[논문리뷰] ViPer: Visual Personalization of Generative Models via Individual Preference Learning
ECCV 2024. [Paper] [Page] [Github]
Sogand Salehi, Mahdi Shafiei, Teresa Yeo, Roman Bachmann, Amir Zamir
Swiss Federal Institute of Technology (EPFL)
24 Jul 2024

Introduction
T2I 생성 모델은 고품질의 이미지를 생성하는 능력을 보여주었으며, 놀라운 일반화 능력을 발휘하였다. 이러한 능력은 이미지 편집, style transfer, 학습 데이터 생성 등의 잠재적 응용에 대한 많은 관심을 불러일으켰다.
이러한 응용은 일반적으로 원하는 결과로 생성 모델을 유도하는 과정을 필요로 하다. 본 논문에서는 개인의 이미지 선호도에 맞춘 생성물을 만들어내는 방법, 즉 개인화(personalization)에 중점을 두었다.
현재 개인적으로 원하는 이미지를 생성하는 방법은 사용자가 원하는 결과를 얻을 때까지 반복적으로 프롬프트를 수정하거나 제한된 피드백을 포함하는 방식이다. 이러한 피드백 형태에는 바이너리 반응 (좋다/싫다), 사용자가 좋아하거나 싫어하는 이미지를 제공하는 방식, 또는 주어진 이미지 세트를 순위 매기는 방식 등이 있다.
본 논문은 주어진 이미지 세트에 대한 개인의 의견을 활용하여 일반적인 시각적 선호도를 포착하는 방법을 제안하였다. 이는 사용자가 왜 특정 이미지를 좋아하거나 싫어하는지 표현할 수 있게 하여, 보다 높은 수준의 표현성을 제공한다. 이러한 표현성의 증가가 개인 선호도에 더 잘 맞는 생성 결과를 가져온다.
이러한 피드백을 Stable Diffusion과 같은 T2I 모델에 통합하기 위해, 먼저 이러한 의견을 시각적 속성으로 이루어진 구조화된 표현으로 변환한다. 즉, 사용자가 이미지에서 좋아하거나 싫어하는 특성들의 집합 (ex. 초현실주의, 거친 붓놀림, 단색 등)을 만든다. 이러한 시각적 선호도를 추가적인 모델의 fine-tuning 없이 Stable Diffusion에 적용할 수 있다.
이 방법을 Visual Personalization of Generative Models via Individual Preference Learning (ViPer)라고 부른다. User study 결과, 사용자는 다른 방법들보다 대부분의 경우 ViPer를 선호하며, 개인화되지 않은 결과나 다른 사용자의 결과보다 개인의 선호도에 맞춘 결과를 강하게 선호한다는 것을 보여준다.
Method
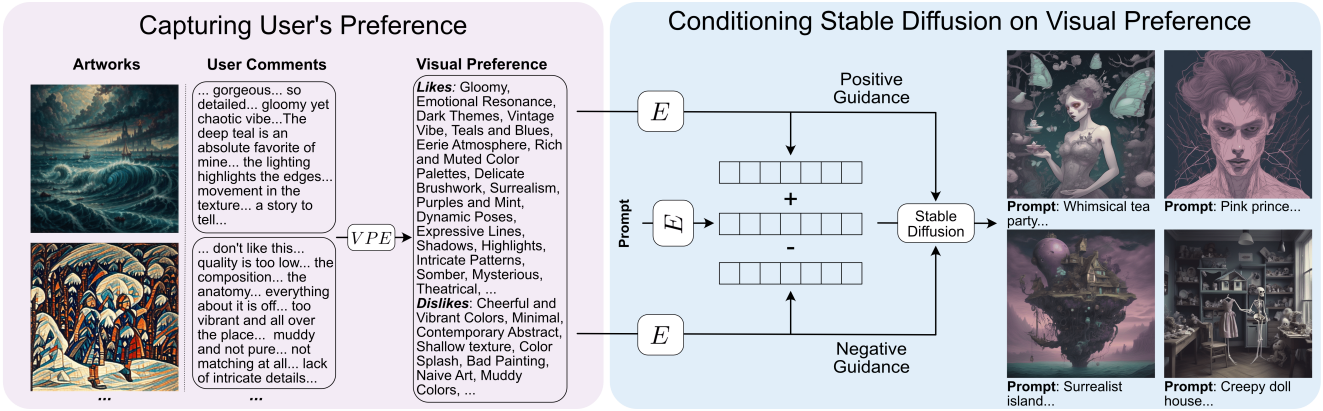
1. Capturing an individual’s visual preferences
선호도를 파악하기 위한 현재의 방법에는 개인이 이미지들을 좋아하거나 싫어하는지, 또는 각 이미지를 어떻게 평가하는지와 같은 신호를 활용하는 것이 포함되고, 일부는 사용자가 대표 이미지들을 제공하도록 요구한다. 그러나 이러한 신호는 개인의 선호도의 일부 측면만 다룰 수 있다.
