[논문리뷰] YOLACT: Real-time Instance Segmentation
ICCV 2019. [Paper] [Github]
Daniel Bolya, Chong Zhou, Fanyi Xiao, Yong Jae Lee
University of California, Davis
4 Apr 2019
Introduction
지난 몇 년 동안 비전 커뮤니티는 부분적으로 잘 확립된 object detection 영역에서 강력한 유사점을 끌어냄으로써 instance segmentation에서 큰 발전을 이루었다. Mask RCNN이나 FCIS와 같은 instance segmentation에 대한 SOTA 접근 방식은 Faster R-CNN이나 R-FCN과 같은 object detection의 발전을 직접 구축한다. 그러나 이러한 방법은 주로 속도보다 성능에 중점을 두어 instance segmentation이 없는 장면을 SSD나 YOLO와 같은 실시간 object detector에 병렬로 맡긴다. 본 논문의 목표는 SSD와 YOLO가 객체 감지를 위해 그 격차를 메우는 것과 같은 방식으로 빠른 one-stage instance segmentation로 그 격차를 메우는 것이다.
그러나 instance segmentation은 object detection보다 훨씬 어렵다. SSD나 YOLO와 같은 one-stage object detector는 Faster R-CNN과 같은 기존 2-stage 감지기의 속도를 높일 수 있다. 단순히 두 번째 단계를 제거하고 다른 방식으로 손실된 성능을 보충한다. 그러나 동일한 접근 방식을 instance segmentation로 쉽게 확장할 수는 없다. SOTA 2-stage instance segmentation 방법은 마스크를 생성하기 위해 feature localization에 크게 의존한다. 즉, 이러한 방법은 일부 boundary box 영역에서 feature를 “repool”한 다음 (ex. RoIpool/align) 이제 이러한 localize된 feature를 마스크 예측 모델에 공급한다. 이 접근 방식은 본질적으로 순차적이므로 가속화하기 어렵다. FCIS와 같이 이러한 단계를 병렬로 수행하는 one-stage 방법이 존재하지만 localization 후 상당한 양의 후처리가 필요하므로 여전히 실시간과는 거리가 멀다.
이러한 문제를 해결하기 위해 명시적인 localization 단계를 생략하는 실시간 instance segmentation 프레임워크인 YOLACT (You Only Look At CoefficienTs)를 제안한다. 대신 YOLACT는 instance segmentation을 두 개의 병렬 task로 나눈다.
- 전체 이미지에 대해 로컬이 아닌 프로토타입 마스크 사전을 생성
- 인스턴스당 일련의 선형 결합 계수 예측
그러면 이 두 구성 요소에서 전체 이미지 instance segmentation을 생성하는 것은 간단하다. 각 인스턴스에 대해 해당 예측 계수를 사용하여 프로토타입을 선형 결합한 다음 예측 boundary box로 자른다. 이러한 방식으로 분할함으로써 네트워크가 자체적으로 인스턴스 마스크를 localize하는 방법을 학습한다. 여기서 시각적, 공간적, 의미론적으로 유사한 인스턴스는 프로토타입에서 다르게 나타난다.
또한 프로토타입 마스크의 수는 카테고리 수와 무관하기 때문에 YOLACT는 각 인스턴스가 카테고리 간에 공유되는 프로토타입의 조합으로 분할되는 분산된 표현을 학습한다. 이 분산된 표현은 프로토타입 space에서 흥미로운 창발적 행동으로 이어진다. 일부 프로토타입은 이미지를 공간적으로 분할하고, 일부는 인스턴스를 localize하고, 일부는 인스턴스 윤곽을 감지하고, 일부는 위치에 민감한 directional map을 인코딩한다. 대부분 이러한 task의 결합을 수행한다.
이 접근 방식에는 몇 가지 실용적인 이점도 있다.
- 무엇보다도 빠르다: 병렬 구조와 초경량 어셈블리 프로세스로 인해 YOLACT는 one-stage backbone detector에 약간의 계산 오버헤드만 추가하므로 ResNet-101을 사용할 때도 쉽게 30fps에 도달할 수 있다. 실제로 전체 마스크 분기를 평가하는 데 5ms밖에 걸리지 않는다.
