[논문리뷰] VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
arXiv 2023. [Paper] [Page] [Github]
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, Ying Shan
Tencent AI Lab | Hong Kong University of Science and Technology | Chinese Academy of Sciences | The Chinese University of Hong Kong | City University of Hong Kong
30 Oct 2023

Introduction
생성 모델, 특히 diffusion model의 급속한 발전으로 이미지 생성, 동영상 생성과 같은 분야에서 수많은 혁신이 이루어졌다. 가장 잘 알려진 오픈 소스 (text-to-image) T2I 생성 모델은 그럴듯한 결과를 생성하는 Stable Diffusion(SD)이다. 이후 향상된 버전인 SDXL이 출시되어 개념 합성과 이미지 품질이 향상되었다.
Text-to-video (T2V) 모델의 경우 Make-A-Video와 Imagen Video는 계단식 모델인 반면, LVDM, Magic Video, ModelScope, Align your Latents와 같은 대부분의 다른 연구들은 SD 기반 모델이다. 이러한 모델들은 프레임 간 시간적 일관성을 보장하기 위해 시간적 레이어를 통합하여 SD 프레임워크를 동영상으로 확장하였다. 공간적 파라미터는 사전 학습된 SD UNet을 상속한다.
성공적인 T2I 모델의 번영과 다운스트림 task의 발전은 주로 커뮤니티 내의 오픈 소스 환경에 기인할 수 있다. SD는 엄청난 컴퓨팅 성능을 사용하여 방대한 텍스트-이미지 쌍에 대해 학습하기 때문에 중요한 기반 역할을 한다. 이와 관련된 비용은 대부분의 학술 연구 그룹에서 감당할 수 없는 수준인 경우가 많다. 이와 대조적으로 T2V 분야에서는 Make-A-Video와 Imagen Video가 유망한 결과를 보여주지만 둘 다 오픈 소스가 아니다. Gen-2, Pika Labs, Moonvalley와 같은 몇몇 스타트업은 고품질 동영상을 생성할 수 있지만 해당 모델은 추가 연구를 위해 액세스할 수 없다.
현재 ModelScope, Hotshot-XL, AnimateDiff, Zeroscope V2 XL과 같은 여러 오픈 소스 T2V 모델이 존재한다. 출시된 ModelScope 모델은 256$\times$256 해상도의 동영상만 생성할 수 있고, 이미지 품질도 만족스럽지 않다. Zeroscope V2 XL은 작은 동영상 세트에서 튜닝하여 시각적 품질을 향상시켰지만 생성된 동영상에는 깜박임과 눈에 띄는 잡음이 남아 있다. Hotshot-XL은 SDXL을 동영상 모델로 확장하고 8프레임, 512$\times$512 해상도의 gif를 생성하는 것을 목표로 한다. AnimateDiff는 LORA SD 모델의 공간 모듈과 시간 모듈을 결합할 것을 제안하였다. 시간 모듈이 WebVid-10M에서 학습하므로 AnimateDiff의 T2V 모델의 결과가 좋지 않다. 고품질 LORA 모델과의 결합으로 고품질 영상을 생성할 수 있다. 그러나 스타일과 개념 합성 능력 측면에서 LORA 모델에 따라 범위가 제한된다. 고해상도, 고품질 영상을 생성할 수 있는 오픈소스 일반 T2V 기반 모델이 아직 부족하다.
최근 Pika Labs와 Gen-2는 콘텐츠와 구조를 유지하면서 주어진 이미지를 신속하게 애니메이션화하는 것을 목표로 하는 image-to-video (I2V) 모델을 출시했다. 이 기술은 생성된 모션이 제한되어 있고 일반적으로 눈에 보이는 아티팩트가 있기 때문에 아직 초기 단계이다. 유일한 오픈 소스 I2V 기반 모델인 I2VGen-XL이 ModelScope에서 출시되었다. 이 모델은 사전 학습된 T2V 모델을 튜닝하기 위해 텍스트 임베딩을 대체하는 이미지 임베딩을 사용한다. 그러나 컨텐츠 보존 제약 조건을 충족하지 않는다. 생성된 동영상은 주어진 이미지의 semantic과 일치하지만 레퍼런스 컨텐츠와 구조를 엄격하게 따르지는 않는다. 따라서 오픈 소스 커뮤니티에서는 좋은 I2V 모델이 필요하다.
