[논문리뷰] Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
CVPR 2023. [Paper] [Page] [Github]
Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, Antoine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, Cordelia Schmid
Google Research | PSL Research University | DeepMind | Czech Institute of Informatics, Robotics and Cybernetics
27 Feb 2023

Introduction
Dense video captioning은 다듬어지지 않은 동영상의 모든 이벤트에 대한 시간적 localization과 captioning이 필요하다. 이는 주어진 짧은 동영상 클립에 대해 하나의 캡션을 생성하는 것이 목표인 표준 video captioning과는 다르다. Dense captioning은 몇 분 길이의 동영상에서 이벤트 위치를 파악하는 데 추가적인 복잡도를 증가시키기 때문에 훨씬 더 어렵다. 그러나 장거리 동영상 정보의 이점도 있다. 이 task는 동영상 콘텐츠가 클립으로 분할되지 않는 대규모 동영상 검색이나 인덱싱과 같은 애플리케이션에서 잠재적으로 매우 유용하다.
기존 방법은 대부분 이벤트를 먼저 localize한 다음 캡션을 추가하는 2단계 접근 방식에 의존한다. 이벤트 localization과 captioning 사이의 task 간 상호 작용을 더욱 향상시키기 위해 일부 접근 방식에서는 두 task를 공동으로 해결하는 모델을 도입했다. 그러나 이러한 접근 방식에는 이벤트 카운터와 같은 task별 구성 요소가 필요한 경우가 많다. 또한 제한된 크기의 수동으로 주석이 달린 데이터셋에 대해서만 학습하므로 task를 효과적으로 해결하기가 어렵다. 이러한 문제를 해결하기 위해 본 논문은 광범위한 비전 및 언어 task에서 성공적인 웹 데이터를 기반으로 사전 학습된 최신 sequence-to-sequence 모델에서 영감을 얻었다.
먼저 Vid2Seq라는 동영상 언어 모델을 제안한다. 웹 텍스트에 대해 학습된 언어 모델에서 시작하여 동영상의 타임스탬프를 나타내는 특수 시간 토큰으로 이를 확장한다. 동영상 프레임과 기록된 음성 입력이 주어지면 결과 모델은 이산 토큰의 단일 시퀀스를 생성하여 모든 이벤트 캡션과 해당 시간 경계를 공동으로 예측한다. 따라서 이러한 모델은 attention을 통해 동영상의 다양한 이벤트 간의 멀티모달 의존성을 학습할 수 있는 잠재력을 가지고 있다. 그러나 이를 위해서는 현재의 dense video captioning 데이터셋에서는 사용할 수 없는 대규모 학습 데이터가 필요하다. 더욱이, 동영상에 대한 dense captioning의 주석을 수동으로 수집하는 것은 비용이 많이 들고 규모도 엄청나다.
따라서 대규모로 쉽게 사용할 수 있는 레이블이 없는 나레이션 동영상을 활용하여 Vid2Seq를 사전 학습한다. 이를 위해 전사된 음성의 문장 경계를 pseudo event 경계로 재구성하고, 전사된 음성 문장을 pseudo event 캡션으로 사용한다. 그런 다음 시각적 입력이 주어지면 전사된 음성을 예측해야 하는 생성 목적 함수와 전사된 음성의 범위를 마스킹하는 denoising 목적 함수를 사용하여 Vid2Seq를 사전 학습한다. 텍스트로 작성된 음성은 동영상 콘텐츠를 충실하게 설명하지 못할 수 있으며 시각적 스트림과 일시적으로 잘못 정렬되는 경우가 많다. 직관적으로 Vid2Seq는 모든 나레이션과 동영상의 해당 타임스탬프를 공동으로 모델링하므로 noisy supervision으로부터 학습하는 데 특히 적합하다.
저자들은 광범위한 실험을 통해 사전 학습된 모델의 효율성을 입증하였다. 자르지 않은 나레이션 동영상에 대한 사전 학습의 중요성, 시각 및 음성 modality를 모두 사용하는 Vid2Seq의 능력, 사전 학습 목적 함수의 중요성, 공동 캡션 생성과 localization의 이점, 언어 모델 크기, 사전 학습 데이터셋의 규모의 중요성을 보여준다. 사전 학습된 Vid2Seq 모델은 다양한 dense video captioning 벤치마크에서 SOTA를 달성하였다. 또한 동영상을 설명하는 텍스트 단락을 생성하는 데 탁월하다. 더욱이 Vid2Seq는 동영상 클립 캡션 작성의 표준 task를 잘 일반화한다.
