[논문리뷰] Vision Transformer Adapter for Dense Predictions (ViT-Adapter)
ICLR 2023. [Paper] [Github]
Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, Yu Qiao
Nanjing University | Shanghai AI Laboratory | Tsinghua University
17 May 2022
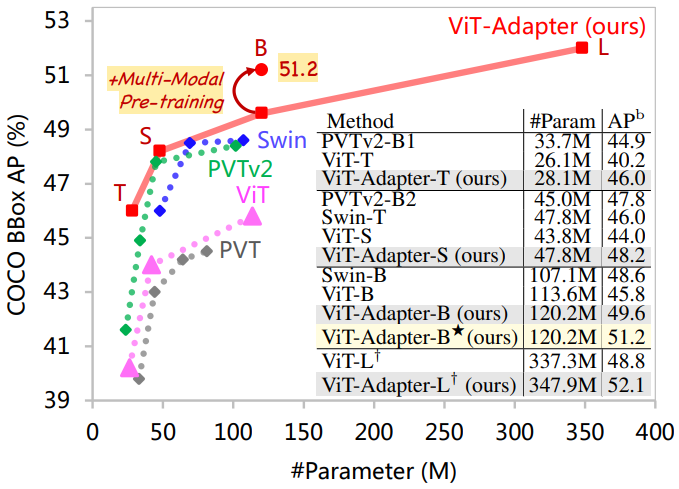
Introduction
최근 transformer는 광범위한 컴퓨터 비전 분야에서 놀라운 성공을 거두었다. 동적 모델링 능력과 attention 메커니즘의 장거리 의존성 덕분에 object detection이나 semantic segmentation과 같은 많은 컴퓨터 비전 task에서 다양한 ViT가 곧 등장하여 CNN 모델을 능가하고 SOTA 성능에 도달했다. 이러한 모델은 주로 일반 ViT와 계층적 변형이라는 두 가지 클래스로 나뉜다. 일반적으로 후자는 더 나은 결과를 생성할 수 있으며 로컬한 공간적 연산을 사용하여 비전 관련 inductive bias를 아키텍처에 도입한다.
그럼에도 불구하고 일반 ViT에는 여전히 무시할 수 없는 장점이 있다. 전형적인 예시는 멀티모달 사전 학습에 있다. 자연어 처리 (NLP) 분야에서 유래한 transformer는 입력 데이터를 가정하지 않는다. 다양한 토크나이저 (ex. 패치 임베딩, 3D 패치 임베딩, 토큰 임베딩)를 갖춘 일반 ViT는 사전 학습을 위해 이미지, 동영상, 텍스트를 포함한 대규모 멀티모달 데이터를 사용할 수 있어 모델이 풍부한 semantic 표현을 학습하도록 장려한다. 그러나 일반 ViT는 비전 전용 transformer에 비해 dense prediction에 결정적인 결함이 있다. 이미지 관련 사전 지식이 부족하면 수렴 속도가 느려지고 성능이 저하되므로 일반 ViT는 dense prediction task에서 비전 전용 transformer와 경쟁하기 어렵다. NLP 분야의 어댑터에서 영감을 받은 본 논문은 dense prediction task를 위해 일반 ViT와 비전 전용 backbone 간의 성능 격차를 줄이는 어댑터를 개발하는 것을 목표로 한다.
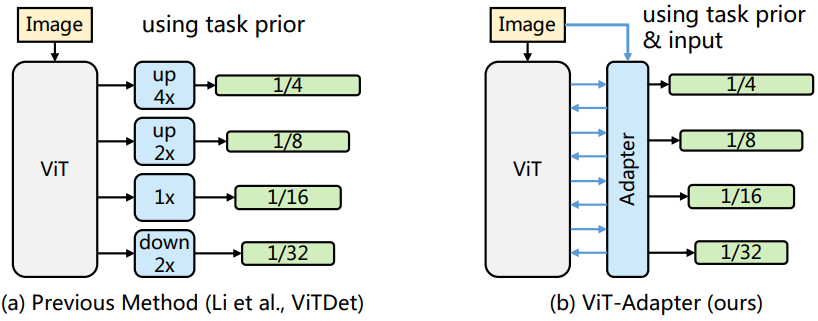
이를 위해 본 논문은 원래 아키텍처를 수정하지 않고도 일반 ViT를 다운스트림 dense prediction task에 효율적으로 적용할 수 있는 사전 학습이 필요 없는 추가 네트워크인 Vision Transformer Adapter (ViT-Adapter)를 제안한다. 특히 일반 ViT에 비전 관련 inductive bias를 도입하기 위해 ViT-Adapter를 위한 맞춤형 모듈 3개를 설계하였다.
