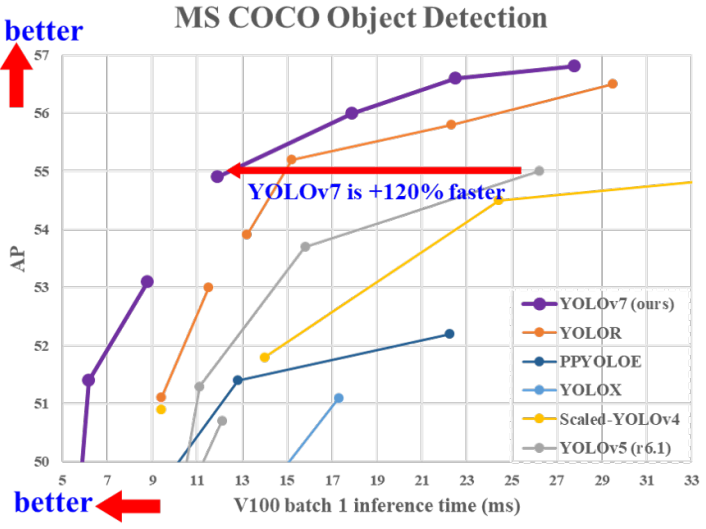
[논문리뷰] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
CVPR 2023. [Paper] [Github]
Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao
Academia Sinica
6 Jul 2022
Introduction
실시간 object detection은 종종 컴퓨터 비전 시스템에서 필요한 구성 요소이기 때문에 컴퓨터 비전에서 매우 중요한 주제이다. 예를 들어, 다중 객체 추적, 자율 주행, 로봇 공학, 의료 영상 분석 등 실시간 객체 감지를 실행하는 컴퓨팅 장치는 일반적으로 일부 모바일 CPU 또는 GPU뿐만 아니라 다양한 신경 처리 장치 (NPU)이다. 일부 edge device는 바닐라 convolution, depth-wise convolution, MLP 연산과 같은 다양한 연산의 속도를 높이는 데 중점을 둔다. 본 논문에서 제안한 실시간 object detector는 모바일 GPU와 GPU 디바이스를 edge에서 클라우드까지 모두 지원할 수 있기를 주로 희망한다.
최근 몇 년 동안 실시간 object detector는 여전히 다른 edge device를 위해 개발되었다. 예를 들어, MCUNet과 NanoDet은 저전력 단일 칩에서 생성하고 edge CPU에서 inference 속도를 향상시키는 데 중점을 두었다. YOLOX와 YOLOR와 같은 방법은 다양한 GPU의 inference 속도를 향상시키는 데 중점을 두었다. 보다 최근에는 실시간 object detector의 개발이 효율적인 아키텍처 설계에 초점을 맞추고 있다. CPU에서 사용할 수 있는 실시간 object detector의 경우 대부분 MobileNet, ShuffleNet, GhostNet을 기반으로 설계되었다. 또 다른 주류 실시간 object detector는 GPU용으로 개발되었으며 대부분 ResNet, DarkNet, DLA를 사용한 다음 CSPNet 전략을 사용하여 아키텍처를 최적화한다. 본 논문에서 제안하는 방법들의 발전 방향은 현재 주류인 실시간 object detector의 발전 방향과 다르다. 아키텍처 최적화 외에도 제안된 방법은 학습 프로세스의 최적화에 중점을 둔다. 본 논문은 object detection의 정확도를 향상시키기 위한 학습 비용을 강화할 수 있지만 inference 비용을 증가시키지 않는 최적화된 모듈 및 최적화 방법에 중점을 둔다. 제안된 모듈과 최적화 방법을 학습 가능한 bag-of-freebies라고 부른다.
최근 모델 re-parameterization과 동적 레이블 할당은 네트워크 학습과 object detection에서 중요한 주제가 되었다. 주로 위의 새로운 개념이 제안된 후 object detector의 학습은 많은 새로운 문제를 발전시켰다. 본 논문에서는 저자들이 발견한 몇 가지 새로운 문제를 제시하고 이를 해결하기 위한 효과적인 방법을 고안하였다. 모델 re-parameterization을 위해 서로 다른 네트워크의 레이어에 적용할 수 있는 모델 re-parameterization 전략을 기울기 전파 경로 개념으로 분석하고 계획된 re-parameterization 모델을 제안한다. 또한 동적 레이블 할당 기술을 사용하면 여러 출력 레이어가 있는 모델의 학습이 새로운 문제를 생성한다는 사실을 알게 되었다. 즉, 다른 분기의 출력에 대해 동적 대상을 할당하는 방법이 필요하다는 문제이다. 이 문제에 대해 coarse-to-fine lead guided label assignment라는 새로운 레이블 할당 방법을 제안한다.