- 마스크는 고품질이다: 마스크는 리풀링으로 인한 품질 손실 없이 이미지 space의 전체 범위를 사용하기 때문에 큰 물체에 대한 마스크는 다른 방법의 마스크보다 훨씬 고품질이다.
- 일반적이다: 프로토타입과 마스크 계수를 생성하는 아이디어는 거의 모든 최신 object detector에 추가할 수 있다.
YOLACT
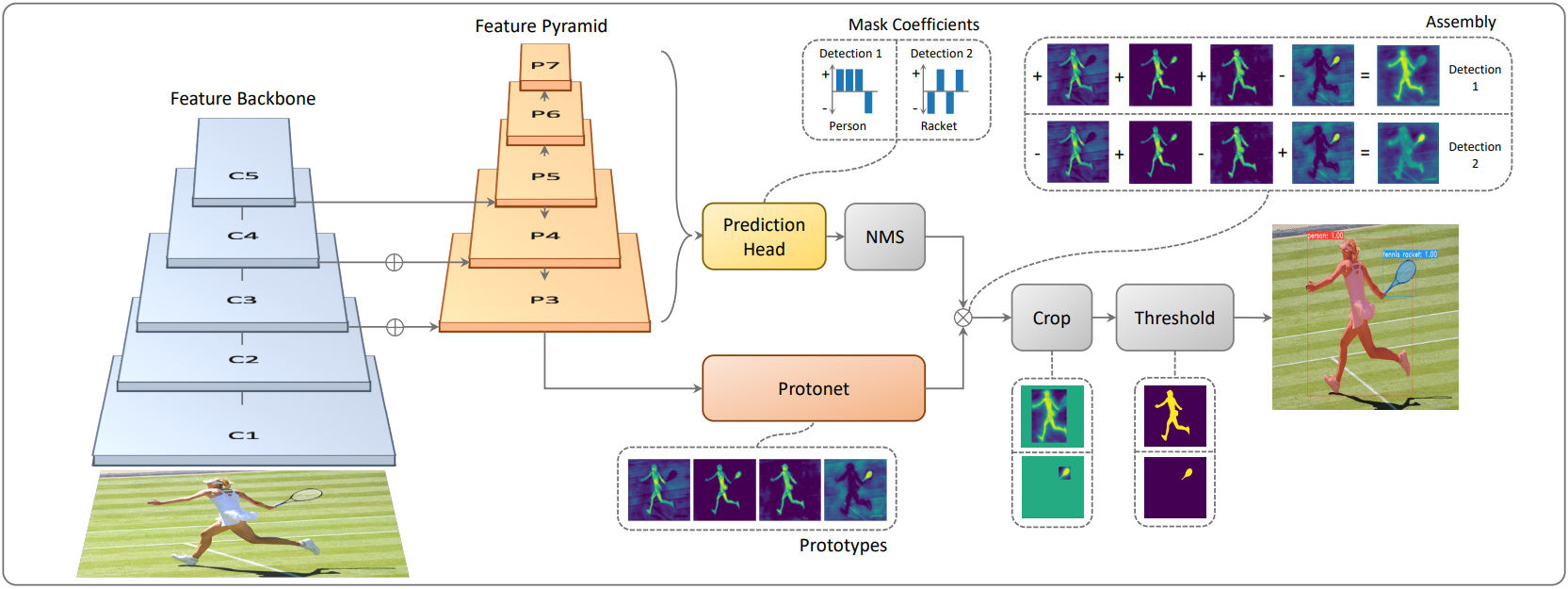
본 논문의 목표는 Mask R-CNN이 Faster R-CNN에 하는 것과 같은 맥락에서 기존의 one-stage object detector 모델에 마스크 분기를 추가하는 것이지만 명시적인 feature localization 단계 (ex. feature repooling)는 없다. 이를 위해 복잡한 instance segmentation task를 최종 마스크를 형성하기 위해 조립할 수 있는 두 개의 더 간단한 병렬 task로 나눈다.
