[논문리뷰] ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
arXiv 2023. [Paper] [Page]
Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao
Zhejiang University | AntGroup
22 May 2023
Introduction
TTS는 특히 DDPM의 등장으로 성능이 크게 향상되었다. 그러나 오디오의 지각 품질은 콘텐츠, 피치, 리듬, 에너지뿐만 아니라 물리적 환경에 따라 달라진다. 예를 들어 콘크리트나 유리와 같은 단단한 표면이 있는 방은 음파를 반사하는 반면 카펫이나 커튼과 같은 부드러운 표면이 있는 방은 음파를 흡수한다. 이러한 차이는 우리가 듣는 소리의 선명도와 품질에 큰 영향을 미칠 수 있다.
실감나고 매력적인 경험을 보장하려면 특히 가상 현실(VR)과 증강 현실(AR) 애플리케이션에서 방의 음향을 정확하게 모델링하는 것이 필수적이다. Visual TTS는 기록 영화 더빙, 가상 현실, 증강 현실에서 더욱 실감나고 사실적인 경험 제공을 제공하고 게임에 적절한 음향 효과를 추가하는 등 수많은 실용적인 애플리케이션을 가능하게 한다.
최근 몇 년 동안 언어-비전 모델링 문제를 다루는 중요한 연구가 급증했다. 언어-비전 접근 방식의 이점에도 불구하고 visual-TTS 모델을 학습하려면 일반적으로 많은 양의 학습 데이터가 필요한 반면, 과도한 작업 부하로 인해 병렬 텍스트-비전-오디오 데이터를 제공하는 리소스는 거의 없다. 게다가 AR/VR 애플리케이션을 개발할 때 시각적 콘텐츠와 일치하는 사운드 경험을 만드는 것은 이미지의 다양한 영역이 잔향에 어떻게 기여하는지, 그리고 TTS에서 시각적 modality를 보조 정보로 통합하는 방법이 여전히 불분명하기 때문에 여전히 어려운 일이다.
본 논문에서는 텍스트와 환경 이미지가 주어진 타겟 시나리오에서 잔향 효과가 있는 오디오를 생성하는 ViT-TTS를 도입하여 데이터 부족 및 실내 음향 모델링 문제를 해결한다. 시각-음향 매칭을 향상시키기 위해 저자들은 2가지 방법을 사용하였다.
- Visual-text fusion: 이미지의 영역에 주의를 기울여 세밀한 언어-비전 추론을 제공하고 시각 정보와 텍스트 정보를 통합
- Transformer 아키텍처를 활용하여 diffusion model의 확장성을 촉진
데이터 부족 문제와 관련하여 self-supervised 방식으로 인코더와 디코더를 사전 학습하여 대규모 사전 학습이 Visual TTS 모델 학습을 위한 데이터 요구 사항을 줄인다.
ViT-TTS는 타겟 시나리오에서 정확한 반향 효과로 음성 샘플을 생성하여 지각 품질 측면에서 새로운 SOTA 결과를 달성하였다. 또한 저자들은 저자원 조건 (1h/2h/5h)에서 ViT-TTS의 확장성과 성능을 조사하였다.
