[논문리뷰] YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
arXiv 2021. [Paper] [Page] [Github]
Edresson Casanova, Julian Weber, Christopher Shulby, Arnaldo Candido Junior, Eren Gölge, Moacir Antonelli Ponti
Universidade de Sao Paulo | Sopra Banking Software | Defined.ai | Federal University of Technology | Coqui
4 Dec 2021
Introduction
TTS 시스템은 최근 몇 년 동안 딥러닝 접근 방식으로 크게 발전하여 음성 기반 가상 비서와 같은 성공적인 애플리케이션을 가능하게 한다. 대부분의 TTS 시스템은 단일 speaker의 음성에 맞게 조정되었지만 현재 몇 초의 음성만 사용하여 새로운 speaker의 음성을 합성하는 데 관심이 있다 (학습 중에는 볼 수 없음). 이 접근 방식을 zero-shot multi-speaker TTS (ZS-TTS)라고 한다.
딥러닝을 이용한 ZS-TTS는 DeepVoice 3 방식을 확장하여 처음 제안되었다. 한편, Tacotron 2는 generalized end-to-end loss (GE2E)를 사용하여 학습된 speaker 인코더에서 추출한 외부 speaker 임베딩을 사용하여 적응되어 타겟 speaker와 유사한 음성 생성이 가능하다. 유사하게, Tacotron 2는 보이지 않는 speaker의 음성의 유사성과 자연스러움을 개선하기 위해 LDE 임베딩과 함께 다른 speaker 임베딩 방법과 함께 사용되었다. 또한 성별 의존 모델이 처음 보는 speaker의 유사성을 향상시킨다는 것을 보여주었다. 이러한 맥락에서 Attentron은 다양한 레퍼런스 샘플에서 세부 스타일을 추출하기 위한 attention 메커니즘을 갖춘 fine-grained 인코더와 coarse-grained 인코더를 제안했다. 여러 레퍼런스 샘플을 사용한 결과 처음 보는 speaker에 대해 더 나은 음성 유사성을 달성했다.
ZSM-SS는 Wav2vec 2.0 기반의 정규화 아키텍처와 외부 speaker 인코더가 포함된 transformer 기반 아키텍처이며, speaker 임베딩, 피치, 에너지를 사용하여 정규화 아키텍처를 컨디셔닝했다. SC-GlowTTS는 ZS-TTS에서 flow 기반 모델을 처음으로 적용하였다. 비교 가능한 품질을 유지하면서 이전 연구와 관련하여 학습에서 보지 못한 speaker의 음성 유사성을 개선했다.
이러한 발전에도 불구하고 학습 중 관찰된 speaker와 관찰되지 않은 speaker 사이의 유사성 차이는 여전히 연구 대상이다. ZS-TTS 모델은 여전히 학습을 위해 상당한 양의 speaker가 필요하므로 리소스가 적은 언어에서 고품질 모델을 얻기가 어렵다. 또한, 현재 ZS-TTS 모델의 품질은 특히 학습에서 본 것과 다른 음성 특성을 가진 타겟 speaker의 경우 충분히 좋지 않다. SC-GlowTTS는 VCTK 데이터셋에서 단 11명의 speaker로 유망한 결과를 달성했지만 학습 speaker의 수와 다양성을 제한하면 처음 보는 음성에 대한 모델 일반화를 더욱 방해한다.
ZS-TTS와 병행하여 다국어 TTS도 동시에 여러 언어에 대한 학습 모델을 목표로 발전했다. 이러한 모델 중 일부는 코드 전환, 즉 동일한 음성을 유지하면서 문장의 일부에 대한 타겟 언어를 변경할 수 있기 때문에 특히 흥미롭다. 이것은 ZS-TTS에서 유용할 수 있다. 한 언어의 speaker를 사용하여 다른 언어로 합성할 수 있기 때문이다.
