[논문리뷰] VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
ICLR 2025. [Paper] [Page] [Github] [Demo]
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, Yao Lu
Tsinghua University | MIT | NVIDIA | UC Berkeley | UC San Diego
6 Sep 2024
Introduction
본 논문에서는 시각적 및 텍스트 입력에 대한 통합된 next-token prediction loss를 가진 end-to-end autoregressive 프레임워크인 VILA-U를 제시하였으며, diffusion model과 같은 외부의 도움 없이 시각적 언어 이해 및 생성 task에서 경쟁력 있는 성과를 달성하였다. 저자들은 비전과 언어 모달리티를 통합하기 위한 두 가지 중요한 원칙을 세웠다.
- 기존의 통합된 end-to-end autoregressive VLM은 discrete한 VQGAN 토큰이 이미지 재구성 loss에 대해서만 학습되고 텍스트 입력과 정렬되지 않기 때문에, 경쟁력 있는 시각적 이해를 달성할 수 없었다. 따라서 VQ (vector quantization) vision tower 사전 학습 중에 텍스트 정렬을 도입하는 것이 중요하다.
- Autoregressive한 이미지 생성은 충분한 크기의 고품질 데이터에서 학습되는 경우 diffusion model과 유사한 품질을 얻을 수 있다.
이러한 통찰력에 따라 VILA-U는 VQ를 통해 시각적 입력을 discrete한 토큰으로 변환하고, contrastive learning을 사용하여 이러한 토큰을 텍스트 입력과 정렬하는 통합된 foundation vision tower를 사용한다. VILA-U의 멀티모달 학습은 소규모의 고품질 이미지-텍스트 코퍼스에서 비주얼 토큰과 텍스트 토큰 모두에 대한 통합된 next-token prediction loss를 활용한다.
VILA-U는 end-to-end autoregressive model과 continuous-token VLM 간의 시각적 이해 성능 격차를 크게 줄이는 동시에 경쟁력 있는 이미지/동영상 생성 능력을 도입하였다.
Method
1. Unified Foundation Vision Tower
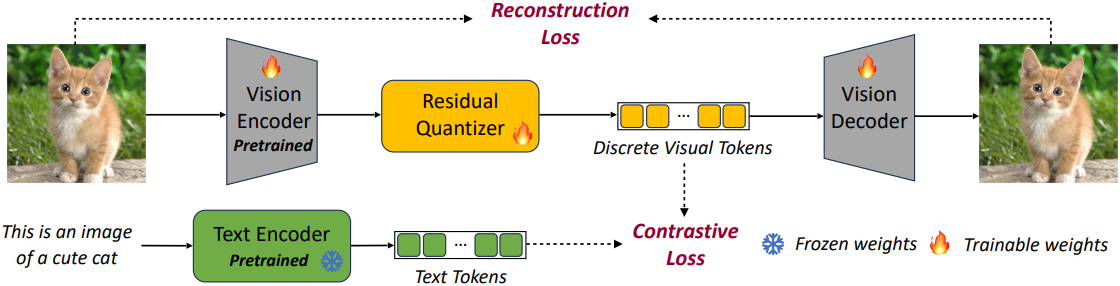
다양한 시각적 이해 및 생성 task를 지원하기 위해, 먼저 적절한 visual feature를 제공하기 위한 foundation vision tower를 구축한다. Vision tower 학습에 텍스트-이미지 contrastive loss와 VQ 기반 이미지 재구성 loss를 포함하여 vision tower의 텍스트 정렬 및 tokenization 능력을 강화한다.
이미지에서 추출한 feature는 residual VQ를 통해 discretize된다. 그런 다음, 한 경로에서는 discrete한 visual feature를 디코더에 입력하여 이미지를 재구성하고 재구성 loss를 계산한다. 다른 경로에서는 discrete한 visual feature와 텍스트 인코더에서 제공하는 텍스트 feature 간의 이미지-텍스트 contrastive loss를 계산한다. 이 학습 절차를 통해 vision tower는 VLM에서 이해와 생성에 모두 적합한 discrete feature를 추출하는 방법을 학습한다.