Method
1. Overview
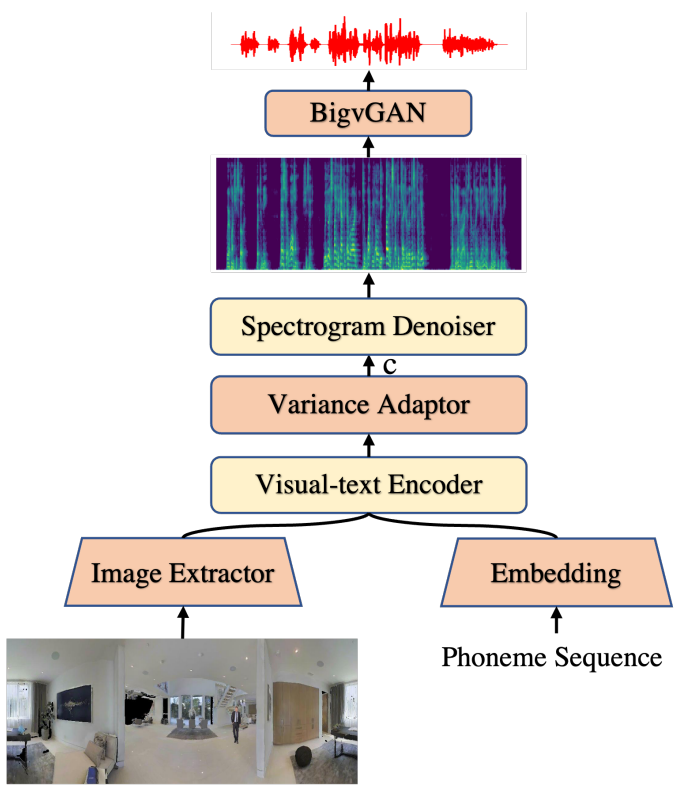
전체 아키텍처는 위 그림과 같다. 데이터 희소성 문제를 완화하기 위해 레이블이 지정되지 않은 데이터를 활용하여 self-supervised 방식으로 scalable transformer를 사용하여 시각적 텍스트 인코더와 denoiser 디코더를 사전 학습한다. 시각적 장면 정보를 캡처하기 위해 visual-text fusion 모듈을 사용하여 다양한 이미지 패치가 텍스트에 기여하는 방식을 추론한다. BigvGAN은 mel-spectrogram을 neural vocoder로 타겟 장면과 일치하는 오디오로 변환한다.
2. Enhanced visual-text Encoder
Self-supervised Pre-training
Masked language model (MLM)의 출현은 자연어 처리 분야에서 중요한 이정표를 세웠다. 데이터 부족 문제를 완화하고 강력한 상황별 인코더를 학습하기 위해 사전 학습 단계에서 BERT와 같은 마스킹 전략을 채택하는 것이 좋다. 특히 각 음소 시퀀스의 15%를 무작위로 마스킹하고 전체 입력을 재구성하는 대신 마스킹된 토큰을 예측한다. 마스킹된 음소 시퀀스는 hidden state를 얻기 위해 텍스트 인코더에 입력된다. 최종 hidden state는 예측된 토큰을 얻기 위해 vocabulary에 대한 linear projection layer로 공급된다. 마지막으로 예측 토큰과 타겟 토큰 간의 cross entropy loss를 계산한다.
사전 학습 단계에서 마스킹된 토큰은 fine-tuning 단계에서 사용되지 않는다. 사전 학습과 fine-tuning 간의 이러한 불일치를 완화하기 위해 마스킹할 음소를 무작위로 선택한다.
- 80% 확률로 마스크를 추가
- 10% 확률로 음소를 변경하지 않고 유지
- 10% 확률로 사전에서 임의의 토큰으로 대체로
Visual-Text Fusion
Fine-tuning 단계에서는 시각적 모달과 모듈을 인코더에 통합하여 시각적 정보와 텍스트 정보를 통합한다. 시각적 텍스트 인코더에 입력하기 전에 먼저 ResNet18을 통해 파노라마 이미지의 이미지 feature를 추출하고 음소 임베딩을 얻는다. Hidden 시퀀스를 얻기 위해 이미지 feature와 음소 임베딩이 transformer의 변형에 입력된다. 구체적으로, 먼저 다음과 같이 정의되는 relative self-attention를 통해 음소를 전달한다.
\[\begin{equation} \alpha (i, j) = \textrm{Softmax} (\frac{(Q_i W^Q) (K_j W^K + R_{ij}^K)^\top}{\sqrt{d_k}}) \end{equation}\]여기서 $n$은 음소 임베딩의 길이이고, $R_{ij}^K$와 $R_{ij}^V$는 key와 value의 상대적 위치 임베딩이며, $Q$, $K$, $V$는 모두 음소 임베딩이다. 음소 $p_i$가 음소 $p_j$에 얼마나 많은 영향을 미치는지 모델링하기 위해 relative self-attention을 사용한다. 그런 다음 feature 추출 후 서로 다른 이미지 패치가 텍스트에 기여하는 방식을 추론할 수 있으므로 단순한 concatenation 방식 대신 cross-attention을 사용한다.
\[\begin{equation} \alpha (Q, K, V) = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d_k}}) V \end{equation}\]여기서 $Q$는 음소 임베딩이고 $K$와 $V$는 시각적 feature이다. 마지막으로, hidden 시퀀스를 출력하기 위해 feed-forward layer가 적용된다.