첫 번째 분기는 FCN을 사용하여 어떤 인스턴스에도 의존하지 않는 이미지 크기의 “프로토타입 마스크” 집합을 생성한다. 두 번째는 프로토타입 space에서 인스턴스의 표현을 인코딩하는 각 앵커에 대한 “마스크 계수” 벡터를 예측하기 위해 object detection 분기에 오버헤드를 추가한다. 마지막으로 NMS에서 살아남은 각 인스턴스에 대해 이 두 분기의 task을 선형 결합하여 해당 인스턴스에 대한 마스크를 구성한다.
이론적 해석
주로 마스크가 공간적으로 일관성이 있기 때문에 이러한 방식으로 instance segmentation을 수행한다. 즉, 서로 가까운 픽셀은 동일한 인스턴스의 일부일 가능성이 높다. Convolutional (conv) layer는 자연스럽게 이러한 일관성을 활용하지만 fully-connected (fc) layer는 그렇지 않다. One-stage object detector가 fc layer의 출력으로 각 앵커에 대한 클래스 및 상자 계수를 생성하기 때문에 문제가 발생한다. Mask R-CNN과 같은 2-stage 접근 방식은 localization 단계 (ex. RoIAign)를 사용하여 이 문제를 해결한다. 마스크가 conv layer 출력이 되도록 허용하면서 feature의 공간적 일관성을 유지한다. 그러나 이렇게 하려면 localization 후보를 제안하기 위해 one-stage RPN을 기다려야 하는 모델의 상당 부분이 필요하므로 상당한 속도 페널티가 발생한다.
따라서 문제를 두 개의 병렬 부분으로 나누어 semantic 벡터를 생성하는 데 능숙한 fc layer와 공간적으로 일관된 마스크를 생성하는 데 능숙한 conv layer를 사용하여 “마스크 계수”와 “프로토타입 마스크”를 각각 생성한다. 그러면 프로토타입과 마스크 계수를 독립적으로 계산할 수 있기 때문에 backbone detector의 계산 오버헤드는 대부분 단일 행렬 곱셈으로 구현할 수 있는 조립 단계에서 발생한다. 이러한 방식으로 feature space에서 공간적 일관성을 유지하면서 여전히 one-stage로 빠르게 진행할 수 있다.
1. Prototype Generation
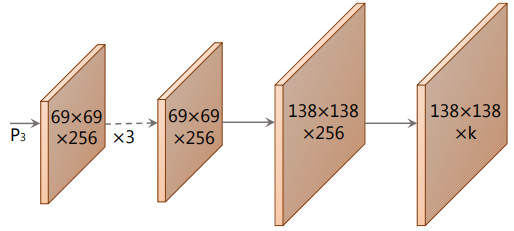
프로토타입 생성 분기 (protonet)는 전체 이미지에 대한 $k$개의 프로토타입 마스크 집합을 예측한다. 마지막 레이어에 $k$개의 채널 (각 프로토타입당 하나씩)이 있는 FCN으로 protonet을 구현하고 이를 backbone feature layer에 연결한다 (위 그림 참조). 이 공식은 표준 semantic segmentation과 유사하지만 프로토타입에서 명시적인 loss를 나타내지 않는다는 점에서 다르다. 대신 이러한 프로토타입에 대한 모든 supervision은 조립 후 최종 마스크 loss에서 비롯된다.
저자들은 두 가지 중요한 디자인 선택에 주목하였다. 더 깊은 backbone feature에서 protonet을 가져오면 더 강력한 마스크가 생성되고 고해상도 프로토타입은 더 작은 개체에서 더 높은 품질의 마스크와 더 나은 성능을 제공한다. 따라서 가장 큰 feature layer가 가장 깊기 때문에 FPN을 사용한다. 그런 다음 작은 물체에 대한 성능을 높이기 위해 입력 이미지 크기의 1/4로 업샘플링한다.