더욱이 선호도와 이미지 자체도 복잡할 수 있어 이러한 신호가 선호도의 복잡성을 완전히 포착하기 어렵게 만든다. 예를 들어 차가운 색상과 사실적인 예술을 좋아하고 따뜻한 색상과 픽셀 스타일을 싫어하는 경우를 생각해보자. 기존의 바이너리 선택 또는 순위 매기기 방법에서 차가운 색상이 특징인 픽셀 아트가 제시되면 개인은 픽셀 스타일에도 불구하고 이미지를 좋아하는지 여부를 결정하거나 얼마나 좋아하는지 순위를 매겨야 한다.
자유형 코멘트로 개인의 선호도를 파악한다
본 논문은 주어진 이미지 집합에 대한 코멘트를 사용하여 개인의 선호도를 파악하는 것을 제안하였다. 먼저 스타일과 같은 다양한 예술적 특징을 가진 약 50개의 이미지를 생성하고 개인에게 코멘트할 무작위 부분집합을 선택하도록 요청한다. 원하는 경우 제공된 이미지들에 코멘트를 달 수도 있다. 사용자는 선택한 각 이미지를 좋아하거나 싫어하는 이유, 이미지에 대한 인식 및 이미지가 불러일으키는 감정에 대해 논의하도록 권장된다. 중요한 점은 코멘트를 달 때 특정 쓰기 구조에 얽매이지 않는다는 것이다. 언어 모델을 사용하여 자유형 코멘트에서 구조화된 선호도를 추출하기 때문에 원하는 만큼 많이 또는 적게 쓸 수 있다. 이상적으로 이러한 코멘트는 개인에게 중요한 이미지에 존재하는 대부분의 속성을 포함한다. 이 경우 8개 이미지에 대한 코멘트만으로도 개인화된 결과를 얻는 데 충분하다.
자유형 코멘트를 개인의 선호도에 대한 구조화된 표현으로 변환한다
질감이나 색상과 같은 20가지 카테고리에 걸친 속성 집합을 통해 개인의 시각적 선호도를 표현한다. 각 카테고리에는 여러 속성이 포함되어 있다. 저자들은 이를 얻기 위해 GPT-3.5, Claude 2.1, Llama 2와 같은 여러 언어 모델에 대표적인 예술 카테고리와 해당 속성을 출력하도록 지시했으며, 결과를 집계하여 총 약 500개의 시각적 속성을 수집했다.
자유형 코멘트를 시각적 선호도로 변환하려면 코멘트와 선호도를 매핑하는 데이터셋이 필요하지만, 이러한 데이터셋은 아직 존재하지 않는다. 저자들은 좋아하는 시각적 속성과 싫어하는 시각적 속성으로 특징지어지는 5000명의 에이전트를 만드는 것으로 시작하였다. 각 에이전트는 위에서 언급한 속성 목록에서 평균 50개의 좋아하는 속성과 싫어하는 속성을 무작위로 할당받는다. 다양성을 보장하기 위해 두 에이전트의 좋아하는 속성과 싫어하는 속성 사이에 최소 85%의 자카드 거리가 있도록 생성한다.
자카드 거리: $d(A, B) = 1 - \frac{\vert A \cap B \vert}{\vert A \cup B \vert}$
다음으로, 각 에이전트가 각자의 시각적 선호도에 따라 다양한 이미지에 대해 코멘트를 생성한다. 코멘트가 시각적 선호도와 관련성 있고 정보가 풍부하도록 하기 위해, 먼저 각 에이전트마다 평균적으로 10개의 이미지를 생성한다. 이때 입력 프롬프트에 그들이 좋아하거나 싫어하는 시각적 속성의 무작위 부분집합을 결합하여 사용한다. 입력 프롬프트는 무작위로 선택되기 때문에 이미지가 어느 정도 랜덤하게 생성되지만 각 에이전트의 시각적 선호도와 직접적으로 관련이 있다.
이 이미지들에 대한 에이전트들의 코멘트를 생성하기 위해, 각 에이전트의 시각적 선호도에 기반하여 GPT-4가 코멘트를 작성하도록 한다. 오타와 풍자는 무작위로 허용되어 다양성을 더하고 결과를 더 인간적으로 보이게 만든다. 이 과정은 각 에이전트에 대해 시각적 속성과 코멘트가 쌍을 이루는 데이터셋을 생성하게 된다.