- 입력 이미지에서 로컬 semantic (spatial prior)를 캡처하기 위한 spatial prior module
- Spatial prior를 ViT에 통합하기 위한 spatial feature injector
- Dense prediction task에 필요한 멀티스케일 feature를 재구성하기 위한 multi-scale feature extractor
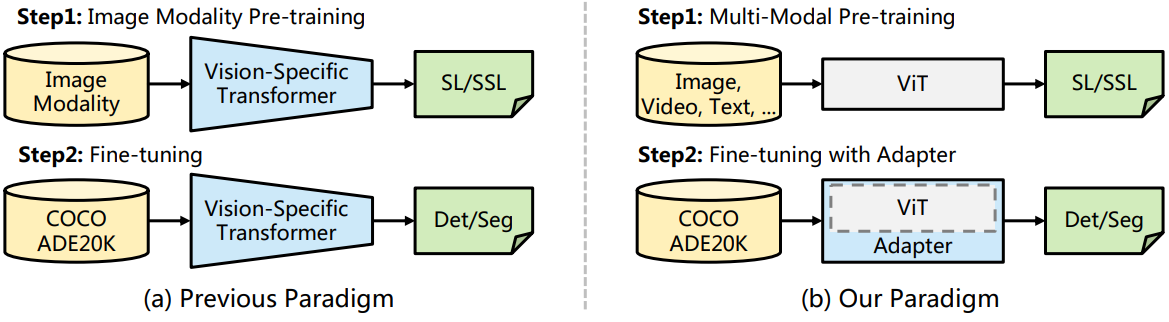
위 그림에서 볼 수 있듯이 대규모 이미지 데이터셋 (ex. ImageNet)를 사전 학습한 다음 다른 task를 fine-tuning하는 이전 패러다임과 비교하여 본 논문의 패러다임은 더 유연하다. 본 논문의 프레임워크에서 backbone network는 이미지뿐만 아니라 멀티모달 데이터로도 사전 학습할 수 있는 범용 모델이다. Dense prediction task의 transfer learning을 위해 랜덤하게 초기화된 어댑터를 사용하여 이미지 관련 사전 지식 (inductive bias)을 사전 학습된 backbone에 도입하여 모델을 이러한 task에 적합하게 만든다. 이러한 방식으로 ViT를 backbone으로 사용하여 본 논문의 프레임워크는 Swin과 같은 비전 전용 transformer와 비슷하거나 더 나은 성능을 달성하였다.
Vision Transformer Adapter
1. Overall Architecture
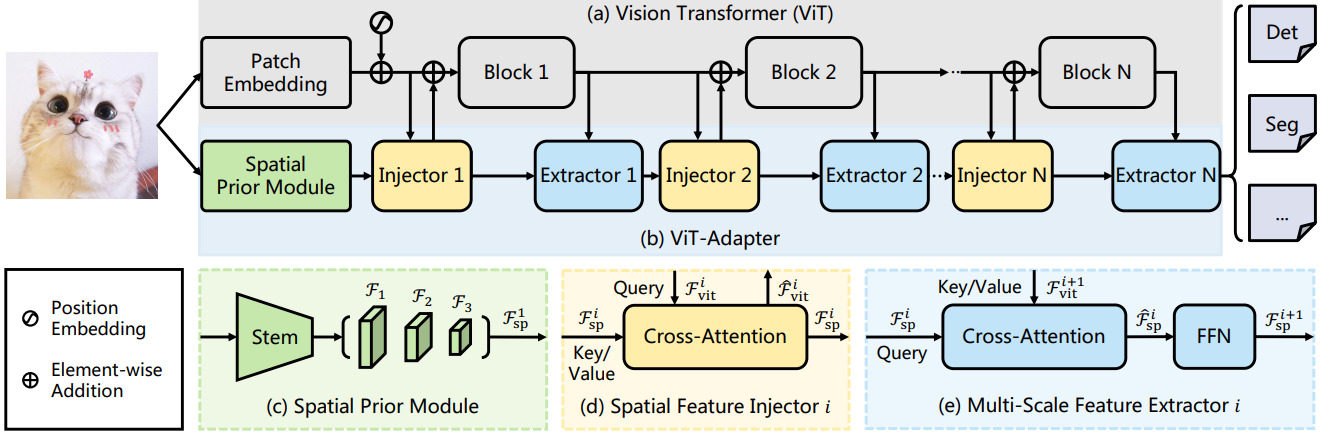
위 그림에서 볼 수 있듯이 본 논문의 모델은 두 부분으로 나눌 수 있다. 첫 번째 부분은 패치 임베딩과 $L$개의 transformer 인코더 레이어로 구성된 일반 ViT이다 (위 그림의 (a) 참조). 두 번째 부분은 위 그림의 (b)와 같이 제안된 ViT-Adapter로
- 입력 이미지에서 공간적 feature를 캡처하는 spatial prior module
- ViT에 spatial prior 정보를 주입하는 spatial feature injector
- ViT의 단일 스케일 feature에서 계층적 feature를 추출하는 multi-scale feature extractor
를 포함한다.
