[논문리뷰] Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
ICCV 2023. [Paper] [Github]
Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi
SHI Labs | UT Austin | Picsart AI Research
15 Nov 2022

Introduction
Multi-modality는 범용 AI를 달성하기 위한 최고의 보석이다. 딥 러닝의 특성을 통해 분류, 탐지, 분할 등과 같은 전통적인 task를 위해 설계된 방법은 거의 인간 수준의 정확도에 도달했다. 또한 멀티모달 연구는 주로 멀티모달 데이터를 공동으로 인식, 일치 또는 이해하는 판별적 task에 중점을 두었다. 그럼에도 불구하고 멀티모달 생성 모델에 대한 연구는 여전히 부족하다. 이전에 가장 성능이 좋은 생성 비전 모델인 GAN은 특정 영역(ex. 얼굴, 글꼴, 자연 장면 등)이나 특정 task (인페인팅, super-resolution, image-to-image translation 등)에만 초점을 맞춘다.
Diffusion model의 최근 성공은 새로운 지평을 열었다. Diffusion model은 가우시안 손상으로부터 이미지 콘텐츠를 점진적으로 복원하는 likelihood 기반 모델이다. 예를 들어 unconditional한 생성, 밀도 추정, super-resolution, text-to-image 생성과 같은 방식과 task를 연결하는 데 효과적인 것으로 입증되었다. Diffusion model의 성공은 여러 측면에 기인할 수 있다.
첫째, 목적 함수는 GAN과 같은 다른 접근 방식보다 더 강력한 학습 절차로 이어진다. 반복적인 정제 inference 절차는 실행 시간이 늘어나는 대신 모델의 능력을 확장한다. 또한 DALL-E 2, Imagen, Stable Diffusion과 같은 최신 diffusion model의 경쟁력 있는 성능은 LAION, CC12M, COYO 등과 같은 놀라운 데이터 수집에서 이점을 얻는다. 데이터 부족 및 높은 inference 비용과 같은 초기 diffusion model의 단점은 보다 효율적인 구조와 스케줄러에 의해 점차 완화되었다. Diffusion 기반 text-to-image 방식은 틀림없이 멀티모달 생성 AI를 위한 새로운 SOTA이다. 그러나 이러한 연구들은 거의 전적으로 single-flow diffusion 파이프라인에 달려 있다. 한편, 대부분은 cross-modality임에도 불구하고 하나의 특수 생성 task에 대해 학습되고 평가된다.
저자들은 범용 AI에서 멀티모달, 멀티태스크 모델의 중심 역할을 믿으며 diffusion model이 이를 가능하게 하는 유망한 일꾼이라고 생각한다. 본 논문은 이 목표를 달성하기 위해 하나의 통합 생성 모델 내에서 텍스트와 이미지들을 종합적으로 해결하는 Versatile Diffusion (VD)를 제안했다. 핵심 기본 기술은 새로운 multi-flow diffusion 프레임워크로, 기존 single-flow diffusion 파이프라인을 일반화하여 여러 modality와 task를 동시에 처리하면서 효율적으로 정보를 공유한다. 더 큰 용량과 crossmodal semantic 캡처 덕분에 VD는 앞서 언급한 지원되는 task를 잘 수행할 뿐만 아니라 특히 semantic-style disentanglement, cross-modal 이중 컨텍스트 또는 다중 컨텍스트 생성 (블렌딩)을 비롯한 많은 새로운 능력을 파생시켜 멀티모달 생성 AI에 대한 경험적 성능의 놀라운 발전을 이끈다.