Unified Training Recipe
Vision tower를 두 가지 loss로 처음부터 학습시키는 것은 어려운 일이다. 정렬과 재구성은 각각 고수준의 semantic feature와 저수준의 appearance feature가 필요하기 때문이다. 두 가지 loss로 전체 vision tower를 처음부터 학습시키면 상충되는 목표로 인해 모델의 성능이 매우 안 좋아진다. (ImageNet zero-shot classification에서 top-1 정확도가 5%)
이 문제를 해결하기 위해, 두 loss를 동시에 학습하는 대신, 먼저 모델에 텍스트-이미지 정렬 능력을 제공한 다음, 정렬 능력을 유지하면서 재구성을 학습시킨다. 구체적으로, CLIP 모델에서 사전 학습된 가중치로 비전 인코더와 텍스트 인코더를 초기화하여 양호한 텍스트-이미지 정렬을 보장한다. 그런 다음, 텍스트 인코더를 고정하고 contrastive loss와 재구성 loss를 모두 사용한다. Contrastive loss는 정렬 능력을 유지하는 반면 재구성 loss는 재구성 능력을 개발한다.
이 접근 방식은 빠르게 수렴하고 강력한 성능을 제공한다. 사전 학습된 CLIP 가중치에는 학습된 고수준의 prior가 포함되어 있으며, 이는 처음부터 학습하기 어렵고 계산 비용이 많이 든다. CLIP 가중치로 초기화하면 비전 인코더에서 저수준 및 고수준 feature를 훨씬 빠르고 다루기 쉽게 바인딩할 수 있다.
텍스트-이미지 contrastive loss와 VQ 기반 이미지 재구성 loss를 결합하기 위해 가중 합을 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{total} = w_\textrm{contra} \mathcal{L}_\textrm{contra} + w_\textrm{recon} \mathcal{L}_\textrm{recon} \end{equation}\](\(w_\textrm{contra} = 1\), \(w_\textrm{recon} = 1\)을 사용)
Residual Vector Quantization
Visual feature의 표현 능력은 quantizer에서 사용하는 코드 크기에 크게 좌우된다. Visual feature들이 고수준과 저수준 feature를 모두 포함하고 있기를 바라기 때문에, 더 큰 코드 크기가 필요하다. 그러나 각 이미지에 대한 코드가 너무 많으면 LLM이 시각적 생성 프로세스에서 생성할 토큰이 너무 많아 많은 지연이 발생한다. 따라서 feature 용량을 늘리고 동시에 LLM에 대한 적절한 수의 토큰을 유지하기 위해, RQ-VAE의 residual VQ 방법을 채택하여 벡터 $\textbf{z}$를 $D$개의 코드로 discretize한다.
\[\begin{equation} \end{equation} \mathcal{R}\mathcal{Q} (\textbf{z}; \mathcal{C}, D) = (k_1, \cdots, k_D) \in [K]^D\]($\mathcal{C}$는 codebook, $K$는 codebook의 크기, $k_d$는 깊이 $d$에서의 $\textbf{z}$의 코드)
\(\textbf{r}_0 = \textbf{z}\)로 시작하여 각 깊이 $d = 1, \cdots, D$에 대해 재귀적으로 VQ를 수행한다.
\[\begin{aligned} k_d &= \mathcal{Q} (\textbf{r}_{d-1}, \mathcal{C}) = \underset{k \in [K]}{\arg \min} \,\| \textbf{r}_{d-1} - \textbf{e} (k_d) \|_2^2 \\ \textbf{r}_d &= \textbf{r}_{d-1} - \textbf{e} (k_d) \end{aligned}\]($\textbf{e}$는 codebook 임베딩 테이블)
$\textbf{z}$에 대한 quantize된 벡터는 모든 깊이에 대한 합이다.
\[\begin{equation} \hat{\textbf{z}} = \sum_{i=1}^D \textbf{e}(k_i) \end{equation}\]표준 VQ 방법과 비교할 때, 하나의 벡터를 quantize하기 위해 $D$개의 코드를 사용하여 더 세밀한 근사화와 더 큰 feature space를 허용한다. 멀티모달 학습 및 inference 중에 LLM은 코드 임베딩만 예측하면 되고, depth transformer가 코드 임베딩을 초기 입력으로 사용하여 순차적으로 다른 깊이의 코드를 생성한다. 따라서 이 지연 시간을 거의 발생시키지 않으면서 vision tower의 표현 능력을 향상시킬 수 있다.