3. Enhanced Diffusion Transformer
Scalable Transformer
DDPM은 이미지와 오디오 합성 모두에서 최고의 결과를 제공하는 탁월한 능력을 입증했다. 그러나 가장 지배적인 diffusion TTS 모델은 WaveNet 또는 U-Net과 같은 convolution 아키텍처를 backbone의 사실상의 선택으로 채택하여 추가 시각적 정보를 모델링하는 확장성이 부족하기 때문에 모델의 시각적 정보 통합을 방지한다. 이미지 합성 분야의 최근 연구에 따르면 convolution 구조의 inductive bias가 DDPM 성능의 중요한 결정 요인이 아니라는 것이 밝혀졌다. 대신 transformer가 실행 가능한 대안으로 등장했다.
이러한 이유로 저자들은 transformer의 확장성을 활용하여 모델 용량을 확장하고 실내 음향 정보를 통합하는 diffusion transformer를 제안한다. 또한 GAN의 adaptive normalization layer를 활용하고 전체 transformer 블록을 항등 함수로 초기화하여 transformer 성능을 더욱 향상시킨다.
Unconditional Pre-training
저자들을 데이터 희소성을 완화하기 위해 수십 배의 mel-spectrograms 데이터에서 self-supervised learning을 조사하였다. 구체적으로 타겟 mel-spectrogram이 $x_0$라고 가정하고 먼저 시작 인덱스로 $x_0$의 0.065%를 무작위로 선택하고 Wav2vec2.0을 따라 10단계에 걸쳐 마스크를 적용한다. 그런 다음 데이터 $x_0$에서 latent 변수 $x_t$까지 고정 Markov chain으로 정의되는 diffusion process를 통해 $x_t$를 얻는다.
\[\begin{equation} q(x_1, \cdots, x_T) = \prod_{t=1}^T q(x_t \vert x_{t-1}) \end{equation}\]각 diffusion step $t \in [1, T]$에 대하여 작은 양의 상수 $\beta_t$에 따라 매우 작은 Gaussian noise가 $x_{t-1}$에 더해져 $x_t$를 얻는다.
\[\begin{equation} q(x_t \vert x_{t-1}) := \mathcal{N} (x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \end{equation}\]Diffusion process에서 얻은 $x_t$는 Gaussian noise $\epsilon_\theta$를 예측하기 위해 transformer를 통과시킨다. Loss는 $\epsilon$-space의 평균 제곱 오차로 정의되며 효율적인 학습은 SGD로 $t$의 랜덤 항을 최적화하는 것이다.
\[\begin{equation} \mathcal{L}_\theta^\textrm{Grad} = \bigg\| \epsilon_\theta \bigg( \alpha_t x_0 + \sqrt{1 - \alpha_t^2} \epsilon \bigg) - \epsilon \bigg\|_2^2, \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]이를 위해 ViT-TTS는 reconstruction loss를 활용하여 데이터 부족 문제를 크게 완화하는 self-supervised 표현을 예측한다.
Controllable Fine-tuning
Fine-tuning 단계에서 다음과 같은 문제에 직면하게 된다.
- 학습을 위해 사용 가능한 파노라마 이미지와 타겟 환경 오디오에 데이터 부족 문제가 있다.
- 빠른 학습 방법은 상당한 시간과 저장 공간을 절약할 수 있으므로 diffusion model을 최적화하는 데에도 똑같이 중요하다.