Method
Dense video captioning의 목표는 다듬어지지 않은 입력 동영상의 모든 이벤트를 시간적으로 localize하고 자연어로 설명하는 것이다. 따라서 핵심 과제는 동영상의 다양한 이벤트 간의 관계를 효과적으로 모델링하는 것이다. 게다가 task가 dense하기 때문에 긴 동영상에는 많은 이벤트가 포함될 수 있으며, 각 이벤트에 대해 자연어 캡션을 출력하는 것이 요구된다. 따라서 또 다른 주요 과제는 이 task에 대한 주석을 수동으로 수집하는 데 특히 비용이 많이 든다는 것이다. 이러한 문제를 해결하기 위해 이벤트 경계와 캡션을 단일 토큰 시퀀스로 공동 예측하는 통합 멀티모달 모델을 개발한다. 그런 다음 cross-modal supervision을 효과적으로 활용하는 사전 학습 전략을 설계한다. 문장 경계를 pseudo event 경계로 재구성하여 레이블이 지정되지 않은 나레이션 동영상에서 전사된 음성 형태로 supervise한다.
1. Model
본 논문은 시각적 신호와 전사된 음성 신호를 사용하여 이벤트 간의 관계를 캡처할 수 있는 dense video captioning 모델을 설계하여 자르지 않은 몇 분 길이의 동영상에서 이러한 이벤트를 효과적으로 localize하고 설명하려고 한다. 이 문제를 해결하기 위해 입력 및 출력 시퀀스에 자연어 설명 형식의 이벤트에 대한 semantic 정보와 시간적 타임스탬프 형식의 이벤트에 대한 시간적 localization이 모두 포함되는 sequence-to-sequence 문제로 dense video captioning을 적용했다. 또한 시각적 신호와 언어 신호를 모두 최대한 활용하기 위해 적절한 멀티모달 인코더-디코더 아키텍처를 개발하였다.
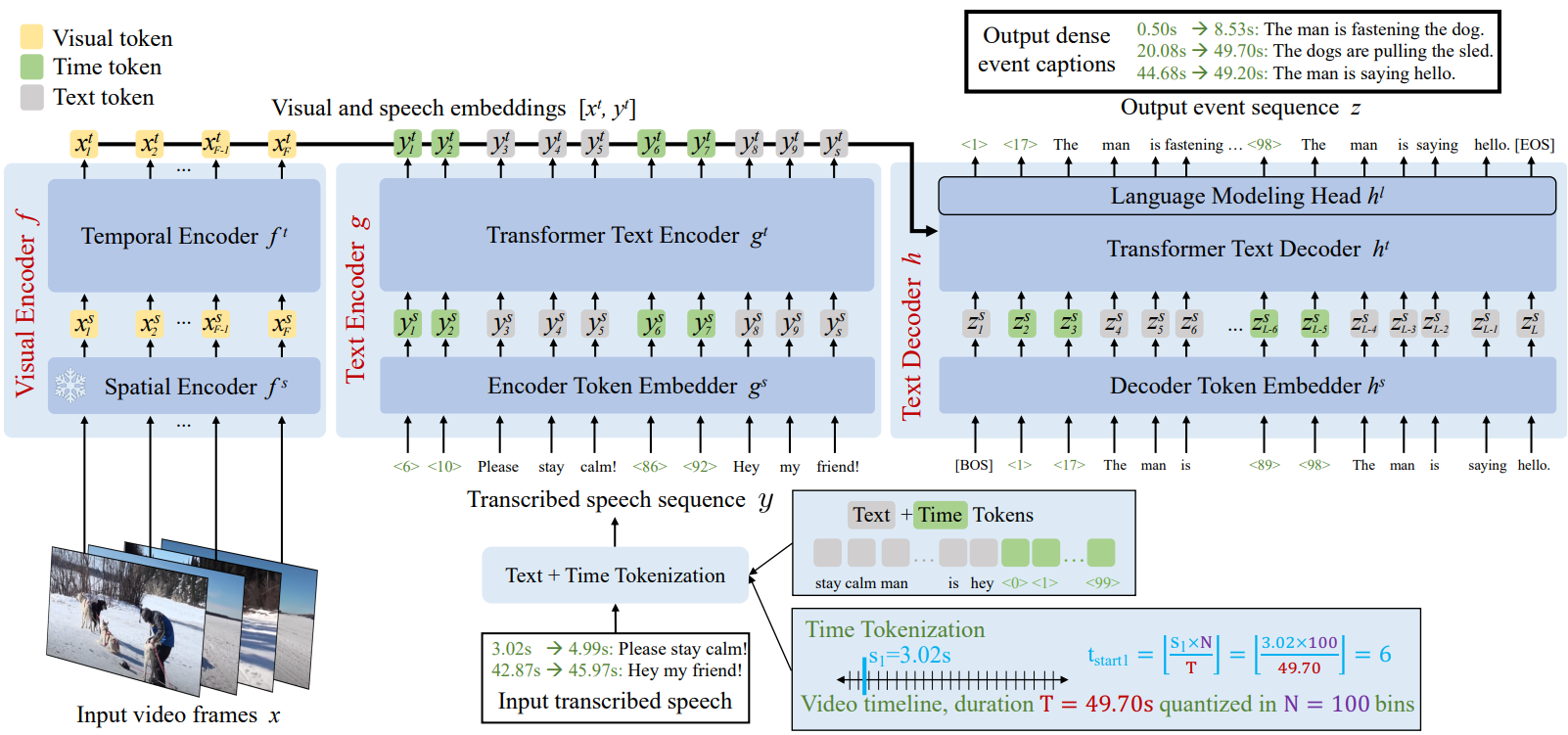
위 그림에서 볼 수 있듯이 Vid2Seq의 아키텍처는 입력 동영상 프레임 \(x = \{x_i\}_{i=1}^F\)과 전사된 음성 시퀀스 \(y = \{y_j\}_{j=1}^S\)를 사용한다. 모델의 출력은 이벤트 시퀀스 \(z = \{z_k\}_{k=1}^L\)이다. 여기서 각 이벤트에는 텍스트 설명과 동영상의 시간적 이벤트 위치에 해당하는 타임스탬프가 모두 포함되어 있다.
