[논문리뷰] Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (Video LDM)
CVPR 2023. [Paper] [Page]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, Karsten Kreis
LMU Munich | NVIDIA | Vector Institute | University of Toronto 5University of Waterloo
18 Apr 2023

Introduction
오늘날 가장 강력한 이미지 생성 모델들은 GAN, autoregressive transformer, diffusion model을 기반으로 한다. Diffusion model(DM)은 특히 바람직한 이점이 있다. 견고하고 확장 가능한 목적 함수를 제공하며 일반적으로 transformer 기반보다 파라미터 집약도가 낮다. 그러나 이미지 도메인은 크게 발전했지만 동영상 모델링은 뒤처졌다. 주로 동영상 데이터 학습과 관련된 상당한 계산 비용과 공개적으로 사용 가능한 대규모의 일반 동영상 데이터셋이 부족하기 때문이다. 동영상 합성에 대한 여러 연구들이 있었지만 기존 동영상 DM을 포함한 대부분의 연구들은 상대적으로 저해상도의 짧은 동영상만 생성한다. 본 논문은 동영상 모델을 실제 문제에 적용하고 고해상도의 긴 동영상을 생성한다. 특히, 두 가지 현실세계 동영상 생성 문제에 초점을 맞춘다.
- 자율주행의 맥락에서 시뮬레이션 엔진으로서 큰 잠재력을 가진 고해상도의 실제 주행 데이터의 영상 합성
- 창의적인 콘텐츠 생성을 위한 가이드 동영상 합성되는
이를 위해 고해상도 이미지에서 학습할 때 무거운 계산 비용을 줄일 수 있는 latent diffusion model(LDM)을 구축한다. Video LDM을 제안하고 LDM을 특히 컴퓨팅 집약적인 작업인 고해상도 동영상 생성으로 확장한다. 동영상 생성을 위한 DM에 대한 이전 연구들과 달리 먼저 Video LDM을 이미지에만 사전 학습(또는 사전 학습된 이미지 LDM 사용)하여 대규모 이미지 데이터셋을 활용한다. 그런 다음 latent space DM에 시간적 차원을 도입하고 사전 학습된 공간적 레이어를 고정하면서 인코딩된 이미지 시퀀스, 즉 동영상에서 이러한 시간적 레이어만 학습함으로써 LDM 이미지 generator를 동영상 generator로 변환한다. 유사하게 픽셀 space에서 시간적 일관성을 달성하기 위해 LDM의 디코더를 fine-tuning한다. 공간 해상도를 더욱 향상시키기 위해 이미지 super-resolution에 널리 사용되는 픽셀 space 및 latent DM upsampler를 시간적으로 일치시켜 시간적으로 일관된 동영상 super-resolution 모델로 전환한다.
LDM을 기반으로 하는 본 논문의 방법은 계산 및 메모리 효율적인 방식으로 글로벌하게 일관되고 긴 동영상을 생성할 수 있다. 매우 높은 해상도의 합성을 위해 동영상 upsampler는 로컬에서만 작동하면 되므로 학습 및 계산 요구 사항이 낮아진다. 저자들은 512$\times$1024 실제 주행 동영상에서 테스트하여 state-of-the-art 동영상 품질을 달성하고 몇 분 길이의 동영상을 합성하였다. 또한 Stable Diffusion을 fine-tuning하여 최대 1280$\times$2048 해상도의 효율적이고 강력한 text-to-video generator로 전환한다. 이 경우 자막이 있는 동영상으로 구성된 상대적으로 작은 학습 셋을 사용할 수 있다. 학습된 시간적 레이어를 다르게 fine-tuning된 text-to-image LDM으로 전송함으로써 개인화된 text-to-video 생성을 처음으로 시연하였다.
Latent Video Diffusion Models
$x \in \mathbb{R}^{T \times 3 \times \tilde{H} \times \tilde{W}}, \; x \sim p_\textrm{data}$가 높이와 너비가 $\tilde{H}$와 $\tilde{W}$인 $T$개의 RGB 프레임의 시퀀스인 동영상으로 구성된 데이터셋 $p_\textrm{data}$를 사용한다고 가정한다.