Method
1. Diffusion basics
Forward diffusion process $p(x_T \vert x_0)$는 랜덤 Gaussian noise를 사용하여 $x_0$를 $x_T$로 점진적으로 저하시키는 $T$ step의 Markov Chain이다.
\[\begin{equation} q (x_T \vert x_0) = \prod_{t=1}^T q(x_t \vert x_{t-1}) = \prod_{t=1}^T \mathcal{N} (\sqrt{1 - \beta_t} x_{t-1}; \beta_t I) = \mathcal{N} (\sqrt{\vphantom{1} \bar{\alpha}_t} x_0; (1 - \bar{\alpha}_t) I) \\ \bar{\alpha}_t = \prod_{s=1}^t \alpha_s, \quad \alpha_t = 1 - \beta_t \end{equation}\]Forward diffusion process가 prior로 주어지면 diffusion model은 추가된 Gaussian noise를 제거하여 프로세스를 역전시키고 $x_T$에서 신호 $x_0$를 다시 복구하도록 학습된다. 이것은 reverse diffusion process로 알려져 있으며, 각 step $p_\theta (x_{t-1} \vert x_t)$는 네트워크 예측 평균 $\mu_\theta (x_t, t)$와 분산 $\Sigma_\theta (x_t, t)$를 사용하여 가우시안 분포에서 샘플링된다.
\[\begin{equation} p_\theta (x_{t-1} \vert x_t) = \mathcal{N} (\mu_\theta (x_t, t), \Sigma_\theta (x_t, t)) \end{equation}\]Diffusion model을 학습시키는 목적 함수는 negative log-likelihood에 대한 variational bound를 최소화하는 것이다. 실제로 많은 연구들에서 step $t$에 대해 deterministic한 $\alpha_t$와 $\beta_t$를 가정한다. Forward process와 reverse process가 모두 가우시안 프로세스라는 점을 감안할 때 목적 함수는 ground truth와 예측 평균 사이의 가중된 $l_2$ loss로 단순화할 수 있다.
\[\begin{equation} L = \mathbb{E} [- \log p_\theta (x_0)] \le \mathbb{E} \bigg[ - \log \frac{p_\theta (x_{0:T})}{q (x_{1:T} \vert x_0)} \bigg] \end{equation}\]2. Multi-flow multimodal diffusion framework
Versatile Diffusion (VD)의 핵심 부분은 다양한 crossmodal 컨텍스트에 따라 다양한 형태의 출력을 생성할 수 있는 multi-flow 멀티모달 diffusion 프레임워크이다. VD에서 single-flow의 공식적인 정의는 modality $m$의 컨텍스트를 사용하여 modality $n$의 feature를 합성하는 것이다. 잘 탐색된 text-to-image task, 즉 텍스트 프롬프트 기반의 이미지 합성이 VD의 single-flow 정의와 일치한다는 것을 알 수 있다. 그러나 VD의 범위는 하나의 단일 task를 넘어선다. 특히 이 task에서 VD는 text-to-image, image-to-text, image-variation과 같은 다양한 task를 수행하도록 설정되었으며 3D, 오디오, 음악 등과 같은 더 많은 modality를 포함하도록 확장될 수 있다.
VD는 입력 컨텍스트와 출력 결과의 modality에 따라 레이어를 활성화하거나 무시할 수 있는 multi-flow 프레임워크로 인해 crossmodal task 그룹을 처리한다.