ViT의 경우 입력 이미지는 먼저 패치 임베딩에 입력되며, 여기서 이미지는 겹치지 않는 16$\times$16 패치로 나뉜다. 그 후, 이러한 패치는 flatten되어 $D$차원 토큰으로 project되며 feature 해상도는 원본 이미지의 1/16로 줄어든다. 그런 다음 위치 임베딩으로 추가된 토큰은 $L$개의 인코더 레이어를 통과한다.
ViT-Adapter의 경우 먼저 입력 이미지를 spatial prior module에 공급한다. 세 가지 타겟 해상도 (ex. 1/8, 1/16, 1/32)의 $D$차원 공간적 feature가 수집된다. 그런 다음 이러한 feature map은 feature 상호 작용을 위한 입력으로 flatten되고 concat된다. 구체적으로, 상호 작용 수 $N$ (보통 $N = 4$)을 고려하여 ViT의 transformer 인코더를 각각 $L/N$개의 인코더 레이어를 포함하는 $N$개의 블록으로 균등하게 분할한다. $i$번째 블록의 경우 먼저 spatial feature injector를 통해 spatial prior \(\mathcal{F}_\textrm{sp}^i\)를 블록에 주입한 다음 multi-scale feature extractor를 통해 블록의 출력에서 계층적 feature를 추출한다. $N$개의 feature 상호 작용 후에 고품질 멀티스케일 feature를 얻은 다음 feature를 1/8, 1/16, 1/32의 세 가지 타겟 해상도로 분할하고 재구성한다. 마지막으로 2$\times$2 transposed convolution을 사용하여 1/8 크기의 feature map을 업샘플링하여 1/4 크기의 feature map을 구축한다. 이러한 방식으로 ResNet과 유사한 해상도의 feature pyramid를 얻으며, 이는 다양한 dense prediction task에 사용할 수 있다.
2. Spatial Prior Module
최근 연구에 따르면 convolution은 transformer가 로컬한 공간 정보를 더 잘 캡처하는 데 도움이 될 수 있다. 이에 영감을 받아 Spatial Prior Module (SPM)을 도입한다. ViT의 원래 아키텍처를 변경하지 않도록 패치 임베딩 레이어와 평행한 이미지의 로컬한 공간 컨텍스트를 모델링하도록 설계되었다.
위 그림의 (c)에서 볼 수 있듯이 ResNet에서 빌린 표준 convolution stem이 사용되며, 이는 3개의 convolution과 max-pooling layer로 구성된다. 그런 다음 stride-2 3$\times$3 convolution 스택을 사용하여 채널 수를 두 배로 늘리고 feature map의 크기를 줄인다. 마지막으로 feature map을 $D$ 차원으로 project하기 위해 여러 개의 1$\times$1 convolution이 마지막에 적용된다. 이러한 방식으로 1/8, 1/16, 1/32 해상도의 $D$차원 feature map을 포함하는 feature pyramid \(\{\mathcal{F}_1, \mathcal{F}_2, \mathcal{F}_3\}\)를 얻는다. 그런 다음 이러한 feature map을 feature 상호 작용을 위한 입력으로 feature 토큰 \(\mathcal{F}_\textrm{sp}^1 \in \mathbb{R}^{(\frac{HW}{8^2} + \frac{HW}{16^2} + \frac{HW}{32^2}) \times D}\)로 flatten하고 concat한다.
3. Feature Interaction
약한 prior 가정으로 인해 일반 ViT는 비전 전용 transformer에 비해 dense prediction task에서 좋지 못한 성능을 발휘한다. 이 문제를 완화하기 위해 본 논문은 SPM과 ViT의 feature map을 연결하는 두 가지 feature 상호 작용 모듈을 제안한다. 구체적으로, 두 모듈은 주로 cross-attention을 기반으로 하며, Spatial Feature Injector와 Multi-Scale Feature Extractor라 부른다.