1.1 Sequence construction
Dense event captioning 주석 (또는 쉽게 사용할 수 있는 전사 나레이션)에서 이벤트 간 관계를 모델링하기 위해 dense video captioning을 토큰 $z$의 단일 출력 시퀀스를 예측하는 것으로 캐스팅한다. 이 출력 이벤트 시퀀스는 특수 시간 토큰으로 보강된 텍스트 토크나이저를 활용하여 구성된다. 또한, 이벤트 시퀀스 $z$와 유사한 방식으로 입력 전사 시퀀스 $y$를 구성하여 입력 나레이션의 전사에 제공된 semantic 정보와 시간 정보에 대해 공동으로 추론할 수 있는 아키텍처를 활성화한다.
Time tokenization
Vocabulary 크기가 $V$인 텍스트 토크나이저에서 시작하여 $N$개의 추가 시간 토큰으로 이를 보강하여 $V + N$ 토큰을 갖는 토크나이저를 만든다. 시간 토큰은 duration $T$의 동영상을 $N$개의 동일한 간격의 타임스탬프로 quantize하므로 동영상의 상대적인 타임스탬프를 나타낸다. 구체적으로 vocabulary 크기 $V = 32128$와 $N = 100$인 SentencePiece 토크나이저를 사용한다.
Event sequence
위에서 설명한 토크나이저를 사용하면 동영상 타임스탬프와 텍스트 동영상 설명을 모두 포함하는 시퀀스를 구성할 수 있다. 표준 dense video captioning 데이터샛에서는 동영상에 이벤트 수가 다양하다. 각 이벤트 $k$는 텍스트 세그먼트, 시작 시간, 종료 시간으로 특징지어진다. 먼저 시작 시간 토큰 \(t_{\textrm{start}_k}\), 종료 시간 토큰 \(t_{\textrm{end}_k}\), 텍스트 토큰 $[z_{k_1}, \ldots, z_{k_{l_k}}]$을 concat하여 각 이벤트 $k$에 대해 시퀀스를 구성한다. 그런 다음 시작 시간의 오름차순으로 모든 시퀀스를 정렬하고 concat한다. 실제로 각 텍스트 세그먼트는 서로 다른 이벤트 간의 구분을 나타내는 점 기호로 끝난다. 마지막으로 이벤트 시퀀스는 각각 시퀀스의 시작과 끝을 나타내는 $\textrm{BOS}$ 토큰과 $\textrm{EOS}$ 토큰을 추가하여 얻는다.