개인의 시각적 선호도를 코멘트에서 추출하기 위해, 이 데이터셋을 바탕으로 IDEFICS2-8b라는 vision-language mode을 fine-tuning한다. Fine-tuning된 IDEFICS 모델을 Visual Preference Extractor (VPE)라고 부른다. VPE의 출력은 미리 정의된 속성에만 국한되지 않으며, 코멘트에서 언급된 속성도 추출할 수 있다. 예를 들어, 속성 집합에 정의되지 않은 색상이 코멘트에 언급되었을 때도 이를 인식할 수 있다.
2. Personalizing a generative model based on an individual’s preference
코멘트에서 파악한 시각적 선호도를 사용하여 생성 모델을 적용해야 한다. 본 논문에서는 Stable Diffusion을 사용한다. 각 개인의 선호도는 각각 선호하는 속성 집합 \(\textrm{VP}_{+}\)와 싫어하는 속성 집합 \(\textrm{VP}_{-}\)으로 설명된다. Stable Diffusion의 텍스트 인코더 $E$를 사용하여 이러한 선호도를 인코딩하면 \(E(\textrm{VP}_{+})\)와 \(E(\textrm{VP}_{-})\)를 얻을 수 있다. 입력 프롬프트 $p$를 인코딩하고 $E(p)$를 \(E(\textrm{VP}_{+})\)와 \(E(\textrm{VP}_{-})\)로 수정하여 다음과 같이 생성을 개인의 선호도로 유도한다.
\[\begin{equation} \textbf{p} = E(p) + \beta (E(\textrm{VP}_{+}) - E(\textrm{VP}_{-})) \end{equation}\]$\beta$는 개인이 선호도에 따라 개인화의 정도를 높이거나 낮추도록 조정할 수 있다. 저자들은 $\beta \le 1$이면 생성이 입력 프롬프트와 시각적 선호도에 모두 충실하게 된다는 것을 발견했다. 프롬프트와 함께 개인의 선호도에 맞춰 프로세스를 더욱 가이드하기 위해 classifier-free guidance를 사용하여 예측된 noise도 수정한다.
\[\begin{aligned} \epsilon_\textrm{vp} (\textbf{x}_t, t) &= \epsilon_\theta (\textbf{x}_t, t, E(\textrm{VP}_{+})) - \epsilon_\theta (\textbf{x}_t, t, E(\textrm{VP}_{-})) \\ \bar{\epsilon}_\theta (\textbf{x}_t, t, \textbf{p}) &= (1 - w) \epsilon_\theta (\textbf{x}_t, t) + w (\epsilon_\theta (\textbf{x}_t, t, \textbf{p}) + \beta \epsilon_\textrm{vp} (\textbf{x}_t, t)) \end{aligned}\]($\epsilon_\theta$는 Stable Diffusion의 denoising U-Net, $w$는 guidance scale)
Denoising process의 변경 사항은 Algorithm 1에 나와 있다.

3. Proxy for evaluating personalized generations
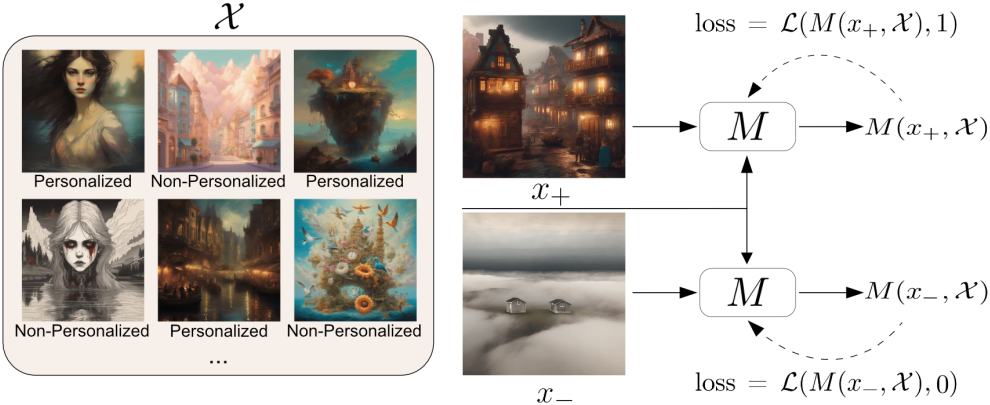
생성된 개인화된 이미지를 평가하기 위해서는 인간 평가가 가장 좋지만 비용이 많이 들고 확장성이 없다. 따라서 저자들은 이러한 생성을 평가하기 위한 proxy metric을 도입하였다.