Spatial Feature Injector
위 그림의 (d)에 표시된 대로 이 모듈은 spatial prior를 ViT에 주입하는 데 사용된다. 구체적으로, ViT의 $i$번째 블록에 대해 입력 feature \(\mathcal{F}_\textrm{vit}^i \in \mathbb{R}^{\frac{HW}{16^2} \times D}\)를 query로 사용하고 공간적 feature \(\mathcal{F}_\textrm{sp}^i \in \mathbb{R}^{(\frac{HW}{8^2} + \frac{HW}{16^2} + \frac{HW}{32^2}) \times D}\)를 key와 value로 사용한다. 공간적 feature \(\mathcal{F}_\textrm{sp}^i\)를 입력 feature \(\mathcal{F}_\textrm{vit}^i\)에 주입하기 위해 cross-attention을 사용한다. 이는 다음과 같이 쓸 수 있다.
\[\begin{equation} \hat{\mathcal{F}}_\textrm{vit}^i = \mathcal{F}_\textrm{vit}^i + \gamma^i \textrm{Attention} (\textrm{norm} (\mathcal{F}_\textrm{vit}^i), \textrm{norm} (\mathcal{F}_\textrm{sp}^i)) \end{equation}\]여기서 $\textrm{norm}(\cdot)$은 LayerNorm이고 attention layer $\textrm{Attention}(\cdot)$은 sparse attention을 사용한다. 또한, 학습 가능한 벡터 $\gamma^i \in \mathbb{R}^D$를 적용하여 attention layer의 출력과 0으로 초기화되는 입력 feature \(\mathcal{F}_\textrm{vit}^i\)의 균형을 맞춘다. 이 초기화 전략은 \(\mathcal{F}_\textrm{vit}^i\)의 feature 분포가 spatial prior의 주입에 크게 수정되지 않도록 보장하여 ViT의 사전 학습된 가중치를 더 잘 활용하도록 한다.
Multi-Scale Feature Extractor
Spatial prior을 ViT에 주입한 후, $i$번째 블록의 인코더 레이어를 통해 \(\hat{\mathcal{F}}_\textrm{vit}^i\)를 전달하여 출력 feature \(\mathcal{F}_\textrm{vit}^{i+1}\)를 얻는다. 그런 다음 위 그림의 (e)와 같이 멀티스케일 feature를 추출하기 위해 cross-attention layer와 feed-forward network (FFN)으로 구성된 모듈을 적용한다. 이 프로세스는 다음과 쓸 수 있다.
\[\begin{equation} \mathcal{F}_\textrm{sp}^{i+1} = \hat{\mathcal{F}}_\textrm{sp}^i + \textrm{FFN} (\textrm{norm} (\hat{\mathcal{F}}_\textrm{sp}^i)) \\ \hat{\mathcal{F}}_\textrm{sp}^i = \mathcal{F}_\textrm{sp}^i + \textrm{Attention} (\textrm{norm} (\mathcal{F}_\textrm{sp}^i), \textrm{norm} (\mathcal{F}_\textrm{vit}^{i+1})) \end{equation}\]여기에서는 공간적 feature \(\mathcal{F}_\textrm{sp}^i\)를 query로 사용하고 출력 feature \(\mathcal{F}_\textrm{vit}^{i+1}\)를 cross-attention의 key와 value로 사용한다. Spatial feature injector와 마찬가지로 계산 비용을 줄이기 위해 sparse attention을 채택한다. 생성된 공간적 feature \(\mathcal{F}_\textrm{sp}^{i+1}\)는 다음 spatial feature injector의 입력으로 사용된다.
4. Architecture Configurations
저자들은 ViT-T, ViT-S, ViT-B, ViT-L을 포함하여 4가지 다양한 크기의 ViT를 위한 ViT-Adapter를 구축하였다. 각 어댑터의 파라미터 수는 250만, 580만, 1400만, 2370만 개이다. 샘플링 포인트의 수를 4로 고정하고 attention head의 수를 6, 6, 12, 16으로 설정하는 deformable attention을 기본 sparse attention로 사용한다. 상호 작용의 수 $N$은 4이다. 마지막 feature 상호 작용에서는 3개의 multi-scale feature extractor를 쌓는다. 또한 계산 오버헤드를 절약하기 위해 어댑터의 FFN 비율을 0.25로 설정했다. 즉, FFN의 hidden size는 4개의 각 어댑터에 대해 48, 96, 192, 256이다.
