[논문리뷰] ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
NeurIPS 2021. [Paper] [Github]
Yufei Xu, Qiming Zhang, Jing Zhang, Dacheng Tao
The University of Sydney | JD Explore Academy
7 Jun 2021
Introduction
Transformer는 self-attention 메커니즘에 의한 장거리 의존성을 모델링하는 강력한 능력으로 인해 NLP 연구에서 지배적인 경향을 보여왔다. 이러한 transformer의 성공과 좋은 특성은 이를 다양한 컴퓨터 비전 task에 적용한 많은 연구에 영감을 주었다. 그 중 ViT는 일련의 시각적 토큰에 이미지를 포함하고 누적된 transformer 블록으로 그들 사이의 글로벌 의존성을 모델링하는 순수 transformer 모델이다. ViT는 이미지 분류에서 유망한 성능을 달성하지만 대규모 학습 데이터와 더 긴 학습 일정이 필요하다. 한 가지 중요한 이유는 ViT가 로컬 시각적 구조 (ex. 가장자리, 모서리)를 모델링하고 convolution과 같은 다양한 규모의 객체를 처리할 때 고유한 inductive bias가 부족하기 때문이다. 또는 ViT는 대규모 데이터에서 이러한 inductive bias를 암묵적으로 학습해야 한다.
ViT와 달리 CNN은 스케일 불변성과 locality의 본질적인 inductive bias를 갖추고 있으며 여전히 비전 task에서 널리 사용되는 backbone 역할을 한다. CNN의 성공은 ViT에서 본질적인 inductive bias를 탐구하도록 영감을 준다. 위의 두 가지 CNN inductive bias, 즉 locality와 스케일 불변성을 분석하는 것으로 시작한다. 인접 픽셀 간의 로컬 상관관계를 계산하는 convolution은 로컬 feature를 추출하는 데 적합하다. 결과적으로 CNN은 얕은 레이어에서 많은 하위 레벨 feature를 제공할 수 있으며, 그런 다음 대량의 순차적 convolution에 의해 점진적으로 상위 레벨 feature로 집계된다. 또한 CNN은 여러 레이어에서 멀티스케일 feature를 추출하기 위한 계층 구조를 가지고 있다. 게다가, 레이어 내 convolution 컨볼루션은 커널 크기와 dilation rate를 변경하여 다양한 스케일의 feature를 학습할 수 있다. 결과적으로 스케일 불변 feature 표현은 레이어 내 또는 레이어 간 feature 융합을 통해 얻을 수 있다. 그럼에도 불구하고 CNN은 transformer의 주요 이점인 장거리 의존성을 모델링하는 데 적합하지 않다. 여기서 흥미로운 질문이 생긴다.
CNN의 좋은 특성을 활용하여 ViT를 개선할 수 있는가?
DeiT는 학습을 용이하게 하고 성능을 향상시키기 위해 CNN에서 transformer로 지식을 증류하는 아이디어를 탐구하였다. 그러나 teacher로 CNN 모델이 필요하고 추가 학습 비용이 필요하다.
DeiT와 달리 본 논문에서는 네트워크 구조를 재설계하여 고유한 inductive bias를 ViT에 명시적으로 도입한다. 현재 ViT는 항상 단일 스케일 컨텍스트로 토큰을 얻고 데이터에서 다양한 스케일의 객체에 적응하는 방법을 학습한다. 스케일 분산을 처리하는 CNN의 성공에 힘입어 본 논문은 transformer에서 유사한 디자인, 즉 다양한 receptive field가 있는 레이어 내 convolution을 탐색하여 멀티스케일 컨텍스트를 토큰에 포함한다. 이러한 디자인을 통해 토큰은 다양한 스케일에서 객체의 유용한 feature를 전달할 수 있으므로 자연스럽게 본질적인 스케일 불변성 inductive bias를 가지며 명시적으로 transformer가 스케일 불변 feature를 데이터에서 보다 효율적으로 학습할 수 있다.
반면에 하위 레벨의 로컬 feature은 상위 레벨의 판별적인 feature을 생성하는 기본 요소이다. Transformer는 데이터의 얕은 레이어에서 이러한 feature를 학습할 수도 있지만 디자인상 convolution에 익숙하지 않다. 최근에는 convolution과 attention 레이어를 순차적으로 쌓고 locality가 글로벌 의존성에 대한 합당한 보상임을 보여주었다. 그러나 이 직렬 구조는 로컬 모델링 중 글로벌 컨텍스트를 무시한다 (반대의 경우도 마찬가지). 이러한 딜레마를 피하기 위해 본 논문은 “분할 정복” 아이디어를 따르고 loclaity와 장거리 의존성을 병렬로 모델링한 다음 feature를 융합하여 둘 다 설명할 것을 제안한다. 이러한 방식으로 transformer가 각 블록 내에서 로컬 및 장거리 feature를 보다 효과적으로 학습할 수 있도록 한다.
