[논문리뷰] ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
CVPR 2024. [Paper] [Page] [Github]
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
University of Wisconsin-Madison | Cruise LLC
1 Dec 2023

Introduction
LLaVA나 MiniGPT-4와 같은 Large Multimodal Model (LMM)들은 주로 전체 이미지 이해에 중점을 둔다. 즉, 복잡한 장면에서 영역별 정보를 처리하는 능력이 부족하다. 이러한 제한은 언어 프롬프트만 사용하여 이미지 내의 특정 물체를 설명하려고 할 때 특히 분명해지며, 질문에 모호함이 있는 경우 어려움을 겪는다.
이 문제를 해결하기 위해 최근에는 LMM의 공간 참조가 연구되었으며, 주로 좌표의 텍스트 표현, 학습된 위치 임베딩, ROI feature를 사용하는 데 중점을 둔다. 그러나 bounding box나 마스크 윤곽의 공간 좌표와 같은 고정된 형식의 시각적 참조로 제한되므로 사용자 친화적이지 않다.
본 논문에서는 임의의 비주얼 프롬프트를 처리할 수 있는 LMM인 ViP-LLaVA를 제안하였다. 이를 통해 사용자는 직관적으로 이미지를 마크업하고 “빨간색 박스”나 “뾰족한 화살표”와 같은 자연스러운 신호를 사용하여 상호 작용할 수 있다. CLIP이 비주얼 마커를 이해할 수 있으므로 추가 영역별 모델 설계 없이 원본 이미지 공간에 비주얼 프롬프트를 직접 주입한다. 이 접근 방식은 간단하지만 예상치 못한 이점을 제공한다. 본 논문의 모델은 정확한 영역별 인식과 복잡한 추론을 요구하는 task에 대해 새로운 SOTA를 달성하였다.
추가로 저자들은 임의의 비주얼 프롬프트를 통해 LMM의 영역 이해 능력을 평가하기 위한 벤치마크인 ViP-Bench를 도입하였다. 다양한 303개의 이미지와 질문을 수집하여 인식, OCR, 지식, 수학, 물체 관계 추론, 언어 생성 등 영역 수준의 6가지 측면에 걸쳐 시각적 이해 능력에 대하여 종합적으로 평가한다.
Method
1. Visual Prompt Embedding via CLIP
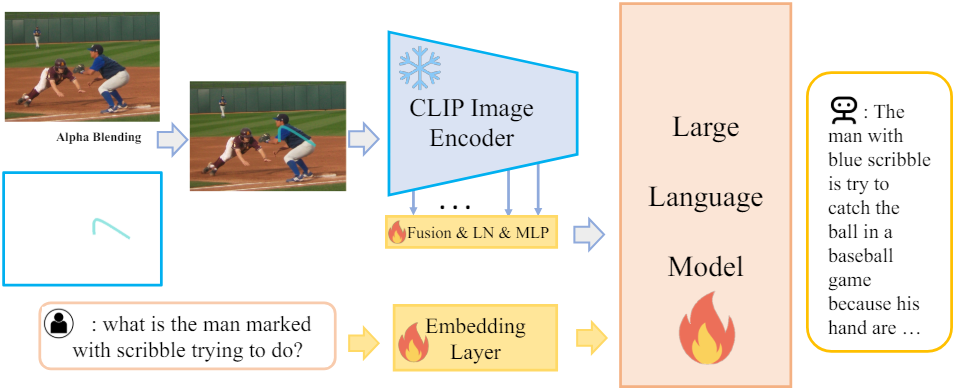
비주얼 프롬프트를 처리하기 위해 새로운 모듈을 구성하는 대신 CLIP의 기존 능력을 활용하여 이미지와 비주얼 마커를 모두 인코딩한다. 최근 연구에 따르면 CLIP은 본질적으로 원, 직사각형 등이 표시된 영역에 주의를 기울이는 것으로 나타났다. 또한 CLIP은 화살표나 임의의 낙서와 같은 다양한 비주얼 프롬프트에 모델의 주의를 집중시킨다. 이 능력을 활용하기 위해 알파 블렌딩을 통해 비주얼 프롬프트 \(\textbf{P}_v\)를 원본 이미지 \(\textbf{X}_v\)에 합성하여 관심 영역을 강조하는 병합 표현을 만든다.
$\alpha$는 비주얼 프롬프트의 투명도이다. 비주얼 프롬프트 아래에 있는 픽셀에 대해서만 알파 블렌딩을 수행한다. 알파 블렌딩 후에 합성 이미지 \(\hat{\textbf{X}}_v\)가 LMM에 입력된다.
