[논문리뷰] VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
arXiv 2024. [Paper] [Page]
Enric Corona, Andrei Zanfir, Eduard Gabriel Bazavan, Nikos Kolotouros, Thiemo Alldieck, Cristian Sminchisescu
Google Research
13 Mar 2024

Introduction
본 논문은 텍스트나 오디오를 기반으로 한 사람의 이미지 하나만 제공하여 말하고 움직이는 사람의 동영상을 자동으로 생성하는 방법인 VLOGGER를 제시하였다. 사실적인 인간 동영상 제작은 여전히 복잡하고 아티팩트가 많다. 현실적인 결과를 얻으려면 상당한 개입이 필요하다. 그러나 완전 자동화는 창의적인 프로세스를 용이하게 할 뿐만 아니라 완전히 새로운 사용 사례를 가능하게 한다. 한 연구에 따르면 현재의 채팅 에이전트들은 공감 능력을 발달시킬 만큼 자연스러운 것으로 인식되지 않는 것으로 나타났으며, 해당 논문의 저자들은 의인화와 행동 현실주의(ex. 시선, 얼굴 표정, 전신 움직임 등)가 사회적 존재감을 창출하고 사용자로부터 공감을 이끌어내는 데 중요하다고 주장하였다. 본 논문이 목표로 하는 것은 자동화와 행동 현실주의이다. VLOGGER는 음성 및 애니메이션 시각적 표현을 갖춘 구체화된 대화 에이전트에 대한 멀티모달 인터페이스로, 복잡한 얼굴 표정과 증가하는 몸 동작 수준을 특징으로 하며, 인간 사용자와의 자연스러운 대화를 지원한다. VLOGGER는 프리젠테이션, 학습, 내레이션, 저대역 온라인 커뮤니케이션을 위한 독립형 솔루션과 텍스트 전용 HCI(인간-컴퓨터 상호 작용)를 위한 인터페이스로 사용할 수 있다.
멀티모달의 사실적인 인간 합성은 데이터 수집, 자연스러운 방식으로 얼굴 표정 구현, 오디오 동기화 표현, occlusion(가려짐) 또는 전신 움직임 표현과 같은 문제로 인해 복잡하다. 많은 시도들은 동영상의 입 부분을 편집하는 등 립싱크에만 집중한 시도가 많았다. 최근에는 오디오에서 얼굴 동작을 예측하여 단일 이미지에서 talking head 동영상을 생성하기 위해 얼굴 재연의 광범위한 발전에 의존했다. 시간적 일관성은 일반적으로 얼굴 키포인트의 부드러운 모션에 의존하여 프레임별 이미지 생성 네트워크를 통해 달성되었다. 그러나 이로 인해 결과가 흐려질 수 있으며 얼굴에서 더 먼 영역에서는 시간적 일관성이 보장되지 않는다. 결과적으로 대부분의 방법에서는 신체의 상당 부분이 보일 때마다 머리를 감지하고 잘라내야 한다.
본 논문에서 의사소통이 입술과 얼굴 동작이 결합된 단순한 오디오 그 이상이라고 주장한다. 인간은 몸짓, 응시, 깜박임, 포즈를 통해 몸을 사용하여 의사소통한다. 따라서 머리와 손 제스처를 모두 포함하여 현실감과 모션의 다양성에 초점을 맞춘 사람에 구애받지 않는 합성 솔루션을 목표로 한다. 즉, 신원(identity)이나 포즈를 제어하지 않고 역동적인 동영상을 생성할 수 있는 최근의 동영상 합성에 대한 노력과 제어 가능한 이미지 생성 방법 간의 격차를 해소하는 것이 목표이다.
이를 위해 본 논문은 2단계 접근 방식을 제안하였다.
- Diffusion 기반 생성 네트워크가 입력 오디오 신호에 따라 몸 동작과 얼굴 표정을 예측한다. 이러한 확률론적 접근 방식은 음성과 자세, 시선, 표현 간의 미묘한 일대다 매핑을 모델링하는 데 필요하다.
- 시간적, 공간적 도메인에서의 제어를 제공하는 최근 이미지 diffusion model을 기반으로 새로운 아키텍처를 제안하였다. 사전 학습 중에 획득한 생성적 인간 prior에 추가로 의존함으로써 이 결합된 아키텍처가 일관된 인간 이미지를 생성하는 데 종종 어려움을 겪는 이미지 diffusion model을 향상시킨다.
