[논문리뷰] VideoPoet: A Large Language Model for Zero-Shot Video Generation
ICML 2024. [Paper] [Page]
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, Krishna Somandepalli, Hassan Akbari, Yair Alon, Yong Cheng, Josh Dillon, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, Mikhail Sirotenko, Kihyuk Sohn, Xuan Yang, Hartwig Adam, Ming-Hsuan Yang, Irfan Essa, Huisheng Wang, David A. Ross, Bryan Seybold, Lu Jiang
Google DeepMind
21 Dec 2023
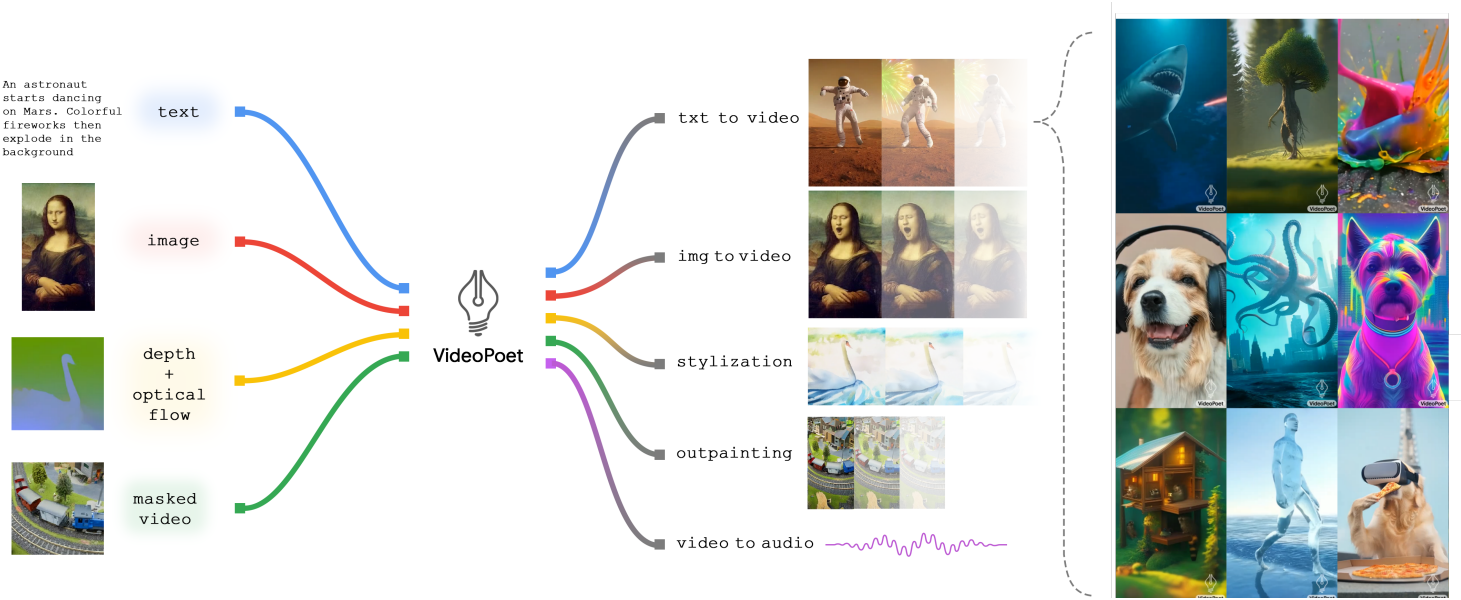
Introduction
동영상 생성에 LLM을 사용하는 것의 주목할 만한 이점은 기존 LLM 프레임워크를 쉽게 통합할 수 있다는 것다. 이 통합을 통해 LLM 인프라를 재사용할 수 있으며, 수년간 LLM을 위해 개발한 최적화를 활용할 수 있다. 여기에는 모델 스케일링, 학습 및 inference 인프라, 하드웨어를 위한 학습 레시피의 최적화가 포함된다. 이는 동일한 모델에서 다양한 task를 인코딩하는 데 있어서의 유연성과 결합된다.