마지막으로, 네트워크가 매우 확신하는 프로토타입 (ex. 명백한 배경)에 대해 크고 압도적인 activation을 생성할 수 있기 때문에 protonet의 출력이 제한되지 않는 것이 중요하다. 따라서 ReLU를 사용하거나 nonlinearity가 없는 protonet을 따르는 옵션이 있다. 저자들은 더 해석 가능한 프로토타입을 위해 ReLU를 선택하였다.
2. Mask Coefficients
일반적인 앵커 기반 object detector에는 예측 헤드에 두 개의 분기가 있다. 하나는 $c$개의 클래스 신뢰도를 예측하는 분기이고 다른 하나는 4개의 boundary box regressor를 예측하는 분기이다. 마스크 계수 예측을 위해 각 프로토타입에 해당하는 $k$개의 마스크 계수를 예측하는 세 번째 분기를 병렬로 추가하기만 하면 된다. 따라서 앵커당 $4 + c$개의 계수를 생성하는 대신 $4 + c + k$개를 생성한다.
Nonlinearity를 위해 최종 마스크에서 프로토타입을 뺄 수 있는 것이 중요하다. 따라서 $k$ 개의 마스크 계수에 tanh를 적용하여 nonlinearity가 없을 때보다 안정적인 출력을 생성한다.
3. Mask Assembly
인스턴스 마스크를 생성하기 위해 프로토타입 분기와 마스크 계수 분기의 작업을 결합하여 둘을 계수로 선형 결합한다. 그런 다음 시그모이드를 따라 최종 마스크를 생성한다. 이러한 연산은 단일 행렬 곱셈과 시그모이드를 사용하므로 효율적으로 구현할 수 있다.
\[\begin{equation} M = \sigma (PC^\top) \end{equation}\]여기서 $P$는 프로토타입 마스크의 $h \times w \times k$ 행렬이고 $C$는 NMS와 점수 thresholding에서 살아남은 $n$개의 인스턴스에 대한 마스크 계수의 $n \times k$ 행렬이다. 다른 더 복잡한 조합 단계도 가능하지만 기본적으로 선형 결합으로 간단하고 빠르게 유지한다.
Losses
모델 학습에 3개의 loss를 사용한다.
- $L_\textrm{cls}$: classification loss
- $L_\textrm{box}$: box regression loss
- $L_\textrm{mask}$: mask loss
가중치는 각각 1, 1.5, 6.125이다. $L_\textrm{cls}$와 $L_\textrm{box}$는 SSD와 동일한 방법으로 정의된다. $L_\textrm{mask}$는 간단하게 조립된 마스크 $M$과 ground-truth mask $M_\textrm{gt}$ 사이의 pixel-wise binary cross entropy로 계산된다.
\[\begin{equation} L_\textrm{mask} = \textrm{BCE}(M, M_\textrm{gt}) \end{equation}\]Cropping Masks
평가 시 예측된 boundary box로 최종 마스크를 자른다. 대신 학습하는 동안은 ground-truth boundary box로 자르고 $L_\textrm{mask}$를 ground-truth boundary box 영역으로 나누어 프로토타입의 작은 개체를 보존한다.
4. Emergent Behavior
Instance segmentation에 대한 일반적인 합의는 FCN이 translation 불변이기 때문에 task에 translation 분산을 다시 추가해야 한다는 것이기 때문에 YOLACT는 놀랍게 보일 수 있다. 따라서 FCIS나 Mask R-CNN과 같은 방법은 directional map과 위치에 민감한 리풀링을 사용하든지 또는 localizing 인스턴스를 처리할 필요가 없도록 마스크 분기를 두 번째 단계에 배치하여 translation 분산을 명시적으로 추가하려고 한다. YOLACT에서 추가된 유일한 translation 분산은 예측된 boundary box로 최종 마스크를 자르는 것이다. 그러나 이 방법은 중형 및 대형 개체에 대해 자르기 없이도 작동하므로 자르기의 결과가 아니다. 대신 YOLACT는 프로토타입에서 다양한 activation을 통해 자체적으로 인스턴스를 localize하는 방법을 배운다.