1. Turning Latent Image into Video Generators
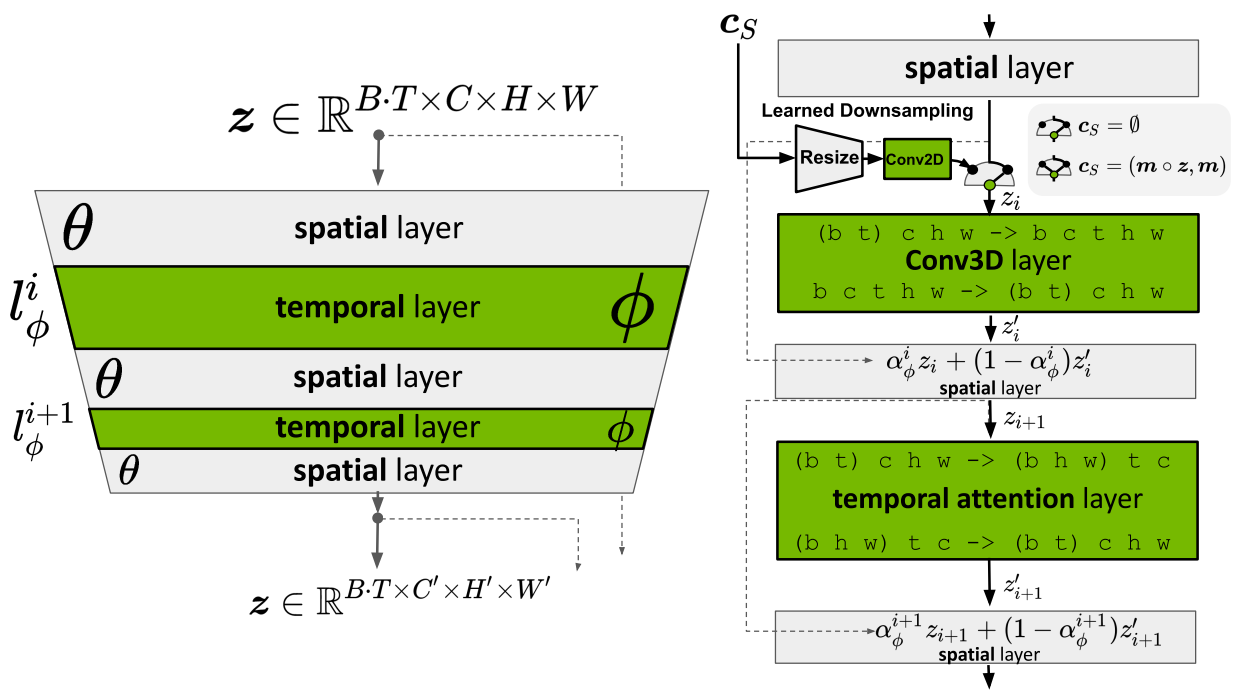
동영상 생성 모델을 효율적으로 학습시키기 위한 핵심 통찰력은 사전 학습된 고정 이미지 생성 모델을 재사용하는 것이다. 구체적으로 파라미터 $\theta$로 parameterize된 LDM을 재사용한다. 레이어 index $i$를 사용하여 이미지 LDM을 구성하는 신경망 레이어의 픽셀 차원에 대한 입력을 공간적 레이어 $l_\theta^i$로 처리한다. 그러나 이러한 모델은 개별 프레임을 고품질로 합성할 수 있지만 모델이 시간 개념이 없기 때문에 $T$개의 연속 프레임 동영상을 직접 렌더링하는 데 사용할 수 없다. 따라서 기존 공간적 레이어 $l_\theta^i$와 인터리브되고 시간적으로 일관된 방식으로 개별 프레임을 정렬하는 방법을 배우는 추가 시간적 신경망 레이어 $l_\phi^Ii$를 도입한다. 이러한 $L$개의 추가적인 시간적 레이어 \(\{l_\phi^i\}_{i=1}^L\)는 모델의 video-aware한 시간적 backbone을 정의하고 따라서 전체 모델 $f_{\theta,\phi}$는 공간적 및 시간적 레이어의 조합이다.
