[논문리뷰] VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models
CVPR 2024. [Paper] [Page] [Github]
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, Ying Shan
Tencent AI Lab
17 Jan 2024

VideoCrafter1의 후속 논문
Introduction
Diffusion model을 사용한 동영상 생성은 특히 text-to-video (T2V) 생성 모델에서 획기적인 발전을 이루었다. 대부분의 기존 방법은 시간 모듈을 추가한 다음 동영상으로 학습시켜 text-to-image (T2I) backbone을 동영상 모델로 확장한다. 동영상 모델을 평가하는 데에는 화질, 모션 일관성, 개념 합성 등 다양한 측면을 고려해야 한다. 화질은 선명도, 잡음, 왜곡, 미적 점수 등과 같은 측면을 나타내며, 모션 일관성은 프레임과 모션 부드러움 간의 외관 일관성을 나타낸다. 개념 합성은 실제 동영상에서는 동시에 등장하지 않는 다양한 개념을 결합하는 능력이다.
최근 몇몇 스타트업에서는 최소한의 잡음, 뛰어난 디테일, 높은 미적 점수로 그럴듯한 동영상을 제작할 수 있는 T2V 모델을 출시했지만 학계에서는 얻을 수 없는 대규모의 잘 필터링된 고품질 동영상 데이터셋에 대해 학습을 받았다. 동영상 이해를 위해 인터넷에서 수집한 오픈소스 영상 데이터셋이 몇 가지 있지만 동영상 생성에는 화질이나 캡션이 좋지 않거나 한 동영상에 여러 클립이 들어가는 등 많은 문제가 존재한다. WebVid10M은 학계에서 동영상 생성 모델을 학습시키는 데 가장 널리 사용되는 데이터셋이다. 클립이 잘 분할되어 있고 다양성도 좋지만 화질이 만족스럽지 못하며 대부분의 동영상의 해상도가 320p 정도이다. 고품질 데이터셋이 부족하면 고품질 동영상 모델을 학습시키는 데 심각한 장애물이 된다.
본 논문에서는 고품질 동영상을 사용하지 않고 고품질 동영상 모델을 학습시키는 매우 어려운 문제를 목표로 한다. 저자들은 다양한 학습 전략 하에서 공간 모듈과 시간 모듈 사이의 연결을 분석하고 저품질 동영상으로의 분포 이동을 조사하기 위해 SD 기반 동영상 모델의 학습 과정을 탐구하였다. 저자들은 모든 모듈을 동시에 학습시키면 단순히 시간 모듈을 학습시키는 것보다 외관과 모션 사이의 결합이 더 강력해진다는 것을 발견했다. 이러한 full training을 통해 보다 자연스러운 모션을 달성하고 공간 모듈의 추가 수정을 허용할 수 있으며, 이는 생성된 동영상의 품질을 향상시키는 핵심이다.
본 논문은 이 관찰을 바탕으로 데이터 레벨에서 모션과 외관을 분리하여 데이터 한계를 극복하는 방법을 제안하였다. 고화질 영상 대신 저화질 영상을 활용해 모션의 일관성을 보장하고, 고화질 이미지를 사용해 화질과 개념 합성 능력을 확보한다. SDXL이나 Midjourney와 같은 성공적인 T2I 모델의 이점을 활용하면 고해상도 및 복잡한 개념 합성을 갖춘 대규모 이미지셋을 얻는 것이 편리하다. 따라서 먼저 SD에서 확장된 동영상 모델을 완전히 학습시킨 다음 합성 이미지를 사용하여 완전히 학습된 모델의 공간 모듈 가중치만 finetuning하는 방법을 사용한다.
Method
1. Spatial-temporal Connection Analyses
Base T2V model
대규모 이미지 데이터셋에 대해 학습된 SD의 prior를 활용하기 위해 대부분의 T2V diffusion model은 시간 모듈을 추가하여 SD 모델을 동영상 모델로 확장하였다. 이들은 VDM을 따라 공간과 시간에 걸쳐 분해되는 특정 유형의 3D-UNet을 사용한다.
이러한 모델들은 학습 전략에 따라 두 그룹으로 분류될 수 있다.
- Full training: SD 가중치로 공간 모듈을 초기화하고 동영상을 사용하여 공간 모듈과 시간 모듈을 모두 학습시키는 전략
- Partial training: SD 가중치로 공간 모듈을 초기화하고 공간 모듈을 고정한 후 시간 모듈을 학습시키는 전략
저자들은 두 가지 학습 전략에 따라 공간 모듈과 시간 모듈 사이의 연결을 조사하기 위해 하나의 일반 모델을 사용하였다. 구체적으로 FPS를 조건으로 하는 오픈 소스 VideoCrafter1의 아키텍처를 따른다. 또한 시간적 일관성을 향상시키기 위해 ModelScopeT2V의 temporal convolution을 통합했다.