본 논문에서는 zero-shot multi-speaker 및 다국어 학습에 초점을 맞춘 몇 가지 참신한 아이디어로 YourTTS를 제안한다. VCTK 데이터셋에 대한 zero-shot 음성 변환에서 SOTA에 필적하는 결과뿐만 아니라 SOTA zero-shot multi-speaker TTS 결과를 달성하였다.
YourTTS Model
YourTTS는 VITS를 기반으로 하지만 zero-shot multi-speaker와 다국어 학습을 위해 몇 가지 새로운 수정 사항이 포함되어 있다. 첫째, 이전 연구들과 달리 음소 대신 텍스트를 입력으로 사용했다. 이를 통해 좋은 오픈 grapheme-to-phoneme 컨버터가 없는 언어에 대해 보다 현실적인 결과를 얻을 수 있다.
VITS와 마찬가지로 transformer 기반의 텍스트 인코더를 사용한다. 그러나 다국어 학습의 경우 4차원 학습 가능한 언어 임베딩을 각 입력 문자의 임베딩에 concat한다. 또한 transformer 블록의 수를 10개로, hidden 채널의 수를 196개로 늘렸다. 디코더로서 4개의 affine coupling layer의 스택을 사용한다. 각 레이어 자체는 VITS 모델에서와 같이 4개의 WaveNet residual block 스택이다.
보코더의 경우 VITS에 의해 도입된 discriminator 수정과 함께 HiFi-GAN 버전 1을 사용한다. 또한 효율적인 end-to-end 학습을 위해 VAE를 사용하여 TTS 모델을 보코더와 연결한다. 이를 위해 Posterior Encoder를 사용한다. Posterior encoder는 16개의 non-causal WaveNet residual block으로 구성된다. Posterior encoder는 선형 spectrogram을 입력으로 받아 latent 변수를 예측한다. 이 latent 변수는 보코더와 flow 기반 디코더의 입력으로 사용되므로 중간 표현 (예: mel-spectrogram)이 필요하지 않다. 이를 통해 모델은 중간 표현을 학습할 수 있다. 따라서 보코더와 TTS 모델이 별도로 학습되는 2단계 접근 시스템으로 우수한 결과를 얻는다. 또한 모델이 입력 텍스트에서 다양한 리듬으로 음성을 합성할 수 있도록 하기 위해 제안된 확률적 duration predictor를 사용한다.