2. Unified multi-modal Generative Pre-training
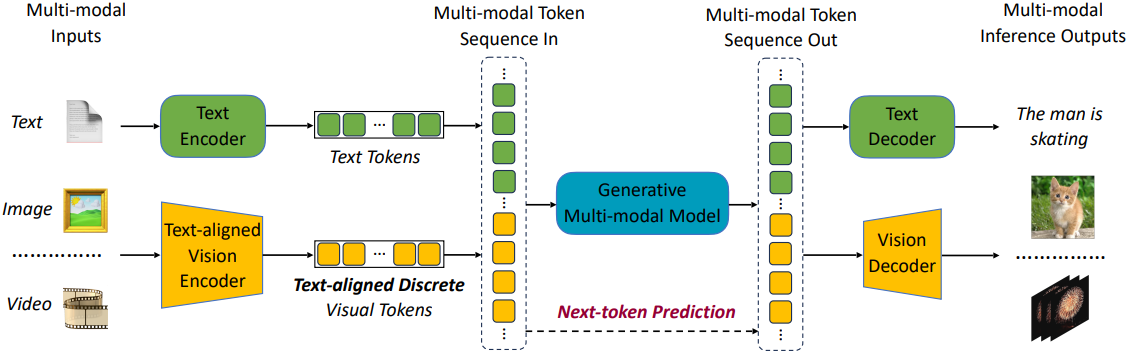
Vision tower 인코더는 시각적 입력을 순차적으로 처리하여 1D 토큰 시퀀스를 생성한다. 그런 다음, 이 시퀀스를 텍스트 토큰과 concat하여 멀티모달 시퀀스를 형성한다.
모달리티를 구별하고 시각적 콘텐츠 생성을 가능하게 하기 위해 특수 토큰을 삽입한다. 이미지 토큰의 시작과 끝에
사전 학습 데이터 형식
텍스트 토큰과 비주얼 토큰 간의 다양한 concat 형태를 활용하여 이해와 생성을 모두 용이하게 한다. 구체적으로, [image, text], [text, image], [text, video]의 형태를 사용하며, unconditional한 콘텐츠 생성을 피하고 모달리티 정렬을 촉진하기 위해 각 쌍에서 후자의 모달리티에만 loss를 추가한다. 또한 시각적 이해를 높이기 위해, [image, text, image, text, …]와 같은 interleaved 형태도 사용하며, loss는 텍스트에만 적용된다. 특히, 효율성을 위해 사전 학습 중에는 [video, text]를 제외하였으며, [video, text]는 supervised fine-tuning에만 사용된다.
학습 loss
비주얼 토큰과 텍스트 토큰은 모두 discrete하므로 일반적인 언어 모델링에 사용되는 next-token prediction loss로 LLM을 학습시킬 수 있다. 그러나 비주얼 토큰에 대한 residual VQ를 사용하기 때문에, 텍스트 토큰과 비주얼 토큰에 대한 학습 loss는 약간 다르다. 텍스트 토큰의 경우, negative log-likelihood loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{text} = - \sum_{i=1}^T \log P_\theta (y_i \vert y_{< i}) \end{equation}\]($T$는 멀티모달 시퀀스의 길이, $i$는 텍스트 토큰이 위치 $i$에 나타날 때만 계산됨)
비주얼 토큰의 경우, residual VQ는 각 위치 $j$에 대해 깊이에 따른 코드들이 생긴다. 이를 해결하기 위해, RQ-VAE에 도입된 depth transformer를 활용한다. 구체적으로, 위치 $j$에 있는 비주얼 토큰에 대해 LLM에서 생성한 코드 임베딩 $h_j$가 주어지면, depth transformer는 $D$개의 residual 토큰 $(k_{j1}, \ldots, k_{jD})$을 autoregressive하게 예측한다.