\[\begin{equation} z = [\textrm{BOS}, t_{\textrm{start}_1}, t_{\textrm{end}_1}, z_{1_1}, \ldots, z_{1_{l_1}}, t_{\textrm{start}_2}, \ldots, \textrm{EOS}] \end{equation}\]Transcribed speech sequence
모델이 전사된 음성과 해당 타임스탬프를 모두 사용할 수 있도록 하기 위해 입력 이벤트 캡션 $z$와 유사하게 음성 전사를 음성 시퀀스 $y$로 변환한다. 이는 Google Cloud API를 사용하여 음성 전사를 문장으로 분할하고, 이벤트 시퀀스와 유사하게 해당 타임스탬프가 있는 각 전사된 음성 문장을 사용하여 시퀀스로 변환한다.
1.2 Architecture
자르지 않은 몇 분 길이의 동영상에서 다양한 이벤트 간의 관계를 효과적으로 모델링할 수 있는 아키텍처를 설계하는 것이 목표이다. 이를 위해 본 논문은 위에서 설명한 이벤트 시퀀스를 점진적으로 개선하고 출력하는 멀티모달 인코더-디코더 아키텍처를 제안한다. 자세히 설명하면, 자르지 않은 몇 분 길이의 동영상이 있는 경우 시각적 인코더 $f$는 프레임을 삽입하고 텍스트 인코더 $g$는 전사된 음성과 해당 타임스탬프를 삽입한다. 그런 다음 텍스트 디코더 $h$는 시각적 임베딩과 전사된 음성 임베딩을 사용하여 이벤트 경계와 텍스트 캡션을 예측한다.
Visual encoder
시각적 인코더는 $F$개의 프레임으로 구성된 시퀀스 $x \in \mathbb{R}^{F \times H \times W \times C}$에서 작동한다. 여기서 $H$, $W$, $C$는 각 프레임의 높이, 너비, 채널 수이다. Visual backbone $f^s$는 먼저 각 프레임을 개별적으로 인코딩하고 프레임 임베딩 $x^s = f^s (x) \in \mathbb{R}^{F \times d}$를 출력한다. 여기서 $d$는 임베딩 차원이다. 그런 다음 transformer 인코더 $f^t$는 서로 다른 프레임 간의 시간적 상호 작용을 모델링하고 $F$개의 맥락화된 시각적 임베딩 $x^t = f^t (x^s + x^p) \in \mathbb{R}^{F \times d}$를 출력한다. 여기서 $x^p \in \mathbb{R}^{F \times d}$는 학습된 시간적 위치 임베딩이며, 시각적 입력에서 모델로 시간 정보를 전달한다. 세부적으로 visual backbone은 해상도 224$\times$224 픽셀의 CLIP ViT-L/14이며, 웹에서 스크랩한 이미지-텍스트 쌍의 contrastive loss를 사용하여 이미지를 텍스트 설명에 매핑하도록 사전 학습되었다. 효율성을 위해 backbone을 동결된 상태로 유지한다.
Text encoder
텍스트 인코더는 $S$개의 토큰으로 구성된 전사된 음성 시퀀스 \(y \in \{1, \ldots, V+N\}^S\)에서 작동한다. 여기서 $V$는 텍스트 vocabulary 크기, N은 시간 토큰 vocabulary 크기, $S$는 전사된 음성 시퀀스의 토큰 수이다. 전사된 음성 시퀀스에는 전사된 음성의 시간 정보를 모델에 입력하기 위한 시간 토큰이 포함되어 있다. 임베딩 레이어 $g^s \in \mathbb{R}^{(V+N) \times d}$는 각 토큰을 독립적으로 임베딩하고 semantic 임베딩 $y^s = g^s (y) \in \mathbb{R}^{S \times d}$를 출력한다. 그런 다음 transformer 인코더 $g^t$는 전사된 음성 시퀀스의 상호 작용을 계산하고 $S$개의 맥락화된 음성 임베딩 $y^t = g^t (y^s) \in \mathbb{R}^{S \times d}$를 출력한다.