이것이 어떻게 가능한지 확인하려면 먼저 위 그림의 단색 빨간색 이미지 a에 대한 프로토타입 activation이 실제로 패딩이 없는 FCN에서는 불가능하다는 점에 유의해야 한다. Convolution은 단일 픽셀로 출력되기 때문에 이미지의 모든 입력이 동일하면 conv 출력의 모든 결과가 동일하다. 반면에 ResNet과 같은 최신 FCN의 일관된 패딩 테두리는 네트워크에서 픽셀이 이미지 가장자리에서 얼마나 멀리 떨어져 있는지 알려주는 기능을 제공한다. 개념적으로 이를 달성할 수 있는 한 가지 방법은 패딩된 0을 가장자리에서 중앙을 향해 순차적으로 여러 레이어를 배치하는 것이다 (ex. $[1,0]$과 같은 커널 사용). 이것은 예를 들어 ResNet이 본질적으로 translation 변형이며 본 논문의 방법이 해당 속성을 많이 사용한다는 것을 의미한다 (이미지 b와 c는 명확한 translation 변형을 나타낸다).
이미지의 특정 “파티션”에서 활성화되는 많은 프로토타입을 관찰할 수 있다. 즉, 프로타입들은 암묵적으로 학습된 경계의 한쪽에 있는 객체에서만 활성화된다. 프로토타입 1-3이 그러한 예이다. 이러한 파티션 맵을 결합함으로써 네트워크는 동일한 semantic 클래스의 서로 다른 (심지어 겹치는) 인스턴스를 구별할 수 있다. 예를 들어 이미지 d의 경우 프로토타입 2에서 프로토타입 3을 빼서 녹색 우산을 빨간색 우산에서 분리할 수 있다.
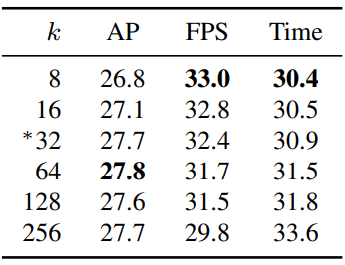
게다가 학습된 객체인 프로토타입은 압축할 수 있다. 즉, protonet이 여러 프로토타입의 기능을 하나로 결합하면 마스크 계수 분기는 어떤 상황에서 어떤 기능이 필요한지 학습할 수 있다. 예를 들어 프로토타입 2는 분할 프로토타입이지만 왼쪽 하단 모서리에 있는 인스턴스에서 가장 강력하게 실행된다. 프로토타입 3은 유사하지만 오른쪽에 있는 인스턴스에 대한 것이다. 이는 실제로 모델이 $k = 32$개 정도의 낮은 프로토타입으로도 성능이 저하되지 않는 이유를 설명한다.
반면에 $k$를 늘리는 것은 계수를 예측하기 어렵기 때문에 비효율적일 가능성이 크다. 네트워크가 하나의 계수라도 큰 오차를 만들면 선형 결합의 특성으로 인해 생성된 마스크가 사라지거나 다른 객체의 누출이 포함될 수 있다. 따라서 네트워크는 올바른 계수를 생성하기 위해 균형을 잡아야 하며 더 많은 프로토타입을 추가하면 이 작업이 더 어려워진다. 사실 $k$ 값이 높을수록 네트워크는 단순히 $\textrm{AP}_95$를 약간 증가시키는 작은 변동이 있는 중복 프로토타입을 추가하지만 그 외에는 그다지 많지 않다.
Backbone Detector
Backbone detector의 경우, 이러한 프로토타입과 계수를 예측하는 것이 좋은 feature를 필요로 하는 어려운 task이기 때문에 속도를 feature의 풍부함만큼 우선시한다. 따라서 backbone detector의 디자인은 속도에 중점을 두고 RetinaNet을 밀접하게 따른다.