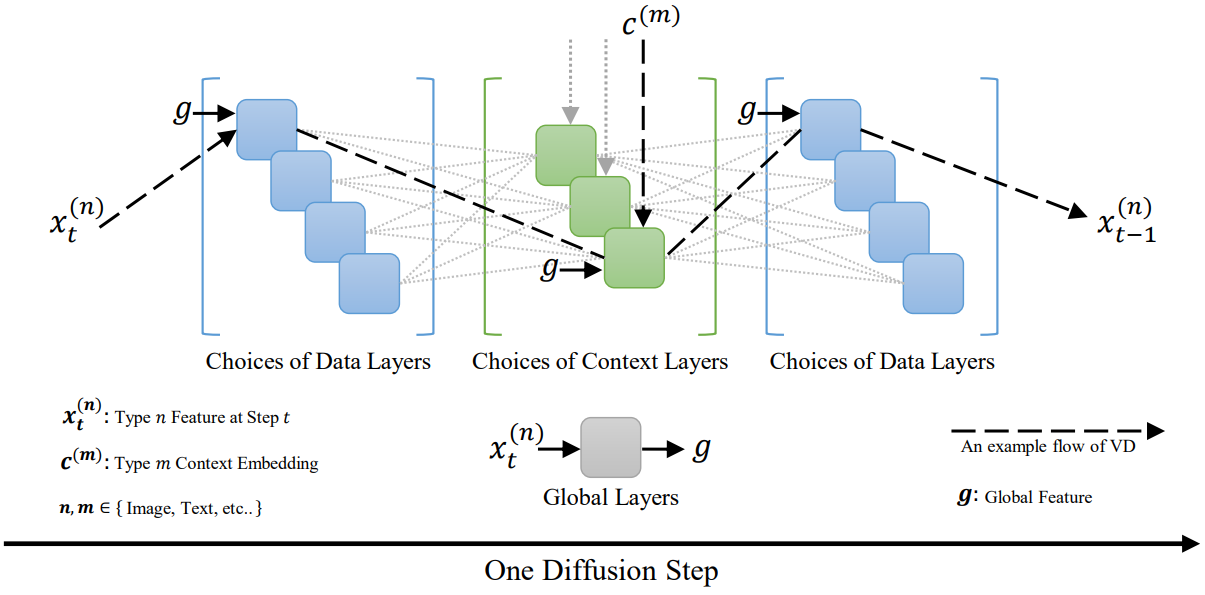
위 그림과 같이 모든 diffuser 레이어를 글로벌 레이어, 데이터 레이어, 컨텍스트 레이어의 세 그룹으로 분류한다. 글로벌 레이어는 항상 활성화되는 flow 독립적 레이어이다. 데이터 레이어는 네트워크가 해당 출력 유형을 생성할 때 활성화되는 출력 종속 레이어이다. 마지막으로 컨텍스트 레이어는 해당 컨텍스트 유형이 입력되면 활성화되는 컨텍스트 종속 레이어이다. Stable Diffusion을 예로 들면, 글로벌 레이어는 시간 임베딩 레이어, 데이터 레이어는 residual block, 컨텍스트 레이어는 cross-attention들이다. VD의 한 flow는 공유된 글로벌 레이어와 선택한 데이터 및 컨텍스트 레이어를 통해 feed-forward pass를 라우팅하는 반면 다른 관련 없는 레이어는 침묵을 유지한다.
이러한 multi-flow 멀티모달 프레임워크는 파라미터 공유를 크게 촉진한다는 것을 알 수 있다. 본 논문에서 기본 VD 설정은 4-flow 모델이다. 이러한 4-flow VD를 복제하려면 총 4개의 diffusion model (즉, SD 크기의 4배)이 필요한 반면 VD는 프레임워크의 공유 레이어를 통해 파라미터 수를 절반으로 줄인다. 보다 일반화된 버전의 VD는 $N$개의 출력 타입과 $M$개의 컨텍스트 타입으로 $N \times M$개의 crossmodal task를 처리한다. 그러면 모델의 크기는 $O(\max (N, M))$가 되며, 이는 $O(N \times M)$의 누적 크기가 필요한 모델 앙상블보다 훨씬 작다.
3. Versatile Diffusion
Tasks
앞서 언급했듯이 Versatile Diffusion은 text-to-image, image-to-text, image-variation을 위한 통합 diffusion model이다. Text-to-image와 image-to-text는 전자가 텍스트 프롬프트에서 이미지를 생성하고 후자는 이미지 캡션을 생성하는 두 가지 잘 알려진 task이다. Image-variation (IV)은 사용자가 레퍼런스 이미지와 의미적으로 유사한 새 이미지를 생성하는 상당히 새로운 task이다. IV는 SD의 I2I (image-to-image)와 두 가지 점에서 다르다.
- IV는 순수 noise에서 diffuse되는 반면 I2I는 noise가 반쯤 혼합된 이미지에서 diffuse된다.
- IV는 높은 수준의 semantic을 유지하지만 낮은 수준의 구조를 완화하는 반면 I2I는 낮은 수준의 구조만 복제하고 높은 수준의 semantic을 보장하지 않는다.
VD는 레퍼런스 텍스트에서 유사한 표현을 생성하는 것이 목표인 multi-flow 특성으로 인해 텍스트의 변형을 생성할 수도 있다.