본 논문에서는 동영상 생성을 위해 언어 모델을 활용하며, 언어 도메인에서의 LLM의 표준 학습 프로토콜을 따른다. 본 논문은 동영상 생성을 위한 언어 모델인 VideoPoet을 소개한다. VideoPoet은 이미지, 동영상, 오디오를 개별 토큰으로 하는 디코더 전용 LLM 아키텍처를 사용하며, 각각은 해당 tokenizer에서 생성된다.
VideoPoet의 학습 과정은 사전 학습과 task-adaptation의 두 단계로 구성된다. 사전 학습 중에는 autoregressive transformer 프레임워크 내에서 멀티모달 사전 학습 목적 함수들을 통합한다. 사전 학습 후 모델은 text-to-video, image-to-video, 동영상 편집, video-to-video stylization과 같은 multi-task 동영상 생성 모델로 사용된다. 이러한 능력은 텍스트 프롬프트에 의해 제어되는 별도의 생성 모델에 의존하지 않고 단일 LLM에 본질적으로 통합된다. Task-adaptation 중에 사전 학습된 모델은 생성 품질을 향상시키거나 새로운 task를 수행하기 위해 추가로 fine-tuning될 수 있다.
VideoPoet은 충실도가 높고 큰 모션을 가진 동영상을 생성하는 데 SOTA 능력을 보여준다. Transformer 아키텍처의 강력한 능력을 통해 VideoPoet은 multi-task, 멀티모달 목적 함수에 대해 간단하게 학습할 수 있어 텍스트나 다른 프롬프트에 의해 구동되는 일관되고 사실적인 모션을 생성할 수 있다. 또한 VideoPoet은 생성된 동영상의 마지막 부분을 조건으로 콘텐츠를 autoregressive하게 확장하여 최대 10초의 일관된 긴 동영상을 합성할 수 있다.
또한 VideoPoet은 zero-shot 동영상 생성이 가능하다. 여기서 “zero-shot”은 학습 데이터 분포에서 벗어나는 새로운 텍스트, 이미지, 동영상 입력을 처리함을 의미한다. 나아가 VideoPoet은 학습에 포함되지 않은 새로운 task를 처리할 수 있다. 예를 들어, VideoPoet는 task를 순차적으로 연결하여 새로운 편집 task를 수행할 수 있다.
Model Overview
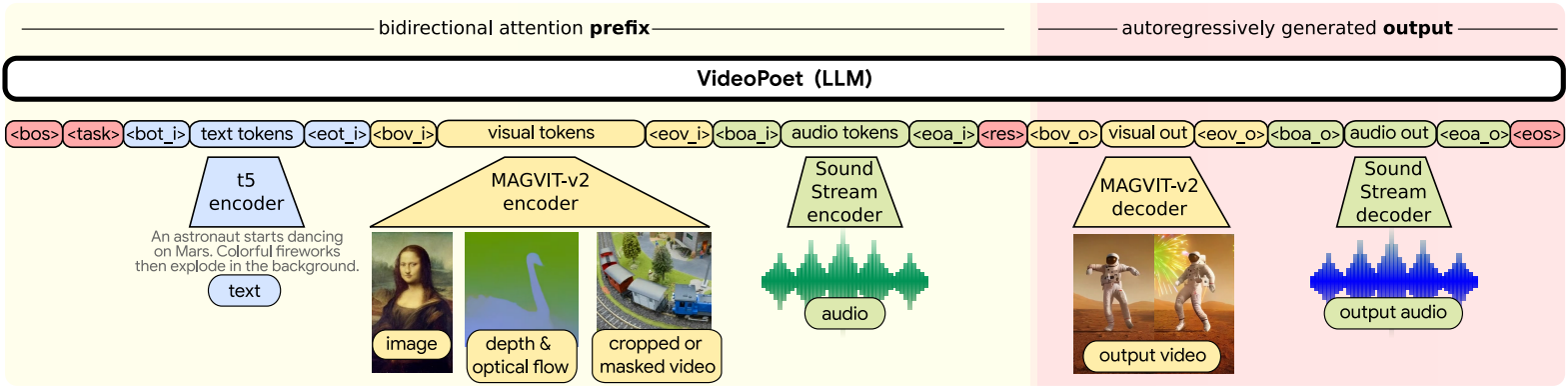
VideoPoet은 세 가지 구성요소로 구성된다.
