[논문리뷰] VideoPrism: A Foundational Visual Encoder for Video Understanding
ICML 2024. [Paper] [Blog]
Long Zhao, Nitesh B. Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J. Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, Rachel Hornung, Florian Schroff, Ming-Hsuan Yang, David A. Ross, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Ting Liu, Boqing Gong
20 Feb 2024

Introduction
동영상은 다양한 도메인에 걸쳐 있는 현실 경험의 풍부하고 역동적인 아카이브이다. Video foundation model은 이 광대한 코퍼스 내에서 새로운 통찰력을 끌어낼 엄청난 잠재력을 가지고 있다. 이전 연구들은 일반적인 동영상 이해를 향해 큰 진전을 이루었지만 video foundation model을 구축하는 것은 여전히 어렵다. 기존 모델들은 종종 외관 중심 추론과 모션 중심 추론의 균형을 맞추는 데 어려움을 겪으며 많은 벤치마크에서 task에 맞춰진 전문 모델보다 뒤처진다.
본 논문은 classification, localization, retrieval, captioning, QA를 포함한 광범위한 동영상 이해 task를 처리하도록 설계된 범용 동영상 인코더인 VideoPrism을 소개한다. 컴퓨터 비전 데이터셋과 과학 도메인 데이터셋에서 광범위하게 평가된 VideoPrism은 하나의 고정 모델을 사용하여 최소한의 적응으로 SOTA 성능을 달성하였다.
사전 학습 데이터는 foundation model의 기반이 되며 이상적인 사전 학습 데이터는 전 세계 모든 동영상의 대표 샘플일 것이다. 이 샘플의 대부분 동영상은 콘텐츠를 설명하는 텍스트가 없거나 매우 잡음이 많다. 설명하는 텍스트가 있는 경우 동영상 공간에 대한 귀중한 semantic 단서를 제공한다. 따라서 사전 학습 전략은 주로 동영상 모달리티에 초점을 맞추면서도 사용 가능한 동영상-텍스트 쌍을 최대한 활용해야 한다.
데이터 측면에서, 저자들은 3,600만 개의 고품질 동영상-캡션 쌍과 잡음이 있는 텍스트 (ex. 자동 음성 인식 기술로 생성한 텍스트, LMM으로 생성된 캡션, 검색된 텍스트)가 있는 5.82억 개의 동영상 클립을 조립하여 원하는 사전 학습 코퍼스를 근사하였다.
모델링 측면에서, 먼저 다양한 품질의 모든 동영상-텍스트 쌍에서 contrastive training으로 semantic video embedding을 학습시킨다. 그런 다음, masked video modeling을 개선하여 semantic embedding을 글로벌하게 토큰별로 추출하여 광범위한 동영상 전용 데이터를 활용한다.
NLP에서는 masked language modeling이 성공을 거두었지만, 컴퓨터 비전 분야에서는 시각 신호에 semantic이 없기 때문에 여전히 어려운 과제이다. 저자들은 사전 학습 데이터에 맞게 조정된 2단계 접근 방식을 구축하였다.
먼저 contrastive loss를 사용하여 동영상-텍스트 쌍을 통해 동영상 인코더와 페어링된 텍스트 인코더를 학습시킨다. 다음으로 두 가지 개선 사항을 적용하여 masked video modeling을 통해 모든 동영상 전용 데이터에서 인코더를 계속 학습시킨다.
- 모델은 마스킹되지 않은 입력 동영상 패치를 기반으로 첫 번째 단계의 동영상 레벨의 글로벌 임베딩과 토큰별 임베딩을 모두 예측해야 한다.
- 인코더의 출력 토큰에 랜덤 셔플을 적용하여 디코더로 전달하기 전에 shortcut 학습을 방지한다.
특히 사전 학습은 동영상의 텍스트 설명과 contextual self-supervision이라는 두 가지 supervision 신호를 사용하여 VideoPrism이 외관 중심 task와 모션 중심 task에서 모두 잘 작동하도록 한다.
Approach
1. Pretraining data

사전 학습 데이터는 고품질의 수동 레이블이 있는 3,600만 개의 클립 (Anonymous-Corpus #1)과, 잡음이 있는 병렬 텍스트가 있는 5.82억 개의 클립 (WTS-70M ~ Anonymous-Corpus #3)으로 구성되어 있다.