VLOGGER는 고화질 영상을 얻기 위해 base model과 super-resolution diffusion model로 구성되어 있다. 이전 연구와 마찬가지로 얼굴 표정뿐만 아니라 몸과 손도 포함하여 몸 전체를 나타내는 2D 제어 표현들을 통해 동영상 생성 프로세스를 컨디셔닝한다. 임의 길이의 동영상을 생성하기 위해 이전 프레임을 기반으로 새 동영상 클립을 컨디셔닝하는 시간적 아웃페인팅 접근 방식을 따른다.
저자들은 견고성과 일반화를 위해 피부색, 자세, 시점, 음성, 신체 가시성 측면에서 이전에 사용 가능한 데이터보다 훨씬 더 다양한 다양성을 갖춘 대규모 데이터셋을 선별하였다. 이전 시도와 달리 데이터셋에는 인간 의사소통의 복잡성을 학습하는 데 중요한 동적 손 제스처가 포함된 동영상도 포함되어 있다. VLOGGER는 다양한 다양성 측정 메트릭에서 이전 연구들보다 성능이 뛰어나며 HDTF와 TalkingHead-1KH 데이터셋에서 SOTA 이미지 품질과 다양성 결과를 얻었다. 또한, VLOGGER는 머리와 상체 동작에 대한 고해상도 동영상을 생성하고 상당히 다양한 얼굴 표정과 제스처를 특징으로 하여 baseline보다 더 넓은 범위의 시나리오를 고려한다. VLOGGER는 다양한 시나리오에 적응할 수 있는 유연성과 능력을 가지고 있으며, 예를 들어 입술이나 얼굴 등 각 프레임의 선택된 영역을 인페인팅하여 동영상 편집은 물론 개인화에도 사용할 수 있다.
Method
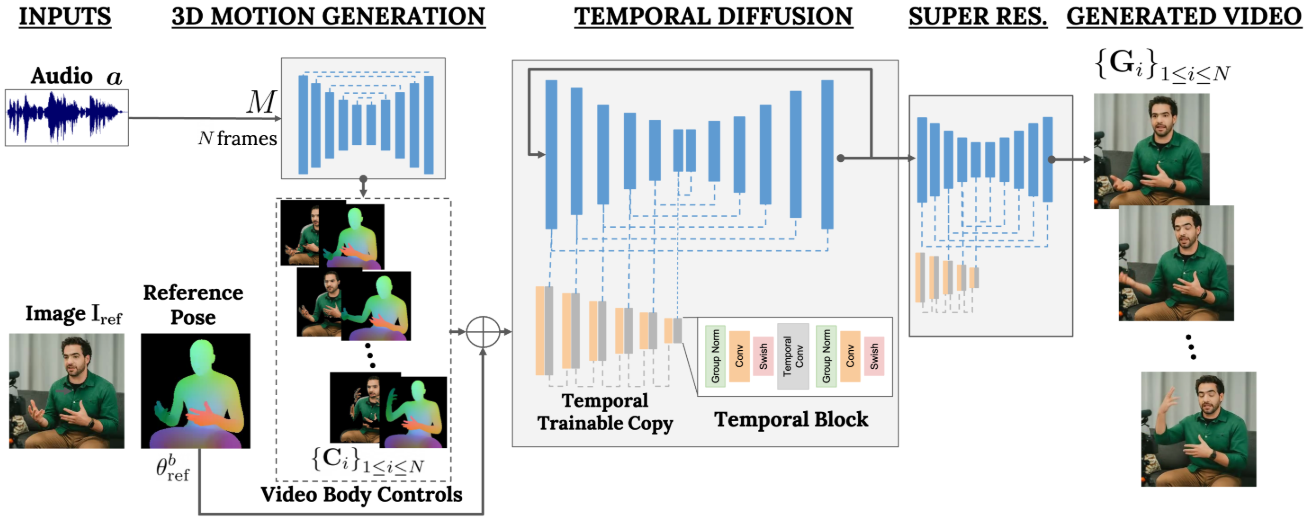
본 논문의 목표는 현실적인 머리 움직임과 몸짓으로 말하는 대상을 합성하는 가변 길이의 사실적인 동영상 $\mathbf{V}$를 생성하는 것이다. VLOGGER라고 부르는 프레임워크는 위 그림에 설명되어 있다. VLOGGER는 음성에서 동영상로의 일대다 매핑을 표현하기 위한 확률론적 diffusion model을 기반으로 하는 2단계 파이프라인이다. 첫 번째 네트워크는 샘플레이트 $S$에서 오디오 파형 $\mathbf{a} \in \mathbb{R}^{NS}$를 입력으로 사용하여 대상 동영상 길이 $N$에 걸쳐 시선, 얼굴 표정, 3D 포즈를 담당하는 중간 신체 모션 제어 표현 $\mathbf{C}$를 생성한다. 두 번째 네트워크는 대형 이미지 diffusion model을 확장한 시간적 image-to-image diffusion model이며, 예측된 신체 제어 표현을 사용하여 해당 프레임을 생성하는 이미지 변환 모델이다. 프로세스를 특정 신원으로 컨디셔닝하기 위해 네트워크는 사람의 레퍼런스 이미지도 가져온다. 새로 도입된 MENTOR 데이터셋을 기반으로 VLOGGER를 학습시킨다.