Text decoder
텍스트 디코더는 시각적 임베딩 $x^t$와 음성 임베딩 $y^t$를 연결하여 얻은 인코더 임베딩을 사용하여 이벤트 시퀀스 $z$를 생성한다. 텍스트 디코더는 인코더 출력에 cross-attend하는 causal transformer decoder $h^t$를 기반으로 하며 각 autoregressive step $k$에서 이전에 생성된 토큰 \(\hat{z}_{< k}^t\)에 self-attend하여 맥락화된 표현
\[\begin{equation} z_k^t = h^t (h^s (\hat{z}_{< k}^t), x^t , y^t) \in \mathbb{R}^d \end{equation}\]를 출력한다. 여기서 $h^s \in \mathbb{R}^{(V+N) \times d}$는 디코더 토큰 임베딩 레이어다. 그런 다음 언어 모델링 head $h^l \in \mathbb{R}^{d \times (V+N)}$은 이벤트 시퀀스에서 다음 토큰을 예측하기 위해 텍스트와 시간 토큰의 공동 vocabulary에 대한 확률 분포를 예측한다.
\[\begin{equation} z_k^l= h^l (z_k^t) \in \mathbb{R}^{V+N} \end{equation}\]Text initialization
웹 텍스트 코퍼스에 대해 denoising loss로 사전 학습된 T5-Base를 사용하여 텍스트 인코더와 텍스트 디코더를 초기화한다. 따라서 구현과 파라미터도 T5-Base를 밀접하게 따른다. T5는 상대 위치 임베딩을 사용하고 토큰 임베딩 레이어를 공유한다.
\[\begin{equation} g^s = h^s \in \mathbb{R}^{(V+N) \times d} \end{equation}\]2. Training
2.1 Pretraining on untrimmed narrated videos
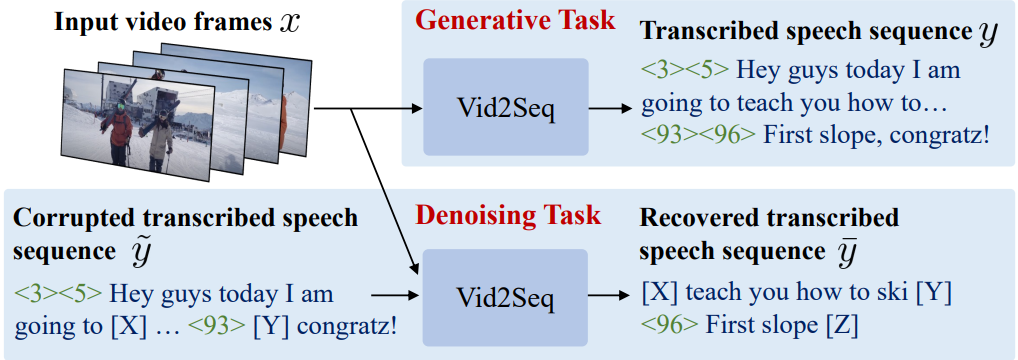
저자들은 대규모로 쉽게 사용할 수 있는 나레이션 동영상을 사전 학습에 활용하고자 하였다. 그러나 이러한 동영상에는 dense event captioning 주석이 포함되어 있지 않다. 따라서 전사된 음성 문장과 해당 타임스탬프를 supervision 신호로 사용한다. 음성 기록은 항상 시각적으로 근거가 있는 것은 아니며 시간적으로 잘못 정렬되는 경우가 많기 때문에 weak supervision만을 제공한다. 게다가 음성 기록은 dense event captioning 주석과 크게 다르다. 예를 들어 YT-Temporal-1B 데이터셋에서 동영상에는 평균 120개의 음성 문장이 포함되어 있으며 이는 표준 dense video captioning 데이터셋의 이벤트 수보다 훨씬 더 많다. Vid2Seq 모델은 수동으로 주석을 추가한 이벤트 시퀀스와 유사하게 음성 시퀀스를 구성하고 더 짧은 클립이 아닌 잠재적으로 몇 분 길이의 동영상에서 음성 경계와 semantic 정보를 공동으로 맥락화하므로 weak supervision을 사용하는 데 특히 적합하다. 이는 모델이 다양한 음성 세그먼트 간의 장기적인 관계를 학습할 수 있도록 한다.
본 논문은 maximum likelihood 목적 함수를 기반으로 하는 두 가지 목적 함수를 제안하였다. 시각적 입력 $x$, 인코더 텍스트 시퀀스 $y$, 디코더 타겟 텍스트 시퀀스 $z$가 주어지면 두 목적 함수 모두 다음 loss를 최소화하는 데 기반을 둔다.
\[\begin{equation} \mathcal{L}_\theta (x, y, z) = - \frac{1}{\sum_{k=1}^{L-1} w_k} \sum_{k=1}^{L-1} w_k \log p_\theta (z_{k+1} \vert x, y, z_{1:k}) \end{equation}\]여기서 $L$은 디코더 타겟 시퀀스의 길이이고, $w_k$는 시퀀스의 $k$번째 토큰에 대한 가중치이며 실제로는 모든 $k$에 대하여 $w_k = 1$로 설정되었다. $\theta$는 모델에서 학습 가능한 파라미터를 나타내고 $p_\theta$는 텍스트와 시간 토큰의 vocabulary에 대한 출력 확률 분포이다.