프레임 단위로 인코딩된 입력 동영상 $\mathcal{E}(x) = z \in \mathbb{R}^{T \times C \times H \times W}$에서 시작한다. 여기서 $C$는 latent 채널의 수이고 $H$와 $W$는 공간적 latent 차원이다. 공간적 레이어는 동영상을 독립적인 이미지의 배치로 해석하고 (시간 축을 배치 차원으로 이동) 각 $l_\phi^i$에 대해 다음과 같이 동영상 차원으로 재구성한다 (einops 표기법 사용).
\[\begin{aligned} z' & \leftarrow \textrm{rearrange} (z, \textrm{(b t) c h w \rightarrow b c t h w}) \\ z' & \leftarrow l_\phi^i (z', c) \\ z' & \leftarrow \textrm{rearrange} (z', \textrm{b c t h w \rightarrow (b t) c h w}) \end{aligned}\]즉, 공간적 레이어는 배치 차원 b에서 모든 $B \cdot T$개의 인코딩된 동영상 프레임을 독립적으로 처리하는 반면, 시간적 레이어 $l_\phi^i (z’, c)$는 새로운 시간 차원 $t$에서 전체 동영상을 처리한다. 또한 $c$는 텍스트 프롬프트와 같은 조건 정보(선택 사항)이다. 각 시간적 레이어 이후에 출력 $z’$은
\[\begin{equation} \alpha_\phi^i z + (1 − \alpha_\phi^i) z' \end{equation}\]으로 $z$와 결합된다. $\alpha_\phi^i \in [0, 1]$는 학습 가능한 파라미터이다.
실제로는 두 가지 다른 종류의 시간적 레이어를 구현한다.
- Temporal attention
- 3D convolution 기반의 reidual block들
Sinusoidal embedding을 사용하여 모델에 시간에 대한 위치 인코딩을 제공한다.
그런 다음 video-aware한 시간적 backbone은 기본 이미지 모델과 동일한 noise schedule을 사용하여 학습되며, 중요한 것은 공간적 레이어 $l_\theta^i$를 고정하고 다음을 통해 시간적 레이어 $l_\phi^i$만 최적화한다는 것이다.
\[\begin{equation} \underset{\phi}{\arg \min} \mathbb{E}_{x \sim p_\textrm{data}, \tau \sim p_\tau, \epsilon \sim \mathcal{N}(0,I)} [\|y - f_{\theta, \phi} (z_\tau; c, \tau) \|_2^2] \end{equation}\]여기서 $z_\tau$는 diffusion encoding $z = \mathcal{E}(x)$를 나타낸다. 이러한 방식으로 시간적 블록을 skip하여 기본 이미지 생성 능력을 유지한다. 각 레이어에 대해 $\alpha_\phi^i = 1$로 설정한다. 이 전략의 중요한 이점은 거대한 이미지 데이터셋을 사용하여 공간적 레이어를 사전 학습할 수 있는 반면, 일반적으로 덜 사용 가능한 동영상 데이터는 시간적 레이어의 집중 학습에 활용할 수 있다는 것이다.