1. Audio-Driven Motion Generation
아키텍처
파이프라인의 첫 번째 네트워크 $M$은 입력 음성을 기반으로 동작을 예측하도록 설계되었다. 또한 text-to-speech (TTS) 모델을 통해 입력 텍스트를 고려하여 입력을 파형으로 변환하고 결과 오디오를 표준 mel-spectrogram으로 나타낸다. $M$은 시간 차원에 4개의 multi-head attention layer가 있는 transformer 아키텍처를 기반으로 한다. 프레임 수와 diffusion step에 대한 위치 인코딩과 입력 오디오 및 diffusion step에 대한 임베딩 MLP가 포함된다. 각 프레임에서 모델이 이전 프레임에만 attention을 하도록 하기 위해 causal mask를 사용한다. 모델은 가변 길이 동영상을 사용하여 학습되어 매우 긴 시퀀스를 생성할 수 있다.
통계적이고 표현력이 풍부한 3D 신체 모델의 추정된 파라미터를 사용하여 합성된 동영상에 대한 중간 제어 표현을 생성한다. 이러한 모델은 얼굴 표정과 몸 동작을 모두 고려하여 보다 표현력이 풍부하고 역동적인 제스처를 통해 인간 합성의 문을 열었다. 프레임 $i$의 입력 오디오 \(\mathbf{a}_i\)를 기반으로 얼굴 및 신체 파라미터 \(M(\mathbf{a}_i) = \{ \theta_i^e, \Delta \theta_i^b \}\)를 예측하도록 모션 생성 네트워크를 실행한다. 즉, 모델은 표정 $\theta_i^e$와 자세 $theta_i^b$에 대한 residual을 생성한다. 변위 $\Delta \theta_i^b$를 예측함으로써 모델이 대상 피사체에 대한 레퍼런스 포즈 $\theta_\textrm{ref}^b$로 입력 이미지를 취하고 프레임 $1 \le i \le N$에 대해 $\theta_i^b = \theta_\textrm{ref}^b + \Delta \theta_i^b$로 사람을 상대적으로 애니메이션화할 수 있다. 기하학적 도메인에서 사람의 신원은 체형 코드로 모델링된다. 학습과 테스트 중에 파라메트릭 신체 모델을 입력 이미지에 맞춰 얻은 추정된 3D 형상 파라미터를 사용한다. CNN 기반 아키텍처로 2D/3D 예측을 활용하기 위해 예측된 표정 및 자세 파라미터를 사용하여 모델을 위치시키고 몸의 template vertex 위치를 dense한 표현으로 rasterization하여 dense한 마스크 \(\{\mathbf{C}_i^d\}_{1 \le i \le N} \in \mathbb{R}^{H \times W \times 3}\)를 얻는다. 또한 $N_c$개의 서로 다른 semantic 클래스에 대해 몸의 semantic 영역 \(\{\mathbf{C}_i^m\}_{1 \le i \le N} \in \{0, 1\}^{H \times W \times 3}\)를 rasterization한다.