이러한 문제를 저자들은 해결하기 위해 신속한 fine-tuning 기술을 구현하였다. 특히 입력 조건을 학습하기 위해 사전 학습된 diffusion model 가중치의 두 복사본, 즉 “학습 가능한 복사본”과 “잠긴 복사본”을 만든다. $\Theta$로 지정된 사전 학습된 transformer의 모든 파라미터를 수정하고 학습 가능한 파라미터 $\Theta_t$로 복제한다. 이러한 학습 가능한 파라미터를 학습시키고 zero convolution layer를 통해 “잠긴 복사본”과 연결한다. 이러한 convolution layer는 커널 크기가 하나씩 있고 가중치와 바이어스가 0으로 설정되어 0에서 최적화된 파라미터로 점진적으로 학습되므로 고유하다.
4. Architecture
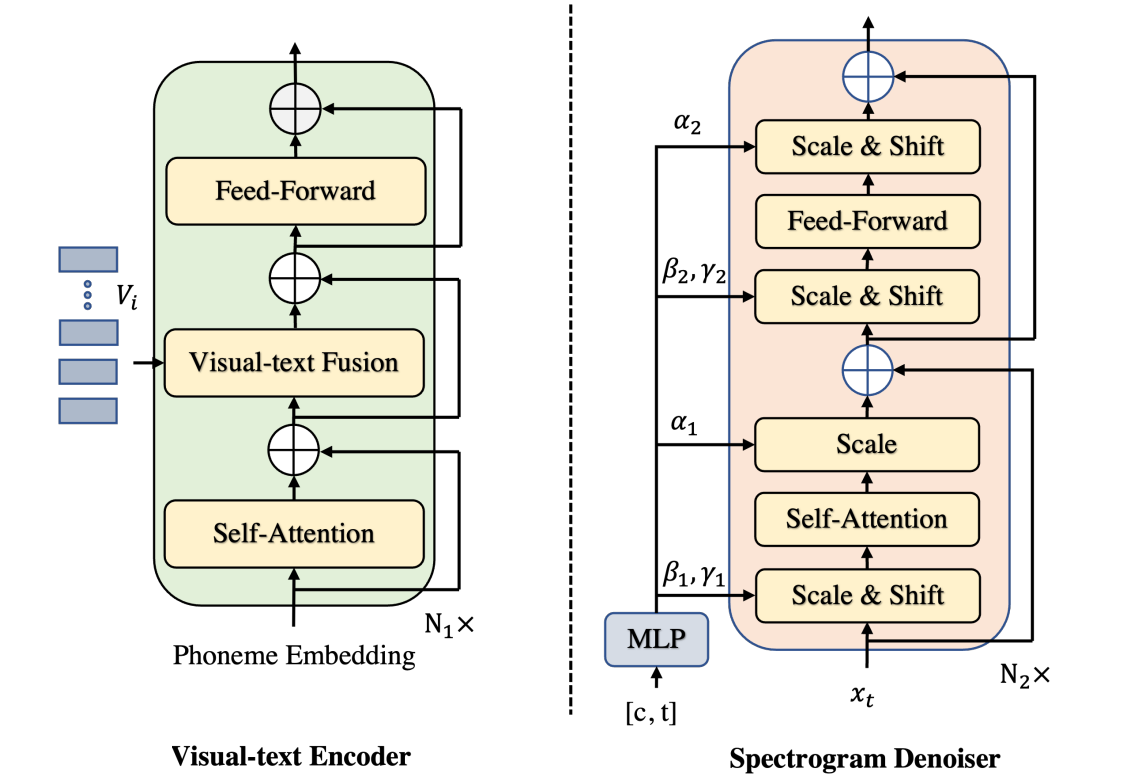
모델은 visual-text encoder, variance adaptor, spectrogram denoiser로 구성된다. Visual-text encoder는 음소 임베딩과 시각적 feature를 hidden 시퀀스로 변환한다. Variance adaptor는 각 hidden 시퀀스의 duration을 예측하여 hidden 시퀀스의 길이를 음성 프레임의 길이와 일치하도록 조절한다. 또한 피치 임베딩과 스피커 임베딩과 같은 다양한 변형이 hidden 시퀀스와 통합된다. 마지막으로 spectrogram denoiser는 길이가 조절된 hidden state를 mel-spectrogram으로 반복적으로 정제한다.
