[논문리뷰] WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
arXiv 2021. [Paper] [Page] [Github]
Nanxin Chen, Yu Zhang, Heiga Zen, Ron J. Weiss, Mohammad Norouzi, Najim Dehak, William Chan
Center for Language and Speech Processing, Johns Hopkins University | Brain Team, Google Research
17 Jun 2021
Introduction
딥 러닝은 TTS 합성에 혁명을 일으켰다. TTS는 입력 텍스트 시퀀스를 음성 시퀀스에 매핑하는 multi-modal 생성 문제이다. 대부분의 신경 TTS 시스템은 2단계 생성 프로세스를 따른다. 첫 번째 단계에서 feature 생성 모델은 텍스트 또는 음소 시퀀스에서 중간 표현, 일반적으로 선형 또는 mel-spectrogram을 생성한다. 중간 표현은 파형의 구조를 제어하며 일반적으로 풍부한 분포를 캡처하기 위해 autoregressive 아키텍처에 의해 생성된다. 다음으로 vocoder는 중간 feature를 입력으로 사용하고 파형을 예측한다. Inference하는 동안 feature 생성 모델에서 예측된 feature를 입력으로 사용하기 때문에 vocoder는 종종 예측된 feature를 입력으로 사용하여 학습된다.
이 2단계 TTS 파이프라인은 높은 fidelity의 오디오를 생성할 수 있지만 학습된 모듈을 계단식으로 사용하기 때문에 적용이 복잡할 수 있다. 또 다른 우려는 주로 경험에 의해 선택되는 중간 feature와 관련이 있다. 예를 들어 mel-spectrogram feature는 일반적으로 잘 작동하지만 모든 애플리케이션에 대해 최선의 선택이 아닐 수 있다. 대조적으로, 데이터 기반 end-to-end 접근 방식의 이점은 기계 학습 전반의 다양한 영역에서 널리 관찰되었다. End-to-end 접근 방식은 일반적으로 task별 학습 데이터에서 자동으로 최상의 중간 feature를 학습할 수 있다. 또한 다른 단계에서 supervision 및 ground-truth 신호가 필요하지 않기 때문에 학습시키기가 더 쉽다.
End-to-end TTS 모델에는 두 가지가 있다. Autoregressive model은 tractable한 likelihood 계산을 제공하지만 inference 시간에 파형 샘플을 반복적으로 생성해야 하므로 속도가 느릴 수 있다. 반대로 non-autoregressive model은 효율적인 병렬 생성을 가능하게 하지만 토큰의 duration 정보가 필요하다. 학습을 위한 레퍼런스 토큰의 duration은 일반적으로 offline forced-alignment model로 계산된다. 생성 duration을 예측하기 위해 ground-truth duration을 예측하도록 추가 모듈을 학습한다.
보다 최근의 연구들은 end-to-end TTS에 non-autoregressive model을 적용하는 데 중점을 두었다. 그러나 그들은 alignment을 위해 여전히 spectral loss와 mel-spectrogram에 의존하며 end-to-end 학습을 최대한 활용하지 않는다. FastSpeech 2는 후보 출력 시퀀스의 수를 줄이기 위해 피치나 에너지와 같은 추가 컨디셔닝 신호가 필요하다. EATS는 아키텍처를 더욱 복잡하게 만드는 일대다 매핑 문제를 처리하기 위해 spectrogram loss뿐만 아니라 적대적 학습을 사용한다.
본 논문에서는 중간 feature나 특화된 loss function이 필요하지 않은 non-autoregressive phoneme-to-waveform model인 WaveGrad 2를 제안한다. 아키텍처를 보다 end-to-end로 만들기 위해 WaveGrad 디코더는 Tacotron 2 스타일 non-autoregressive 인코더에 통합되었다. WaveGrad 디코더는 random noise에서 시작하여 입력 신호를 반복적으로 정제하고 충분한 step을 거쳐 고음질 오디오를 생성할 수 있다. 일대다 매핑 문제는 log-likelihood의 가중 VLB를 최적화하는 score-matching 목적 함수에 의해 처리된다.
Non-autoregressive 인코더는 텍스트 인코더와 Gaussian resampling layer를 결합하여 duration 정보를 통합하는 최근에 제안된 non-attentive Tacotron을 따른다. Ground-truth duration은 학습 중에 활용되며 duration predictor는 이를 추정하기 위해 학습된다. Inference 중에 duration predictor는 각 입력 토큰의 duration을 예측한다. Attention 기반 모델과 비교할 때 이러한 duration predictor는 attention 실패에 훨씬 더 탄력적이며 위치를 계산하는 방법으로 인해 monotonic alignment가 보장된다.