- Modality별 tokenizer: 입력 데이터 (이미지 픽셀, 동영상 프레임, 오디오 파형)를 통합 vocabulary에 대한 discrete한 토큰으로 매핑한다. 비주얼 토큰과 오디오 토큰은 정수 시퀀스로 flatten된다.
- 언어 모델 backbone: 매핑된 토큰들을 텍스트 임베딩과 함께 입력으로 받고 multi-task 및 멀티모달 모델링을 담당한다. 텍스트 임베딩, 비주얼 토큰, 오디오 토큰을 조건으로 비주얼 토큰과 오디오 토큰을 autoregressive하게 예측한다.
- Super-resolution 모듈: 더 높은 품질을 위해 시각적 디테일을 정제하고 동영상 출력의 해상도를 높인다.
1. Tokenization
이미지와 동영상 tokenization을 위해 MAGVIT-v2 tokenizer를 사용하고, 오디오 tokenization을 위해 SoundStream tokenizer를 사용한다.
Image and video tokenizer
MAGVIT-v2 tokenizer는 높은 시각적 품질을 가졌을 뿐만 아니라 압축 능력이 좋아 LLM의 시퀀스 길이를 줄일 수 있다. 동영상 클립은 정수 시퀀스로 인코딩되며, 디코더는 이를 픽셀 공간으로 다시 매핑한다. MAGVIT-v2는 8fps로 샘플링된 17프레임 (2.125초)의 128$\times$128 해상도 동영상을 tokenize하여 $(5, 16, 16)$ 모양의 latent를 생성한 다음 이를 $2^{18}$의 vocabulary 크기를 갖는 1,280개의 토큰으로 flatten한다. 또한 동영상을 128$\times$224 해상도의 세로 종횡비로 tokenize하여 $(5, 28, 16)$ 모양의 latent를 생성한 다음 2,240개의 토큰으로 flatten한다.
더 긴 동영상 생성을 용이하게 하는 인과적 시간 종속성을 적용한다. 이미지와 동영상을 공동으로 표현하기 위해 동영상 또는 정적 이미지의 초기 프레임을 일관된 $(1, 16, 16)$ 모양의 토큰으로 인코딩한다. Inpainting과 outpainting task는 MAGVIT의 COMMIT 인코딩 체계를 사용하여 tokenize된다.
Audio tokenizer
SoundStream tokenizer는 2.125초의 오디오를 임베딩하여 4단계의 residual vector quantizer (RVQ)가 있는 106개의 latent 프레임을 생성한다. RVQ 표현으로 오디오 토큰을 예측하는 데는 두 가지 가능한 선택지가 있다.
- 낮은 RVQ 레벨에서 높은 RVQ 레벨까지 전체 오디오 클립을 순차적으로 예측
- 하나의 오디오 토큰에 대한 모든 RVQ 레벨을 동시에 예측
저자들의 실험에 따르면 전자의 방법이 후자의 방법보다 약간 유리하다고 한다. 각 RVQ 레벨은 분리된 vocabulary가 있으며 각 레벨에는 1,024개의 코드가 있다. 따라서 결합된 오디오 vocabulary 크기는 4,096개의 코드가 된다.
Text embedding as input
일반적으로 사전 학습된 텍스트 표현은 처음부터 텍스트 토큰을 학습하여 모델을 학습하는 것보다 성능이 뛰어나다. 저자들은 고정된 T5 XL 인코더에서 사전 학습된 언어 임베딩을 사용한다. Text-to-video와 같이 텍스트 guidance가 있는 task의 경우 T5 XL 임베딩은 linear layer를 통해 transformer의 embedding space에 projection된다.