본 논문은 두 가지 유형의 기본 셀, 즉 reduction cell (RC)과 normal cell (NC)의 조합인 새로운 Vision Transformers Advanced by Exploring Intrinsic Inductive Bias (ViTAE)를 제안한다. RC는 입력 이미지를 다운샘플링하고 풍부한 멀티스케일 컨텍스트가 있는 토큰에 포함하는 데 사용되는 반면 NC는 토큰 시퀀스에서 loclaity와 글로벌 의존성을 공동으로 모델링하는 것을 목표로 한다. 또한, 이 두 가지 유형의 셀은 단순한 기본 구조, 즉 피드포워드 네트워크 (FFN)가 뒤따르는 병렬 attention 모듈과 convolution layer를 공유한다. RC에는 멀티스케일 컨텍스트를 토큰에 포함시키기 위해 서로 다른 dilation rate의 dialted convolution이 있는 pyramid reduction module이 추가로 있다. 3개의 RC를 쌓아 공간 해상도를 1/16로 줄이고 데이터에서 일련의 NC를 판별적 feature로 학습한다. ViTAE는 데이터 효율성 및 학습 효율성은 물론 다운스트림 task에 대한 분류 정확도와 일반화 측면에서 ViT를 능가한다.
Methodology
1. Overview architecture of ViTAE
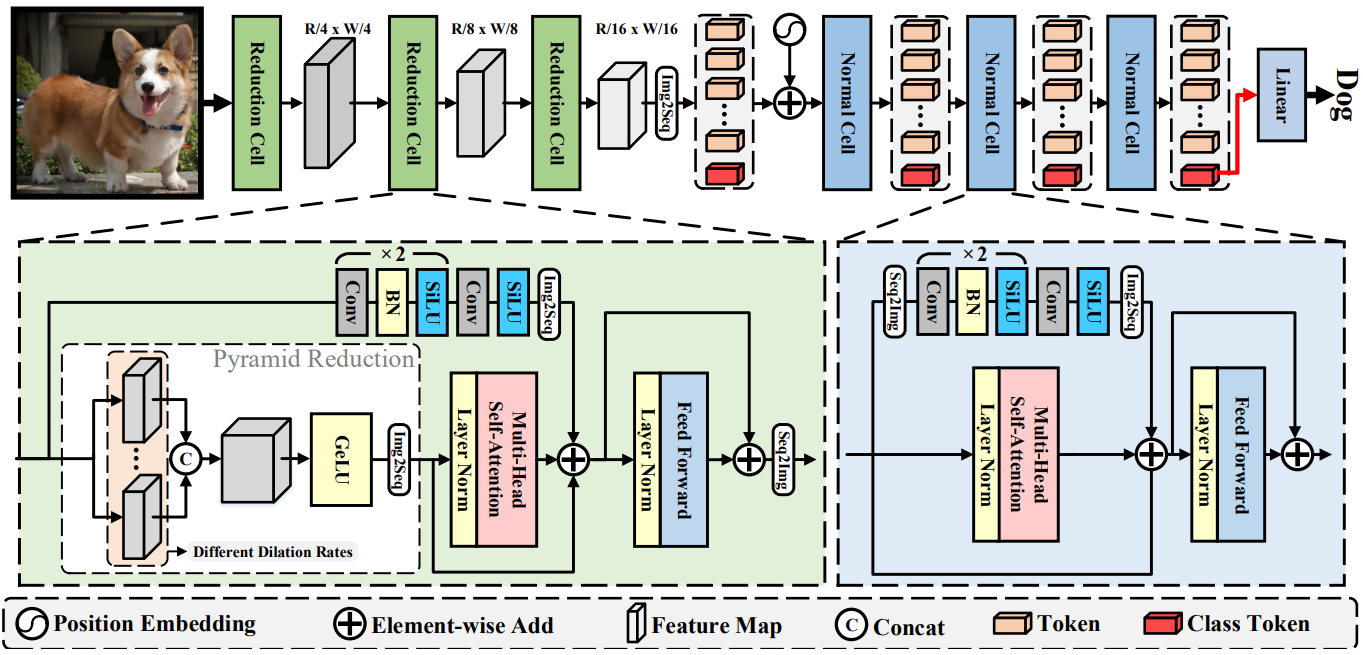
ViTAE는 CNN의 고유 inductive bias를 ViT에 도입하는 것을 목표로 한다. 위 그림과 같이 ViTAE는 RC와 NC의 두 가지 유형의 셀로 구성된다. RC는 멀티스케일 컨텍스트와 로컬 정보를 토큰에 포함시키는 역할을 하며 NC는 토큰의 locality와 장거리 의존성을 추가로 모델링하는 데 사용된다. 이미지 $x \in \mathbb{R}^{H \times W \times C}$가 입력으로 주어지면 3개의 RC를 사용하여 $x$를 각각 $4 \times$, $2 \times$, $2 \times$씩 점진적으로 다운샘플링한다. 따라서 RC의 출력 토큰은 크기가 $[H/16, W/16, D]$이며, $D$는 토큰 차원이다. 그런 다음 RC의 출력 토큰은 $\mathbb{R}^{HW/256 \times D}$로 flatten되고 클래스 토큰과 concat되며 sinusoid position encoding이 추가된다. 토큰은 토큰 길이를 유지하면서 다음 NC에 공급된다. 마지막으로 마지막 NC의 클래스 토큰에 대해 linear classification layer를 사용하여 예측 확률을 얻는다.