Generative objective
생성 목적 함수는 전사된 음성을 (pseudo-)supervision 신호로 사용하여 디코더가 시각적 입력에 따라 일련의 이벤트를 예측하도록 학습시킨다. 인코더에 공급되는 동영상 프레임 $x$가 주어지면 디코더는 dense event captioning 주석 역할을 하는 전사된 음성 시퀀스 $y$를 예측해야 한다. 입력과 타겟 모두로 전사된 음성을 사용하면 모델이 text-only shortcut을 학습하게 되므로 이 task에서는 인코더에 텍스트 입력이 제공되지 않는다.
Denoising objective
생성 task를 위해 인코더에 텍스트 입력이 제공되지 않으므로 생성 목적 함수는 시각적 인코더와 텍스트 디코더만 학습시키고 텍스트 인코더는 학습시키지 않는다. 그러나 모델이 dense video captioning에 사용되는 경우 텍스트 인코더는 음성 전사를 인코딩하므로 매우 중요하다. 따라서 시각적 인코더, 텍스트 인코더, 텍스트 디코더를 공동으로 정렬하는 것을 목표로 하는 denoising 목적 함수를 도입한다. 텍스트 도메인의 T5에서 영감을 받아 전사된 음성 시퀀스의 토큰 범위를 확률 $P$와 평균 범위 길이 $M$으로 랜덤하게 마스킹한다. 인코더 입력은 동영상 프레임 $x$와 손상된 음성 시퀀스 $\tilde{y}$로 구성된다. 여기서 $\tilde{y}$는 마스킹된 범위를 고유하게 식별하는 sentinel token이 포함되어 있다. 그런 다음 디코더는 시각적 입력 $x$와 음성 컨텍스트 $\tilde{y}$를 기반으로 각 sentinel token에 대해 해당 마스크 범위로 구성된 시퀀스 $\bar{y}$를 예측해야 한다.
2.2 Downstream task adaptation
본 논문의 아키텍처와 task 공식을 사용해 일반적인 언어 모델링 목적 함수와 inference 절차를 통해 dense video captioning을 처리할 수 있다. 모델은 출력 시퀀스에서 시간 토큰을 간단히 제거하여 전체 동영상에 대한 단락을 생성하는 데에도 사용할 수 있으며 동일한 finetuning과 inference 방법을 적용할 수 있다.
Finetuning
Dense video captioning을 위한 모델을 finetuning하기 위해 이벤트 시퀀스를 기반으로 하는 maximum likelihood 목적 함수를 사용한다. 동영상 프레임 $x$와 음성 전사 $y$가 주어지면 디코더는 이벤트 시퀀스 $z$를 예측해야 한다.
Inference
텍스트 디코더는 모델 likelihood에서 샘플링하여 이벤트 시퀀스를 autoregressive하게 생성한다. 실제로 beam search를 사용하여 argmax sampling이나 nucleus sampling에 비해 캡션 품질을 향상시킨다. 마지막으로, 이벤트 시퀀스는 단순히 시퀀스 구성 프로세스를 역순으로 수행하여 일련의 이벤트 예측으로 변환된다.
Experiments
- 데이터셋: YT-Temporal-1B, YouCook2, ViTT, ActivityNet Captions, MSR-VTT, MSVD
- 구현 디테일
- 1FPS에서 동영상 프레임을 추출하고 프레임 시퀀스를 $F = 100$으로 서브샘플링하거나 패딩
- 텍스트 인코더와 디코더 시퀀스는 $L = S = 1000$개의 토큰으로 잘리거나 패딩
- 학습 가능한 파라미터: 3.14억 개
- optimizer: Adam
- batch size: 512개의 video split (64개의 TPU v4 칩에 분할)
- iteration: 200,000 (1일 소요)
- 사전 학습 loss: 두 목적 함수를 동일한 가중치로 합산
1. Ablation studies
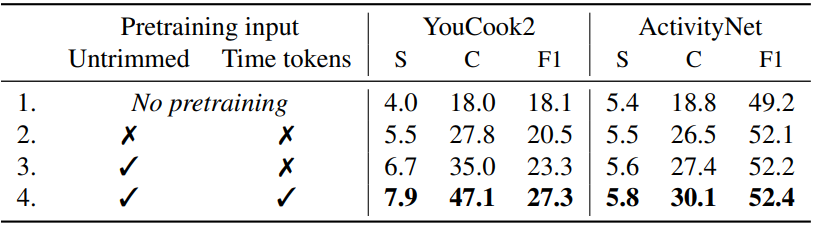
다음은 자르지 않은 동영상 사용과 사전 학습 중 시간 토큰 추가에 대한 ablation 결과이다.