Experiments
1. Object Detection and Instance Segmentation
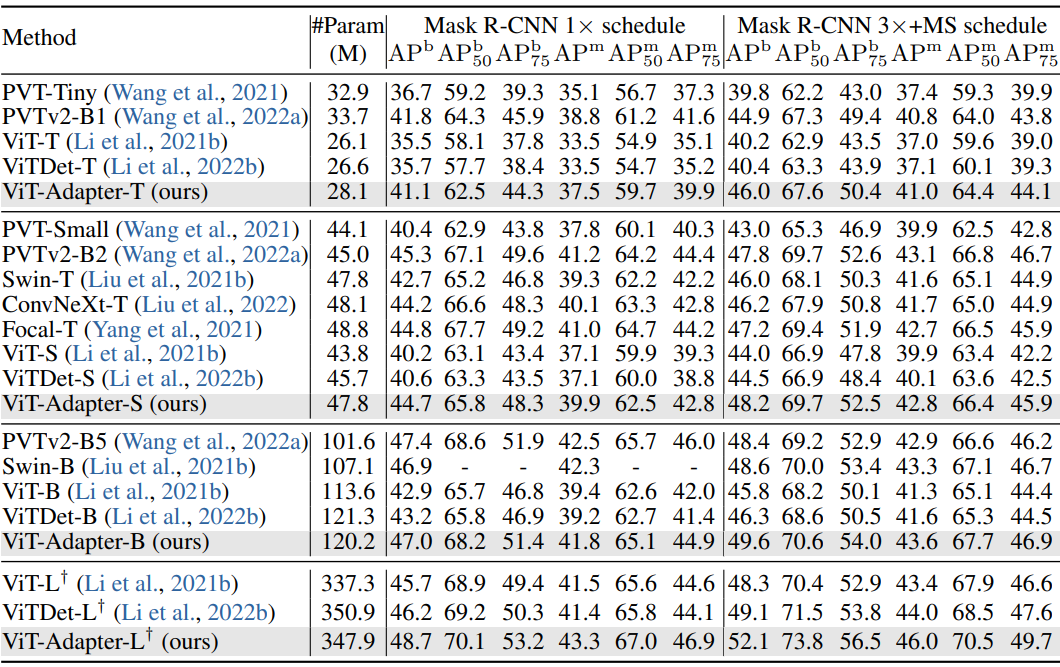
다음은 COCO val2017에서 Mask R-CNN을 사용한 object detection과 instance segmentation 결과이다.
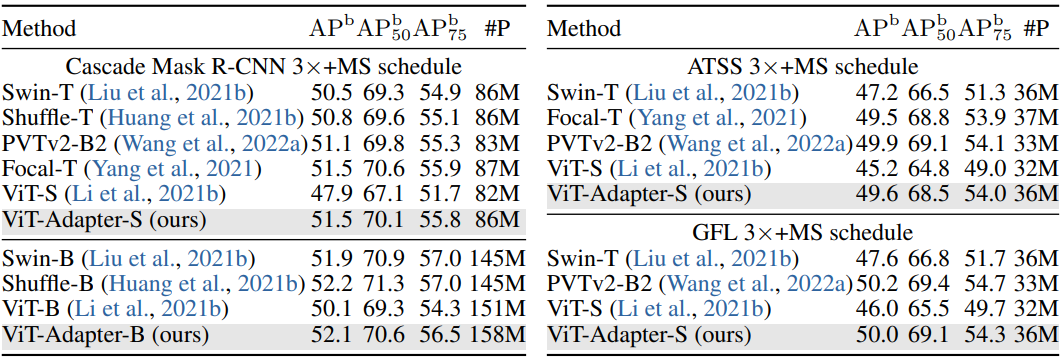
다음은 COCO val2017에서 다른 프레임워크를 사용한 object detection 결과이다.