Temporal Autoencoder Finetuning
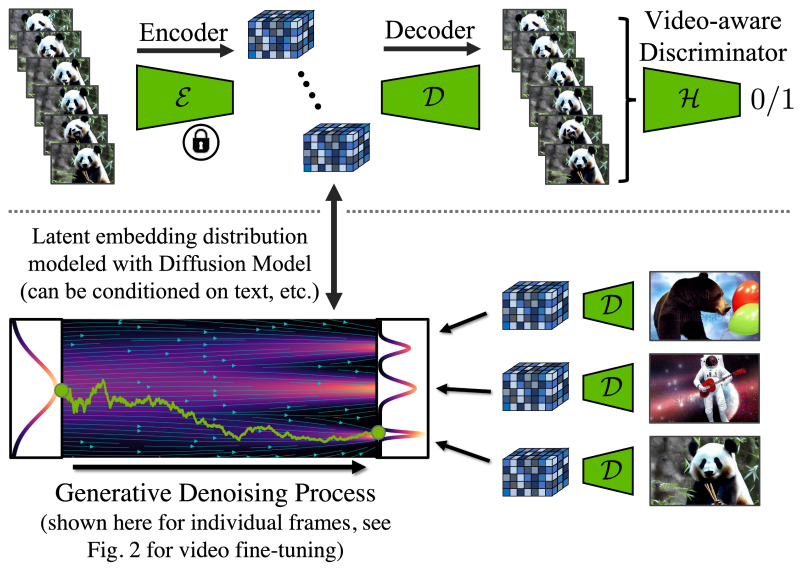
동영상 모델은 사전 학습된 이미지 LDM을 기반으로 한다. 이렇게 하면 효율성이 높아지지만 LDM의 autoencoder는 이미지에 대해서만 학습되므로 시간적으로 일관된 이미지 시퀀스를 인코딩 및 디코딩할 때 아티팩트가 발생한다. 이에 대응하기 위해 autoencoder의 디코더를 위한 추가적인 시간적 레이어를 도입하여 3D convolution으로 구축된 (patch-wise) temporal discriminator로 동영상 데이터를 fine-tuning한다. 인코딩된 동영상 프레임의 latent space에서 작동하는 이미지 DM이 재사용될 수 있도록 인코더는 이미지 학습에서 변경되지 않은 상태로 유지된다.
2. Prediction Models for Long-Term Generation
앞서 설명한 방법은 짧은 동영상 시퀀스를 생성하는 데 효율적이며 매우 긴 동영상을 합성할 때 한계에 도달한다. 따라서 모델을 $S$개의 컨텍스트 프레임이 주어진 예측 모델로 학습시킨다. 모델이 예측해야 하는 $T - S$개의 프레임을 마스킹하는 temporal binary mask $m_S$를 도입하여 이를 구현한다. 여기서 $T$는 총 시퀀스 길이다. 컨디셔닝을 위해 이 마스크와 마스킹된 인코딩된 동영상 프레임을 모델에 공급한다. 구체적으로, 프레임은 LDM의 이미지 인코더 $\mathcal{E}$로 인코딩되고 마스크로 곱해진 다음 학습된 다운샘플링 연산으로 처리된 후 시간적 레이어 $l_\phi^i$에 공급된다 (채널 방향으로 마스크와 concat됨). $(m_S \circ z, m_S)$는 마스크와 마스킹된 이미지의 연결된 공간적 컨디셔닝을 나타낸다. 그리고 나서 다음과 같은 목적 함수를 사용한다.
\[\begin{equation} \mathbb{E}_{x \sim p_\textrm{data}, m_S \sim p_S, \tau \sim p_\tau, \epsilon} [\| y - f_{\theta,\phi} (z_\tau; c_S, c, \tau) \|_2^2] \end{equation}\]여기서 $p_S$는 마스크 샘플링 분포이다. 실제로는 classifier-free guidance를 위해 0, 1 또는 2개의 컨텍스트 프레임으로 컨디셔닝된 예측 모델을 학습시킨다.
Inference 중에는 긴 동영상을 생성하기 위해 최신 예측을 새로운 컨텍스트로 재사용하여 샘플링 프로세스를 반복적으로 적용할 수 있다. 먼저 기본 이미지 모델에서 단일 컨텍스트 프레임을 합성하고 이를 기반으로 시퀀스를 생성하여 첫 번째 초기 시퀀스를 생성된다. 그 후에 움직임을 인코딩하기 위해 두 개의 컨텍스트 프레임으로 컨디셔닝한다. 이 프로세스를 안정화하기 위해 classifier-fre guidance를 사용하는 것이 유익하다.
\[\begin{equation} f_{\theta, \phi}' (z_\tau; c_S) = f_{\theta, \phi} (z_\tau) + s \cdot (f_{\theta, \phi} (z_\tau; c_S) - f_{\theta, \phi} (z_\tau)) \end{equation}\]여기서 $s \ge 1$은 guidance scale을 나타내며 가독성을 위해 $\tau$와 $c$에 대한 명시적 조건을 생략하였다. 이 guidance를 context guidance라고 부른다.