YOLACT Detector
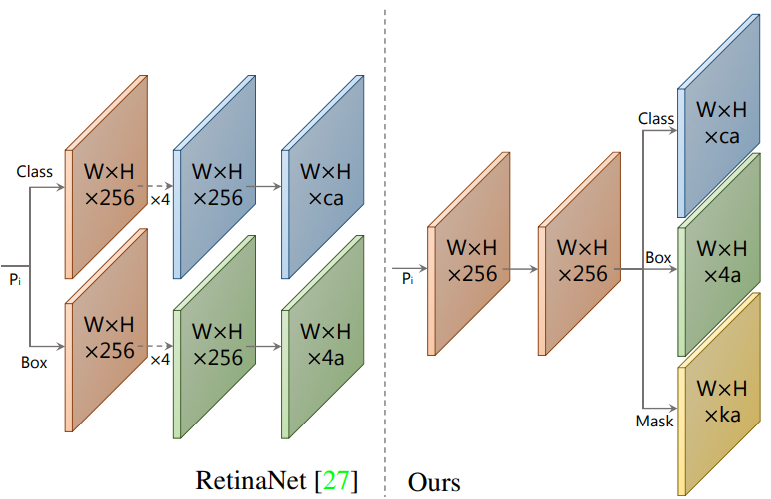
기본 feature backbone으로 FPN과 기본 이미지 크기가 550$\times$550인 ResNet-101을 사용한다. 이미지당 일관된 평가 시간을 얻기 위해 종횡비를 유지하지 않는다. RetinaNet과 마찬가지로 $P_2$를 생성하지 않고 $P_6$와 $P_7$을 $P_5$에서 시작하여 연속적인 3$\times$3 stride 2 conv 레이어로 생성하고 각각에 종횡비가 있는 3개의 앵커를 배치하여 FPN을 수정한다. $P_3$의 앵커는 24$\times$24의 영역을 가지며 모든 후속 레이어는 이전 레이어의 두 배 크기를 갖는다. 각 $P_i$에 연결된 예측 헤드의 경우 세 가지 모두에서 하나의 3$\times$3 conv를 공유하고 각 분기는 병렬로 자체 3$\times$3 conv를 얻는다. RetinaNet과 비교할 때 YOLACT의 예측 헤드 디자인은 더 가볍고 훨씬 빠르다 (위 그림 참조). Smooth-L1 loss를 box regressor에 적용하고 SSD와 같은 방식으로 box regression 좌표를 인코딩한다. 클래스 예측을 학습하기 위해 $c$개의 레이블과 1개의 배경 레이블이 있는 softmax cross entropy를 사용하고 3:1 neg:pos 비율로 OHEM을 사용하여 학습 예제를 선택한다. 따라서 RetinaNet과 달리 YOLACT는 focal loss를 사용하지 않는다.
이러한 디자인 선택을 통해 이 backbone은 동일한 이미지 크기로 ResNet-101을 사용하며, 수정된 SSD보다 더 빠르고 더 나은 성능을 보인다.
Other Improvements
Fast NMS
대부분의 object detector와 마찬가지로 각 앵커에 대한 bounding box regression 계수와 클래스 신뢰도를 생성한 후 NMS를 수행하여 중복 감지를 억제한다. 많은 이전 연구들에서 NMS는 순차적으로 수행되었다. 즉, 데이터셋의 $c$개의 각 클래스에 대해 신뢰도에 따라 내림차순으로 감지된 box를 정렬한 다음, 각각에 대해 신뢰도가 낮은 모든 box를 제거하였다. 이 순차 접근 방식은 약 5fps의 속도에서 충분히 빠르지만 30fps를 얻는 데 큰 장벽이 된다.
기존 NMS의 순차적 특성을 수정하기 위해 모든 인스턴스를 병렬로 유지하거나 삭제할 수 있는 NMS 버전인 Fast NMS를 도입한다. 이를 위해 이미 제거된 detection이 다른 detection을 억제하도록 허용하기만 하면 된다. 이는 기존 NMS에서는 불가능하다. 이러한 완화를 통해 표준 GPU 가속 행렬 연산에서 Fast NMS를 완전히 구현할 수 있다.