Architecture
1. Extended efficient layer aggregation networks
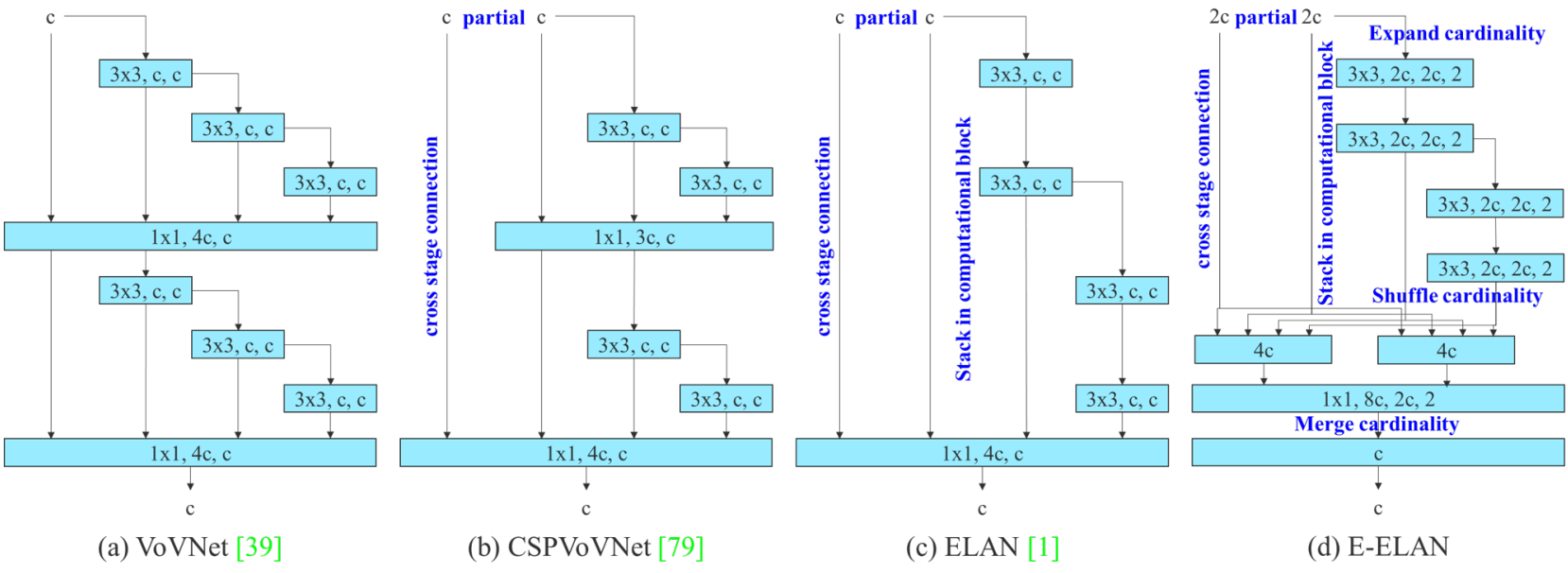
효율적인 아키텍처 설계에 관한 대부분의 논문에서 주요 고려 사항은 파라미터 수, 계산량, 계산 밀도이다. ShuffleNet V2 논문는 메모리 액세스 비용의 특성에서 시작하여 입출력 채널 비율, 아키텍처의 분기 수, 요소별 연산이 네트워크 inference 속도에 미치는 영향도 분석했다. Fast and Accurate Model Scaling 논문은 모델 스케일링을 수행할 때 activation을 추가로 고려했다. 위 그림의 (b)의 CSPVoVNet 디자인은 VoVNet의 변형이다. 앞서 언급한 기본 디자인 문제를 고려하는 것 외에도 CSPVoVNet의 아키텍처는 다양한 레이어의 가중치가 더 다양한 feature를 학습할 수 있도록 기울기 경로를 분석하였다. 위에서 설명한 기울기 분석 방식은 inference를 더 빠르고 정확하게 만든다. 위 그림의 (c)의 ELAN은 “효율적인 네트워크를 설계하는 방법”이라는 설계 전략을 고려하였다. ELAN의 결론은 가장 짧은 가장 긴 기울기 경로를 제어함으로써 더 깊은 네트워크가 효과적으로 학습하고 수렴할 수 있다는 것이다. 본 논문에서는 ELAN을 기반으로 한 Extended-ELAN (E-ELAN)을 제안하고 그 구조는 위 그림의 (d)와 같다.