비주얼 프롬프트를 효과적으로 인식하기 위해 낮은 수준과 높은 수준의 visual feature의 균형을 유지한다.
CLIP의 더 깊은 feature를가 낮은 수준의 디테일을 간과하는 경향을 해결하기 위해 여러 CLIP 레이어에서 feature를 선택적으로 추출한다. 구체적으로, 6번째 레이어를 사용하여 상세한 기하학적 모양을 인코딩하고 15, 18, 21, 24번째의 레이어를 사용하여 더 광범위한 semantic 정보를 캡처한다. 이러한 multi-level feature들은 concatenate되고 학습 안정성을 위해 LayerNorm으로 정규화되며 마지막으로 MLP 레이어를 통과한다. 이 프로세스를 통해 ViP-LLaVA는 다양한 시각적 신호를 효과적으로 통합할 수 있다.
비주얼 프롬프트를 직접 오버레이하는 디자인은 여러 가지 이점을 제공한다. 사용자는 다양한 비주얼 마커를 사용하는 경우가 많기 때문에 추가 처리 모듈을 사용하지 않아 모델 복잡도를 줄이고 인간 상호 작용과 밀접하게 일치한다. 이러한 유연성을 통해 ViP-LLaVA는 사용자가 생성한 광범위한 시각적 신호를 해석하여 실제 시나리오에서의 적용 가능성을 향상시킬 수 있다.
ViP-LLaVA를 학습시키기 위해 autoregressive 언어 모델링을 수행한다. 즉, 정답 \(\textbf{X}_a\)의 토큰을 생성할 likelihood를 최대화한다.
\[\begin{equation} P (\textbf{X}_a \; \vert \; \hat{\textbf{X}}_v, \textbf{X}_\textrm{instruct}) = \prod_{i=1}^L P_\theta (x_i \; \vert \; \hat{X}_v, \textbf{X}_\textrm{instruct}, \textbf{X}_{a, <i}) \end{equation}\]$\theta$는 학습 가능한 파라미터, \(\textbf{X}_\textrm{instruct}\)는 텍스트 명령, $L$은 답변 \(\textbf{X}_a\)의 시퀀스 길이, \(\textbf{X}_{a, <i}\)는 현재 예측 토큰 $x_i$ 이전의 모든 답변 토큰이다.
모델은 시각적 콘텐츠, 언어 명령, 중첩된 프롬프트를 이해하여 상황에 맞게 정확한 응답을 생성할 수 있다. 이는 이미지와 함께 비주얼 마커를 해석하는 모델의 능력을 육성하여 영역에 대한 복잡한 질문을 처리하는 능력을 향상시킨다.
2. Visual Prompting Design

기존 데이터셋 중에 임의의 비주얼 프롬프트와 명령-출력 텍스트 쌍이 포함된 데이터셋은 존재하지 않는다. 따라서 저자들은 새로운 비주얼 프롬프트 instruction tuning 데이터셋을 개발하였다.
데이터셋은 비주얼 프롬프트가 표시되어 있는 52만 개의 이미지-텍스트 쌍으로 구성되며, 기존의 공개 데이터셋들로부터 구성되었다.
- 단일 영역 추론 데이터
- RefCOCOg: 참조 이해 및 생성 데이터 8만 개
- PointQA-LookTwice: 물체 개수 계산 데이터 3.7만 개
- 두 영역 추론 데이터
- Visual Genome: 삼중 관계 데이터 8만 개
- 다중 영역 추론 데이터
- Flicker 30k Entities: grounded image captioning 데이터 3만 개
- Visual Commonsense Reasoning: 21.3만 개
- Visual7W: 8.2만 개
다양한 비주얼 프롬프트를 사용하여 각 이미지에 자동으로 주석을 추가한다. Bounding box만 제공되는 데이터의 경우 직사각형, 타원, 화살표의 세 가지 비주얼 프롬프트를 샘플링한다. 화살표의 경우 화살표 머리가 항상 이미지 내에 있는지 확인한다. 타원의 경우 장반경과 단반경이 bounding box 크기의 1 ~ 1.5배가 되도록 한다.