Visual-Text Encoder는 transformer 아키텍처를 기반으로 하는 relative position transformer block으로 구성된다. 구체적으로 다음과 같이 구성된다.
- 음소 임베딩을 위한 pre-net
- 이미지를 위한 시각적 feature 추출기
- multi-head self-attention, multi-head cross-attention, feed-forward layer를 포함하는 trasnformer 인코더
Variance Adaptor는 duration과 피치 predictor는 ReLU가 포함된 2-layer 1D convolution network로 구성된 유사한 모델 구조를 공유하며, 각 레이어에는 layer normalization과 dropout layer가 뒤따르고 hidden state를 출력 시퀀스에 projcet하기 위한 추가 linear layer가 있다.
Spectrogram Denoiser는 step 임베딩 $E_t$와 인코더 출력로 컨디셔닝된 diffusion process에서 추가된 $\epsilon$을 예측하기 위해 $x_t$를 입력으로 사용한다. Transformer의 변형을 backbone으로 채택하고 표준 transformer를 일부 개선하며 주로 다음을 포함한다.
- $t$의 임베딩 벡터와 hidden 시퀀스의 합에서 scale 및 shift 파라미터를 회귀하기 위해 transformer 블록의 표준 layer norm 레이어를 adaptive layer norm (adaLN)으로 대체
- ResNets에서 영감을 받아 transformer 블록을 항등 함수로 초기화하고 MLP가 영벡터를 출력하도록 초기화
5. Pre-training, Fine-tuning, and Inference Procedures
Pre-training
사전 학습에는 두 단계가 있다.
- 인코더 단계: 마스킹된 토큰을 예측하기 위해 masked LM loss \(\mathcal{L}_\textrm{CE}\) (즉, cross-entropy loss)를 통해 visual-text encoder를 사전 학습한다.
- 디코더 단계: Gaussian noise $\epsilon_\theta$를 예측하기 위해 마스킹된 $x_0$를 denoiser에 넣는다. 그런 다음 MSE loss를 예측된 Gaussian noise와 타겟 Gaussian noise에 적용한다.
Fine-tuning
사전 학습된 visual-text encoder와 unconditional diffusion decoder에서 모델 가중치를 로드하고 모델이 수렴할 때까지 둘 다 fine-tuning한다. 최종 loss 항은 다음 부분으로 구성된다.
- 샘플 재구성 loss \(\mathcal{L}_\theta\) 예측된 Gaussian noise와 타겟 Gaussian noise 사이의 MSE
- 분산 재구성 손실 \(\mathcal{L}_{dur}\)
- \(\mathcal{L}_p\): 음소 레벨 duration의 예측값과 타겟 사이의 MSE
Inference
Inference에서 DDPM은 데이터 샘플 $x_0$를 얻기 위해 reverse process를 반복적으로 실행한 다음 사전 학습된 BigvGAN-22khz-80band를 vocoder로 사용하여 생성된 mel-spectrogram을 파형으로 변환한다.
