[논문리뷰] YOLACT++: Better Real-time Instance Segmentation
arXiv 2019. [Paper] [Github]
Daniel Bolya, Chong Zhou, Fanyi Xiao, Yong Jae Lee
University of California, Davis
3 Dec 2019
본 논문은 YOLACT 논문을 확장시킨 논문이다. (YOLACT 논문리뷰)
YOLACT의 내용이 동일하게 포함되어 있어 중복된 내용은 제외하였다.
Introduction
본 논문은 YOLACT에 비해 모델의 성능을 더욱 향상시킨 YOLACT++를 제안하였다. 특히 deformable convolution을 backbone에 통합하여 보다 유연한 feature 샘플링을 제공하고 다양한 크기, 종횡비, 회전으로 인스턴스를 처리하는 능력을 강화하였다. 또한 더 큰 객체 recall을 위해 더 나은 앵커 스케일 및 종횡비 선택으로 예측 헤드를 최적화하였다. 마지막으로, 새롭고 Fast Mask Re-Scoring 분기를 도입하여 약간의 속도 오버헤드만으로 적절한 성능 향상을 가져왔다.
YOLACT++
1. Fast Mask Re-Scoring Network
Mask Scoring R-CNN 에서 알 수 있듯이 모델의 분류 신뢰도와 예측된 마스크의 품질에 불일치가 있다. 따라서 마스크 품질과 클래스 신뢰도를 더 잘 연관시키기 위해 Mask Scoring R-CNN은 ground-truth를 사용하여 마스크 IoU로 예측된 마스크를 회귀하는 방법을 학습하는 새로운 모듈을 Mask R-CNN에 추가하였다.
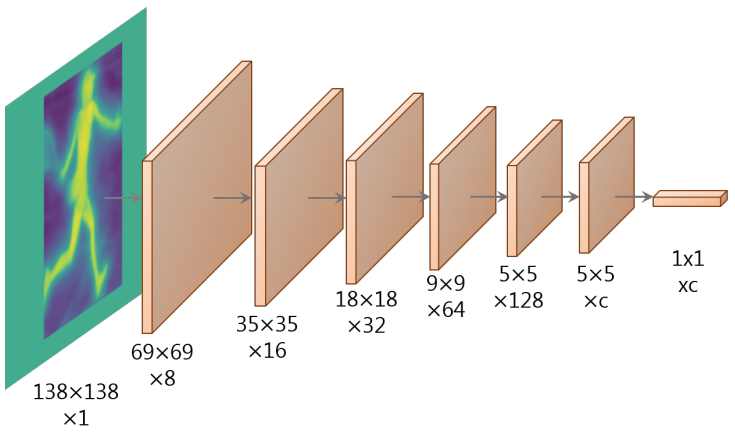
Mask Scoring R-CNN에서 영감을 받아 마스크 IoU를 기반으로 예측된 마스크의 점수를 ground-truth와 함께 재채점하는 Fast Mask Re-Scoring 분기를 도입한다. 특히 Fast Mask Re-Scoring Network는 conv 레이어당 ReLU nonlinearity와 최종 global pooling layer가 있는 6-layer FCN이다. YOLACT의 잘라낸 마스크 예측 (thresholding 전)을 입력으로 받아 각 객체 카테고리에 대한 마스크 IoU를 출력한다. 분류 헤드가 예측한 카테고리에 대한 예측 마스크 IoU와 해당 분류 신뢰도 사이의 곱을 취하여 각 마스크를 다시 채점한다.
본 논문의 방법은 다음과 같은 중요한 점에서 Mask Scoring R-CNN과 다르다.
- YOLACT++의 입력은 전체 이미지 크기 (예측된 box 영역 외부에 0이 있는)의 마스크만 있는 반면 Mask Scoring R-CNN 입력은 마스크 예측 분기의 feature와 연결된 ROI repooled mask이다.
- fc layer가 없다. 이것은 YOLACT++를 훨씬 더 빠르게 만든다.