대규모 ELAN은 기울기 경로 길이와 계산 블록의 스택 수에 관계없이 안정적인 상태에 도달했다. 더 많은 계산 블록이 무한정 쌓이면 이 안정 상태가 파괴될 수 있으며 파라미터 활용률이 감소한다. 제안된 E-ELAN은 확장, 셔플, 병합 카디널리티를 사용하여 원래 기울기 경로를 파괴하지 않고 네트워크의 학습 능력을 지속적으로 향상시킨다. 아키텍처 측면에서 E-ELAN은 계산 블록의 아키텍처만 변경하고 transition layer의 아키텍처는 완전히 변경되지 않는다. 본 논문의 전략은 group convolution을 사용하여 계산 블록의 채널과 카디널리티를 확장하는 것이다. 계산 레이어의 모든 계산 블록에 동일한 그룹 파라미터와 channel multiplier를 적용한다. 그런 다음 각 계산 블록에서 계산된 feature map은 설정된 그룹 파라미터 $g$에 따라 $g$개의 그룹으로 섞인 다음 함께 concat된다. 이 때 feature map의 각 그룹의 채널 수는 원래 아키텍처의 채널 수와 동일하다. 마지막으로 카디널리티를 병합하기 위해 $g$개의 feature map 그룹을 추가한다. 원래 ELAN 디자인 아키텍처를 유지하는 것 외에도 E-ELAN은 다양한 feature를 학습하기 위해 다양한 계산 블록 그룹을 가이드할 수 있다.
2. Model scaling for concatenation-based models
모델 스케일링의 주요 목적은 모델의 일부 속성을 조정하고 다양한 inference 속도의 요구 사항을 충족하기 위해 다양한 스케일의 모델을 생성하는 것이다. 예를 들어 EfficientNet의 스케일링 모델은 너비, 깊이, 해상도를 고려하였다. Scaled-YOLOv4의 경우 스케일링 모델은 단계 수를 조정하였다. Fast and Accurate Model Scaling 논문은 너비 및 깊이 스케일링을 수행할 때 vanilla convolution과 group convolution이 파라미터와 연산량에 미치는 영향을 분석하고 이를 이용하여 모델 스케일링 방법을 설계하였다.

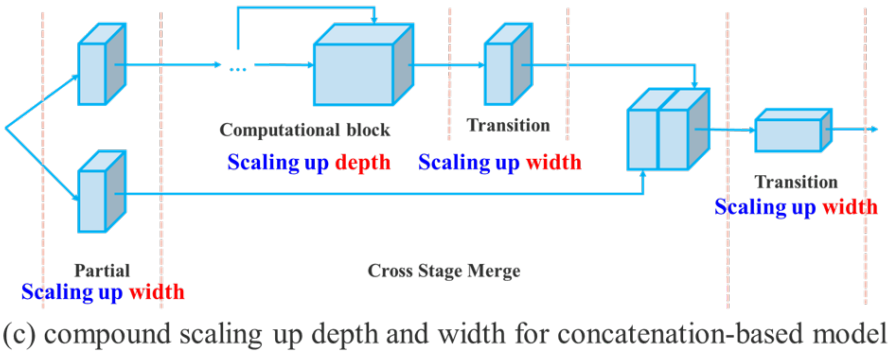
위의 방법들은 주로 PlainNet이나 ResNet과 같은 아키텍처에서 사용된다. 이러한 아키텍처가 scaling up 또는 scaling down을 실행할 때 각 레이어의 in-degree 및 out-degree는 변경되지 않으므로 각 스케일링 요소가 파라미터와 계산량에 미치는 영향을 독립적으로 분석할 수 있다. 그러나 이러한 방법을 concatenation 기반 아키텍처에 적용하면 깊이에서 scaling up 또는 scaling down을 수행할 때 concatenation 기반 계산 블록 바로 뒤에 있는 translation layer의 in-degree가 감소하거나 증가한다 (위 그림 참조).
Concatenation 기반 모델에 대해 서로 다른 스케일링 요소를 개별적으로 분석할 수 없으며 함께 고려해야 함을 위의 현상에서 유추할 수 있다. Scaling-up 깊이를 예로 들면, 이러한 행동은 transition layer의 입력 채널과 출력 채널 간의 비율 변경을 유발하여 모델의 하드웨어 사용량을 감소시킬 수 있다. 따라서 concatenation 기반 모델에 해당하는 복합 모델 스케일링 방법을 제안해야 한다. 계산 블록의 depth factor를 스케일링할 때 해당 블록의 출력 채널 변화도 계산해야 한다. 그런 다음 transition layer에서 동일한 양의 변경으로 width factor 스케일링을 수행하고 그 결과는 아래 그림과 같다. 제안된 복합 스케일링 방법은 초기 디자인 시 모델이 가지고 있던 속성을 유지하면서 최적의 구조를 유지할 수 있다.