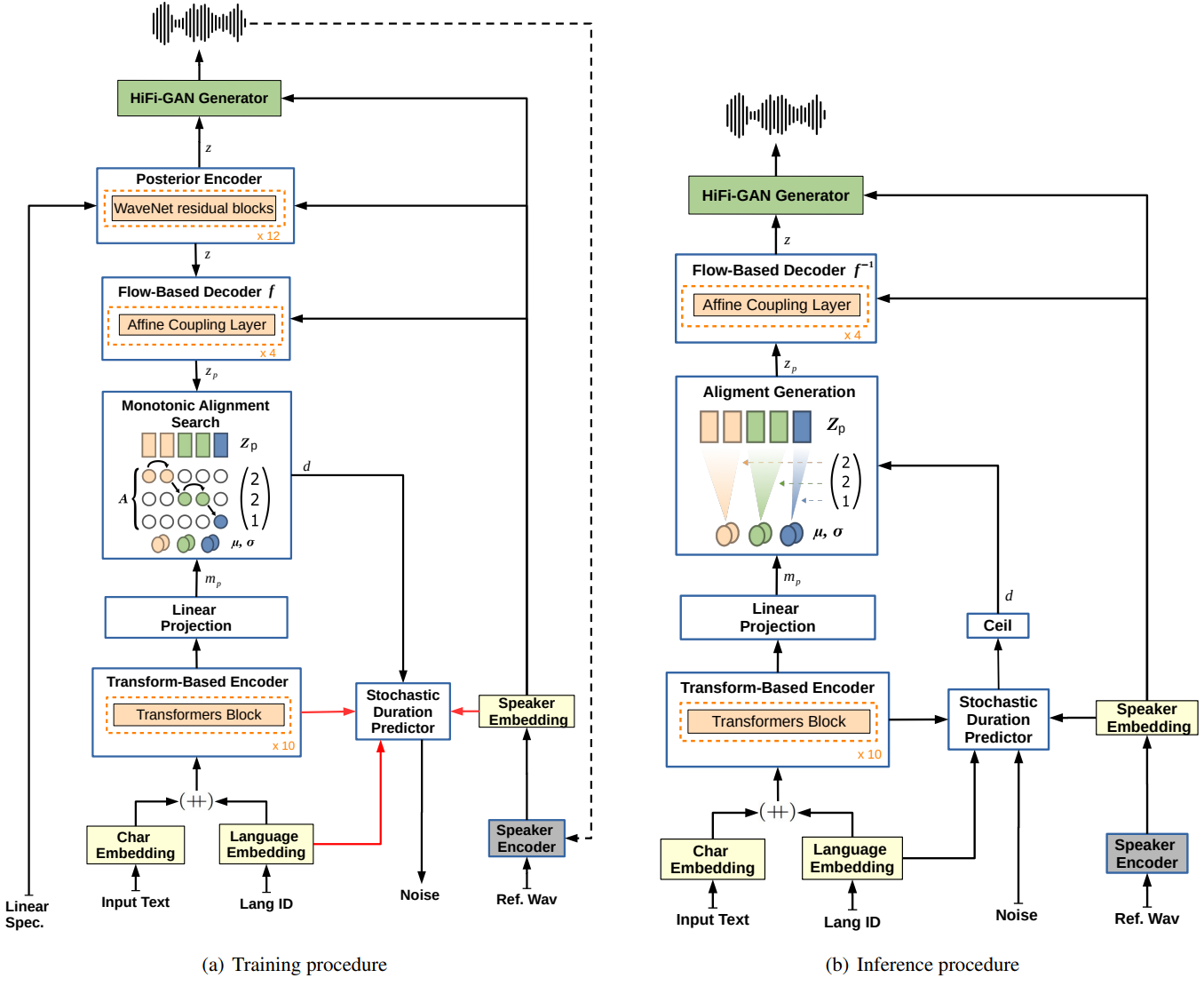
학습과 inference 중의 TTS는 위 그림에 나와 있다. 여기서 $(\unicode{xA520})$는 concatenation을 나타내고, 빨간색 연결은 이 연결에 의해 전파되는 기울기가 없음을 의미하며, 점선 연결은 선택 사항이다. 단순화를 위해 Hifi-GAN discriminator 네트워크를 생략하였다.
모델에 zero-shot multi-speaker 생성 능력을 제공하기 위해 flow 기반 디코더, posterior encoder, 외부 speaker 임베딩의 보코더의 모든 affine coupling layer를 컨디셔닝한다. Coupling layer의 residual block과 posterior encoder에서 글로벌 컨디셔닝을 사용한다. 또한 외부 speaker 임베딩을 텍스트 인코더 출력과 디코더 출력과 합산한 후 duration predictor와 보코더에 각각 전달한다. Linear projection layer를 사용하여 element-wise summation 전에 차원을 일치시킨다.
또한 저자들은 최종 loss에서 Speaker Consistency Loss (SCL)을 조사했다. 이 경우 사전 학습된 speaker 인코더를 사용하여 코사인 유사도를 최대화하는 생성된 오디오와 ground-truth에서 speaker 임베딩을 추출한다. $\phi(\cdot)$를 speaker의 임베딩을 출력하는 함수, $\textrm{cos_sim}$을 코사인 유사도 함수, $\alpha$를 최종 loss에서 SCL의 영향을 제어하는 양의 실수, $n$을 배치 크기라고 하면 SCL은 다음과 같이 정의된다.
\[\begin{equation} L_\textrm{SCL} = - \frac{\alpha}{n} \cdot \sum_i^n \textrm{cos_sim} (\phi (g_i), \phi (h_i)) \end{equation}\]여기서 $g$와 $h$는 각각 ground-truth와 생성된 speaker 오디오를 나타낸다.