WaveGrad 2
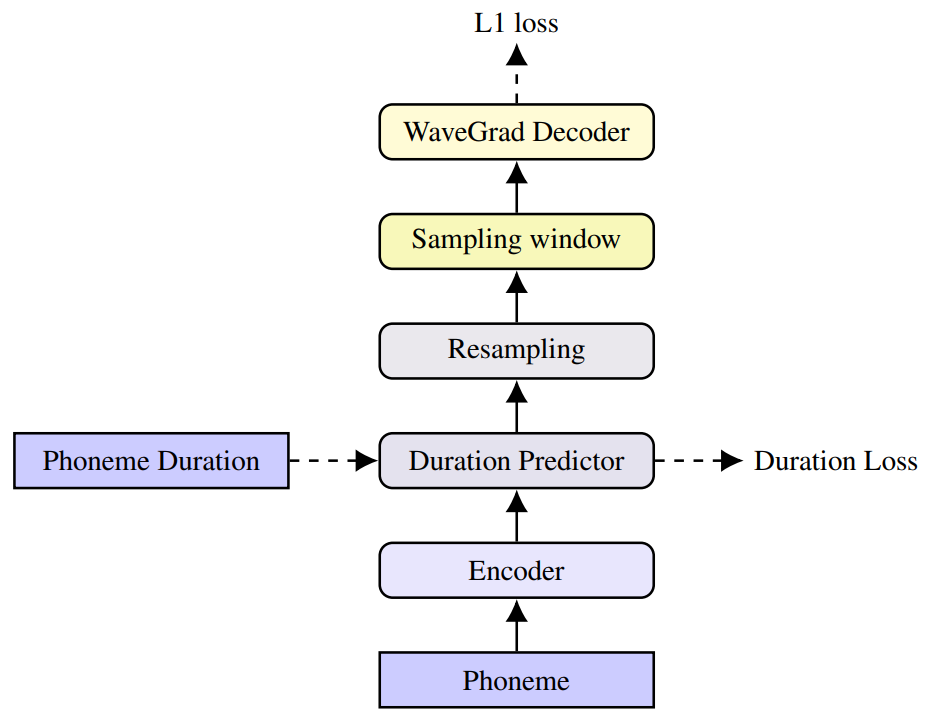
제안된 모델은 위 그림과 같은 세 가지 모듈을 포함한다.
- 인코더는 음소 시퀀스를 입력으로 사용하고 입력 컨텍스트에서 추상적인 hidden representation을 추출한다.
- Resampling layer는 10ms segment로 양자화된 출력 파형 시간 스케일과 일치하도록 인코더 출력의 해상도를 변경한 (일반적인 mel-spectrogram feature와 유사). 이는 학습 중 목표 duration으로 컨디셔닝함으로써 달성된다. Duration predictor module에서 예측한 duration은 inference 중에 활용된다.
- WaveGrad 디코더는 noisy한 파형을 반복적으로 정제하여 파형을 예측한다. 각 iteration에서 디코더는 점차적으로 신호를 정제하고 세분화된 디테일을 추가한다.
1. Encoder
인코더의 디자인은 Tacotron 2의 디자인을 따른다. 음소 토큰은 단어 boundary에 삽입된 무음 토큰과 함께 입력으로 사용된다. 시퀀스 종료 토큰은 각 문장 뒤에 추가된다. 토큰은 먼저 학습된 임베딩으로 변환된 다음 dropout과 batch normalization layer가 있는 3개의 convolution layer를 통과한다. 마지막으로, 출력을 ZoneOut regularization을 사용하여 양방향 LSTM layer를 통해 전달하여 장기 컨텍스트 정보를 모델링한다.
2. Resampling
출력 파형 시퀀스의 길이는 인코더 표현의 길이와 매우 다르다. Tacotron 2에서는 attention mechanism으로 이를 해결한다. 구조를 non-autoregressive로 만들고 inference 속도를 향상시키기 위해 non-attentive Tacotron에 도입된 Gaussian upsampling을 채택한다. Duration에 따라 각 토큰을 반복하는 대신 Gaussian upsampling은 duration과 영향 범위를 동시에 예측한다. 이 파라미터들은 예측된 위치에 전적으로 의존하는 attention 가중치 계산에 사용된다. 학습 중에는 ground-truth duration이 대신 사용되며 duration predictor를 학습시키기 위해 추가로 mean square loss가 측정된다. 이는 위 그림에서 Duration Loss로 레이블되어 있다. Inference 중에는 ground-truth duration이 필요하지 않으며 대신 예측된 duration이 사용된다.
