여러 개의 쉬운 단계로 분해하는 추론 경로를 생성하는 데 도움이 된다. 특히 CoT를 사용하면 추론 성능이 언어 모델의 크기에 따라 급격히 증가한다.
CoT prompting의 성공과 다른 많은 task별 prompting 방법들의 성공은 LLM의 few-shot 학습 능력에 기인한다. 반면, 본 논문의 Zero-shot-CoT는 각 질문에 답하기 전에 단계별로 생각하도록 돕는 간단한 프롬프트인 “Let’s think step by step”을 추가한 zero-shot 방법이다. 단순함에도 불구하고, Zero-shot-CoT는 zero-shot 방식으로 그럴듯한 추론 경로를 생성하고 기존 zero-shot 방식이 실패하는 문제에서 정답에 도달한다.
중요한 점은, Zero-shot-CoT는 대부분의 기존 prompt engineering이 예시(few-shot)나 템플릿(zero-shot) 형태로 이루어졌던 것과 달리 다재다능하고 task에 구애받지 않는다는 점이다. 즉, task별로 프롬프트를 수정하지 않고도 산술적 추론, 기호적 추론, 상식적 추론, 기타 논리적 추론 등 다양한 추론 task에 걸쳐 단계별 답변이 가능하다.
Zero-shot-CoT는 신중하게 만들어진 task별 단계별 예제를 사용한 CoT보다 성능이 낮지만, zero-shot baseline보다 엄청나게 점수가 향상하였다. 중요한 점은 단일 고정 프롬프트를 사용하면 zero-shot LLM이 CoT보다 훨씬 더 나은 스케일링 곡선을 갖는다는 것이다.
또한 기존 CoT는 프롬프트 예시 질문과 task 질문의 유형이 서로 일치하지 않으면 성능이 저하되어 task별 프롬프트 설계에 대한 민감도가 높다. 이와 대조적으로 Zero-shot-CoT의 다양한 추론 task에 걸친 다재다능함은 충분히 연구되지 않은 LLM의 zero-shot 기본 역량, 예를 들어 일반적인 논리적 추론과 같은 고차원의 광범위한 인지 역량을 암시한다.
Zero-shot Chain of Thought
본 논문은 CoT 추론을 위한 zero-shot 템플릿 기반 prompting인 Zero-shot-CoT를 제안하였다. Zero-shot-CoT는 단계별 few-shot 예제를 요구하지 않기 때문에 원래의 CoT prompting과 다르다. 또한, 본질적으로 task에 독립적이고 하나의 템플릿으로 광범위한 task에 걸쳐 multi-hop 추론을 이끌어내기 때문에 대부분의 이전 템플릿 prompting과 다르다. 핵심 아이디어는 단계별 추론을 추출하기 위해 “Let’s think step by step” 또는 유사한 텍스트를 추가하는 것이다.
multi-hop 추론: 답에 도달하기 위해 다양한 맥락 간의 논리적 연결을 만드는 능력
1. Two-stage prompting
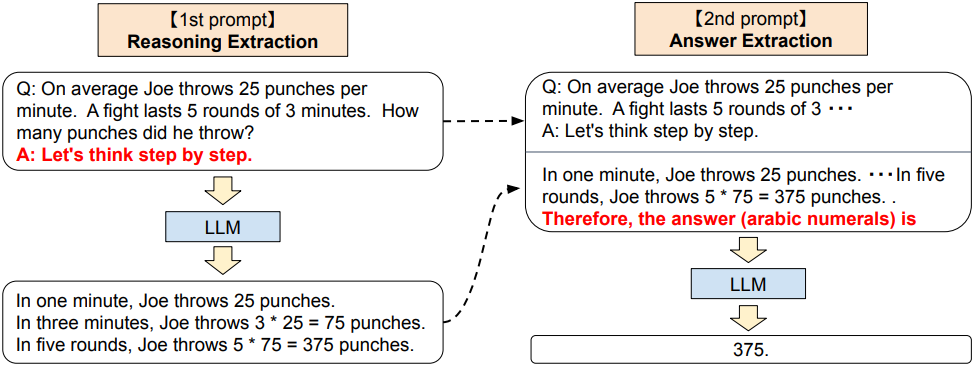
Zero-shot-CoT는 개념적으로 간단하지만, 추론과 답변을 추출하기 위해 두 번 prompting을 사용한다. 반면, zero-shot baseline은 이미 “The answer is” 형태의 prompting을 사용하여 올바른 형식으로 답변을 추출한다. CoT는 few-shot 예시 답변을 이러한 형식으로 끝내도록 명시적으로 설계하여 이러한 답변 추출 prompting이 필요하지 않다. 요약하자면, CoT는 task별로 특정 답변 형식을 사용하여 몇 가지 prompting 예시를 신중하게 설계해야 하는 반면, Zero-shot-CoT는 prompting engineering이 덜 필요하지만 LLM을 두 번 prompting해야 한다.