Anonymous-Corpus #1은 video foundation model에 대한 데이터셋 중 가장 크지만 이미지 foundation model에 사용되는 이미지-텍스트 데이터보다 여전히 규모가 작다. 따라서 자동 음성 인식, 메타데이터, LMM 등을 통해 생성된 잡음이 있는 텍스트를 사용하여 대규모 동영상-텍스트 데이터도 수집하였다. 중요한 점은 이전 연구들과 달리, 사전 학습을 위해 Kinetics와 같은 평가 벤치마크의 학습 세트를 통합하지 않는다는 것이다. 이러한 선택은 특정 평가 벤치마크에 대하여 모델이 지나치게 튜닝되는 것을 방지한다.
2. Model architecture
VideoPrism 모델 아키텍처는 ViT를 기반으로 하며, ViViT를 따라 공간과 시간으로 인수분해된 설계를 채택하였다. 그러나 공간 인코더 바로 뒤에 있는 ViViT의 global average pooling layer를 제거하여 출력 토큰 시퀀스에 시공간 차원을 남기고 세밀한 feature가 필요한 다운스트림 task를 용이하게 한다.
본 논문에서는 VideoPrism-g와 VideoPrism-B의 두 가지 모델 구성을 실험하였다. VideoPrism-g는 공간 인코더에 10억 개의 파라미터가 있는 ViT-giant 네트워크이고, VideoPrism-B는 ViT-Base 네트워크를 사용하는 더 작은 모델이다.
3. Training algorithm
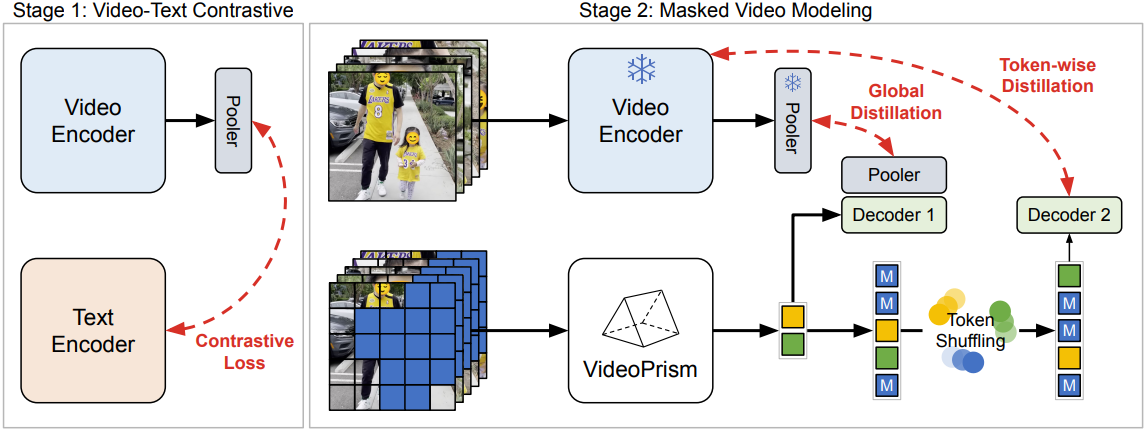
본 논문의 목표는 동영상-텍스트 쌍과 큐레이팅한 동영상 전용 데이터를 모두 활용하여 VideoPrism을 확장 가능하게 학습시키고, VideoPrism을 동영상에서 외관과 모션 semantic을 모두 캡처할 수 있는 동영상 인코더로 만드는 것이다. 대규모 사전 학습 데이터의 텍스트는 대부분의 동영상에서 매우 잡음이 많기 때문에 동영상-텍스트에만 의존하기보다는 동영상 전용 모달리티를 사용한다. VideoPrism의 학습 파이프라인은 동영상-텍스트 contrastive training과 masked video modeling의 두 단계로 구성된다.
Stage 1: Video-text contrastive training
Stage 1에서는 모든 동영상-텍스트 쌍을 사용하여 동영상 인코더를 텍스트 인코더에 맞추기 위해 contrastive training을 수행한다. 기존 연구들을 따라 mini-batch에서 모든 동영상-텍스트 쌍의 유사도 점수에 대한 대칭적 cross-entropy loss를 최소화한다. CoCa의 이미지 모델을 사용하여 공간 인코더를 초기화하고 WebLI를 사전 학습에 포함한다. 동영상 인코더의 feature는 loss 계산 전에 multi-head attention pooler (MAP)를 통해 집계된다. 이 단계에서는 동영상 인코더가 텍스트에서 풍부한 semantic을 학습할 수 있으며, 결과 모델은 Stage 2 학습을 위한 semantic video embedding을 제공한다.