Trainable bag-of-freebies
1. Planned re-parameterized convolution
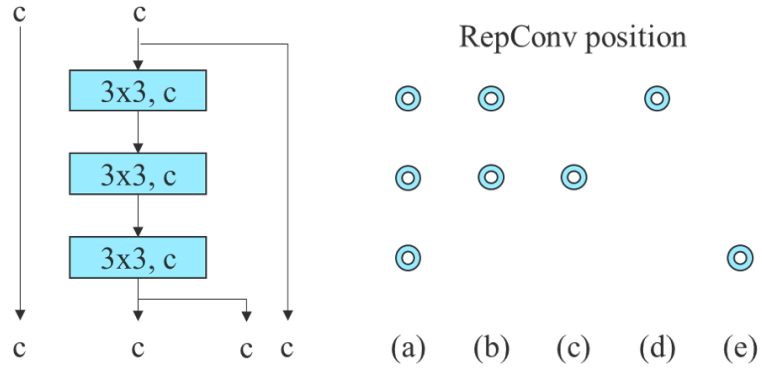
RepConv는 VGG에서 우수한 성능을 달성했지만 ResNet, DenseNet 및 기타 아키텍처에 직접 적용하면 정확도가 크게 떨어진다. Re-parameterized convolution이 다른 네트워크와 어떻게 결합되어야 하는지 분석하기 위해 기울기 전파 경로를 사용한다. 저자들은 이에 따라 planned re-parameterized convolution를 설계했다.
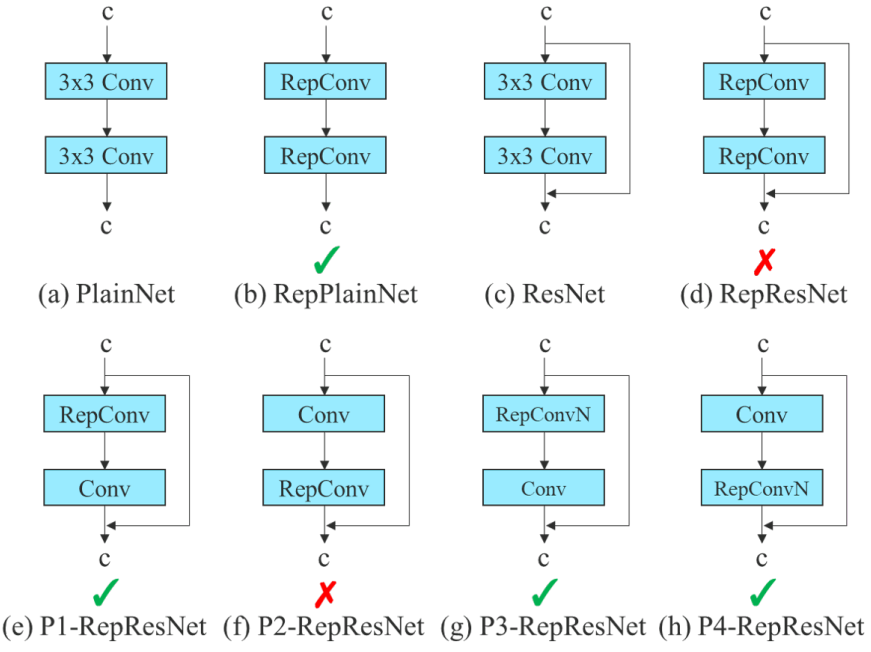
RepConv는 실제로 3$\times$3 convolution, 1$\times$1 convolution, identity 연결을 하나의 convolution layer에 결합한다. 저자들은 RepConv와 다른 아키텍처의 조합 및 해당 성능을 분석한 후, RepConv의 identity 연결이 ResNet의 residual과 DenseNet의 concatenation을 파괴하여 다양한 feature map에 더 다양한 기울기를 제공한다는 사실을 발견했다. 위와 같은 이유로 identity 연결이 없는 RepConv (RepConvN)을 사용하여 planned re-parameterized convolution의 아키텍처를 설계한다. Residual 또는 concatenation이 있는 convolutional layer가 re-parameterized convolution으로 대체되면 identity 연결이 없어야 한다. 위 그림은 PlainNet과 ResNet에서 사용하도록 설계된 “planned re-parameterized convolution”의 예를 보여준다.
2. Coarse for auxiliary and fine for lead loss

Deep supervision은 심층 네트워크를 학습하는 데 자주 사용되는 기술이다. 주요 개념은 네트워크의 중간 레이어에 여분의 auxiliary head를 추가하고 보조 loss를 가이드로 하는 얕은 네트워크 가중치를 추가하는 것이다. 일반적으로 잘 수렴되는 ResNet이나 DenseNet과 같은 아키텍처의 경우에도 deep supervision은 여전히 많은 task에서 모델의 성능을 크게 향상시킬 수 있다. 위 그림의 (a)와 (b)는 각각 deep supervision이 “없는” 또는 “있는” object detector 아키텍처를 보여준다. 본 논문에서는 최종 출력을 담당하는 head를 lead head라 하고 학습을 보조하는 head를 auxiliary head라 한다.