1번째 프롬프트: 추론 추출
이 단계에서는 먼저 간단한 템플릿 “Q: $x$. A: $t$”를 사용하여 입력 질문 $x$를 프롬프트 $x^\prime$으로 수정한다. 여기서 $t$는 질문 $x$에 답하기 위해 생각의 사슬을 추출하는 트리거 문장이다. 예를 들어 “Let’s think step by step”를 트리거 문장으로 사용하면 프롬프트 $x^\prime$은 “Q: $x$. A: Let’s think step by step.”가 된다. 프롬프트 텍스트 $x^\prime$은 LLM에 입력되고 후속 문장 $z$가 생성된다. 어떤 디코딩 전략이든 사용할 수 있지만 단순성을 위해 greedy decoding을 사용했다.
2번째 프롬프트: 답변 추출
두 번째 단계에서는 생성된 문장 $z$와 prompting된 문장 $x^\prime$을 사용하여 언어 모델에서 최종 답을 추출한다. 구체적으로, “$x^\prime$ $z$ $a$”와 같이 세 요소를 간단히 concat한다. 여기서 $a$는 최종 답변을 얻기 위한 트리거 문장이다. 이 단계의 프롬프트는 동일한 LLM에서 생성된 문장 $z$가 프롬프트에 포함되어 있으므로 자체 증강된다.
답변 형식에 따라 약간 다른 답변 트리거를 사용한다. 예를 들어, 다중 선택 QA의 경우 “Therefore, among A through E, the answer is”를 사용하고 숫자 답이 필요한 수학 문제의 경우 “Therefore, the answer (arabic numerals) is”을 사용한다. 마지막으로 언어 모델에 prompting된 텍스트를 입력으로 제공하여 문장 $\hat{y}$를 생성하고 최종 답을 파싱한다.
Experiment
- Task & 데이터셋
- 산술적 추론: SingleEq, AddSub, MultiArith, AQUARAT, GSM8K, SVAMP
- 상식적 추론: CommonsenseQA, StrategyQA
- 기호적 추론: CoT와 동일
- Last Letter Concatenation: 단어들의 끝 문자만 모아서 출력하는 task
- Coin Flip: 동전의 초기 상태와 몇 번 뒤집어졌는지 정보를 준 뒤, 마지막 동전의 상태를 맞추는 task
- 논리적 추론: BIG-bench의 두 평가 세트 사용
- Date Understanding: 컨텍스트에서 날짜를 추론
- Tracking Shuffled Objects: 초기 상태와 일련의 물체를 섞은 과정이 주어지면 물체의 최종 상태를 추론
1. Results
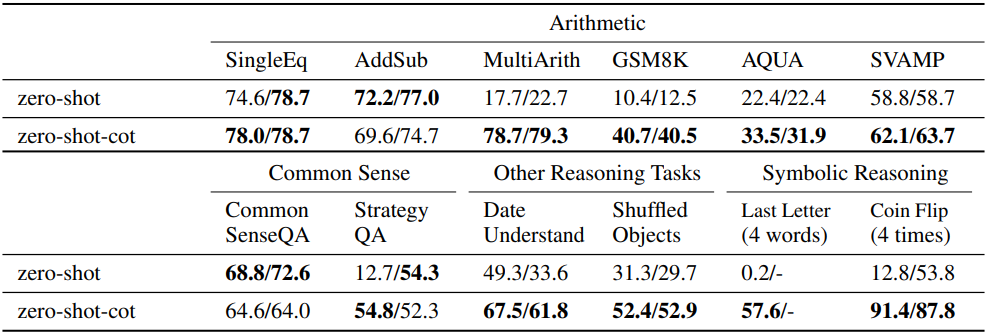
다음은 Zero-shot-CoT와 zero-shot prompting을 비교한 결과이다.