3. Temporal Interpolation for High Frame Rates
고해상도 동영상은 높은 공간적 해상도뿐만 아니라 높은 시간적 해상도, 즉 높은 프레임 속도를 특징으로 한다. 이를 달성하기 위해 고해상도 동영상 합성 프로세스를 두 부분으로 나눈다. 첫 번째 부분은 앞서 설명한 프로세스로, 큰 의미 변화가 있는 키 프레임을 생성할 수 있지만 (메모리 제약으로 인해) 상대적으로 낮은 프레임 속도에서만 가능하다. 두 번째 부분에서는 주어진 키 프레임 사이를 보간하는 작업을 수행하는 추가 모델을 도입한다. 이를 구현하기 위해 앞서 설명한 masking-conditioning mechanism을 사용한다. 그러나 예측 task와 달리 이제 보간할 프레임을 마스킹하고 나머지 메커니즘은 동일하게 유지된다. 즉, 이미지 모델이 동영상 보간 모델로 정제된다. 실험에서 두 개의 주어진 키 프레임 사이에서 세 개의 프레임을 예측하여 $T \rightarrow 4T$ 보간 모델을 학습시킨다. 더 큰 프레임 속도를 달성하기 위해 이진 컨디셔닝으로 $T \rightarrow 4T$와 $4T \rightarrow 16T$ 방식에서 동시에 모델을 학습시킨다.
4. Temporal Fine-tuning of SR Models
LDM 메커니즘이 이미 우수한 기본 해상도를 제공하지만 저자들은 이를 메가픽셀 범위로 끌어올리는 것을 목표로 하였다. Cascaded DM에서 영감을 받아 동영상 LDM 출력을 4배 더 확장한다. 주행 동영상 합성 실험을 위해 픽셀 space DM을 사용하고 512$\times$1024로 확장한다. Text-to-video 모델의 경우 LDM upsampler를 사용하고 1280$\times$2048로 확장한다. Noise level conditioning과 함께 noise augmentation을 사용하고 다음을 통해 super-resolution (SR) 모델 $g_{\theta,\phi}$을 학습시킨다.
\[\begin{equation} \mathbb{E}_{x \sim p_\textrm{data}, (\tau, \tau_\gamma) \sim p_\tau, \epsilon \sim \mathcal{N}(0,I)} [\| y - g_{\theta, \phi} (x_\tau; c_{\tau_\gamma}, \tau_\gamma, \tau) \|_2^2] \\ c_{\tau_\gamma} = \alpha_{\tau_\gamma} x + \sigma_{\tau_\gamma} \epsilon, \quad \epsilon \sim \mathcal{N}(0,I) \end{equation}\]여기서 $c_{\tau_\gamma}$는 모델에 주어지는 noisy한 저해상도 이미지이고, $\tau_\gamma$는 저해상도 이미지에 더해진 noise의 양이다.
동영상 프레임을 독립적으로 업샘플링하면 시간적 일관성이 좋지 않기 때문에 이 SR 모델도 video-aware하도록 한다. 앞서 설명한 $l_\theta^i$와 $l_\phi^i$를 사용하는 메커니즘을 따르며, 유사하게 동영상은 upscaler를 fine-tuning하고 길이 $T$의 저해상도 시퀀스로 컨디셔닝하고 저해상도 동영상 이미지를 프레임별로 concat한다. Upscaler는 로컬에서 작동하기 때문에 모든 upscaler 학습을 패치에서만 효율적으로 수행하고 나중에 모델을 convolution하게 적용한다.
전반적으로 저자들은 LDM과 upsampler DM의 조합이 효율적인 고해상도 동영상 합성에 이상적이라고 믿는다. 한편으로 동영상 LDM의 주요 LDM 구성 요소는 계산 효율적이고 압축된 latent space를 활용하여 모든 동영상 모델링을 수행한다. 이를 통해 큰 batch size를 사용하고 더 많은 동영상 프레임을 공동으로 인코딩할 수 있으며, 이를 통해 모든 동영상 예측 및 보간이 latent space에서 수행되므로 과도한 메모리 요구 없이 장기적인 동영상 모델링에 도움이 된다. 반면에 upsampler는 효율적인 patch-wise 방식으로 학습될 수 있으므로 마찬가지로 계산 리소스를 절약하고 메모리 소비를 줄이며 저해상도 컨디셔닝으로 인해 장기적인 시간적 상관 관계를 캡처할 필요가 없다. 따라서 upsampler에는 예측 및 보간 프레임워크가 필요하지 않다.