다음으로 레이블 할당 문제에 대해 논의한다. 과거에는 심층 네트워크 학습에서 레이블 할당은 일반적으로 ground-truth 정보를 직접 참조하고 주어진 규칙에 따라 hard label을 생성했다. 그러나 최근 몇 년 동안 object detection을 예로 들면 연구자들은 종종 네트워크에 의한 예측 출력의 품질과 분포를 사용한 다음 ground-truth과 함께 몇 가지 계산 및 최적화 방법을 사용하여 신뢰할 수 있는 soft label을 생성하는 것을 고려하였다. 예를 들어, YOLO는 bounding box regression 예측의 IoU와 ground-truth 정보를 객체성의 soft label로 사용한다. 본 논문에서는 네트워크 예측 결과를 ground truth와 함께 고려한 후 soft label을 “label assigner”로 할당하는 메커니즘을 호출한다.
Auxiliary head든 lead head든 상황에 관계없이 목표물에 대한 철저한 supervision 학습이 필요하다. 저자들은 soft label assigner 관련 기술을 개발하는 동안 우연히 새로운 파생 문제, 즉 “auxiliary head와 lead head에 soft label을 할당하는 방법”을 발견했다. 현재 가장 많이 사용되는 방법의 결과는 위 그림의 (c)와 같이 auxiliary head와 lead head를 분리한 다음 자체 예측 결과와 ground truth를 사용하여 레이블 할당을 수행하는 것이다. 본 논문에서 제안하는 방법은 lead head 예측을 통해 auxiliary head와 lead head 모두를 가이드하는 새로운 레이블 할당 방법이다. 즉, lead head 예측을 guidance로 사용하여 auxiliary head와 lead head 학습에 각각 사용되는 coarse-to-fine 계층적 레이블을 생성한다. 제안된 두 가지 deep supervision 레이블 할당 전략은 각각 위 그림의 (d)와 (e)에 나와 있다.
Lead head guided label assigner는 주로 lead head와 ground truth의 예측 결과를 기반으로 계산되며, 최적화 과정을 거쳐 soft label을 생성한다. 이 soft label 집합은 auxiliary head와 lead head 모두에 대한 타겟 학습 모델로 사용된다. 이렇게 하는 이유는 lead head가 상대적으로 학습 능력이 강하기 때문에 여기에서 생성된 soft label이 소스 데이터와 타겟 간의 분포와 상관 관계를 더 잘 나타내야 하기 때문이다. 또한 이러한 학습을 일종의 일반화된 residual learning으로 볼 수 있다. 더 얕은 auxiliary head가 lead head가 학습한 정보를 직접 학습하게 함으로써 lead head는 아직 학습되지 않은 잔여 정보 학습에 더 집중할 수 있다.
Coarse-to-fine lead head guided label assigner도 lead head의 예측 결과와 ground truth를 사용하여 soft label을 생성했다. 그러나 그 과정에서 soft label의 두 가지 다른 집합, 즉 coarse label과 fine label을 생성한다. 여기서 fine label은 lead head guided label assigner에 의해 생성된 soft label과 동일하고 coarse label은 더 많은 그리드를 허용하여 생성된다. Positive 샘플 할당 프로세스의 제약을 완화하여 positive 타겟으로 취급해야 한다. 그 이유는 auxiliary head의 학습 능력이 lead head만큼 강하지 않으며, 학습해야 할 정보를 잃지 않기 위함이다. 따라서 object detection task에서 auxiliary head의 recall을 최적화하는 데 중점을 둔다.
Lead head의 출력은 높은 recall 결과에서 높은 정확도의 결과를 최종 출력으로 필터링할 수 있다. 그러나 coarse label의 추가 가중치가 fine label의 추가 가중치에 가까우면 최종 예측에서 나쁜 prior를 생성할 수 있다. 따라서 여분의 coarse positive grid가 덜 영향을 미치도록 하기 위해 디코더에 제한을 두어 여분의 coarse positive grid가 soft label을 완벽하게 생성할 수 없도록 한다. 위에서 언급한 메커니즘은 fine label과 coarse label의 중요성을 학습 프로세스 중에 동적으로 조정하고 fine label의 최적화 가능한 상한을 coarse label보다 항상 높게 만든다.
3. Other trainable bag-of-freebies
몇 가지 학습 가능한 bag-of-freebies 목록은 다음과 같다. 이러한 freebies는 학습에서 사용된 트릭 중 일부이지만 원래 개념은 이전에 제안되었던 것이다.
- conv-bn-activation 토폴로지의 batch normalization: 이 부분은 주로 batch normalization layer를 convolution layer에 직접 연결한다. 이것의 목적은 batch normalization의 평균과 분산을 inference 단계에서 convolution layer의 바이어스와 가중치에 통합하는 것이다.