본 연구에서는 고품질 동영상 생성을 위한 두 가지 diffusion model을 소개한다. 하나는 T2V 생성을 위한 것이고 다른 하나는 I2V 생성을 위한 것이다. T2V 모델은 시간적 일관성을 캡처하기 위해 SD UNet에 temporal attention layer를 통합하여 SD 2.1을 기반으로 구축되었다. 저자들은 개념 망각을 방지하기 위해 이미지 및 동영상 공동 학습 전략을 사용하였다. 학습 데이터셋은 LAION COCO 600M, WebVid-10M, 수집된 천만 개의 고해상도 동영상 데이터셋으로 구성된다. T2V 모델은 해상도 1024$\times$576, 길이 2초의 동영상을 생성할 수 있다. 반면에 I2V 모델은 T2V 모델을 기반으로 하며 텍스트와 이미지 입력을 모두 허용한다. 이미지 임베딩은 CLIP을 사용하여 추출되고 텍스트 임베딩 주입과 유사하게 cross attention을 통해 SD UNet에 주입된다. I2V 모델은 LAION COCO 600M과 WebVid-10M에서 학습되었다.
Methodology
1. VideoCrafter1: Text-to-Video Model
Structure Overview
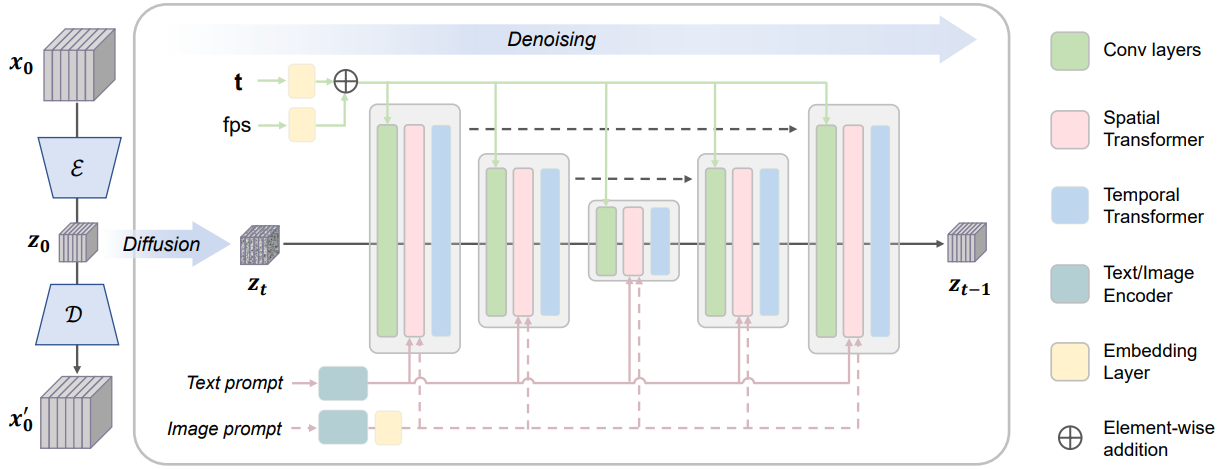
VideoCrafter T2V 모델은 위 그림에 설명된 것처럼 동영상 VAE와 동영상 latent diffusion model의 두 가지 주요 구성 요소로 구성된 Latent Video Diffusion Model (LVDM)이다. 동영상 VAE는 샘플 차원을 줄여 diffusion model이 보다 컴팩트하고 효율적이도록 한다. 먼저, 동영상 데이터 $x_0$는 VAE 인코더 $\mathcal{E}$에 입력되어 더 낮은 데이터 차원의 압축된 동영상 표현인 video latent $z_0$에 project된다. 그런 다음, video latent는 VAE 디코더 $\mathcal{D}$를 통해 재구성된 동영상 $x_0^\prime$으로 다시 project될 수 있다. Stable Diffusion 모델에서 사전 학습된 VAE를 채택하여 동영상 VAE 역할을 하도록 하고 시간 정보를 추출하지 않고 각 프레임을 개별적으로 project시킨다. Video latent $z_0$를 얻은 후 다음과 같이 $z_0$에서 diffusion process가 수행된다.