2. Reduction cell
선형 이미지 패치 임베딩 레이어를 기반으로 이미지를 시각적 토큰으로 직접 분할하고 flatten하는 대신 멀티스케일 컨텍스트와 로컬 정보를 시각적 토큰에 임베딩하기 위해 reduction cell (RC)을 고안하여 convolution에서 고유한 스케일 불변성과 locality inductive bias를 도입한다. 기술적으로 RC에는 각각 locality와 장거리 의존성을 모델링하는 두 개의 병렬 분기가 있고 그 뒤에 feature 변환을 위한 FFN이 있다. $i$번째 RC의 입력 feature를 $f_i \in \mathbb{R}^{H_i \times W_i \times D_i}$로 표시한다. 첫 번째 RC의 입력은 이미지 $x$이다. 글로벌 의존성 분기에서 $f_i$는 먼저 Pyramid Reduction Module (PRM)에 공급되어 멀티스케일 컨텍스트를 추출한다.
\[\begin{equation} f_i^\textrm{ms} = \textrm{PRM}_i (f_i) = \textrm{Cat} ([\textrm{Conv}_{ij} (f_i; s_{ij}, r_i) \vert s_{ij} \in \mathcal{S}_i, r_i \in \mathcal{R}]) \end{equation}\]여기서 \(\textrm{Conv}_{ij} (\cdot)\)는 PRM (\(\textrm{PRM}_i (\cdot)\))의 $j$번째 convolution layer를 나타낸다. $i$번째 RC에 해당하는 미리 정의된 dilation rate 집합 \(\mathcal{S}_i\)에서 dilation rate $s_{ij}$를 사용한다. Stride convolution을 사용하여 미리 정의된 reduction ratio 집합 $\mathcal{R}$에서 $r_i$로 feature의 공간 차원을 줄인다. Conv feature는 채널 차원을 따라 concat된다.
\[\begin{equation} f_i^\textrm{ms} \in \mathbb{R}^{(W_i / p) \times (H_i / p) \times ( \vert \mathcal{S}_i \vert D)} \end{equation}\]여기서 \(\vert \mathcal{S}_i \vert\)는 \(\mathcal{S}_i\)의 dilation rate 수를 나타낸다. $f_i^\textrm{ms}$는 장거리 의존성을 모델링하기 위해 MHSA 모듈에 의해 처리된다.
\[\begin{equation} f_i^g = \textrm{MHSA}_i (\textrm{Img2Seq} (f_i^\textrm{ms})) \end{equation}\]여기서 \(\textrm{Img2Seq} (\cdot)\)는 feature map을 1D 시퀀스로 flatten하는 단순한 reshape 연산이다. 이러한 방식으로 $f_i^g$는 각 토큰에 멀티스케일 컨텍스트를 포함한다. 또한 Parallel Convolutional Module (PCM)을 사용하여 다음과 같이 $f_i^g$와 융합된 토큰 내에 로컬 컨텍스트를 포함한다.
\[\begin{equation} f_i^{lg} = f_i^g + \textrm{PCM}_i (f_i) \end{equation}\]여기서 \(\textrm{PCM}_i (\cdot)\)은 PCM을 나타내며 3개의 convolution layer와 \(\textrm{Img2Seq} (\cdot)\) 연산으로 구성된다. 병렬 convolution 분기는 stride convolution을 사용하여 PRM과 동일한 공간적 다운샘플링 비율을 갖는다는 점에 주목할 필요가 있다. 이러한 방식으로 토큰 feature는 로컬 및 멀티스케일 컨텍스트를 모두 전달할 수 있으므로 RC가 디자인에 따라 locality inductive bias와 스케일 불변성 inductive bias를 획득함을 의미한다. 그런 다음 융합된 토큰은 FFN에 의해 처리되고 feature map으로 다시 형성되며 다음 RC 또는 NC에 공급된다.