2. Language Model Backbone
이미지, 동영상, 오디오를 공유 vocabulary 내에서 discrete한 토큰으로 변환한 후, 언어 모델을 직접 활용하여 token space에서 동영상과 오디오를 생성할 수 있다. Backbone으로 디코더 전용 아키텍처를 갖춘 prefix language model을 사용한다. 학습 중에 다양한 패턴의 입력 토큰을 출력 토큰으로 구성함으로써, 모델이 수행할 수 있는 task를 제어할 수 있다.
3. Super-Resolution
고해상도(HR) 동영상을 autoregressive하게 생성하려면 시퀀스 길이가 늘어나기 때문에 많은 계산 비용이 필요하다. 동영상 tokenizer는 17$\times$896$\times$512 동영상에서 작동하여 35,840개의 토큰 시퀀스를 생성하므로 autoregressive 샘플링이 매우 비실용적이다.
저자들은 효율적이고 고품질의 동영상 업샘플링을 위해 언어 모델의 token space에서 작동하는 커스텀 MAGVIT를 개발했다. Self-attention layer의 시퀀스 길이의 제곱에 비례하는 메모리를 완화하기 위해 windowed local attention이 통합되었다.
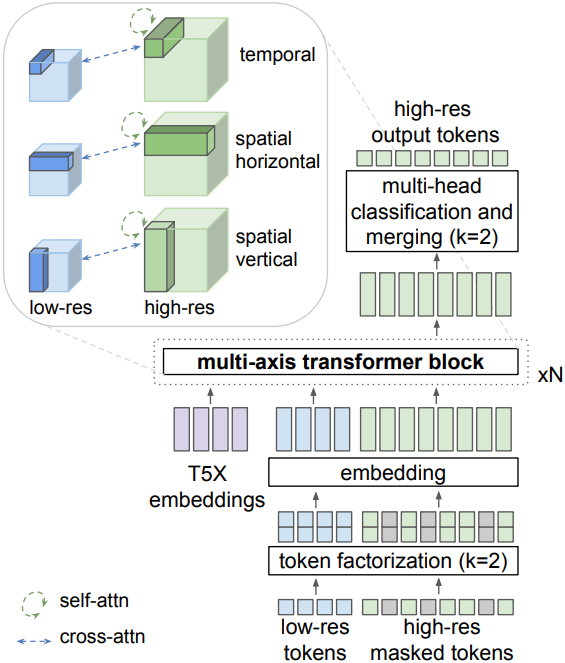
구체적으로, SR transformer는 세 개의 transformer layer block으로 구성되며, 각 레이어는 공간적 수직 공간적 수평, 시간 축 중 하나에 맞춰진 local window에서 self-attention을 수행한다. Cross-attention layer는 저해상도(LR) 토큰 시퀀스에 attention되고 local window로 나뉘며, self-attention layer의 window와 동일한 모양이다. 모든 block에는 텍스트 임베딩에 대한 cross-attention도 포함된다. 커스텀 MAGVIT의 아키텍처는 위 그림과 같다.
더 큰 vocabulary 크기를 설명하기 위해, MAGVIT-v2를 따르고 $k = 2$ factor의 token factorization을 사용하여 SR transformer를 학습시킨다. 이는 262, 144-way classification 문제를 두 개의 512-way classification 문제로 변환한다. LR 토큰 시퀀스는 GT 동영상의 bicubic 다운샘플링 버전을 tokenize하고 discrete한 latent space에 noise augmentation을 적용하여 실제 동영상과 생성된 동영상 간의 분포 불일치를 완화한다. 특히, LR 토큰의 랜덤한 부분집합의 값을 무작위로 리샘플링하고 학습 샘플의 10%에 대해 LR 조건과 텍스트 임베딩을 독립적으로 제거한다. Inference 시에는 LR 조건과 텍스트 임베딩 모두에 대해 classifier-free guidance를 사용한 non-autoregressive sampling을 사용한다. VideoPoet의 224$\times$128 기본 출력에서 896$\times$512 해상도의 동영상을 생성하기 위해 두 개의 2$\times$의 cascade를 사용한다.