이전의 얼굴 재현 task는 워핑된 이미지에 의존하는 경우가 많았지만 인간 애니메이션을 위한 diffusion 기반 아키텍처에서는 이러한 부분이 간과되었다. 저자들은 이 두 가지 표현 사이의 격차를 해소하고 워핑된 이미지를 사용하여 diffusion process를 가이드할 것을 제안하였다. 이는 네트워크의 task를 촉진하고 피사체의 신원을 보존하는 데 도움이 된다. 레퍼런스 이미지에 표시되는 각 신체 vertex에 픽셀 색상을 할당하고 각 새 프레임에서 몸을 렌더링하여 부분적 워프 \(\{\mathbf{C}_i^w\}_{1 \le i \le N} \in \mathbb{R}^{H \times W \times 3}\)을 얻는다. 모든 렌더링의 경우 rasterization 프로세스에서는 학습 동영상 또는 레퍼런스 이미지에서 추론된 diagonal FOV를 갖춘 전체 full-perspective camera를 가정한다.
Loss functions
이 모델은 조건부 오디오 입력 $\mathbf{a}$를 사용하여 ground truth 샘플 \(x_0 = \{ \{ \theta_i^e, \Delta \theta_i^b \} \}_{1 \le i \le N}\)에 Gaussian noise $\epsilon \sim \mathcal{N}(0,1)$을 점진적으로 추가하는 diffusion 프레임워크를 따른다. 목표는 noise가 추가된 입력 $x_t$에서 추가된 noise를 예측하는 denoising network $\epsilon_\phi$를 학습시켜 실제 머리와 몸의 동작 분포 $x_0 \sim q(x_0 \vert \textbf{a})$를 모델링하는 것이다. 여기서 $t$는 임의의 diffusion step이다. Noise 대신 ground truth 분포를 직접 예측하여 더 나은 성능을 얻는다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \mathbb{E}_{x_0, t, \mathbf{a}, \epsilon \sim \mathcal{N}(0,1)} [ \| x_0 - \epsilon_\phi (x_t, t, \mathbf{a}) \|_2^2 ] \end{equation}\]또한 임의의 주어진 프레임 $i \in N$에 대해 연속되는 프레임에서의 예측 차이에 페널티를 주기 위해 추가적인 temporal loss
\[\begin{equation} \mathcal{L}_\textrm{temp} = \| \epsilon_\phi (x_t, t, \mathbf{a})_{i+1} - \epsilon_\phi (x_t, t, \mathbf{a})_i \|_2^2 \end{equation}\]를 추가한다. 두 loss의 선형 조합, 즉 \(\mathcal{L}_\textrm{diff} + \lambda_\textrm{temp} \mathcal{L}_\textrm{temp}\)를 사용하여 전체 모델을 학습시킨다. 실제로 얼굴 표정에 더 큰 역동성을 허용하면서 머리와 손의 더 부드러운 움직임을 보장하기 위해 표정과 자세에 대해 서로 다른 temporal loss 가중치를 사용한다.
2. Generating Photorealistic Talking and Moving Humans
아키텍처
다음 목표는 입력 이미지 \(\textbf{I}_\textrm{ref}\)를 애니메이션화하여 이전에 예측된 몸과 얼굴의 동작을 따르도록 하는 것이다. 이는 semantic mask, sparse mask, dense mask $\textbf{C}$로 표현된다. 이러한 이미지 기반 제어 표현을 기반으로 SOTA diffusion model을 시간을 인식하도록 확장한다. ControlNet에서 영감을 받아 초기 학습 모델을 고정하고 인코딩 레이어를 0으로 초기화한 복사본을 만들어 시간적 제어 표현 $\textbf{C}$를 입력으로 사용한다. 각 다운샘플링 블록의 첫 번째 레이어 뒤, 두 번째 GroupNorm activation 전에 시간 도메인에 1D convolution layer를 인터리브한다. 네트워크는 $N$개의 연속되는 프레임과 제어 표현을 사용하여 학습되고 입력 제어 표현에 따라 애니메이션이 적용된 레퍼런스 이미지에 대한 짧은 클립을 생성한다.
학습
고유한 인간 피사체에 대한 전체 길이의 동영상으로 구성된 MENTOR 데이터셋에 대하여 모델을 학습시킨다. 학습 중에 네트워크는 일련의 연속 프레임과 사람의 임의 레퍼런스 이미지 \(\textbf{I}_\textrm{ref}\)를 사용하므로 이론적으로는 모든 동영상 프레임을 레퍼런스로 할당할 수 있다. 실제로는 레퍼런스를 클립에서 시간적으로 더 멀리 샘플링한다. 가까운 레퍼런스는 학습을 평범하게 만들고 일반화 잠재력을 떨어지기 때문이다.