\[\begin{equation} f_{i+1} = \textrm{Seq2Img} (\textrm{FFN}_i (f_i^{lg}) + f_i^{lg}) \end{equation}\]여기서 \(\textrm{Seq2Img} (\cdot)\)는 토큰 시퀀스를 feature map으로 다시 형성하는 간단한 재구성 task이다. \(\textrm{FFN}_i (\cdot)\)는 $i$번째 RC의 FFN을 나타낸다. ViTAE에서는 3개의 RC가 순차적으로 쌓여 입력 이미지의 공간 차원을 각각 $4 \times$, $2 \times$, $2 \times$씩 점진적으로 줄인다. 마지막 RC에 의해 생성된 feature map은 크기가 $[H/16 \times W/16 \times D]$이며 시각적 토큰으로 flatten되어 다음 NC에 공급된다.
3. Normal cell
NC는 PRM이 없다는 점을 제외하면 RC와 유사한 구조를 공유한다. RC 이후 feature map의 상대적으로 작은 공간 크기 ($\frac{1}{16} \times$)로 인해 NC에서 PRM을 사용할 필요가 없다. 세 번째 RC에서 $f_3$이 주어지면 먼저 이를 클래스 토큰 $t_\textrm{cls}$와 concat한 다음 위치 인코딩에 추가하여 다음 NC에 대한 입력 토큰 $t$를 얻는다. 여기서는 모든 NC가 동일한 아키텍처를 갖지만 학습 가능한 가중치가 다르기 때문에 명확성을 위해 아래 첨자를 무시한다. $t_\textrm{cls}$는 학습 시작 시 랜덤으로 초기화되고 inference 중에 고정된다. RC와 마찬가지로 토큰은 MHSA 모듈에 공급된다.
\[\begin{equation} t_g = \textrm{MHSA} (t) \end{equation}\]한편, 이들은 2D feature map으로 재구성되어 PCM에 공급된다.
\[\begin{equation} t_l = \textrm{Img2Seq} (\textrm{PCM} (\textrm{Seq2Img}(t))) \end{equation}\]클래스 토큰은 다른 시각적 토큰과의 공간적 연결이 없기 때문에 PCM에서 버려진다. NC의 파라미터를 더 줄이기 위해 PCM에서 group convolution을 사용한다. 그런 다음 MHSA와 PCM의 feature이 element-wise sum을 통해 융합된다.
\[\begin{equation} t_{lg} = t_g + t_l \end{equation}\]마지막으로 $t_{lg}$는 FFN에 입력되어 NC의 출력 feature를 얻는다.
\[\begin{equation} t_{nc} = FFN(t_{lg}) + t_{lg} \end{equation}\]ViT와 유사하게 마지막 NC에서 생성된 클래스 토큰에 layer normalization을 적용하고 classification head에 공급하여 최종 분류 결과를 얻는다.
4. Model details

유사한 모델 크기를 가진 다른 모델과의 공정한 비교를 위해 실험에서 ViTAE의 두 가지 변형을 사용한다. 자세한 내용은 위 표에 요약되어 있다.
Experiments
- 데이터셋: ImageNet
- 구현 디테일
- 이미지 크기: 224$\times$224
- Optimizer: AdamW
- Learning rate: 초기값 $5 \times 10^{-4}$, cosine schedule 사용
- T2T와 동일한 data augmentation 전략 사용
- Batch size: 512
1. Comparison with the state-of-the-art
다음은 ImageNet validation set에서 SOTA 방법들과 비교한 표이다.

2. Ablation study
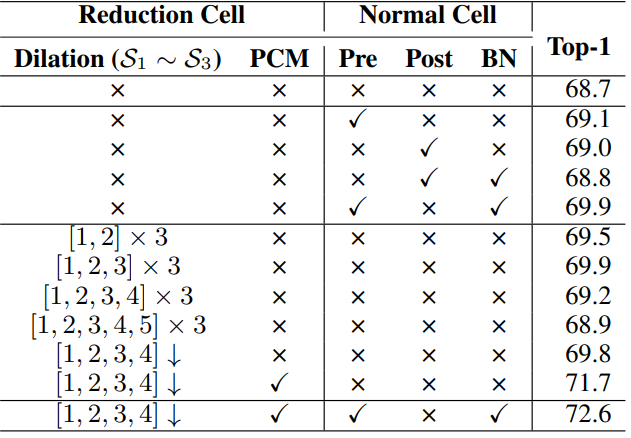
다음은 RC와 NC에 대한 ablation study 결과이다.