LLM Pretraining for Generation
1. Task Prompt Design
저자들은 다음과 같은 사전 학습 task들을 설계하였으며, 각 task는 미리 정의된 입출력 prefix를 갖는다.
- Unconditioned video generation
- Text-to-video (T2V)
- Video future prediction (FP)
- Image-to-video (I2V)
- Video inpainting/outpainting (Painting)
- Video stylization
- Audio-to-video
- Video-to-audio
- Audio-video continuation (AVCont)
모델은 prefix로 컨디셔닝되며, loss는 출력에만 적용된다. 각 task의 경우 입력 시퀀스에는 텍스트 임베딩(T5), 비주얼 토큰(MAGVIT-v2), 오디오 토큰(SoundStream)의 세 가지 유형의 값이 포함될 수 있다. 모델은 비주얼 토큰과 오디오 토큰의 두 가지 유형의 토큰을 출력한다. VideoPoet은 학습을 용이하게 하기 위해 특수 토큰을 사용한다.
Task 유형을 나타내기 위해, 각 고유한 출력에 대해 고유한 값을 갖는 <task> 토큰으로 컨디셔닝한다. 모든 task에 독립적인 <task>가 필요한 것은 아니다. 모델은 동일한 출력에 대해 다른 컨텍스트 신호에 적응한다. 예를 들어, T2V, I2V, Unconditioned video generation은 동일한 <task>를 공유한다. Task에 특정 modality가 없는 경우 관련된 입출력 토큰과 특수 토큰이 제외되어 시퀀스가 단축된다.
이미지를 동영상으로 표현
Text-to-image 사전 학습 시 입력 시퀀스에서 <eos>와 <eov_o> 토큰을 생략하여 더 긴 동영상의 추론을 위한 지속적인 토큰 생성을 가능하게 한다. 이 접근 방식은 동영상과 이미지 생성 task 간의 경계를 모호하게 만들어 modality 사이의 정보 공유를 향상시킨다. 이 디자인은 더 높은 품질의 초기 프레임을 예측하고 후속 프레임의 아티팩트를 줄인다.
동영상 토큰 형식
128$\times$128과 128$\times$224의 두 가지 해상도로 동영상 토큰을 생성하며, 각각 17프레임과 41프레임의 두 가지 길이로 제공되고 둘 다 8 FPS로 인코딩된다. 특수 컨디셔닝 토큰은 원하는 해상도와 길이로 컨디셔닝하는 데 사용된다. 이미지는 128$\times$128 해상도로 tokenize하는 프레임이 하나인 동영상의 특수한 경우이다.
Video stylization
Video stylization의 경우, 학습 시에는 주어진 optical flow, 깊이, 텍스트 정보로부터 GT 동영상을 재구성하는 것이 목표이다. 하지만, inference 시에는 입력 동영상에 optical flow와 깊이 추정을 적용한 다음, 텍스트 프롬프트를 변경하여 새로운 스타일을 생성한다. 텍스트는 출력 컨텐츠 또는 외형을 가이드하는 반면, optical flow와 깊이 정보는 구조를 가이드한다.
2. Training Strategy
다양한 길이의 동영상을 학습시키기 위해 Alternating Gradient Descent (AGD)을 사용한다. 구체적으로, 시퀀스 길이에 따라 task를 그룹화하고 각 iteration에서 한 그룹을 번갈아 샘플링한다. 시퀀스 길이는 고정되어 있고 task 간에 상당히 다르기 때문에 최소한의 패딩으로 효율적인 학습이 가능하다.
시간에 따라 균일하게 이미지 및 동영상 데이터셋에서 샘플링하면 최적이 아닌 결과가 나올 수 있다. 이미지에 대한 학습은 물체에 대한 이해를 향상시킬 수 있지만 동영상 데이터의 모션을 포착하지 못하기 때문이다. 따라서 2단계 사전 학습 전략을 사용한다. 먼저, 학습의 처음 25% iteration에서 이미지 데이터를 90%의 시간 동안 샘플링하고 동영상 데이터를 10%의 시간 동안 샘플링한다. 그런 다음 나머지 iteration에서 동영상 90%, 이미지 10%로 전환한다.