네트워크는 먼저 하나의 프레임에서 새로운 제어 레이어를 학습하고 나중에 시간적 성분을 추가하여 동영상을 학습하는 두 단계로 학습된다. 이를 통해 첫 번째 단계에서 큰 batch size를 사용하고 머리 재현을 더 빠르게 학습할 수 있다. 두 단계 모두에서 batch size가 128인 40만 iteration에 대해 learning rate $5 \times 10^{-5}$로 이미지 모델을 학습시킨다.
Loss functions
앞서 설명된 loss와 유사하게, ground truth 이미지 $\textbf{I}$에 noise $\epsilon^I$를 추가하는 diffusion process를 따른다. 학습은 추가된 noise $\epsilon^I$를 예측하도록 내부 데이터 소스에 대해 학습된 Imagen 버전을 기반으로 한다.
\[\begin{equation} \mathcal{L}_\textrm{diff}^I = \mathbb{E}_{x_0^I, t, \mathbf{C}, \epsilon^I \sim \mathcal{N}(0,1)} [\| \epsilon^I - \epsilon_\phi^I (x_t^I, t, \mathbf{C}) \|_2^2] \end{equation}\]Super Resolution
이전 접근 방식은 해상도에 독립적이지만 VLOGGER는 128$\times$128 해상도에서 기본 동영상을 생성하고 cascaded diffusion 접근 방식을 사용하여 256$\times$256 또는 512$\times$512의 고품질 동영상을 위해 두 가지 super-resolution 모델에서 시간적 컨디셔닝을 확장한다. 생성된 이미지는 \(\{\textbf{G}_i\}_{1 \le i \le N}\)으로 표시된다.
Inference 중 temporal outpainting
제안된 temporal diffusion model은 고정된 수의 프레임 $N$만 생성하도록 학습되었으므로 이를 가변 길이의 동영상으로 확장하는 방법은 명확하지 않다. 대부분의 이전 diffusion 기반 동영상 생성 방법은 짧은 클립으로 제한되거나 원활하게 생성된 중간 토큰 표현에 의존하지만 픽셀 도메인의 원활한 변경을 보장하지 않는다. 본 논문은 temporal outpainting에 대한 아이디어를 탐구하였다. 먼저 $N$개의 프레임을 생성한 다음 이전 $N − N^\prime$개를 기반으로 $N^\prime$개의 프레임을 반복적으로 아웃페인팅한다. 두 개의 연속되는 클립 사이의 중첩 정도, 즉 $N -N^\prime$은 품질과 실행 시간 간의 trade-off를 위해 선택된다.
3. MENTOR Dataset
저자들은 한 명의 화자가 주로 카메라를 향하고 상체부터 위쪽으로 영어로 의사소통하는 대규모 내부 동영상 저장소에서 MENTOR 데이터셋을 선별하였다. 동영상에는 24fps의 240프레임(10초 클립)이 포함되어 있으며 오디오는 16kHz이다.
인간과 소통하는 전신 모델링을 목표로 3차원 신체 관절과 손을 추정하고, projection 오차와 연속 프레임 간의 시간적 차이를 최소화하여 3차원 신체 모델을 피팅한다. 배경이 의미 있게 변하거나, 얼굴이나 몸이 부분적으로만 감지되었거나, 추정이 불안정하거나, 손이 완전히 감지되지 않거나 오디오 품질이 낮은 동영상을 필터링되었다. 이 프로세스를 통해 2200 시간이 넘고 80만 명으로 구성된 학습 세트와 120시간의 길이와 약 4천 명으로 구성된 테스트셋이 생성되어 사람의 수와 길이 측면에서 현재까지 사용된 데이터셋 중 가장 큰 고해상도 데이터셋이 되었다. 또한 MENTOR 데이터셋에는 다양한 피사체(ex. 피부색, 나이), 시점, 신체 가시성이 포함되어 있다.
Experiments
1. Ablation Study
다음은 VLOGGER의 주요 디자인 선택에 대한 ablation study 결과이다.