두 학습 전략을 위한 파라미터 섭동
동일한 데이터를 사용하여 동일한 아키텍처에 두 학습 전략을 적용한다. 모델은 사전 학습된 SD 가중치에서 초기화되며, 학습 데이터로는 WebVid-10M을 활용한다. 개념 망각을 방지하기 위해 LAION-COCO 600M이 동영상 및 이미지 공동 학습에도 사용된다.
Full training된 동영상 모델은 $M_F (\theta_T, \theta_S)$로 나타내고, partial training된 동영상 모델은 $M_P (\theta_T, \theta_S^0)$로 나타낸다. 여기서 $\theta_T$와 $\theta_S$는 각각 시간 모듈과 공간 모듈의 학습된 파라미터이다. $\theta_S^0$은 공간 모듈의 학습되지 않은 원래 파라미터이다.
공간 모듈과 시간 모듈 간의 연결 강도를 평가하기 위해 finetuning을 위한 또 다른 고품질 이미지 데이터셋 \(\mathcal{D}_I\)를 사용하여 지정된 모듈의 파라미터를 섭동시킨다. 이미지 데이터는 Midjornery의 합성 이미지로 구성된 JDB이다. JDB에는 400만 개의 이미지가 있으며 LORA를 사용하여 finetuning한다.
공간적 섭동. 먼저 이미지 데이터셋을 사용하여 두 동영상 모델의 공간 모듈 파라미터를 섭동시킨다. 시간 모듈의 파라미터는 고정되었다. $M_F$의 섭동 프로세스는 다음과 같이 표시될 수 있다.
\[\begin{equation} M_F^\prime (\theta_T, \theta_S + \Delta_{\theta_S}) \leftarrow \textrm{PERTB}_{\theta_S}^\textrm{LORA} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \end{equation}\]여기서 \(\textrm{PERTB}_{\theta_S}^\textrm{LORA}\)는 LORA를 사용하여 이미지 데이터셋 \(\mathcal{D}_I\)의 $\theta_S$에 대하여 $M_F$를 finetuning하는 것을 의미한다. \(\Delta_{\theta_S}\)는 LORA의 파라미터이다. 마찬가지로, $M_P$의 섭동된 모델은 다음과 같이 얻을 수 있다.
\[\begin{equation} M_P^\prime (\theta_T, \theta_S^0 + \Delta_{\theta_S}) \leftarrow \textrm{PERTB}_{\theta_S}^\textrm{LORA} (M_P (\theta_T, \theta_S^0), \mathcal{D}_I) \end{equation}\]$M_F^\prime$은 ‘F-Spa-LORA’, $M_P^\prime$은 ‘P-Spa-LORA’라는 이름을 사용하며, 아래의 규칙으로 다른 모델들의 이름을 정의한다.
- F: Full training
- P: Partial training
- Spa: 공간 모듈 finetuning
- Temp: 시간 모듈 finetuning
- LORA: finetuning을 위해 LORA를 사용
- DIR: LORA 없이 직접 finetuning

두 결과 모델의 합성된 동영상을 비교하면 다음과 같은 관찰 결과가 나타난다.
- F-Spa-LORA의 모션 품질은 P-Spa-LORA보다 안정적이다. P-Spa-LORA의 움직임은 finetuning 과정에서 빠르게 악화된다. Finetuning 단계가 많을수록 동영상은 로컬 깜박임으로 인해 더욱 정지되는 경향이 있다. F-Spa-LORA의 모션은 $M_F$에 비해 약간 저하된다.
- P-Spa-LORA는 F-Spa-LORA보다 훨씬 더 나은 시각적 품질을 달성하였다. F-Spa-LORA의 화질과 미적 점수는 $M_P$에 비해 크게 향상되었으며 워터마크도 제거되었다. F-Spa-LORA는 화질과 미적 점수가 약간 향상되었지만 생성된 동영상에는 여전히 잡음이 있다.
두 가지 관찰을 통해 $M_F$의 공간 모듈과 시간 모듈 간의 결합 강도가 $M_P$의 결합 강도보다 더 강하다는 결론을 내릴 수 있다. $M_P$의 시공간적 결합은 쉽게 깨져서 빠른 모션 저하 및 화질 변화로 이어질 수 있기 때문이다. 강한 연결은 약한 연결보다 파라미터 섭동을 더 잘 견딜 수 있다.