여기서 $T$는 diffusion timestep의 수이고 $\beta_t$는 timestep $t$에서의 noise level이다. 따라서 임의의 시간 간격 $t$에서 일련의 noisy video latent $z_t$를 얻을 수 있다.
Denoising process를 수행하기 위해 denoising U-Net은 입력 noise latent에서 noise을 추정하도록 학습된다. 점진적인 denoising process 후에 latent 샘플은 noise가 있는 상태에서 깨끗한 상태로 전환되고 최종적으로 VAE 디코더에 의해 픽셀 공간에서 생성된 동영상으로 디코딩될 수 있다.
Denoising 3D U-Net
Denoising U-Net은 skip connection이 있는 기본 시공간 블록의 스택으로 구성된 3D U-Net 아키텍처이다. 각 블록은 convolutional layer, spatial transformers (ST), temporal transformers (TT)로 구성된다.
\[\begin{aligned} \textrm{ST} &= \textrm{Proj}_\textrm{in} \circ (\textrm{Attn}_\textrm{self} \circ \textrm{Attn}_\textrm{cross} \circ \textrm{MLP}) \circ \textrm{Proj}_\textrm{out} \\ \textrm{TT} &= \textrm{Proj}_\textrm{in} \circ (\textrm{Attn}_\textrm{temp} \circ \textrm{Attn}_\textrm{temp} \circ \textrm{MLP}) \circ \textrm{Proj}_\textrm{out} \end{aligned}\]Denoiser의 제어 신호에는 텍스트 프롬프트와 같은 semantic 제어와 동영상 FPS와 같은 모션 속도 제어가 포함된다. Cross-attention을 통해 semantic 제어를 주입된다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = \textrm{softmax} \bigg( \frac{QK^\top}{\sqrt{d}} \bigg) \cdot V \\ \textrm{where} \; Q = W_Q^{(i)} \cdot \phi_i (z_t), \; K = W_K^{(i)} \cdot \phi (y), \; V = W_V^{(i)} \cdot \phi (y) \end{equation}\]여기서 $\phi_i (z_t) \in \mathbb{R}^{N \times d_\epsilon^i}$는 공간적으로 flatten된 video latent 토큰을 나타내고, $\phi$는 CLIP 텍스트 인코더를 나타내고, $y$는 입력 텍스트 프롬프트를 나타낸다. FPS를 사용한 모션 속도 제어는 timestep 임베딩과 동일한 구조를 공유하는 FPS 임베딩을 통해 통합된다. 특히, FPS와 timestep은 sinusoidal embedding을 사용하여 임베딩 벡터에 project된다. 그런 다음 이 벡터는 2-layer MLP에 입력되어 sinusoidal embedding을 학습된 임베딩에 매핑한다. 이어서, element-wise 덧셈을 통해 timestep 임베딩과 FPS 임베딩이 융합된다. 융합된 임베딩은 최종적으로 convolutional feature에 더해져 중간 feature를 조정한다.