- 덧셈과 곱셈 방식으로 convolution feature map과 결합된 YOLOR의 암시적 지식: YOLOR의 암시적 지식은 inference 단계에서 미리 계산하여 벡터로 단순화할 수 있다. 이 벡터는 이전 또는 나중 convolution layer의 바이어스 및 가중치와 결합될 수 있다.
- EMA 모델: EMA는 평균 teacher에서 사용되는 기술이며, 본 논문의 시스템에서는 EMA 모델을 최종 inference 모델로만 사용한다.
Experiments
- 데이터셋: COCO 2017
- 모델
- YOLOv7: 일반 GPU용
- YOLOv7-tiny: edge GPU용
- YOLOv7-W6: 클라우드 GPU용
- YOLOv7-X: neck에 stack scaling을 하고, 복합 스케일링 방법을 사용하여 전체 모델의 깊이와 너비를 scaling-up
- YOLOv7-E6/D6: 복합 스케일링 방법울 YOLOv7-W6에 사용
- YOLOv7-E6E: E-ELAN을 YOLOv7-E6에 사용
1. Baselines
다음은 baseline object detector들과의 비교 결과이다.
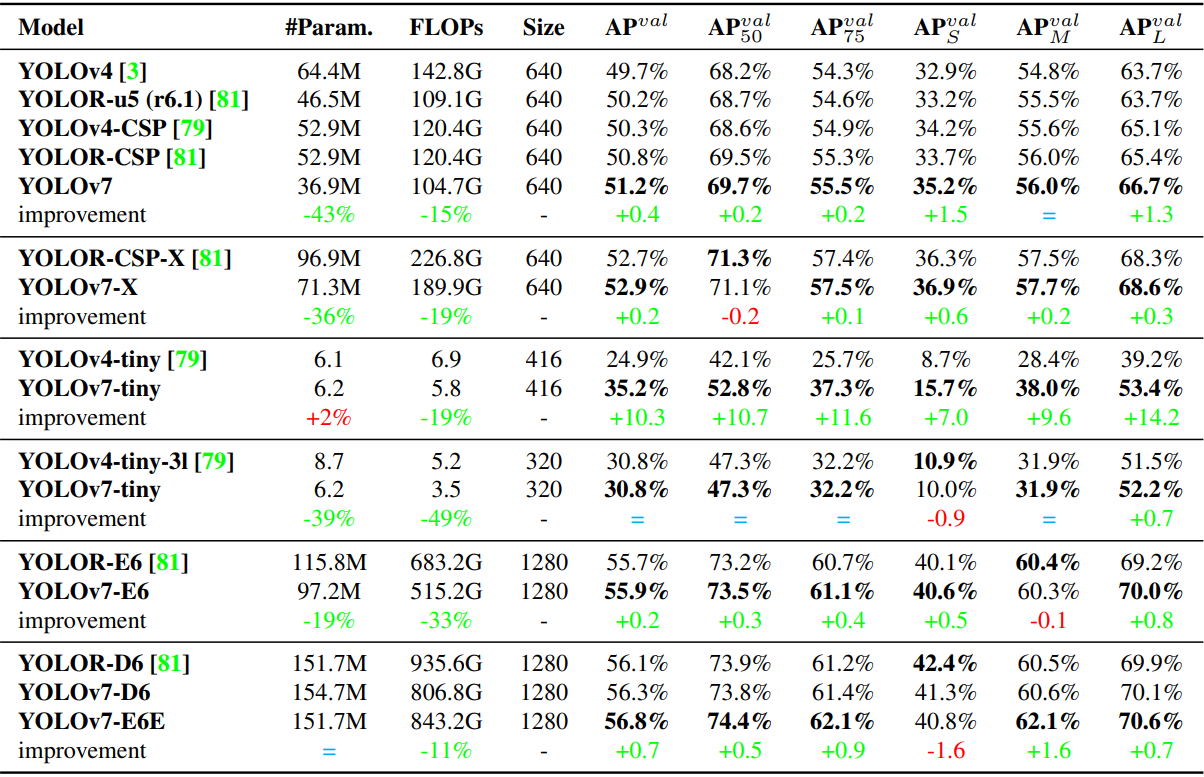
2. Comparison with state-of-the-arts
다음은 SOTA 실시간 object detector과의 비교 결과이다.

3. Ablation study
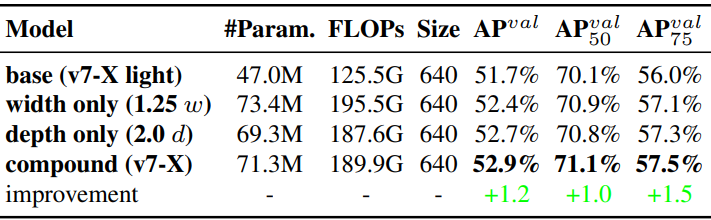
Proposed compound scaling method
다음은 복합 스케일링 방법에 대한 ablation study 결과이다.