시간적 섭동. $M_P$는 시간 모듈만 업데이트되었지만 화질은 WebVid-10M의 화질로 이동되었다. 따라서 시간 모듈은 모션뿐만 아니라 화질도 담당한다. 이미지 데이터셋으로 공간 모듈을 수정하는 동안 시간 모듈을 섭동시킨다. 섭동 과정은 다음과 같이 표현된다.
\[\begin{aligned} M_F^{\prime \prime} (\theta_T + \Delta_{\theta_T}, \theta_S) &\leftarrow \textrm{PERTB}_{\theta_T}^\textrm{LORA} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \\ M_P^{\prime \prime} (\theta_T + \Delta_{\theta_T}, \theta_S^0) &\leftarrow \textrm{PERTB}_{\theta_T}^\textrm{LORA} (M_P (\theta_T, \theta_S^0), \mathcal{D}_I) \end{aligned}\]아래 그림에서 볼 수 있듯이 \(M_P^{\prime \prime}\) (P-Temp-LORA)의 화질이 \(M_F^{\prime \prime}\) (F-Temp-LORA)보다 우수하다. 그러나 동영상의 전경과 배경이 더 흔들리고, 즉 시간적 일관성이 나빠진다. F-Temp-LORA의 사진이 개선되었으나 워터마크가 여전히 남아있다. 모션은 base model에 가깝고 P-Temp-LORA보다 훨씬 좋다. 이러한 관찰은 공간적 섭동에서 얻은 결론을 뒷받침한다.

2. Data-level Disentanglement of Appearance and Motion
다양성이 높은 대규모의 고품질 동영상 데이터셋을 얻는 것은 매우 어려우며 WebVid-10M과 같은 저화질 동영상 데이터셋과 JDB와 같은 고품질 이미지 데이터셋만 사용할 수 있다. 따라서 저자들은 고품질 동영상을 사용하지 않고도 고품질 동영상 모델을 학습시킬 수 있는 가능성을 모색하였다. 저자들은 데이터 레벨에서 모션과 외형을 분리할 것을 제안하였다. 즉, 저품질의 동영상으로 모션을 학습시키고 고품질 이미지로 화질과 미적인 부분을 finetuning하는 것이다. 핵심은 동영상 모델을 학습시키는 방법과 이를 이미지로 finetuning하는 방법에 있다.
공간 모듈과 시간 모듈 간의 연결에 대한 앞의 연구에 따르면 $M_F$는 고품질 이미지를 사용한 후속 finetuning에 더 적합하다. 이는 강력한 시공간 결합이 명백한 모션 변성 없이 공간 모듈과 시간 모듈 모두에 대한 파라미터 섭동을 견딜 수 있기 때문이다.
다음으로 이미지를 사용하여 base model을 finetuning하는 방법을 조사해야 한다. 공간적 섭동과 시간적 섭동 모두에서 화질이 크게 향상되지는 않는다. 더 큰 품질 향상을 얻기 위해 저자들은 두 가지 전략을 평가하였다.
- 더 많은 파라미터를 포함한다. 이미지를 사용하여 공간 모듈과 시간 모듈을 모두 finetuning한다.
- Finetuning 방법을 변경한다. LORA 없이 직접 finetuning을 사용한다.
다음 네 가지 경우를 평가할 수 있다.
\[\begin{aligned} M_F^A (\theta_T + \Delta_{\theta_T}, \theta_S + \Delta_{\theta_S}) &\leftarrow \textrm{PERTB}_{\theta_T, \theta_S}^\textrm{LORA} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \\ M_F^B (\theta_T, \theta_S + \Delta_{\theta_S}) &\leftarrow \textrm{PERTB}_{\theta_S} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \\ M_F^C (\theta_T + \Delta_{\theta_T}, \theta_S) &\leftarrow \textrm{PERTB}_{\theta_T} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \\ M_F^D (\theta_T + \Delta_{\theta_T}, \theta_S + \Delta_{\theta_S}) &\leftarrow \textrm{PERTB}_{\theta_T, \theta_S} (M_F (\theta_T, \theta_S), \mathcal{D}_I) \end{aligned}\]$M_F^A$ (F-Spa&Temp-LORA)는 첫 번째 전략에 따라 얻어지고, $M_F^B$, $M_F^C$, $M_F^D$는 두 번째 전략을 통해 얻어진다. $M_F^B$ (F-Spa-DIR)와 $M_F^C$ (F-TempDIR)는 각각 공간 모듈과 시간 모듈을 직접 finetuning하며, $M_F^D$ (F-Spa&Temp-DIR)는 모든 모듈을 직접 finetuning한다.

생성된 네 가지 모델의 동영상을 비교한 관찰 결과는 다음과 같다.
- F-Spa&Temp-LORA는 F-Spa-LORA의 화질을 더욱 향상시킬 수 있지만 품질은 여전히 만족스럽지 않다. 생성된 대부분의 동영상에는 워터마크가 존재하며 잡음이 뚜렷이 나타난다.