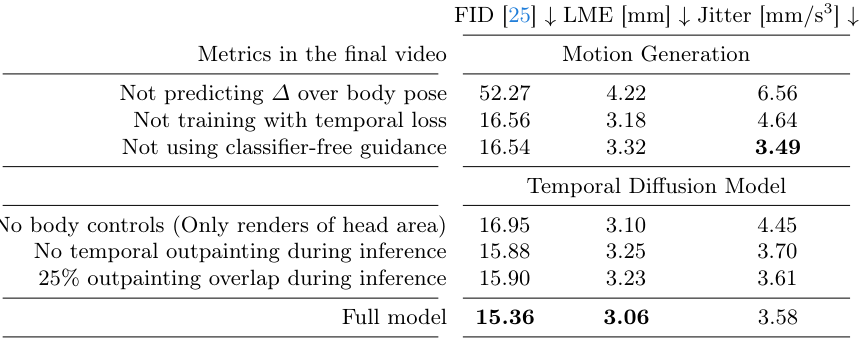
다음은 동영상 생성에서의 2D 제어 표현에 대한 ablation study 결과이다.

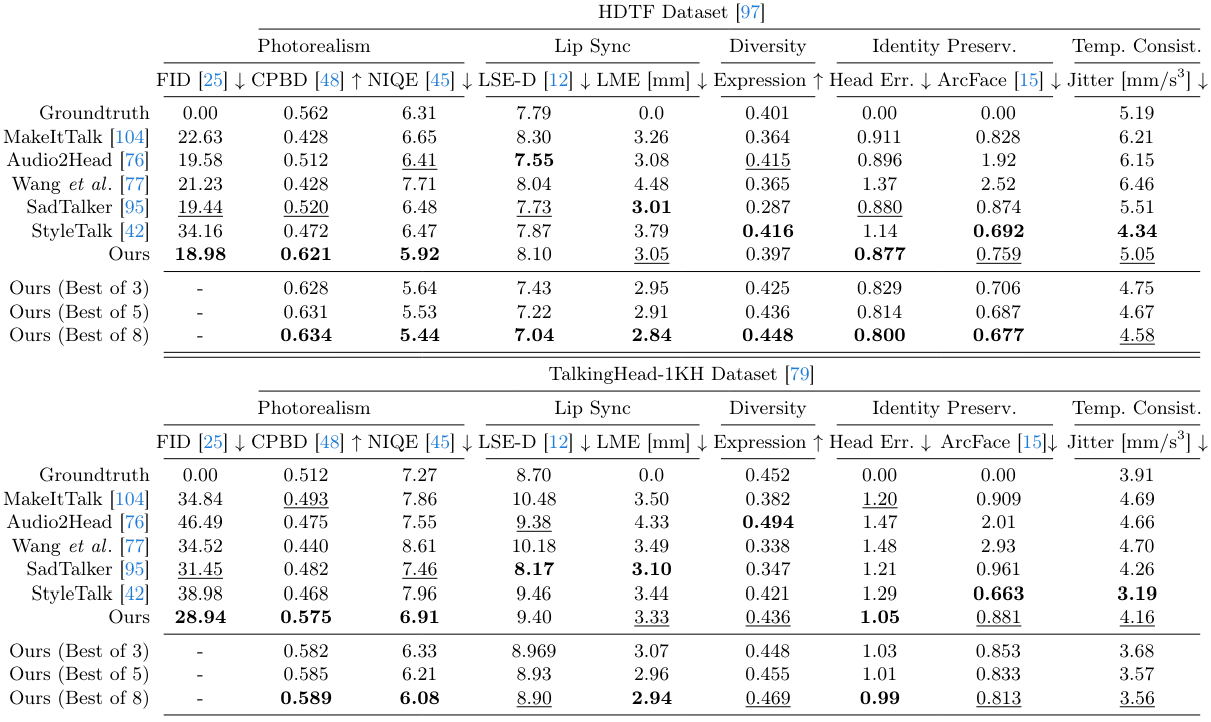
2. Quantitative Results
다음은 HDTF와 TalkingHead-1KH 데이터셋에서의 정량적 평가 결과이다.