Proposed planned re-parameterized model
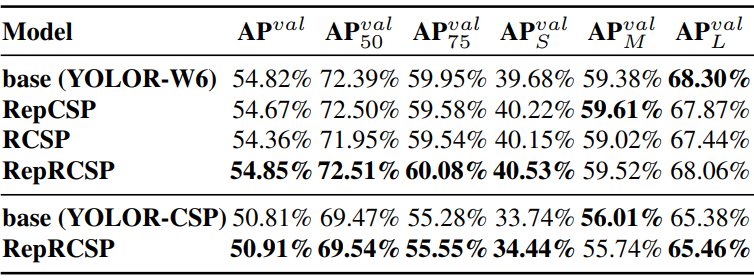
Concatenation 기반 모델의 실험에서는 3-stacked ELAN에서 서로 다른 위치에 있는 3$\times$3 convolutional layer를 RepConv로 교체하고 자세한 구성은 아래 그림과 같다. 파란색 원은 Conv를 RepConv로 교체한 위치이다.
다음은 planned RepConcatenation model에 대한 ablation study 결과이다.

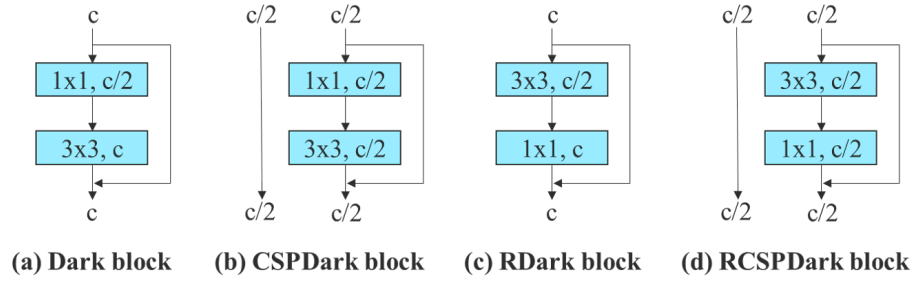
Residual 기반 모델을 다루는 실험에서 원래의 dark block에는 3$\times$3 convolution block이 없기 때문에 실험을 위해 reversed dark block을 추가로 설계한다. 그 아키텍처는 아래 그림과 같다.
다음은 planned RepResidual model에 대한 ablation study 결과이다.
Proposed assistant loss for auxiliary head
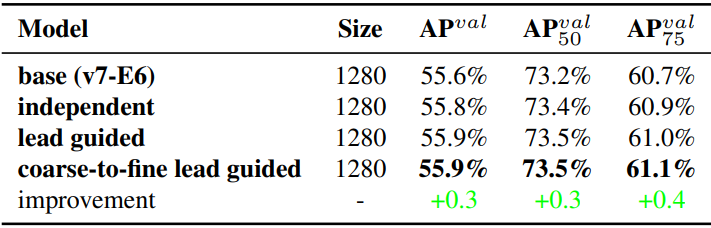
다음은 제안된 auxiliary head에 대한 ablation study 결과이다.
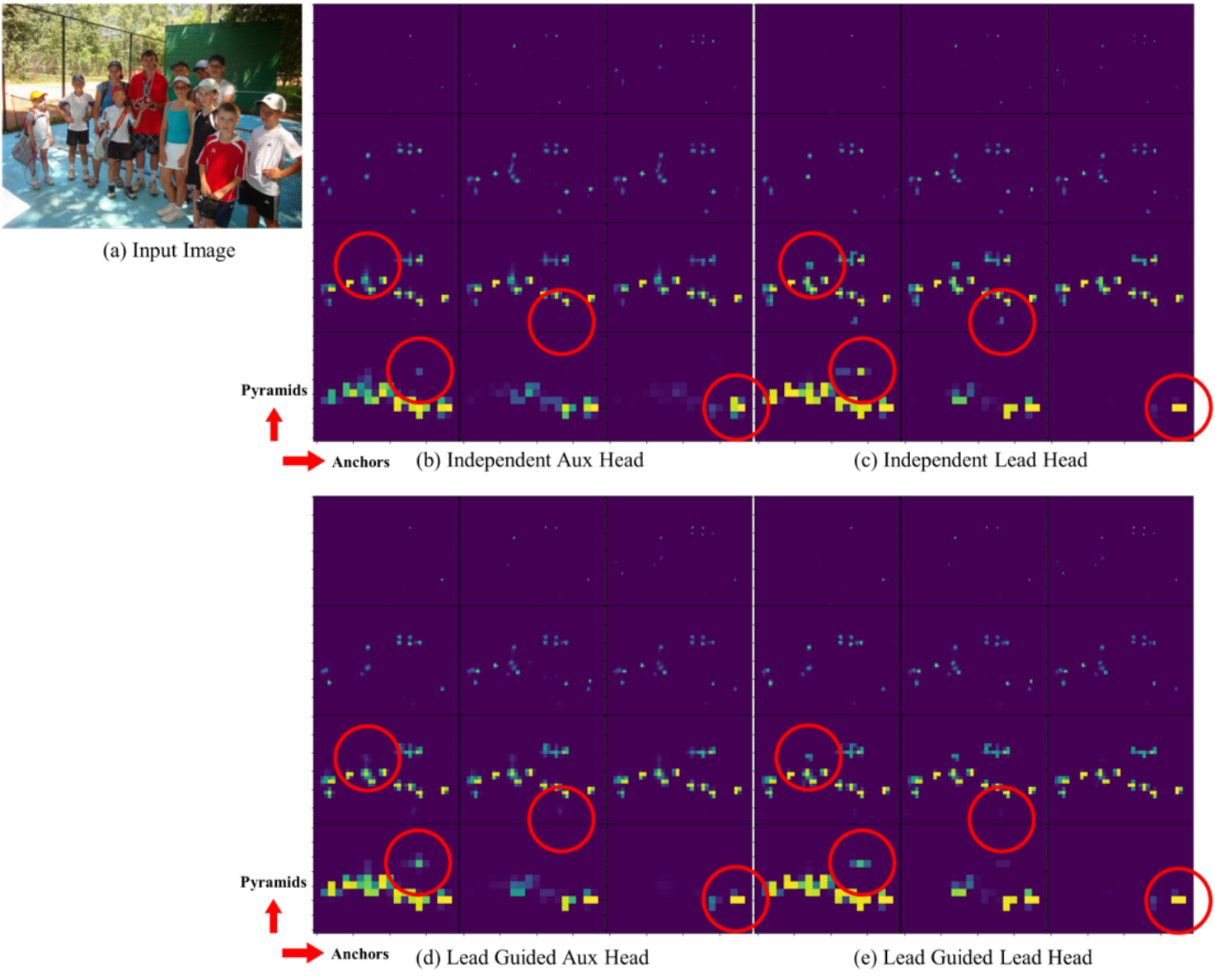
다음은 auxiliary head와 lead head에서 서로 다른 방법으로 예측한 objectness map이다.