저자들은 더 높은 품질의 데이터들을 사용하여 특정 task나 새로운 task 적응에 대한 향상된 성능을 위해 사전 학습된 모델을 fine-tuning하였다. 이러한 fine-tuning은 출력을 다양화할 뿐만 아니라 더 높은 classifier-free guidance scale을 사용할 수 있게 하여 전반적인 품질을 향상시킨다.
Experiments
- 데이터셋
- 이미지-텍스트 쌍 10억 개
- 동영상 2.7억 개
- 동영상-텍스트 쌍 1억 개
- fine-tuning 용 5천만 개
- 동영상-오디오 쌍 1.7억 개
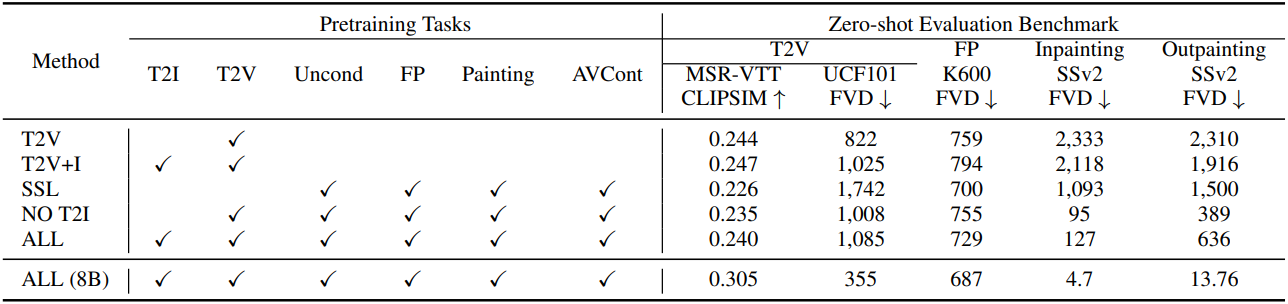
1. Pretraining Task Analysis
다음은 300M 모델에 대한 사전 학습 task 분석 결과이다. 상단 행은 일부 데이터로 학습된 300M 모델이며, 하단 행은 전체 데이터에서 학습된 8B 모델이다.
2. Comparison with the State-of-the-Art
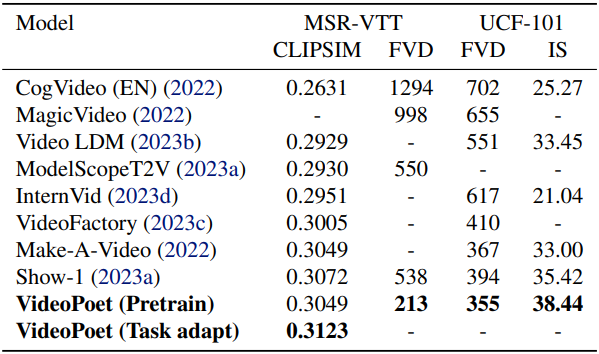
다음은 zero-shot text-to-video 성능을 기존 SOTA와 비교한 표이다.
다음은 text-to-video 생성에 대한 인간 평가 결과이다.

3. LLM’s Diverse Capabilities in Video Generation
다음은 10초 길이의 동영상 생성 예시이다.

다음은 정지 이미지를 애니메이션으로 변환한 예시이다.

다음은 task chaining을 통한 zero-shot 동영상 편집의 예시이다.

Limitations
- 압축된 토큰으로부터 RGB 프레임을 재구성하기 때문에 생성 모델의 시각적 충실도에 상한이 있다.
- 특히 큰 모션과 결합될 때 작은 물체와 세밀한 디테일은 토큰 기반 모델링 내에서 여전히 어렵다.