Network
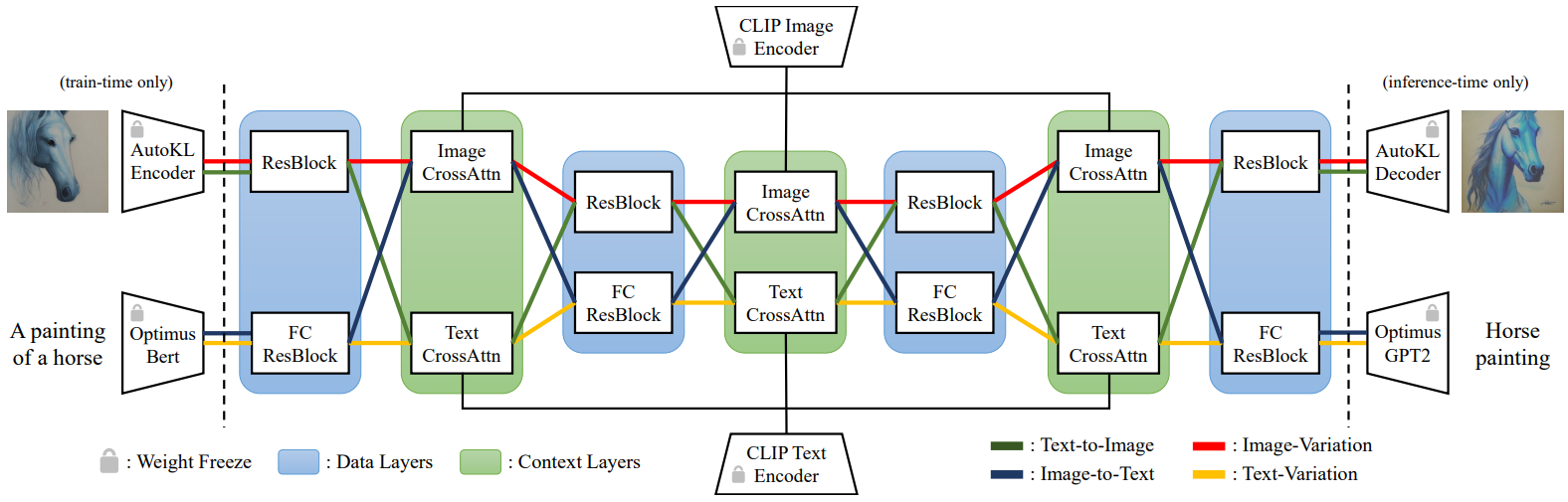
VD의 전체 모델에는 세 가지 구성 요소가 포함된다.
- Multi-flow 멀티모달 프레임워크를 따르는 diffuser
- 데이터 샘플을 latent 표현으로 변환하는 VAE
- 컨텍스트를 임베딩으로 인코딩하는 컨텍스트 인코더
전체 네트워크 다이어그램은 위 그림에 나와 있다.
Diffuser: Diffuser 네트워크의 주요 구조로 잘 채택된 UNet을 cross-attention과 함께 사용한다. UNet의 일부는 SD를 따르며 residual block을 이미지 데이터 레이어로 채택하고 cross-attention을 텍스트 및 이미지 컨텍스트 레이어로 채택한다. 텍스트 데이터 레이어의 경우 768차원 텍스트 latent 벡터를 320$\times$4 hidden feature로 확장하고 GroupNorms, SiLU, skip connection을 사용하여 유사한 residual block 패러다임을 따르는 fully connected residual blocks (FCResBlock)을 제안한다 (아래 그림 참조).