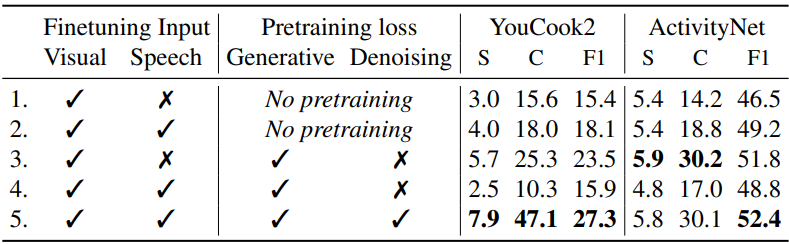
다음은 입력 modality와 사전 학습 loss들에 대한 ablation 결과이다.
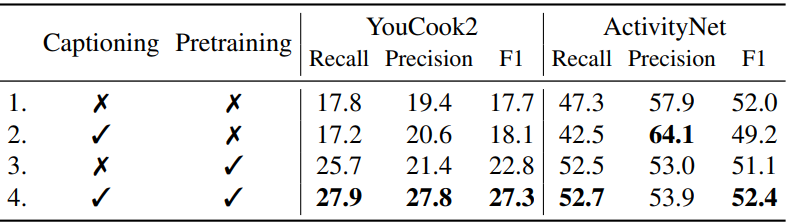
다음은 공동 captioning과 localization에 대한 ablation 결과이다.
다음은 언어 모델 크기와 사전 학습 데이터에 대한 ablation 결과이다. (HTM: HowTo100M, YTT: YT-Temporal-1B)

2. Comparison to the state of the art
다음은 dense video captioning에 대한 SOTA와의 비교 결과이다.

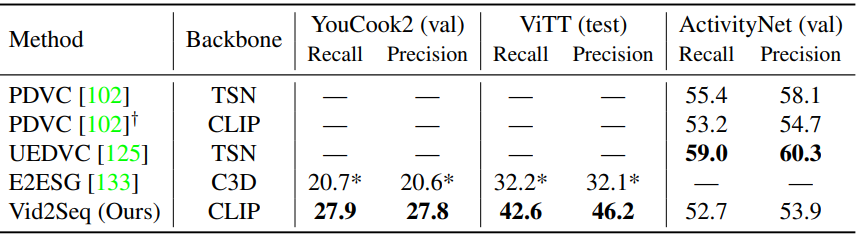
다음은 이벤트 localization에 대한 SOTA와의 비교 결과이다.
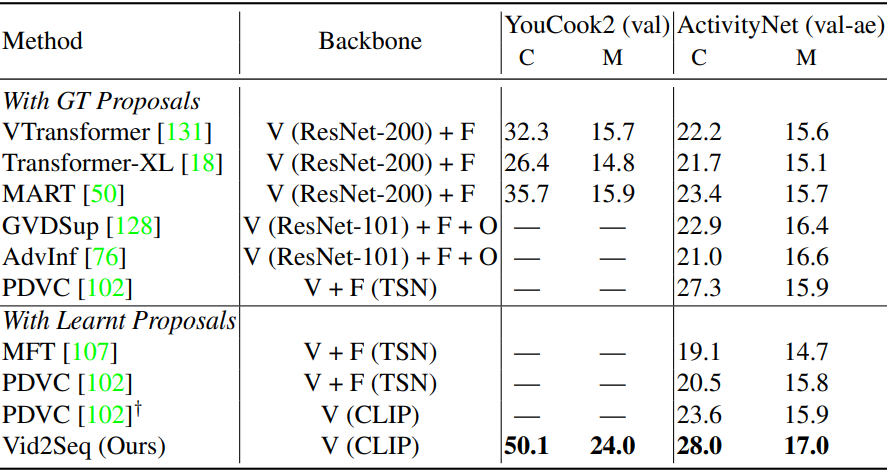
다음은 동영상 단락 captioning에 대한 SOTA와의 비교 결과이다.