Stage 2: Masked video modeling
Stage 1에서처럼 동영상-텍스트 데이터만을 사용하여 학습하는 것은 한계점이 있다. 텍스트 설명은 잡음이 많고, 종종 모션보다 외관을 더 잘 포착한다. 이를 해결하기 위해 Stage 2에서는 동영상 전용 데이터에서 외관과 모션 정보를 모두 학습하는 데 중점을 둔다. 모션 이해를 위해 masked autoencoding을 적용하는 동시에 모델이 Stage 1에서 습득한 semantic 지식을 유지하도록 한다.
Stage 2에서는 개선된 masked video modeling을 사용하여 동영상 전용 데이터에서 동영상 인코더를 계속 학습시킨다. 개선 사항은 두 가지이다.
- 디코딩 shortcut을 방지하기 위한 새로운 토큰 셔플링 방식
- Stage 1에서 습득한 지식을 효과적으로 활용하기 위한 글로벌 및 토큰별 distillation loss
Stage 2 모델 (student)은 마스킹된 동영상을 기반으로 모든 토큰의 Stage 1 모델 (teacher)의 임베딩을 예측하는 방법을 학습한다. 인코더-디코더 Transformer는 MAE의 설계를 따라 분리된다.
Token shuffling
Stage 1 모델로 Stage 2 모델을 초기화할 때 발생하는 한 가지 문제는 모델이 마스킹되지 않은 토큰을 복사 붙여넣기 할 수 있는 shortcut을 디코더에 만들어 모든 토큰을 예측하는 것보다 쉬운 task로 만든다는 것이다. 이 문제를 해결하기 위해 인코더에서 출력한 토큰 시퀀스를 디코더에 공급하기 전에 무작위로 섞고 디코더는 섞인 시퀀스에 위치 임베딩을 추가한다. 이 셔플링 연산은 디코더가 잠재적으로 탐색할 수 있는 마스킹되지 않은 토큰의 복사 붙여넣기 shortcut을 피한다. 또한 디코더가 마스킹된 토큰을 예측하는 동안 마스킹되지 않은 토큰에 대한 직소 퍼즐을 푸는 것과 유사하다고 볼 수도 있다.
Global-local distillation