다음은 다른 baseline들과 비교한 결과이다.

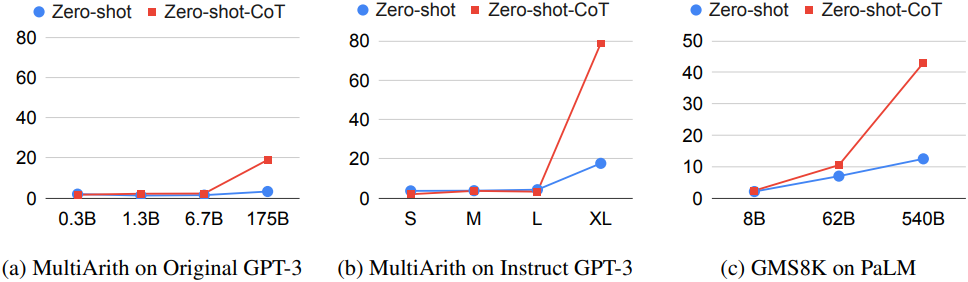
다음은 모델 크기에 따른 성능을 비교한 결과이다.
다음은 CommonsenseQA에서 Zero-Shot-CoT가 오답을 생성한 예시들이다.

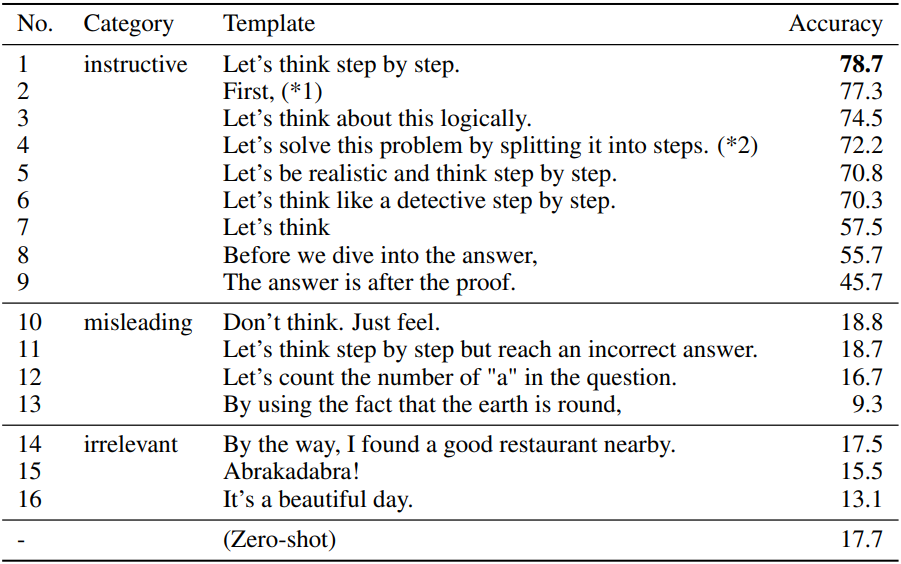
다음은 템플릿에 따른 Zero-shot-CoT의 성능을 비교한 결과이다.
다음은 few-shot 예제에 따른 성능을 비교한 결과이다. †는 CommonsenseQA를 위한 few-shot 예제를 사용한 경우이다.