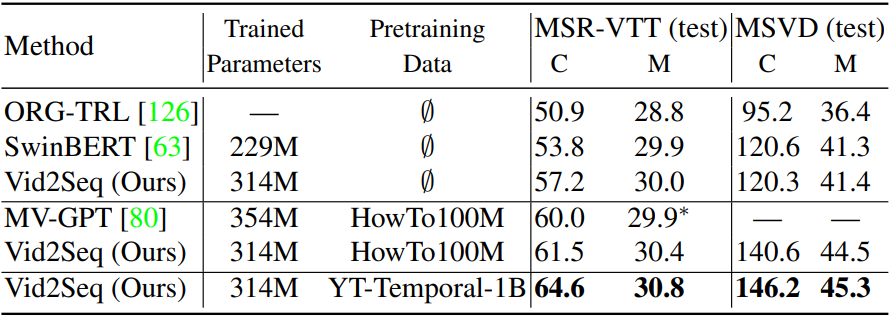
다음은 동영상 클립 captioning에 대한 SOTA와의 비교 결과이다.
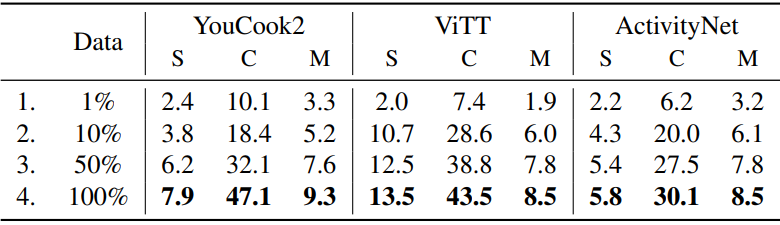
3. Few-shot dense video captioning
다음은 다운스트림 학습 데이터셋의 작은 부분을 사용하여 Vid2Seq를 finetuning한 결과이다.
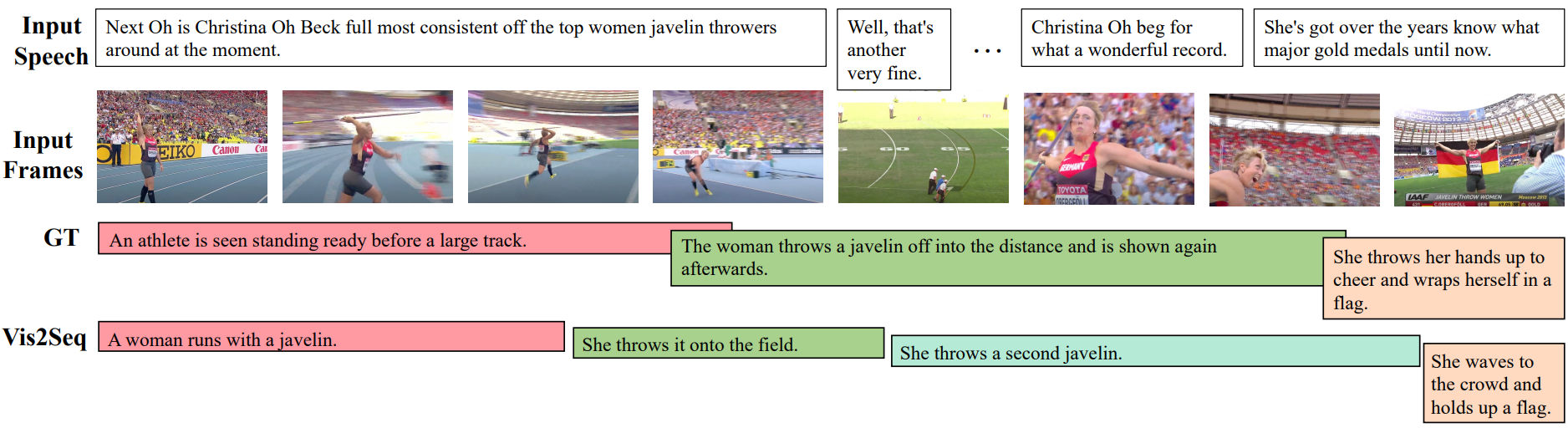
4. Qualitative examples
다음은 ActivityNet Captions validation set에서의 Vid2Seq의 예측 결과를 ground truth와 비교한 예시이다.