깊이 $d$에서 depth transformer의 입력 $v_{jd}$는 $d > 1$에 대해 깊이 $d−1$까지의 코드 임베딩의 합으로 정의된다.
\[\begin{equation} v_{jd} = \sum_{d^\prime = 1}^{d-1} \textbf{e} (k_{jd^\prime}), \quad v_{j1} = h_j \end{equation}\]따라서 depth transformer는 $d−1$까지의 이전 추정을 기반으로 feature \(\bar{z}_j\)의 더 정밀한 추정을 위해 다음 코드를 예측한다. 비주얼 토큰에 대한 negative log-likelihood loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{visual} = - \sum_{j=1}^T \sum_{d=1}^D \log P_\delta (k_{jd} \vert k_{j, < d}) \end{equation}\]($T$는 멀티모달 시퀀스의 길이, $j$는 비주얼 토큰이 위치 $j$에 나타날 때만 계산됨)
멀티모달 사전 학습 시, depth transformer의 가중치는 랜덤하게 초기화되고 LLM과 함께 업데이트된다.
Experiments
- 데이터셋: COYO-700M, ShareGPT4V, MMC4, OpenVid
- 구현 디테일
- base LLM: LLaMA-2-7B
- 비전 인코더: SigLIP-Large-patch16-256 / SigLIP-SO400M-patch14-384
- codebook 크기: 16,384
- residual VQ
- 이미지: 256$\times$256 $\rightarrow$ 16$\times$16$\times$4 ($D$ = 4)
- 동영상: 384$\times$384 $\rightarrow$ 27$\times$27$\times$16 ($D$ = 16)
- classifier-free guidance: CFG weight = 3
1. Unified Foundation Vision Tower
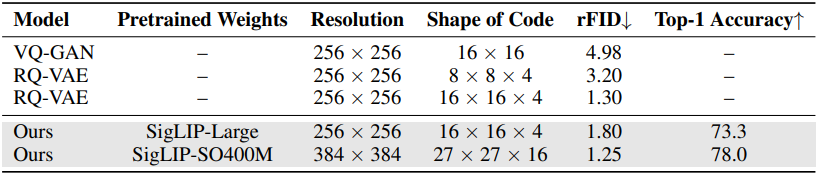
다음은 vision tower의 reconstruction FID (rFID)와 ImageNet classification에 대한 top-1 accuracy를 비교한 표이다.
2. Quantitative Evaluation
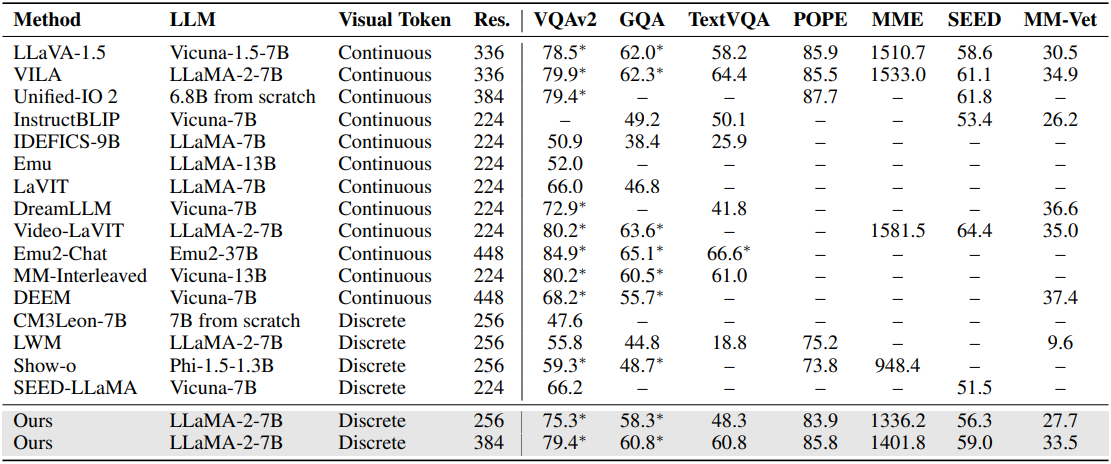
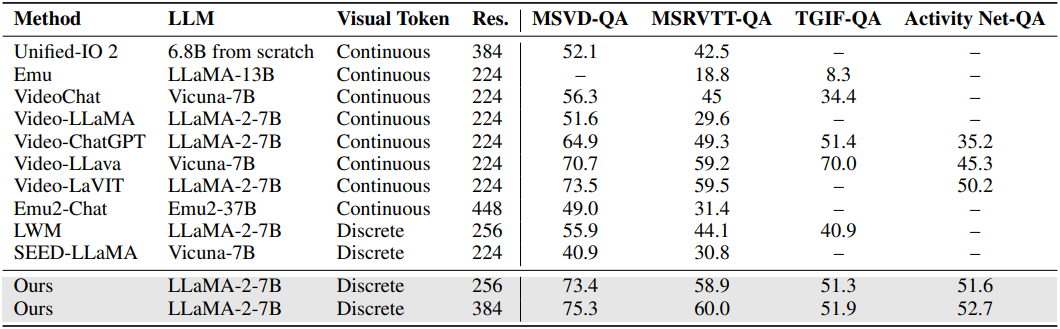
다음은 (위) 이미지-언어 벤치마크와 (아래) 동영상-언어 벤치마크에 대한 평가 결과이다.