학습 중에 posterior encoder는 선형 spectrogram과 speaker 임베딩을 입력으로 받고 latent 변수 $z$를 예측한다. 이 latent 변수와 speaker 임베딩은 파형을 생성하는 GAN 기반 보코더 generator에 대한 입력으로 사용된다. 효율적인 end-to-end 보코더 학습을 위해 $z$에서와 같이 일정한 길이의 부분 시퀀스를 무작위로 샘플링한다. Flow 기반 디코더는 $P_{Z_p}$ 사전 분포와 관련하여 latent 변수 $z$와 speaker 임베딩을 컨디셔닝하는 것을 목표로 한다. $P_{Z_p}$ 분포를 텍스트 인코더의 출력과 정렬하기 위해 Monotonic Alignment Search (MAS)을 사용한다. 확률적 duration predictor는 speaker 임베딩, 언어 임베딩, MAS를 통해 얻은 duration을 입력으로 받는다. 사람과 같은 말의 리듬을 생성하기 위해 확률론적 duration predictor의 목적은 음소 duration의 log-likelihood의 변동 하한이다.
inference 중에는 MAS가 사용되지 않는다. 대신 텍스트 인코더에서 $P_{Z_p}$ 분포를 예측하고 확률적 duration predictor의 역변환을 통해 랜덤 noise에서 duration을 샘플링한 다음 정수로 변환한다. 이러한 방식으로 latent 변수 $z_p$는 분포 $P_{Z_p}$에서 샘플링된다. Inverted Flow 기반 디코더는 latent 변수 $z_p$와 speaker 임베딩을 입력으로 받아 latent 변수 $z_p$를 보코더 generator에 입력으로 전달되는 latent 변수 $z$로 변환하여 합성된 파형을 얻는다.
Experiments