3. Sampling Window
파형 해상도가 매우 높기 때문에 (본 논문의 경우 초당 24,000개 샘플) 높은 계산 비용과 메모리 제약으로 인해 발화의 모든 파형 샘플에 대한 loss를 계산하는 것은 불가능하다. 대신 전체 입력 시퀀스에 대한 표현을 학습한 후 작은 세그먼트를 샘플링하여 파형을 합성한다. Resampling layer로 인해 인코더 표현과 파형 샘플이 이미 정렬되어 있다. 랜덤 세그먼트는 각 mini-batch에서 개별적으로 샘플링되고 해당 파형 세그먼트는 upsampling 속도(본 논문에서는 300)에 따라 추출된다. 전체 인코더 시퀀스(resampling 후)는 inference 중에 사용되며, 학습과 inference 간에 약간의 불일치가 발생한다.
4. Decoder
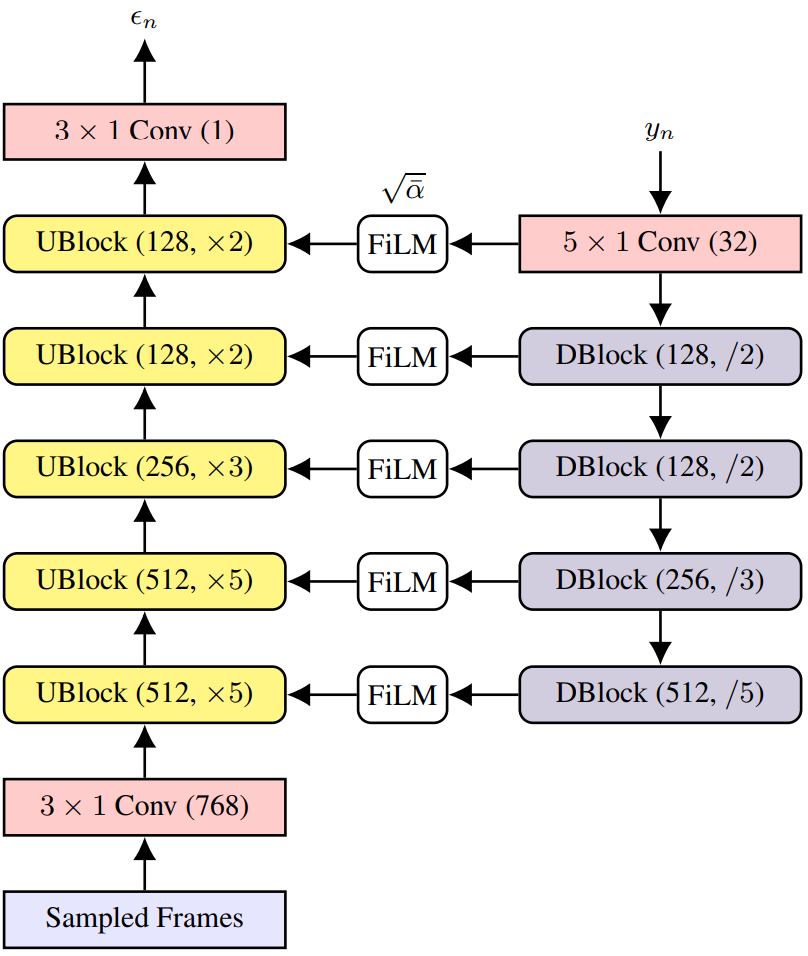
디코더는 hidden representation을 점진적으로 upsampling하여 파형 해상도와 일치시킨다. 본 논문의 경우 파형은 24kHz로 샘플링되었으며 300배로 upsampling해야 한다. 이는 위 그림과 같이 WaveGrad 디코더를 사용하여 달성된다. 아키텍처에는 5개의 upsampling block(UBlock)과 4개의 downsampling block(DBlock)이 포함된다. 생성 프로세스의 각 iteration에서 네트워크는 다음 방정식에 따라 hidden representation으로 컨디셔닝하여 포함된 noise 항 $\epsilon_n$을 예측하여 noisy한 입력 파형 추정치 $y_n$을 denoise한다.