Fast NMS를 수행하기 위해 먼저 $c$개의 각 클래스에 대해 점수별로 내림차순으로 정렬된 상위 $n$개의 detection에 대해 $c \times n $\times$ n$개의 쌍별 IoU 행렬 $X$를 계산한다. GPU에서 일괄 정렬을 쉽게 사용할 수 있으며 IoU 계산은 쉽게 벡터화할 수 있다. 그런 다음 일부 임계값 $t$보다 큰 IoU를 가진 더 높은 점수의 detection이 있는 경우 detection을 제거한다. 먼저 $X$의 아래쪽 삼각형과 대각선을 0으로 설정하고 (triu) 열별로 최대값을 구하여 각 detection에 대한 최대 IoU 값의 행렬 $K$를 계산한다.
\[\begin{equation} X_{kij} = 0, \quad \forall k, j, i \ge j \\ K_{kj} = \max_i (X_{kij}), \quad \forall k, j \end{equation}\]마지막으로 이 행렬을 $t$ ($K < t$)로 thresholding하면 각 클래스에 대해 유지할 detection을 나타낸다.
완화로 인해 Fast NMS는 약간 너무 많은 box를 제거하는 효과가 있다. 그러나 이로 인해 발생하는 성능 저하는 속도의 현저한 증가에 비해 무시할 수 있다.
다음은 Fast NMS에 대한 ablation study 결과이다.
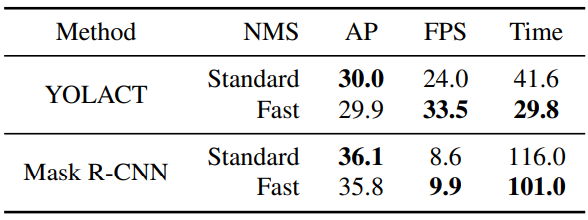
Fast NMS는 기존 NMS의 Cython 구현보다 11.8ms 더 빠르지만 성능은 0.1mAP만 감소한다. Mask R-CNN 벤치마크에서 Fast NMS는 기존 NMS의 CUDA 구현보다 15.0ms 더 빠르며 성능 손실은 0.3mAP에 불과하다.
Semantic Segmentation Loss
Fast NMS는 속도를 위해 약간의 성능을 희생하지만 속도 저하 없이 성능을 향상시킬 수 있는 방법이 있다. 이러한 방법 중 하나는 테스트 시에 실행되지 않은 모듈을 사용하여 학습 중에 모델에 추가 loss를 적용하는 것이다. 이 방법은 속도 저하 없이 feature의 풍부함을 효과적으로 증가시킨다.
따라서 학습 중에만 평가되는 레이어를 사용하여 feature space에 semantic segmentation loss를 적용한다. 인스턴스 주석에서 이 loss에 대한 ground-truth 정보를 구성하기 때문에 이것은 semantic segmentation을 엄격하게 캡처하지 않는다. 학습 중에 예측을 생성하려면 출력 채널이 $c$인 1$\times$1 conv layer를 backbone에서 가장 큰 feature map ($P_3$)에 직접 연결하기만 하면 된다. 각 픽셀은 둘 이상의 클래스에 할당될 수 있으므로 softmax와 $c + 1$개의 채널 대신 시그모이드와 $c$개의 채널을 사용한다. 이 loss에는 가중치 1이 지정되고 결과적으로 +0.4 mAP의 성능 향상이 발생한다.