- 데이터셋: VCTK (영어), TTS-Portuguese Corpus (포르투갈어), M-AILABS french (프랑스어)
- 구현 디테일
- Speaker 인코더: VoxCeleb 2에서 학습된 H/ASP model 사용
- $\alpha$ = 9
- batch size = 64
- optimizer: AdamW ($\beta_1$ = 0.8, $\beta_2$ = 0.99, weight decay = 0.01)
- learning rate: 0.0002, 지수적으로 감소 ($\gamma = 0.999875$)
- 다중 언어 실험의 경우 weighted random sampling을 사용하여 언어 균형 batch를 보장
- 실험 세팅
- 실험 1: VCTK 데이터셋만 사용
- 실험 2: VCTK, TTS-Portuguese 데이터셋 사용
- 실험 3: VCTK, TTS-Portuguese, MAILABS french 데이터셋 사용
- 실험 4: 실험 3에서 얻은 모델부터 시작하여 LibriTTS에서 1151명의 추가 영어 사용자로 학습을 계속함
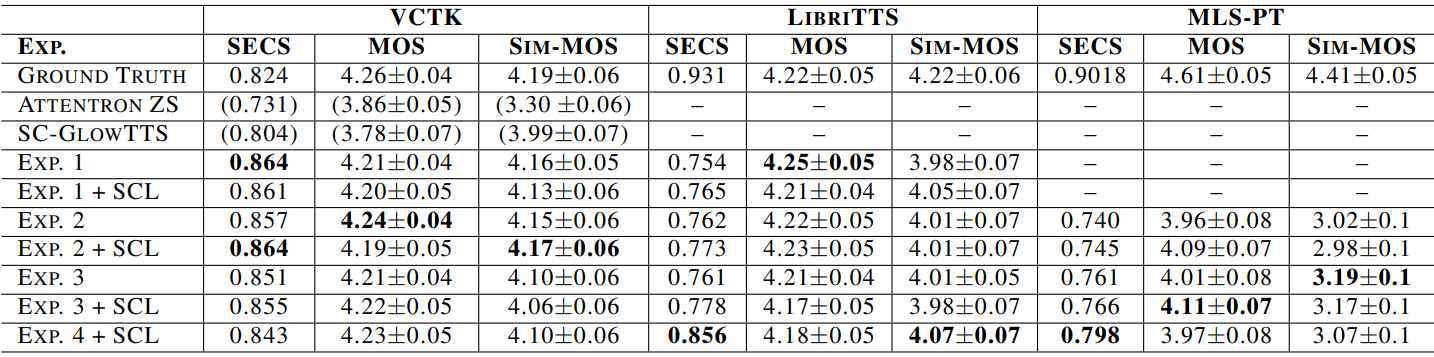
1. Results
다음은 모든 실험에 대한 SECS, MOS, Sim-MOS를 비교한 표이다. (신뢰 구간 95%)
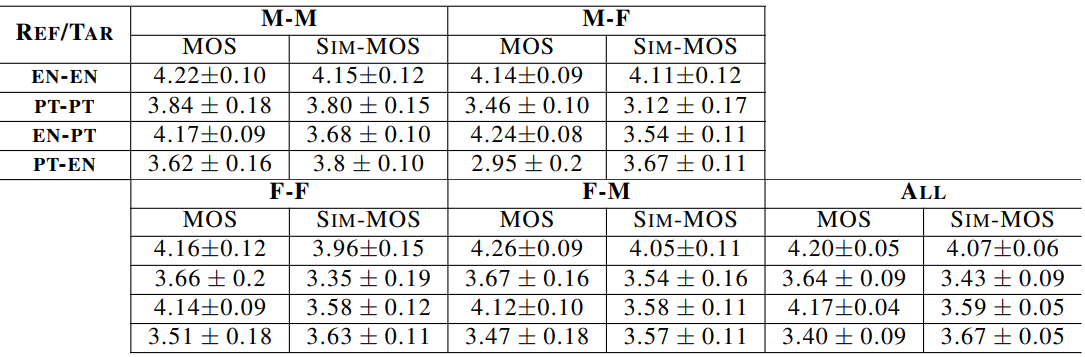
2. Zero-Shot Voice Conversion
다음은 zero-shot 음성 변환 실험에 대한 MOS와 Sim-MOS를 비교한 표이다. (신뢰 구간 95%)
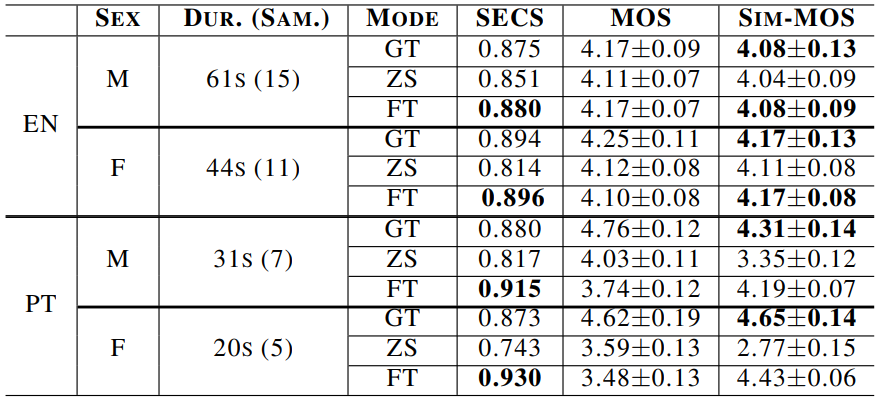
3. Speaker Adaptation
다음은 speaker 적응 실험에 대한 SECS, MOS, Sim-MOS를 비교한 표이다. (신뢰 구간 95%)