생성 프로세스는 random noise 추정치 $y_N$에서 시작하고, 파형 샘플을 생성하기 위해 $N$ (일반적으로 1000으로 설정) step에 걸쳐 반복적으로 정제한다. WaveGrad 논문을 따라 목적 함수는 예측된 noise 항과 ground-truth noise 항 사이의 L1 loss이다.
\[\begin{equation} \mathbb{E}_{\bar{\alpha}, \epsilon} [\| \epsilon_\theta (\sqrt{\vphantom{1} \bar{\alpha}} y_0 + \sqrt{1 - \bar{\alpha}} \epsilon, x, \sqrt{\vphantom{1} \bar{\alpha}}) - \epsilon\|_1] \end{equation}\]학습 중에 이 loss는 랜덤하게 샘플링된 단일 iteration을 사용하여 계산된다.
Experiments
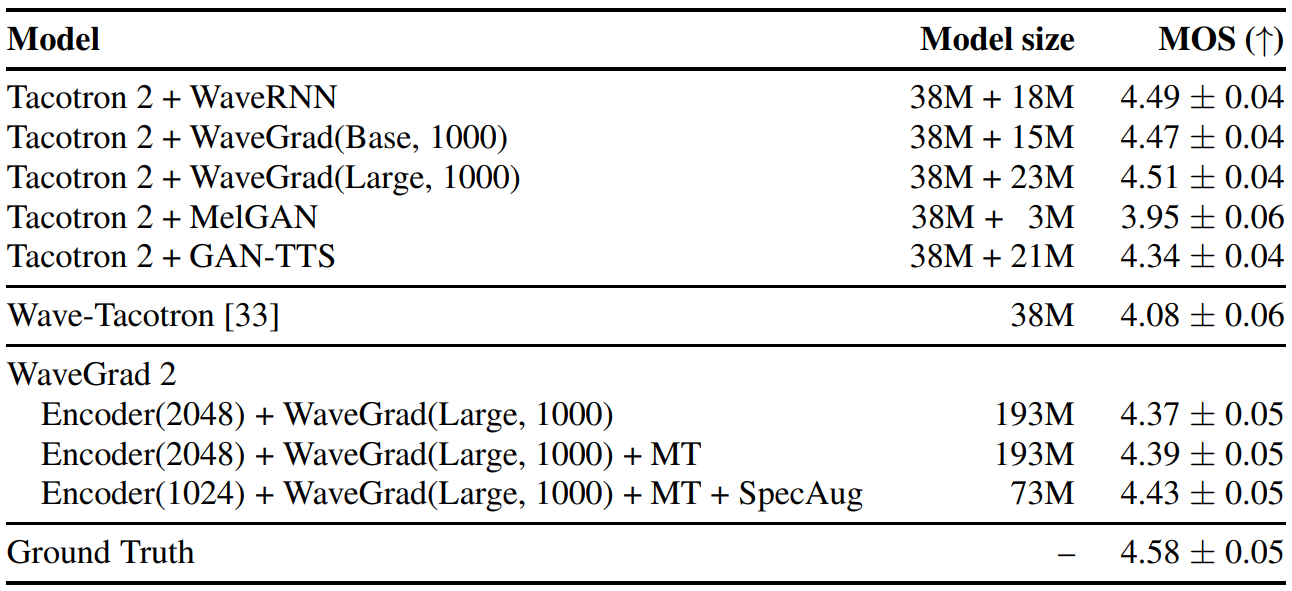
다음은 주관적 평가 결과(MOS)를 나타낸 표이다.
1. Sampling Window Size
메모리 사용량은 end-to-end 학습의 주요 관심사다. 대부분의 계산 병목 현상은 파형 sample rate에서 연산하는 WaveGrad 디코더에서 발생하기 때문에 수초의 발화에 해당하는 긴 시퀀스는 메모리에 맞지 않을 수 있다. 학습을 효율적으로 만들기 위해 resampling된 인코더 표현에서 작은 세그먼트를 샘플링하고 전체 시퀀스 대신 이 세그먼트를 사용하여 디코더 네트워크를 학습시킨다. 각각 0.8초와 3.2초의 음성에 해당하는 64프레임과 256프레임의 두 가지 window size를 살펴보았다.
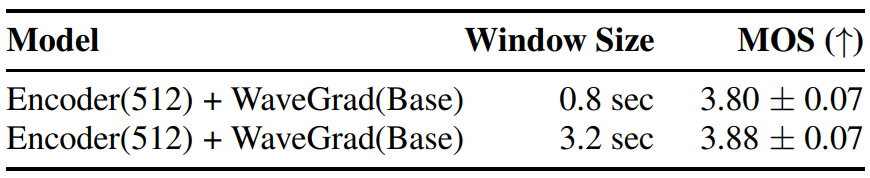
결과는 위 표에 나와 있다. 큰 window를 사용하면 작은 window에 비해 더 나은 MOS를 제공한다. 다음의 모든 실험의 학습에서 큰 window를 사용한다.