픽셀 수준 GT 마스크가 제공되는 영역의 경우 8가지 비주얼 프롬프트, 즉 직사각형, 타원, 점, 삼각형, 마스크, 마스크 윤곽선, 화살표, 낙서 중에서 비주얼 프롬프트를 샘플링한다. 화살표 머리, 점, 삼각형, 낙서는 제공된 마스크 내에 있도록 한다. 이러한 주석은 인간의 자연스러운 상호 작용을 시뮬레이션한다. 낙서의 경우 Bezier curve를 사용하여 인간과 유사한 그림을 시뮬레이션한다. 마스크 내에서 quadratic Bezier curve의 앵커 역할을 하는 세 점을 무작위로 선택하고 Bezier curve를 알파 블렌딩으로 이미지에 합성한다.
3. Optional Region-level Instruction Tuning Data
학습 데이터는 앞서 설명한 영역 레벨의 비주얼 프롬프트 데이터와 LLaVA-1.5에서 가져온 비주얼 프롬프트가 없는 이미지 레벨의 데이터에서 나온다. ViP-LLaVA는 주로 이미지 레벨의 LLaVA instruction data로 인해 인간과 유사한 대화에 참여할 수 있다. 저자들은 영역 레벨의 대화에서 ViP-LLaVA의 능력을 더욱 향상시키기 위해 GPT-4V의 도움을 받아 영역별 명령 데이터를 설계하였다.
GPT4와 같은 텍스트 전용 모델과 달리 GPT-4V는 이미지에 표시되는 비주얼 프롬프트를 해석할 수 있다. 원본 이미지와 비주얼 프롬프트가 있는 수정된 이미지, GT 텍스트 주석을 GPT-4V에 공급한다. 이를 통해 앞서 설명된 데이터셋의 이미지에 대한 (비주얼 프롬프트, 텍스트 프롬프트, 텍스트 출력) 데이터를 선별한다.
GPT-4V가 단일 영역 및 다중 영역에서 비주얼 프롬프트를 인식하도록 안내하기 위해 “within red box”와 같은 특정 텍스트 표현을 도입한다. 학습 중에 이러한 문구를 8가지 비주얼 프롬프트들로 대체하여 데이터셋의 다양성을 크게 향상시킨다. 이를 통해 7,000개의 단일 영역 인스턴스와 6,000개의 다중 영역 인스턴스로 구성된 1.3만 개의 고품질 영역 레벨 명령 데이터들을 선별한다.
ViP-LLaVA는 이러한 풍부한 데이터 없이도 벤치마크에서 잘 작동하지만 풍부한 데이터를 사용하면 인간처럼 대화를 할 수 있는 모델의 능력을 더욱 향상시키는 데 도움이 된다.
ViP-Bench for Evaluation
저자들은 다양한 비주얼 프롬프트를 해석하고 응답하는 LMM의 능력을 엄격하게 평가하기 위해 새로운 벤치마크인 ViP-Bench를 도입하였다. ViP-Bench는 303개의 고유한 이미지-질문 쌍으로 구성되며, 여기서 이미지는 MM-Vet, MMBench, Visual Genome에서 수집되었다. 각 쌍은 모델의 이해 및 해석 능력을 테스트하기 위해 고안된 다양한 시각적 추론 질문과 해당 이미지로 구성된다. 저자들은 MM-Vet와 MMBench의 질문을 재사용하였지만 Visual Genome의 질문과 답변은 직접 디자인하였다. 또한 SAM으로 생성한 bounding box와 마스크를 사용하여 물체의 위치에 주석을 달았다.
ViP-Bench 설계의 핵심은 인식, OCR, 지식, 수학, 물체 관계 추론, 언어 생성 등 영역 수준에서 시각적 이해의 6가지 중요한 측면을 포괄적으로 다루는 것이다. 이 범위는 영역 수준 시각적 추론의 다양한 측면에서 모델 성능에 대한 전체적인 평가를 보장한다.
ViP-Bench는 MM-Vet과 유사한 채점 메커니즘을 사용한다. LMM의 응답을 평가하기 위해 SOTA 언어 모델인 GPT-4 텍스트 모델을 사용한다. 구체적으로 LMM의 응답, 사람이 주석을 추가한 답변, 여러 상황 내 채점 예시를 GPT-4에 제공한다. LMM의 응답은 GPT-4에 의해 0에서 10까지 점수가 매겨진다. 이 채점 시스템은 다양한 모델의 성능을 비교하기 위한 표준화된 프레임워크를 제공한다.
또한 ViP-Bench는 사람이 꼼꼼하게 주석을 달았다. Bounding box, 마스크, 질문, 답변의 정확성과 관련성을 보장하기 위한 7번 검증되었다. 이러한 엄격한 주석은 모델 평가 도구로서 벤치마크의 신뢰성을 보장한다.