Experiment
- 데이터셋: SoundSpaces-Speech (샘플 수: 28,853 / 1,441 / 1,489)
- 전처리
- Spectrogram 추출: FFT size = 1024, hop size = 256, window size = 1024
- Mel-spectrogram으로 변환: 80 frequency bin
- Parselmouth로 F0 (fundamental frequency) 추출
- 모델 설정
- 음소 vocabulary: 73
- 음소 임베딩의 차원: 256
- visual-text transformer 블록의 차원: 256
- 이미지 feature 추출기: 사전 학습된 ResNet18
- 피치 인코더: lookup table 크기 = 300, 인코딩된 피치 임베딩의 크기 = 256
- Denoiser: transformer-B layer 5개 (hidden size = 384, head = 12)
- transformer 블록은 항등 함수로 초기화
- $T = 100$, $\beta_1 = 10^{-4}, \beta_T = 0.06$ (linear)
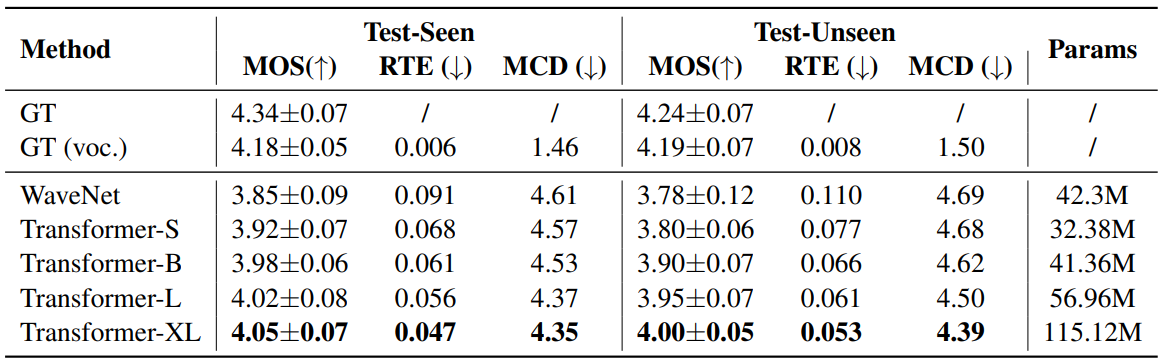
1. Scalable Diffusion Transformer
다음은 채택한 diffusion transformer의 종류에 따른 성능을 비교한 표이다.
2. Model Performances
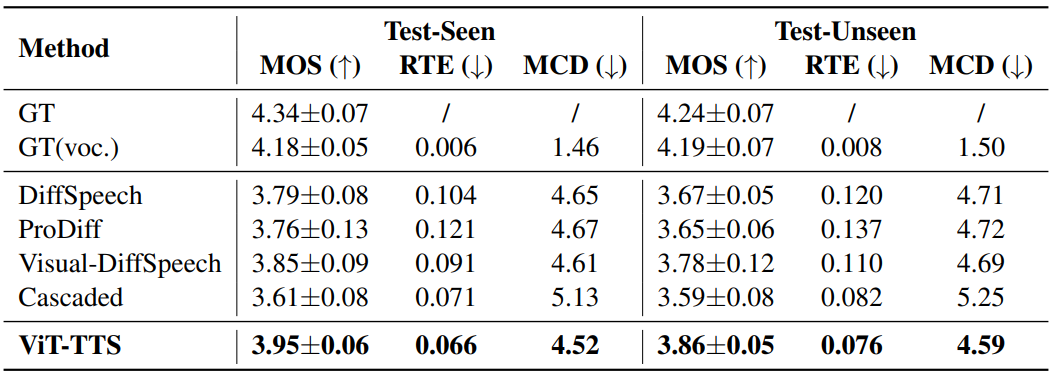
다음은 SoundSpaces-Speech에서 baseline들과 성능을 비교한 표이다.
3. Low Resource Evaluation
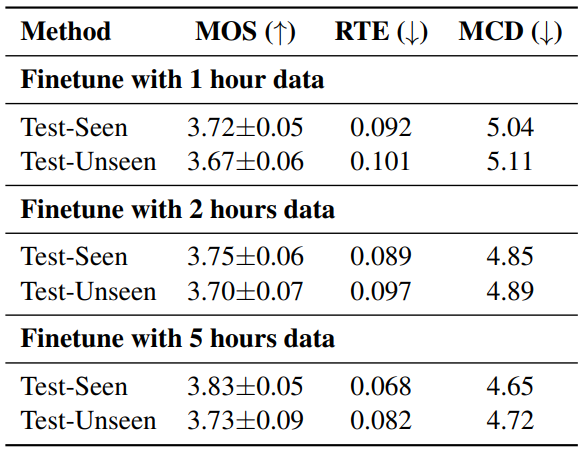
다음은 적은 리소스에서 평가한 결과이다.
4. Case Study
다음은 다양한 Visual TTS 모델이 생성한 mel-spectrogram을 ground-truth와 시각화한 것이다.

5. Ablation Studies
다음은 ablation study 결과이다.