2. Network Size
저자들은 다양한 네트워크 크기로 ablation study를 진행하였다. 인코더는 한 번만 계산하면 되므로 차원을 늘려도 inference 속도에 거의 영향을 미치지 않는다. 반면에 WaveGrad 디코더는 반복 횟수에 따라 여러 번 실행해야 한다.
다음은 다양한 네트워크 크기에 대한 MOS를 비교한 표이다.
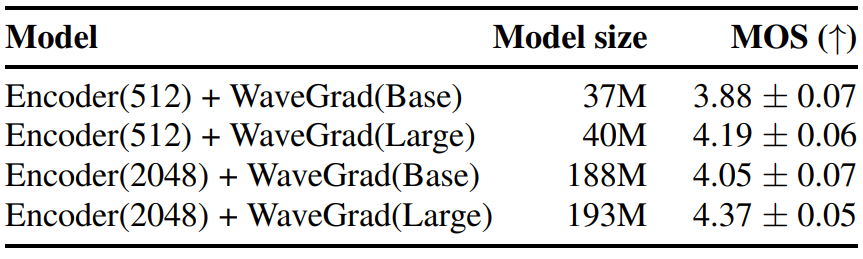
인코더 크기가 클수록 파라미터 수가 크게 증가하고 품질이 약간 향상되었음을 표에서 볼 수 있다. 그러나 더 큰 WaveGrad 디코더를 사용하는 것에 비해 개선이 더 작았으며, 이는 더 큰 디코더를 갖는 것이 중요함을 나타낸다.
3. Hidden Features Augmentation
저자들은 SpecAugment의 변형을 디코더에 대한 컨디셔닝 입력(resampling된 인코더 출력)에 적용하는 방법을 살펴보았다. Augmentation은 spectrogram 대신 학습된 hidden representation에 적용된다. 이는 correlated block dropout의 한 형태로 볼 수 있다. 32개의 연속 프레임을 랜덤하게 선택하여 마스킹하고 augmentation을 두 번 적용했다. 직관은 WaveGrad 디코더가 컨텍스트 정보로 컨디셔닝하여 마스크된 부분을 복구할 수 있다는 것이다. 이는 인코더가 더 많은 컨텍스트 정보를 포함하는 강력한 표현을 학습하도록 한다.

결과는 위 표와 같다. 이 regularization로 큰 개선을 관찰하지 못했다.
4. Multi-task Learning and Speed-Quality Tradeoff
저자들은 FastSpeech 2에서 영감을 받아 mel-spectrogram feature를 활용하여 인코더 학습을 개선하는 방법을 살펴보았다. 인코더는 spectrogram feature를 직접 예측할 수 있는 표현을 추출하도록 권장된다. Mel-spectrogram feature를 예측하기 위해 resampling layer 뒤에 별도의 mel-spectrogram 디코더를 추가했다. 이 디코더에는 하나의 upsampling block이 포함되어 있으며 전체 시퀀스에서 추가로 mean squared error(MSE) loss를 측정하였다. Inference하는 동안 FastSpeech 2와 유사한 이 디코더를 간단히 삭제했다.
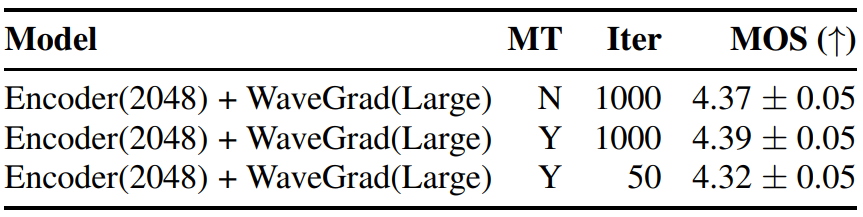
결과는 위 표와 같다. 표에서 볼 수 있듯이 멀티태스킹 학습과 큰 성능 차이는 없었다. 이는 멀티태스킹 학습이 end-to-end 생성에 유익하지 않음을 시사한다. 또한 반복 횟수를 1000에서 50으로 줄이는 방법을 살펴보았고 약간의 성능 저하(약 0.07포인트)가 발생했다.