2. VideoCrafter1: Image-to-Video Model
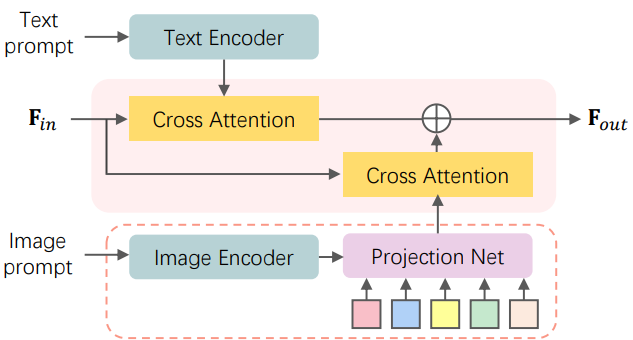
텍스트 프롬프트는 콘텐츠 생성을 위한 매우 유연한 제어를 제공하지만 주로 디테일한 모양보다는 semantic 수준의 컨텐츠에 중점을 둔다. I2V 모델에서는 제공된 이미지를 기반으로 동적인 시각적 콘텐츠를 합성할 것으로 예상되는 video diffusion model에 추가 조건부 입력, 즉 이미지 프롬프트를 통합하는 것을 목표로 한다. Text-to-video diffusion model의 경우 조건부 텍스트 삽입 공간은 최종 출력 동영상의 시각적 콘텐츠를 결정하는 데 중요한 역할을 한다. 동영상 모델에 이미지 정보를 호환 가능한 방식으로 제공하려면 텍스트 정렬된 임베딩 공간에 이미지를 project하는 것이 필수적이다. 저자들은 시각적 충실도를 높이기 위해 풍부한 디테일을 포함하는 임베딩을 학습시킬 것을 제안한다. 위 그림은 diffusion model에 이미지 조건 분기를 장착하는 다이어그램이다.
Text-Aligned Rich Image Embedding
텍스트 임베딩은 사전 학습된 CLIP 텍스트 인코더를 사용하여 구성되므로 입력 이미지에서 이미지 feature를 추출하기 위해 사전 학습된 CLIP 이미지 인코더를 사용한다. CLIP 이미지 인코더의 글로벌 semantic 토큰 $f_\textrm{cls}$는 이미지 캡션과 잘 정렬되어 있지만 주로 semantic 수준에서 시각적 컨텐츠를 나타내지만 디테일을 캡처하는 능력은 떨어진다. 저자들은 CLIP 이미지 ViT의 마지막 레이어에서 전체 패치 시각적 토큰 \(F_\textrm{vis} = \{f_i\}_{i=0}^K\)을 활용한다. 이는 이미지에 대한 훨씬 더 풍부한 정보를 포함한다.
텍스트 임베딩과의 정렬을 촉진하기 위해 학습 가능한 projection network $\mathcal{P}$를 활용하여 \(F_\textrm{vis}\)를 대상 이미지 임베딩 \(F_\textrm{img} = \mathcal{P} (F_\textrm{vis})\)로 변환하여 동영상 모델 backbone이 이미지 feature를 효율적으로 처리할 수 있도록 한다. 텍스트 임베딩 \(F_\textrm{text}\)와 이미지 임베딩 \(F_\textrm{img}\)는 이중 cross-attention layer를 통해 U-Net 중간 feature \(F_\textrm{in}\)을 계산하는 데 사용된다.
\[\begin{equation} F_\textrm{out} = \textrm{Softmax} (\frac{QK_{text}^\top}{\sqrt{d}}) V_\textrm{text} + \textrm{Softmax} (\frac{QK_{img}^\top}{\sqrt{d}}) V_\textrm{img} \\ \textrm{where} \; Q = F_\textrm{in} W_q, \; K_\textrm{text} = F_\textrm{text} W_k, \; V_\textrm{text} = F_\textrm{text} W_v, \; K_\textrm{img} = F_\textrm{img} W_k^\prime, \; V_\textrm{img} = F_\textrm{img} W_v^\prime \end{equation}\]텍스트 cross-attention과 이미지 cross-attention에 대해 동일한 쿼리를 사용한다. 따라서 각 cross-attention layer에 대해 두 개의 파라미터 행렬 $W_k^\prime$과 $W_v^\prime$만이 새로 추가된다. 아래 그림은 주어진 조건부 이미지 입력 (a)에 대하여 글로벌 semantic 토큰 (b)과 본 논문이 채택한 풍부한 시각적 토큰 (c)을 각각 조건으로 생성된 동영상의 시각적 충실도를 비교한 것이다.