구체적으로 Fast Mask Re-Scoring 분기가 YOLACT에 추가하는 속도 오버헤드는 1.2ms이며, 이는 ResNet-101 모델의 fps를 34.4에서 33으로 변경한다. 반면 Mask Scoring R-CNN의 모듈을 YOLACT에 통합하는 오버헤드는 28ms이며, fps가 34.4에서 17.5로 변경된다. Mask-RCNN은 단순히 ROI feature를 재사용할 수 있는 반면 YOLACT의 경우 feature을 다시 풀링해야 하므로 오버헤드가 특히 크다. 속도 차이는 주로 MS R-CNN의 ROI align 연산, fc 레이어와 입력의 feature concatenation 사용에서 비롯된다.
2. Deformable Convolution with Intervals
Deformable Convolution Network (DCN)는 기존 convnet에서 사용되는 엄격한 그리드 샘플링을 자유 형식 샘플링으로 대체하여 object detection, semantic segmentation, instance segmentation에 효과적인 것으로 입증되었다. 본 논문은 DCNv2에서 선택한 디자인을 따르고 각 ResNet 블록의 3$\times$3 convolution layer를 $C_3$에서 $C_5$로의 3$\times$3 deformable convolution layer로 교체한다. Modulated deformable module은 도입되는 inference 시간 오버헤드를 감당할 수 없기 때문에 사용하지 않는다.
Deformable convolution layer를 YOLACT의 backbone에 추가하면 속도 오버헤드가 8ms인 +1.8 mask mAP 이득이 발생한다. 저자들은 이 부스트가 다음과 같은 이유 때문이라고 생각한다.
- DCN은 타겟 인스턴스에 정렬하여 크기, 회전, 종횡비가 다른 인스턴스를 처리하는 네트워크의 능력을 강화할 수 있다.
- YOLACT는 single-shot 방식으로 re-sampling 과정이 없다.
따라서 네트워크에서 최적이 아닌 샘플링을 복구할 방법이 없기 때문에 Mask R-CNN과 같은 2-stage 방법보다 더 우수하고 유연한 샘플링 전략이 YOLACT에 더 중요하다. 반대로 Mask R-CNN의 ROI align 연산은 모든 객체를 표준 레퍼런스 영역에 정렬하여 이 문제를 어느 정도 해결할 수 있다.
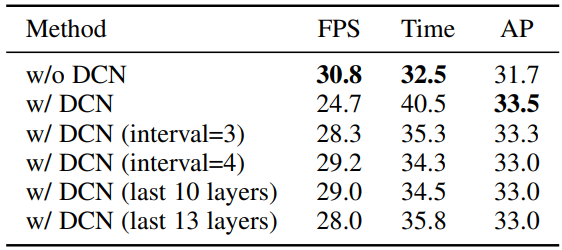
Deformable convolution layer를 직접 연결할 때 성능 향상이 꽤 괜찮은 편이지만 속도 오버헤드도 상당히 크다. ResNet-101을 사용할 때 deformable convolution이 있는 레이어가 30개 있기 때문이다. 성능 향상을 유지하면서 ResNet-101 모델의 속도를 높이기 위해 일부에만 deformable convolution을 적용하여 탐색한다.
구체적으로, 저자들은 4개의 다른 구성에서 deformable convolution을 시도하였다.
- 마지막 10개의 ResNet 블록에 적용
- 마지막 13개의 ResNet 블록에 적용
- 마지막 3개의 ResNet stage에 간격 3으로 적용 (즉, 사이에 두 개의 ResNet 블록 건너뛰기), 총 11개의 deformable layer
- 마지막 3개의 ResNet stage에 간격 4로 적용, 총 8개의 deformable layer
그 결과는 아래 표와 같다.
3. Optimized Prediction Head
마지막으로 YOLACT는 앵커 기반 backbone detector를 기반으로 하므로 스케일과 종횡비와 같은 앵커에 대한 올바른 hyperparameter를 선택하는 것이 매우 중요하다. 따라서 앵커 선택을 다시 검토하고 RetinaNet과 RetinaMask의 앵커 디자인과 비교한다. 저자들은 두 가지 변형을 시도하였다.
- 앵커 종횡비를 $[1, 1/2, 2]$에서 $[1, 1/2, 3, 1/3, 3]$로 늘리는 동안 스케일을 변경하지 않고 유지
- 종횡비를 변경하지 않고 FPN 레벨당 스케일을 세 배로 늘림 ($[1x, 2^{1/3} x, 2^{2/3} x]$)
전자와 후자는 YOLACT의 원래 구성에 비해 앵커 수를 각각 $\frac{5}{3} x$, $3x$만큼 증가시킨다.