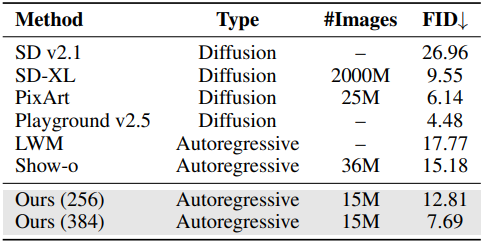
다음은 MJHQ-30K에서 이미지 생성 품질을 비교한 표이다.
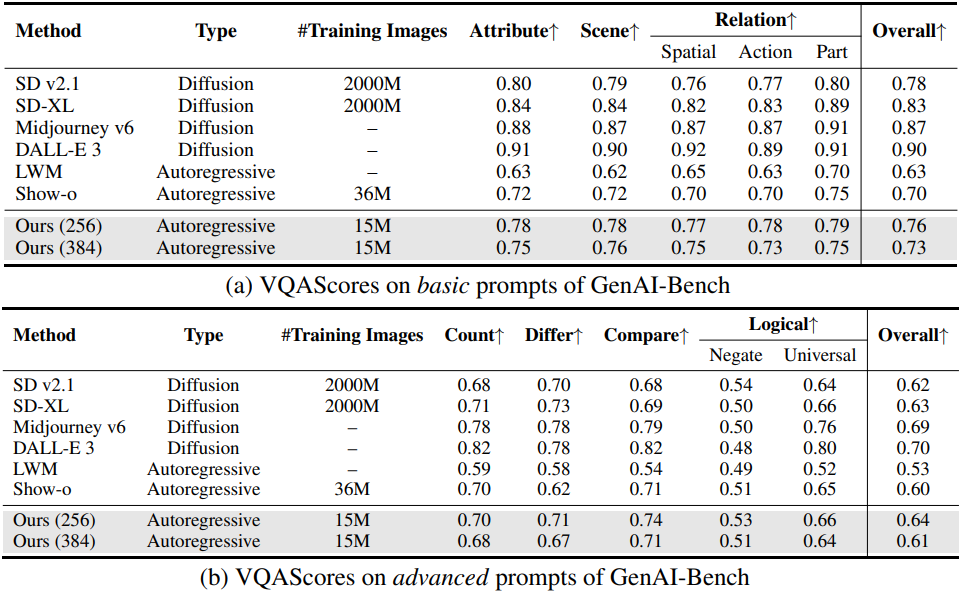
다음은 GenAI-Bench에서 이미지 생성 품질을 비교한 표이다.
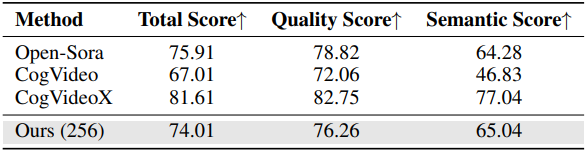
다음은 VBench에서 동영상 생성 품질을 비교한 표이다.
3. Qualitative Evaluation
다음은 동영상 캡션 생성의 예시이다.

다음은 VQA의 예시이다.

다음은 in-context learning의 예시이다.

다음은 여러 이미지들에 대한 추론의 예시이다.

다음은 주어진 텍스트 입력에 대한 고해상도 이미지 및 동영상 생성 예시이다.

4. Ablation Study
다음은 contrastive loss에 대한 ablation 결과이다. (위: 시각적 이해, 아래: 이미지 생성)


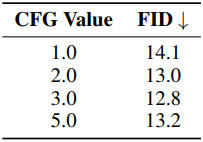
다음은 CFG에 대한 ablation 결과이다.