Experiments
- 데이터셋
- 자체적인 real driving scene (RDS) 동영상
- WebVid-10M (Stable Diffusion에 사용)
- Mountain Biking dataset
1. High-Resolution Driving Video Synthesis
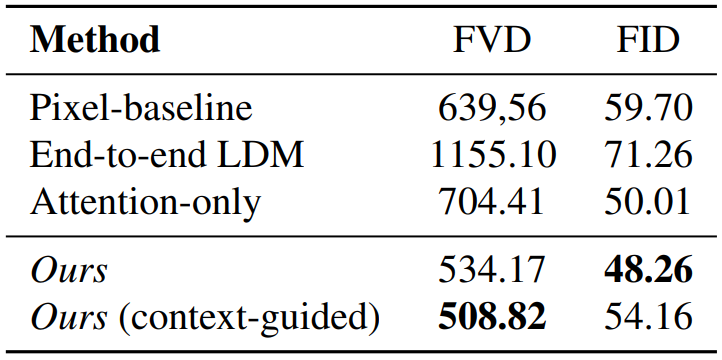
다음은 RDS에 대하여 LVG와 비교한 결과(왼쪽)와 ablation 결과(오른쪽)이다.

다음은 RDS에서 주행 동영상 합성에 대한 user study 결과이다.

다음은 RDS 데이터에서 diffusion upsampler에 대한 시간적 fine-tuning을 평가한 결과(왼쪽)와 1단계 디코더 네트워크의 동영상 fine-tuning을 평가한 결과(오른쪽)이다.


다음은 본 논문의 Video LDM과 동영상 upsampler로 생성한 512$\times$1024 주행 동영상이다. 상단은 주행 동영상을 생성한 것이고, 중간은 multimodal하게 주행 시나리오를 예측한 것이고, 하단은 특정 동영상 시나리오를 시뮬레이션한 것이다.

2. Text-to-Video with Stable Diffusion
다음은 Stable Diffusion 기반 Video LDM으로 생성한 1280$\times$2048 해상도의 샘플들이다.

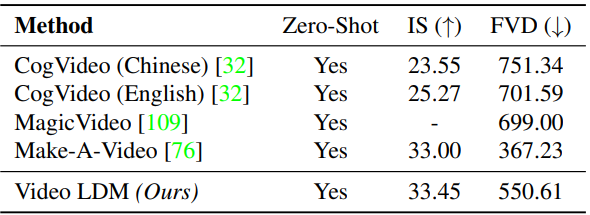
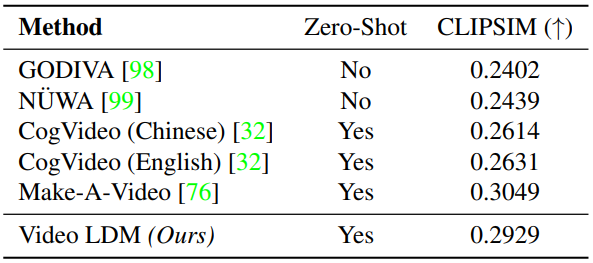
다음은 UCF-101(왼쪽)과 MSR-VTT(오른쪽)에 대하여 text-to-video 생성의 성능을 평가한 표이다.
다음은 DreamBooth를 사용하여 개인화된 text-to-video를 구현한 것이다. 왼쪽은 DreamBooth 학습 이미지이다. 오른쪽의 상단은 Video LDM과 DreamBooth 이미지 LDM backbone으로 생성한 동영상이고, 오른쪽 하단은 DreamBooth 이미지 backbone 없이 생성한 동영상이다.