이 proxy metric은 개인이 특정 이미지를 얼마나 선호하는지를 나타낸다. Proxy metric을 얻기 위해 에이전트들로부터 얻은 데이터와 Pick-a-Pic 데이터셋을 결합한다. Pick-a-Pic 데이터셋은 생성된 이미지를 인간 사용자가 좋다/싫다로 선호도를 나타낸 데이터셋이다. 언어 모델을 사용해 개인화된 프롬프트를 생성하고, 이를 통해 Stable Diffusion XL로 이미지를 생성한다. 이는 proxy metric이 ViPer의 생성 결과에만 편향되지 않도록 하기 위함이다.
따라서, 특정 엔티티 (에이전트나 인간 사용자)에 대해 그들의 개인화된 이미지 세트 또는 그들이 좋아하는 생성된 이미지 세트를 얻는다. 각 엔티티 $i$에 대하여 이 세트에서의 이미지를 $x_{+}^i$라 하고, 이들이 싫어하거나 개인화되지 않은 이미지는 $x_{-}^i$라 하자. 그리고 이러한 이미지 쌍의 집합을 \(\mathcal{X}^i = \{x_{+}^{i,j}, x_{-}^{i,j}\}_{j=1}^k\)라 하자.
5,000개의 이미지 쌍을 사용해 IDEFICS2-8b 모델 $M$을 fine-tuning하여, 주어진 이미지 $x$에 대해 사용자가 좋아할 확률
\[\begin{equation} M(x, \mathcal{X}) = \textrm{Pr}(x \; \textrm{is liked by the user} \; \vert \; \mathcal{X}) \end{equation}\]을 출력하도록 만든다. 학습 시에는 cross-entropy loss를 사용한다.
Evaluation and Ablations
1. Evaluating the personalized generations
다음은 여러 사용자의 개인화된 생성 결과를 비교한 것이다.

다음은 user study 결과이다. 각 사용자에게는 8개의 이미지가 주어지며, 사용자 각 이미지에 순위를 매긴다. 각 사용자마다 12~15개의 프롬프트가 주어진다.
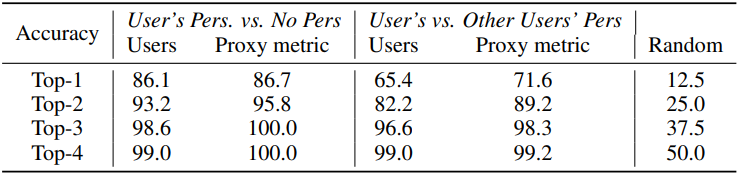
- User’s Pers. vs. No Pers: 사용자에 개인화된 이미지 1개와 개인화되지 않은 이미지 7개가 주어진다.
- User’s vs. Other Users’ Pers: 사용자에 개인화된 이미지 1개와 다른 사용자에 개인화된 이미지 7개가 주어진다.
다음은 $\beta$를 사용하여 개인화의 정도를 조절한 예시이다.

다음은 Author test와 VP vs. VP test의 결과이다.
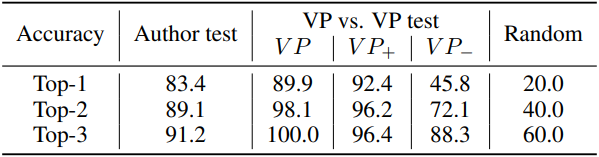
- Author test: 에이전트 5명의 시각적 선호도가 주어지면 GPT-4가 코멘트를 작성한 에이전트를 식별하는 테스트
- VP vs. VP test: 재구성된 시각적 선호도가 주어지면 5개의 실제 시각적 선호도와 비교하여 에이전트를 식별하는 테스트
2. Comparison with baselines
다음은 다른 방법들과 생성 결과를 비교한 것이다.

Limitations
- 선호도를 명확하게 표현하는 것은 여전히 일부 사용자에게 어려울 수 있다.
- 사전에 정의한 시각적 속성 세트가 모든 것을 다 포괄하지 못할 수 있다.
- Stable Diffusion의 텍스트 인코더에 의존하고 있다. 이 인코더는 77 토큰 제한과 단어 순서에 대한 민감성과 같은 한계를 가지고 있어, 때때로 선호하는 속성이 간과되는 경우가 있다.
- 제안된 proxy metric을 사용하여 Stable Diffusion을 fine-tuning하면 생성 품질이 저하되는 문제가 있다.