3. Data efficiency and training efficiency
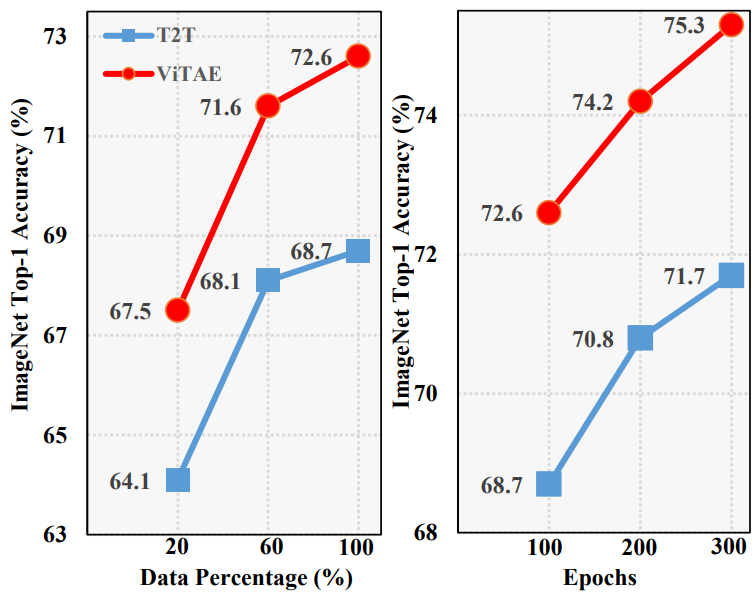
다음은 ImageNet에서 T2T-ViT-7와 ViTAE-T의 데이터와 학습 효율성을 나타낸 그래프이다.
다음은 CIFAR10과 CIFAR100에서의 학습 결과이다.

4. Generalization on downstream tasks
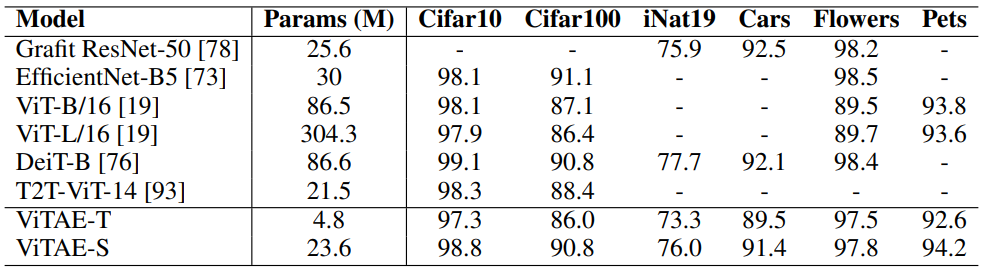
다음은 다양한 다운스트림 task에서의 일반화를 비교한 표이다.
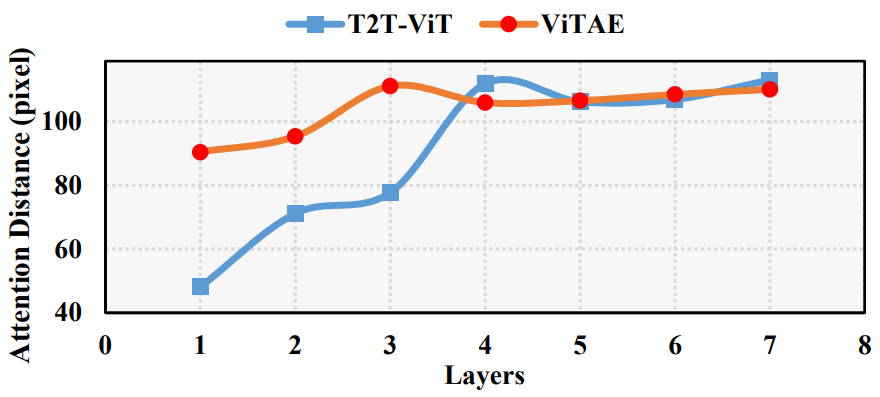
5. Visual inspection of ViTAE
다음은 ViTAE-T와 T2T-ViT-7의 레이어별 평균 attention 거리이다.
다음은 ViTAE와 T2T-ViT의 Grad-CAM을 비교한 것이다.