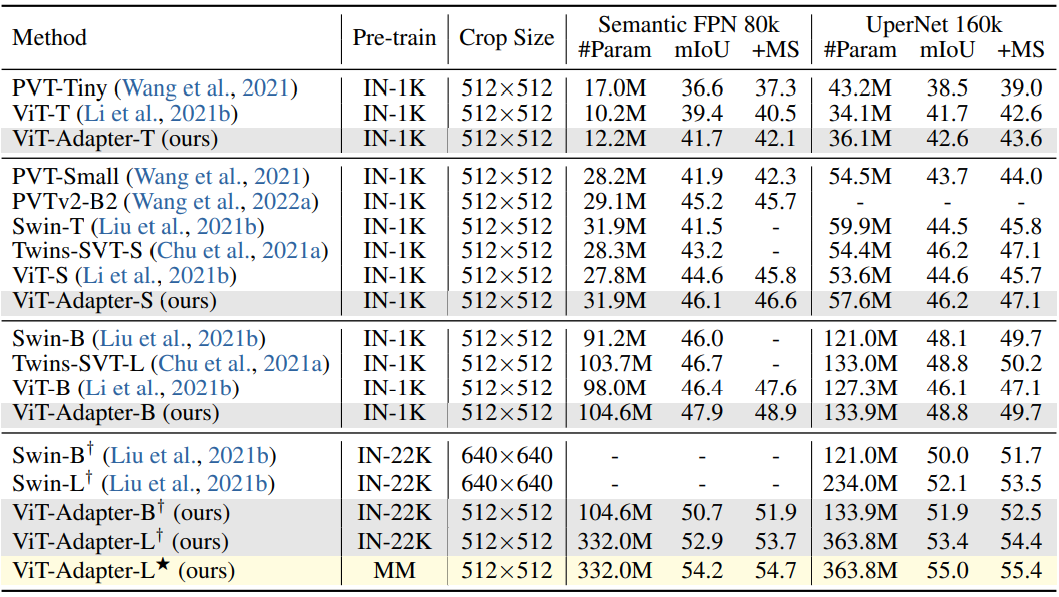
다음은 다양한 사전 학습 가중치에 대한 비교 결과이다.

2. Semantic Segmentation
다음은 ADE20K val에서의 semantic segmentation 결과이다.
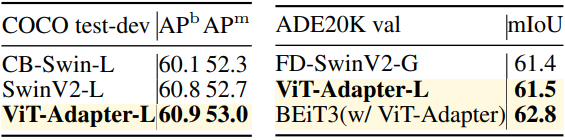
3. Comparisons with State-of-the-Arts
다음은 이전 SOTA와의 비교 결과이다.
4. Ablation Study
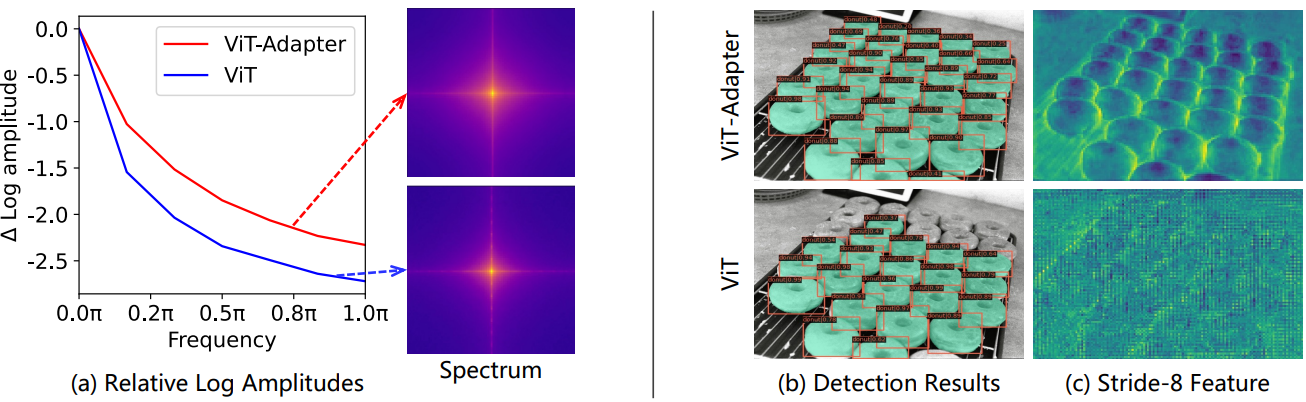
다음은 ViT와 ViT-Adapter의 feature를 시각화한 것이다. (a)는 푸리에 변환된 feature map의 상대 로그 진폭이다. (b)는 detection 결과이고 (c)는 stride-8 feature map이다.
다음은 ViT-Adapter의 ablation study 결과이다. 왼쪽은 주요 구성 요소에 대한 ablation 결과이고 오른쪽은 상호 작용 수 $N$에 대한 ablation 결과이다.

다음은 다양한 attention 메커니즘 사용에 대한 ablation 결과이다.