다음 표는 auxiliary head의 디코더에 대해 coarse-to-fine lead guided label assignment의 효과를 추가로 분석한 것이다. 즉, 상한 제약을 도입한 경우와 도입하지 않은 경우의 결과를 비교하였다.
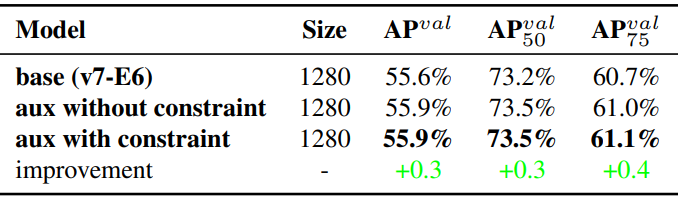
표의 수치로 미루어 볼 때 물체 중심으로부터의 거리로 물체의 상한을 제한하는 방법이 더 나은 성능을 얻을 수 있다.
YOLOv7은 object detection 결과를 공동으로 예측하기 위해 여러 pyramid를 사용하기 때문에 학습을 위해 중간 레이어의 pyramid에 auxiliary head를 직접 연결할 수 있다. 이러한 유형의 학습은 다음 단계 pyramid 예측에서 손실될 수 있는 정보를 보충할 수 있다. 위와 같은 이유로 저자들은 제안된 E-ELAN 아키텍처에서 partial auxiliary head를 설계했다. 카디널리티를 병합하기 전에 feature map 집합 중 하나 다음에 auxiliary head를 연결하는 것이며, 이 연결은 보조 loss로 인해 새로 생성된 feature map 집합의 가중치가 직접 업데이트되지 않도록 할 수 있다. 본 논문의 디자인은 lead head의 각 pyramid가 여전히 크기가 다른 물체로부터 정보를 얻을 수 있도록 한다.
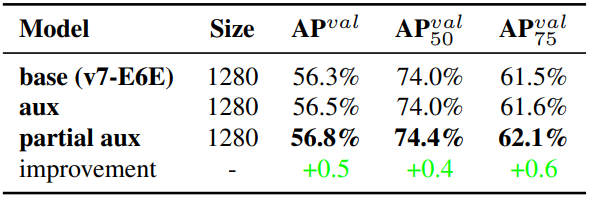
위 표는 두 가지 다른 방법, 즉 coarse-to-fine lead guided 방법과 partial coarse-to-fine lead guided 방법을 사용하여 얻은 결과를 보여준다. 분명히, partial coarse-to-fine lead guided 방법은 더 나은 보조 효과가 있다.