Experiments
- 모델 구성
- 비전 모델: CLIP-336px (학습 시 고정)
- 언어 인코더: Vicuna v1.5
- 멀티모달 커넥터: 2-layer MLP
- 학습 디테일
- GPU: NVIDIA A100 8개
- 1단계: BLIP의 캡션이 달린 이미지-텍스트 쌍 55.8만 개로 멀티모달 커넥터를 사전 학습
- 2단계: LLaVA v1.5의 명령 데이터와 영역 수준의 비주얼 프롬프트 데이터셋으로 전체 모델 학습 (ViP-LLaVA-Base)
- 3단계: GPT-4V 명령 데이터 1.3만 개와 2단계에서 사용한 데이터 1.3만 개를 혼합하여 2단계 모델을 fine-tuning (ViP-LLaVA)
- 학습 시간: 7B 모델은 2단계까지 10시간, 3단계는 0.5시간이 소요되며, 13B 모델은 7B 모델의 약 2배가 소요
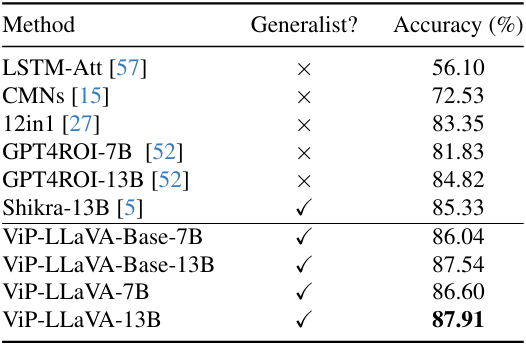
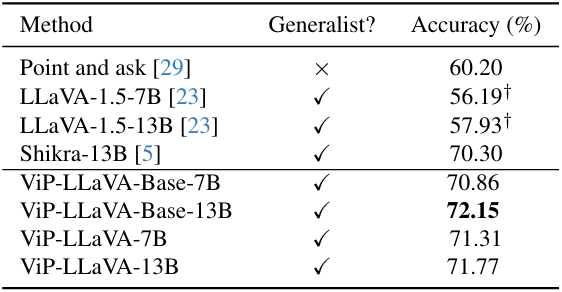
1. Evaluation on Region Reasoning Benchmarks
다음은 (왼쪽) Visual7W와 (오른쪽) PointQA-LookTwice에 대한 성능을 비교한 표이다. (†: zero-shot)
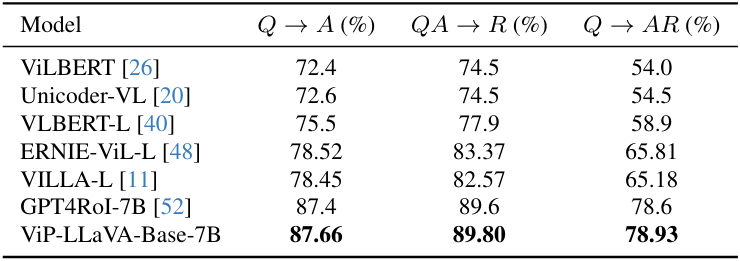
다음은 VCR 데이터셋에 대한 성능을 비교한 표이다.
2. In-depth Analysis
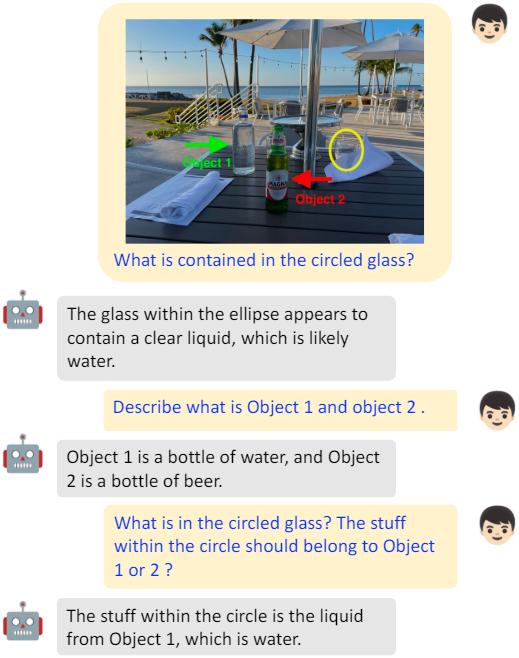
ViP-LLaVA는 (왼쪽) 이미지 내 여러 물체 간의 대응 관계를 추론할 수 있으며, (오른쪽) 텍스트 마커를 이해하고 이에 대해 추론할 수 있다.