- F-Temp-DIR은 F-Temp-LORA과 F-Spa&Temp-LORA보다 화질이 더 좋다. 동영상의 절반에서 워터마크가 제거되거나 밝아진다.
- F-Spa-DIR과 F-Spa&Temp-DIR은 finetuning 모델 중 최고의 화질을 보여준다. 그러나 F-Spa-DIR의 모션이 더 좋다. F-Spa&Temp-DIR의 전경과 배경은 $M_F^D$로 생성된 동영상, 특히 로컬 텍스처에서 깜박인다.
이러한 관찰 결과를 통해 고품질 이미지로 공간 모듈을 직접 finetuning하는 것이 모션 품질의 손실 없이 화질을 향상시키는 가장 좋은 방법임을 알 수 있다. 따라서 먼저 저품질의 동영상으로 동영상 모델을 완전히 학습시킨 다음 고품질 이미지로만 공간 모듈을 직접 finetuning한다.
3. Promotion of Concept Composition
동영상 모델의 개념 합성 능력을 향상시키기 위해 부분 finetuning 단계에서 실제 이미지를 사용하는 대신 복잡한 개념을 가진 합성 이미지를 사용한다. SDXL과 Midjornery와 같은 T2I 모델은 현실에 나타나지 않는 개념을 합성하는 능력을 가지고 있다. 학습 이미지를 사용하는 대신 복잡한 개념을 가진 이미지들을 합성하여 개념 합성 능력을 동영상 모델에 이전한다. 이를 통해 개념과 모션을 동시에 잘 잡아야 한다는 부담감을 덜어줄 수 있다.
합성된 이미지의 유효성을 검증하기 위해 두 번째 finetuning 단계의 이미지 데이터로 JDB와 LAION-aesthetics V2를 사용한다. LAION-aesthetics V2는 웹에서 수집한 이미지로 구성되어 있고, JDB는 Midjourney에서 합성한 이미지로 구성되어 있다.

F-Spa-DIR-LAION과 F-Spa-DIR은 각각 LAION-aesthetics V2와 JDB를 이미지 데이터로 사용한 것이다. JDB로 학습된 모델이 훨씬 더 나은 개념 합성 능력을 가지고 있다.
Experiments
- 학습 디테일
- 가중치 초기화: 공간 모듈은 SD 2.1로 초기화, 시간 모듈은 0으로 초기화
- 1단계: 동영상 학습
- 동영상 해상도: 512$\times$320
- batch size: 128
- iteration: 27만
- learning rate: $5 \times 10^{-5}$
- GPU: NVIDIA A100 32개
- 2단계: 이미지 pretraining
- 이미지 해상도: 512$\times$512
- batch size: 256
- iteration: 3만
- GPU: NVIDIA A100 8개
1. Comparison with State-of-the-Art T2V Models
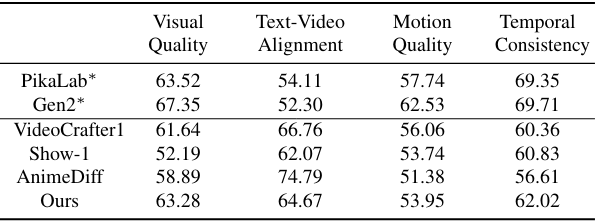
다음은 EvalCrafter 벤치마크에서 SOTA T2V 모델들과 성능을 비교한 표이다.
다음은 다른 T2V 모델들과 생성 결과를 비교한 것이다.

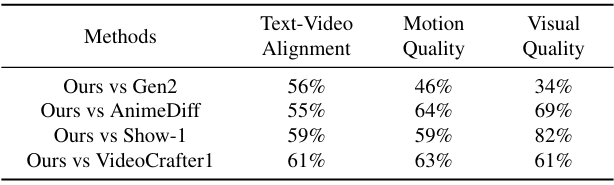
다음은 다른 T2V 모델들과 인간 선호도를 비교한 표이다.
2. Strategy Evaluation
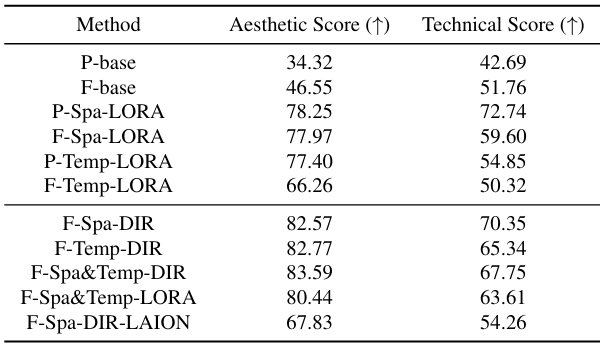
다음은 섭동된 T2V 모델들의 시각적 품질을 평가한 표이다.
다음은 섭동된 T2V 모델들의 모션 품질에 대한 user study 결과이다.