다음은 deformable convolution layer의 선택에 따른 정확도와 속도를 나타낸 표이다.
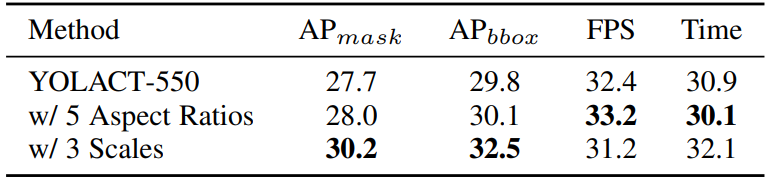
위 표에서 볼 수 있듯이 FPN 레벨당 멀티스케일 앵커를 사용하면 (구성 2) 속도와 성능 간의 균형이 가장 잘 맞는다.
Results
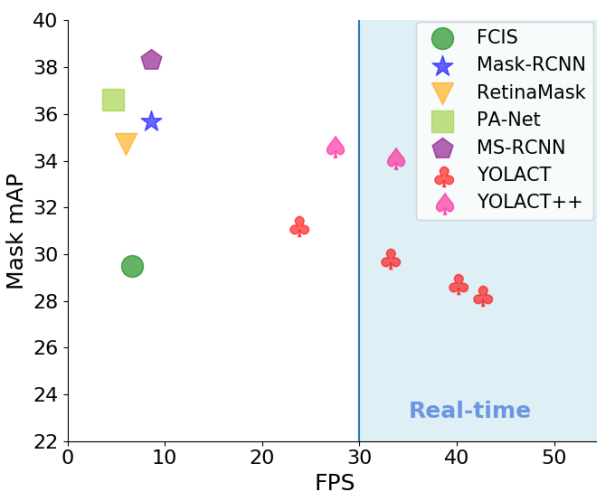
1. YOLACT++ Improvements
다음은 YOLACT++의 각 요소가 정확도와 속도에 얼마나 영향을 미치는지 나타낸 표이다.

다음은 YOLACT와 YOLACT++의 결과를 비교한 것이다.

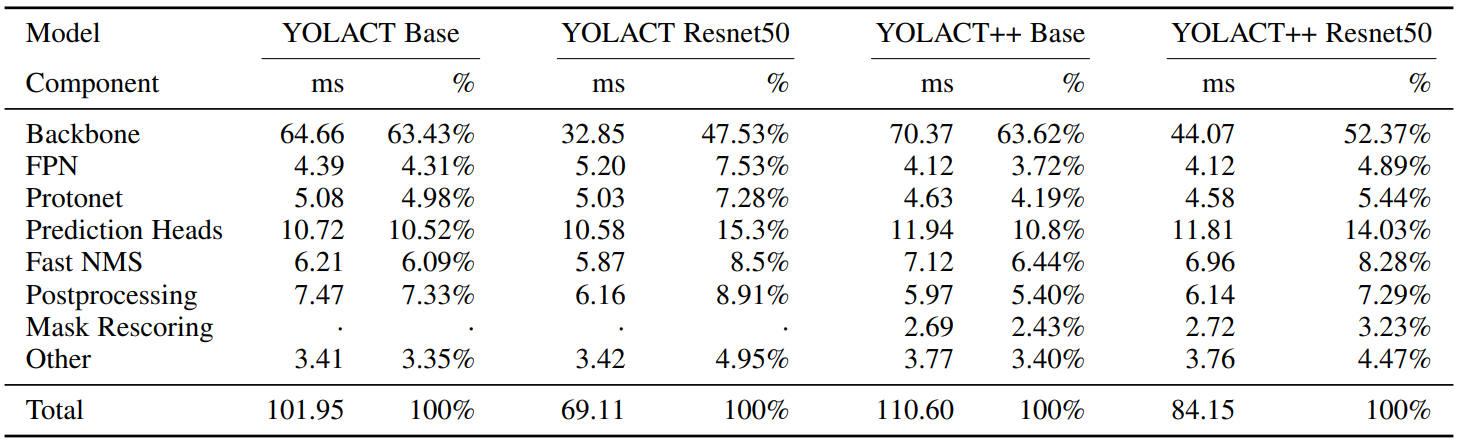
2. Timing Breakdown
다음은 YOLACT와 YOLACT++의 각 stage가 걸리는 시간을 나타낸 표이다.