Results
- 데이터셋: MS COCO, Pascal 2012 SBD
- 구현 디테일
- ImageNet에서 사전 학습된 가중치를 사용하여 모든 모델을 학습
- Batch size: 8
- 사전 학습된 batch norm은 고정시키지 않으며, 추가 bn layer를 더하지 않음
- Optimizer: SGD
- Iteration: 80만
- Learning rate: 맨 처음에 $10^{-3}$이고, 28만, 60만, 70만, 75만 iteration에서 10으로 나눔
- Weight decay $5 \times 10^{-4}$, momentum 0.9
- SSD와 동일한 data augmentation
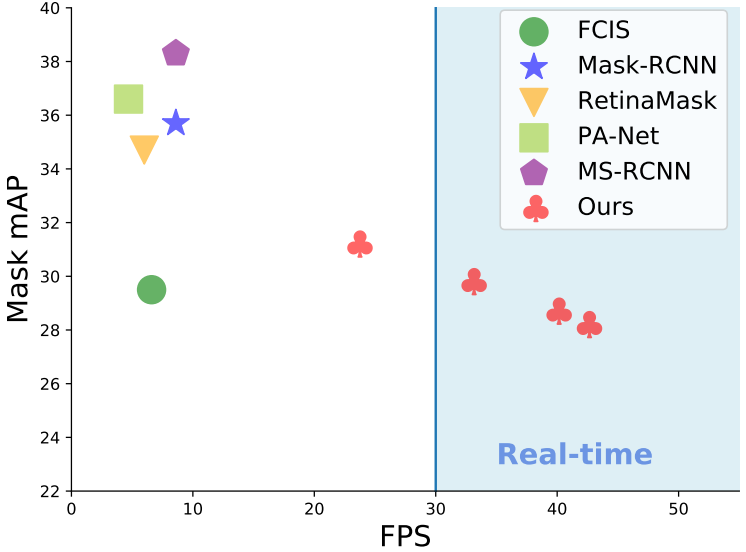
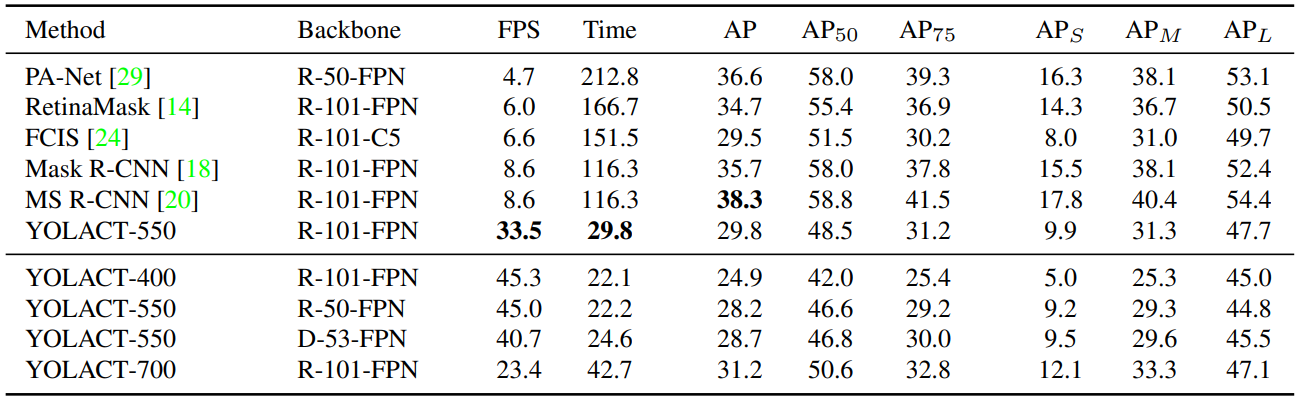
다음은 MS COCO에서의 결과이다.
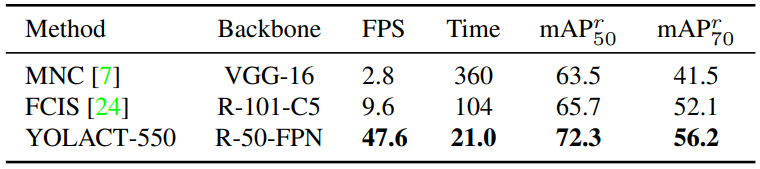
다음은 Pascal 2012 SBD에서의 결과이다.
다음은 마스크 품질을 비교한 것이다.

다음은 MS COCO의 test-dev set에서 YOLACT를 평가한 결과이다.