이미지에 대한 masked distillation과 달리, masked modeling loss만 활용했을 때 외관이 중요한 task에서 Stage 2 모델이 Stage 1 모델보다 성능이 떨어지는데, 이는 아마도 2단계 사전 학습에서의 catastrophic forgetting 때문일 것이다. 이 문제를 완화하기 위해, Stage 2 모델이 보이는 토큰을 사용하여 Stage 1 모델로부터 전체 동영상의 글로벌 임베딩을 distillation하도록 추가 loss를 도입한다. 따라서 Stage 2 학습 loss는 토큰별 masked video modeling과 글로벌 distillation을 결합한다.
Experiments
1. Classification and spatiotemporal localization
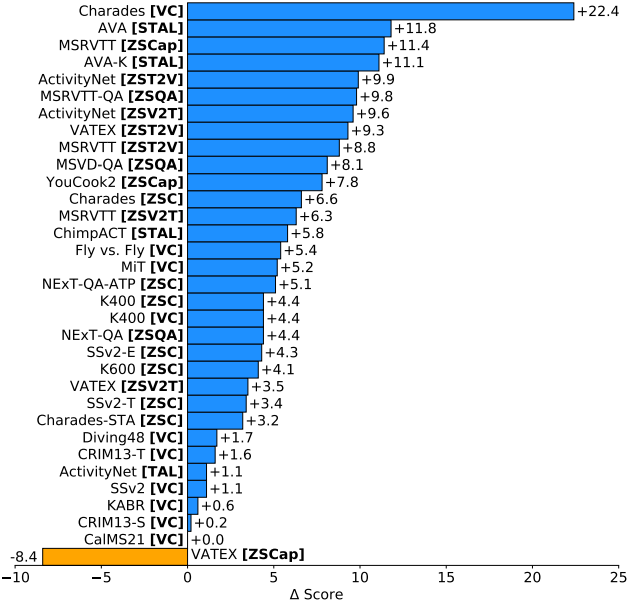
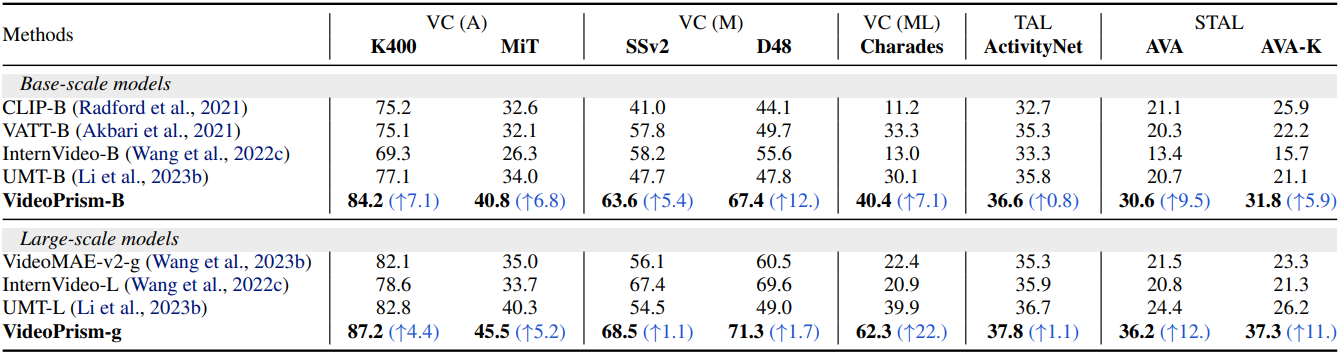
다음은 VideoGLUE 벤치마크에서 기존 foundation model과 비교한 표이다. Video classification (VC)은 top-1 accuracy를 비교하였으며, temporal localization (TAL)과 spatiotemporal localization (STAL)은 mean average precision (mAP)를 비교하였다. (A)는 외관 중심, (M)은 모션 중심, (ML)은 multi-label을 뜻한다.
2. Zero-shot video-text retrieval and classification
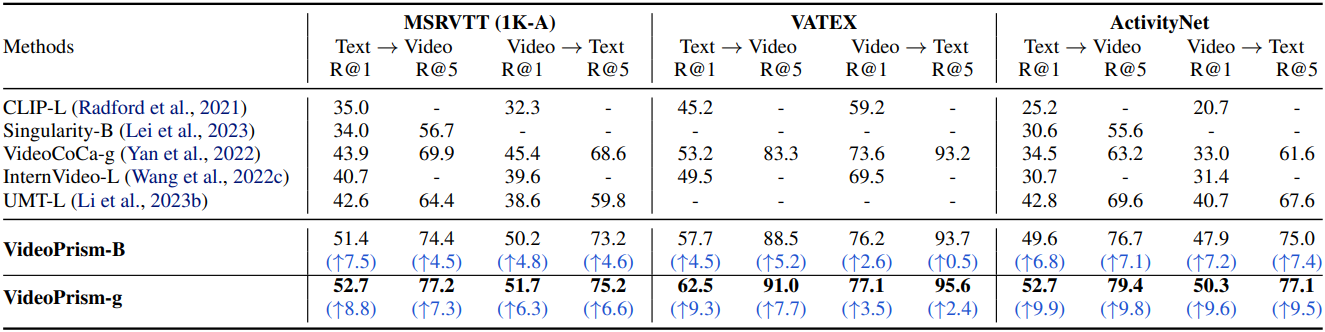
다음은 zero-shot 동영상-텍스트 검색 성능을 비교한 표이다. Recall@1 (R@1)과 Recall@5 (R@5)를 비교하였다.
다음은 zero-shot video classification 성능을 SOTA와 비교한 표이다.
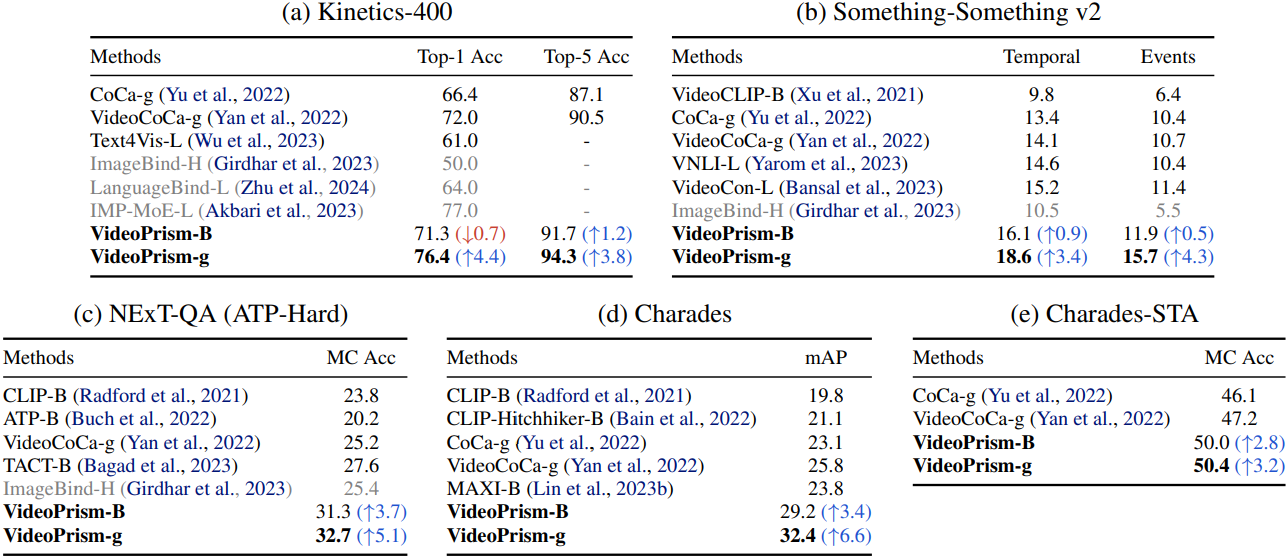
3. Zero-shot video captioning and QA
다음은 zero-shot video captioning 성능을 SOTA와 비교한 표이다. 모든 벤치마크에서 CIDEr를 비교하였다.