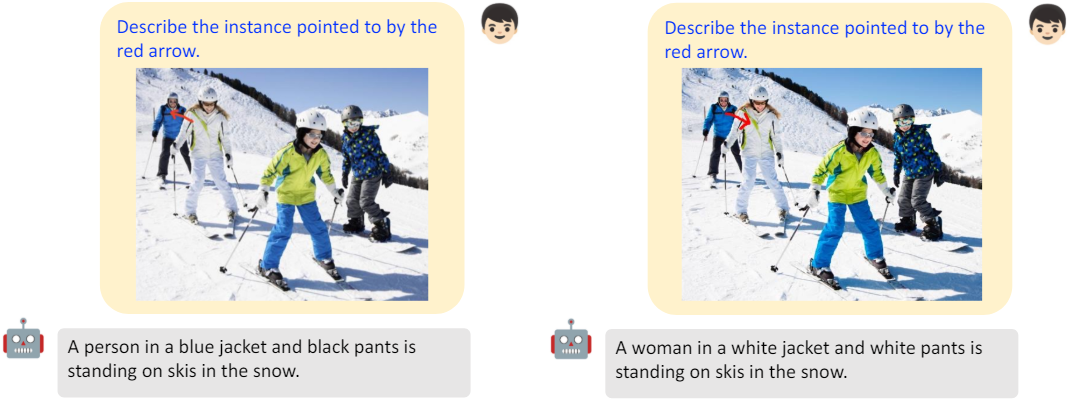
ViP-LLaVA는 화살표의 방향을 이해할 수 있다.
3. Ablation Studies
다음은 CLIP 이미지 인코딩 레이어에 대한 ablation 결과이다.

4. ViP-Bench Evaluation Results
다음은 ViP-Bench에서 인식(Rec), OCR, 지식(Know), 수학(Math), 관계(Rel), 언어 생성(Lang)을 평가한 표이다.
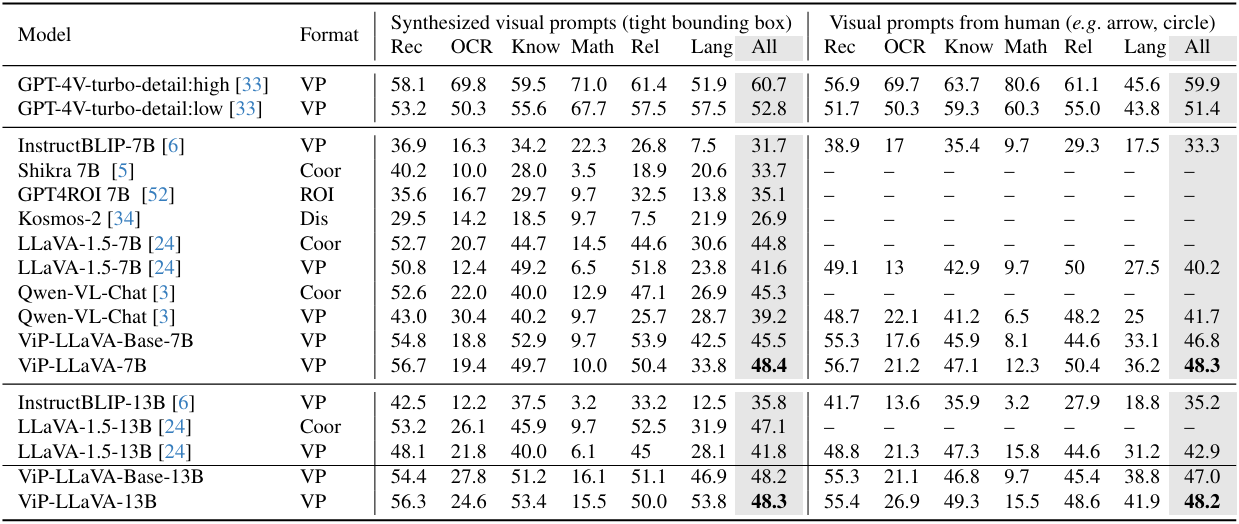
- VP: 비주얼 프롬프트
- Coor: 좌표를 비주얼 프롬프트로 사용
- Dis: Vocabulary 확장을 위한 discrete한 위치 토큰
- ROI: 위치 임베딩을 사용한 CLIP 관심 영역 feature
다음은 GPT-4V가 잘못된 예측을 하는 ViP-Bench의 예시이다.