Experiments
- 데이터셋
- 이미지: LAION COCO (텍스트-이미지 쌍 6억 개)
- 동영상: WebVid-10M, 1280$\times$720보다 큰 천만 개의 동영상을 포함하는 자체 수집 데이터셋
- 학습 디테일
- T2V 모델: 낮은 해상도에서 높은 해상도로 학습
- 256$\times$256에서 8만 iteration, batch size 256으로 학습
- 512$\times$320에서 13.6만 iteration, batch size 128로 fine-tuning
- 1024$\times$576에서 4.5만 iteration, batch size 64로 fine-tuning
- I2V 모델
- 처음에는 이미지 임베딩에서 cross-attention에 사용되는 임베딩 공간까지의 매핑을 학습
- 그 후, 텍스트 임베딩과 이미지 임베딩 모두의 매핑을 수정하고 정렬 개선을 위해 동영상 모델을 fine-tuning
- T2V 모델: 낮은 해상도에서 높은 해상도로 학습
Text-to-Video Results
다음은 user study 결과이다.
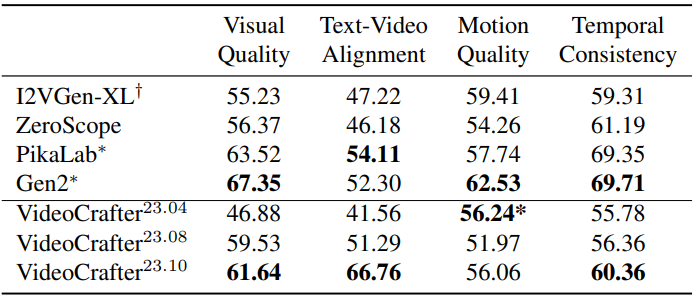
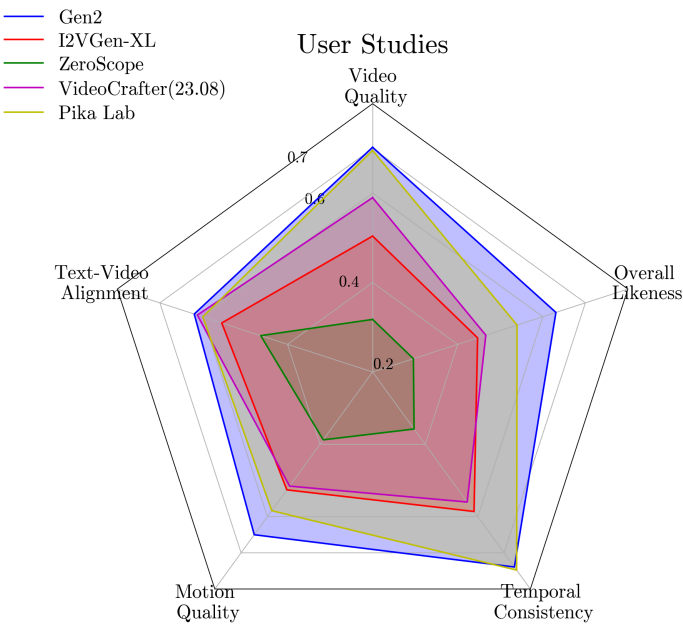
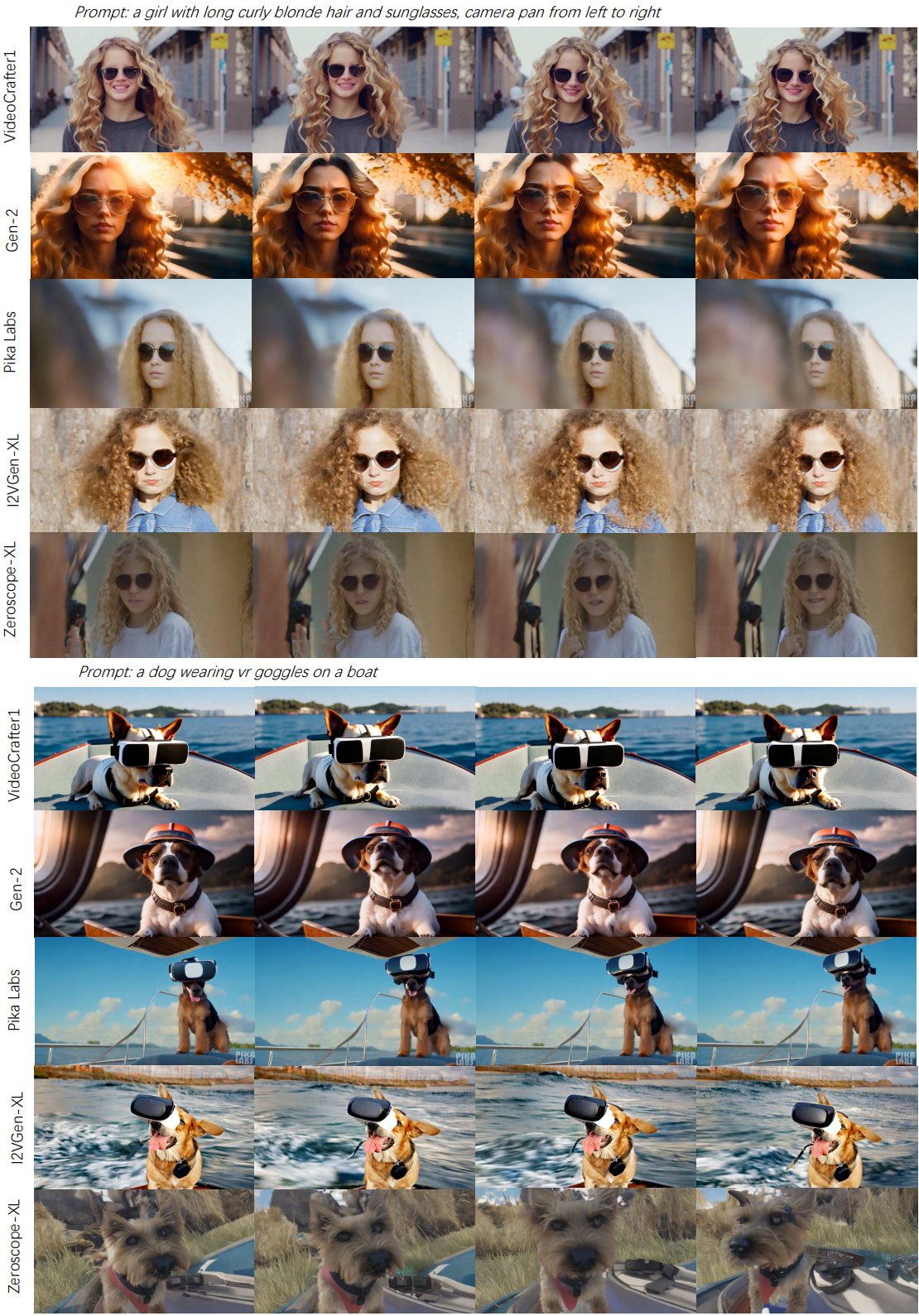
다음은 T2V에 대한 Gen-2, Pika Labs, I2VGen-XL, Zeroscope-XL와의 시각적 비교 결과이다.

다음은 서로 다른 VideoCrafter T2V 버전 사이의 시각적 품질을 비교한 것이다.

Image-to-Video Results
다음은 I2V에 대한 VideoComposer, I2VGen-XL, Pika, Gen-2와의 시각적 비교 결과이다.