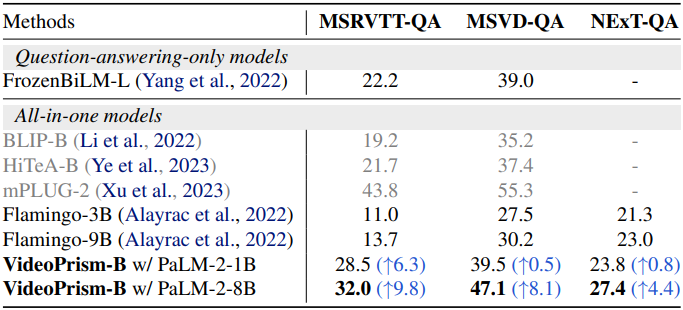
다음은 zero-shot video QA 성능을 SOTA와 비교한 표이다. NExT-QA는 WUPS index를 비교하였고, 나머지는 top-1 accuracy를 비교하였다.
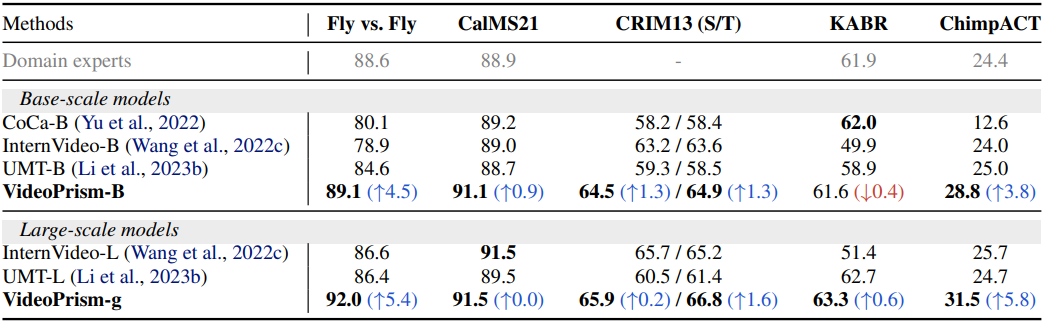
4. CV for science tasks
다음은 과학 벤치마크에서 SOTA와 비교한 표이다. KABR는 macro-accuracy를 비교하였고, 나머지는 mAP를 비교하였다.
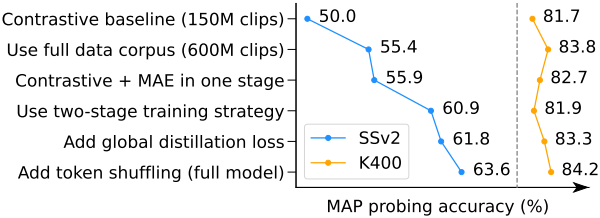
5. Ablation study
다음은 ablation study 결과이다.
Limitations
- 사전 학습의 일부로 잡음이 있는 텍스트가 있는 동영상 데이터를 활용한다. 이 잡음이 있는 텍스트는 잠재적으로 불완전하고 편향되어 모델 성능에 영향을 미칠 수 있다.
- 긴 동영상 이해는 여전히 어렵다. VideoPrism은 입력으로 16개 프레임을 샘플링하는 짧은 동영상에 초점을 맞추고 있다.
- 고정된 backbone 평가를 사용하였지만, end-to-end fine-tuning과 parameter-efficient adaptation에서 더 많은 이점을 얻는 시나리오가 있다.