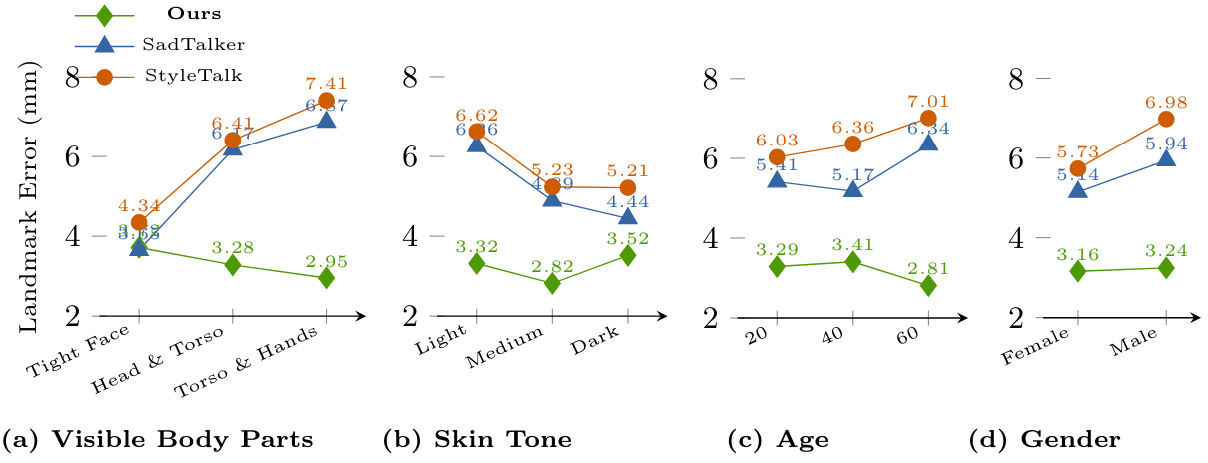
다음은 다른 방법들과 피부색, 성별, 나이 등의 속성에 대한 랜드마크 오차를 비교한 그래프이다. (MENTOR의 테스트셋)
3. Qualitative Results
다음은 다른 방법들과 정성적으로 비교한 결과이다.

VLOGGER는 stochastic하며 동일한 피사체에 대해 다양한 동영상을 생성할 수 있다. 다은은 대상 이미지와 입력 음성이 주어졌을 때 생성된 24개의 동영상에서 얻은 1~4초 후의 픽셀 색상 편차이다.
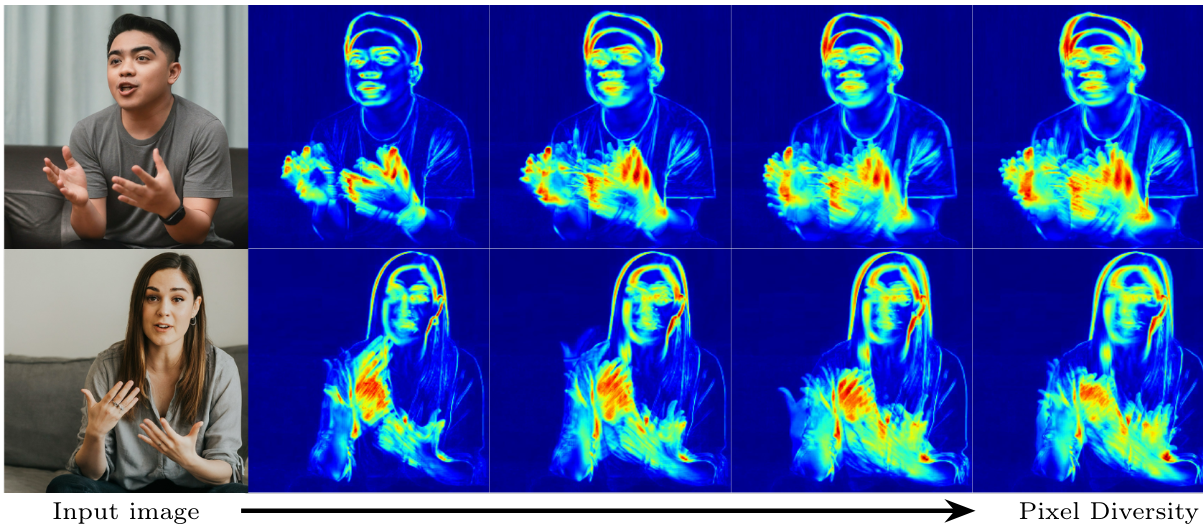
단 1초 후에 모델은 이미 손 포즈와 표정에서 매우 다양한 모습을 보여준다.
다음은 다양한 동영상 편집 결과들이다.

피사체의 동영상에서 더 많은 데이터를 사용하여 diffusion model을 finetuning하여 모델을 개인화한 결과이다.