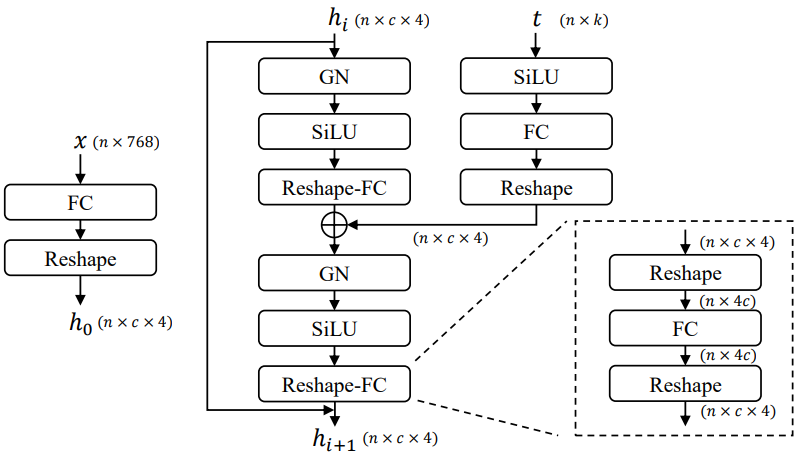
VAE: SD와 동일한 Autoencoder-KL을 이미지 VAE로 채택한다. 동시에 Optimus를 텍스트 VAE로 채택한다. Optimus는 Bert 텍스트 인코더와 GPT2 텍스트 디코더로 구성되어 있으며 이를 통해 문장을 768차원 정규분포 latent 벡터로 양방향 변환할 수 있다.
Context encdoer: VD의 컨텍스트 인코더로 CLIP 텍스트 인코더와 CLIP 이미지 인코더를 모두 사용한다. 텍스트 임베딩을 컨텍스트 입력으로 사용하는 SD와 달리 CLIP text-image contrastive loss를 최소화하는 정규화되고 project된 임베딩을 사용한다. 컨텍스트 (즉, 이미지와 텍스트) 사이에 더 가까운 임베딩 space가 더 빠르게 수렴되고 더 나은 성능을 발휘하는 데 도움이 된다.
Loss

VD의 학습은 놀라울 정도로 간단하다. 각 flow에 대해 가중된 $l_2$ loss를 계산하고 규칙적인 역전파를 수행한다 (Algorithm 1 참조). 모든 flow의 기울기가 누적되면 모델 가중치가 업데이트된다. 게다가 가중치를 업데이트할 때 multi-flow 모델 설정을 더 잘 적응시키기 위해 데이터 레이어와 컨텍스트 레이어의 파라미터에 대한 기울기 스케일을 수동으로 설정한다.
Experiments
- 데이터셋: Laion2B-en, COYO-700M
- 학습
- single-flow, dual-flow, 4-flow의 세 가지 설정으로 VD를 점진적으로 학습
- single-flow: image variation
- dual-flow: text-to-image, image variation
- 4-flow: 본 논문에서 주로 설명하는 4가지 task가 있는 기본 VD 모델
- 학습하는 동안 diffusion 설정을 DDPM과 SD에 가깝게 유지 (1000 step, $\beta$는 $8.5 \times 10^{-5}$에서 $1.2 \times 10^{-2}$로 선형적으로 증가)
- learning rate: single-flow와 dual-flow는 $10^{-4}$, 4-flow는 $5 \times 10^{-5}$
- Single-flow 모델은 SD v1.4 체크포인트를 초기 가중치로 사용, 다른 모델은 이전 모델의 최신 체크포인트를 계속 fine-tuning
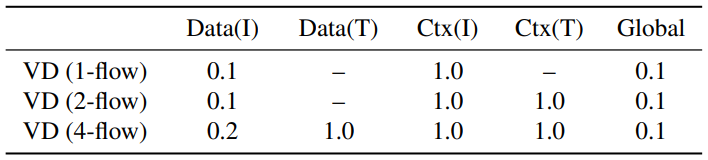
- 서로 다른 레이어에 대해 서로 다른 기울기 스케일을 설정 (아래 표 참조)
- batch size: single-flow의 경우 2048, dual-flow의 경우 1024, 4-flow의 경우 512
- 모든 모델은 256$\times$256에서 3,000만 개의 샘플로 학습 후 해상도 512$\times$512에서 640만 개의 샘플로 학습
- single-flow, dual-flow, 4-flow의 세 가지 설정으로 VD를 점진적으로 학습
1. Performance
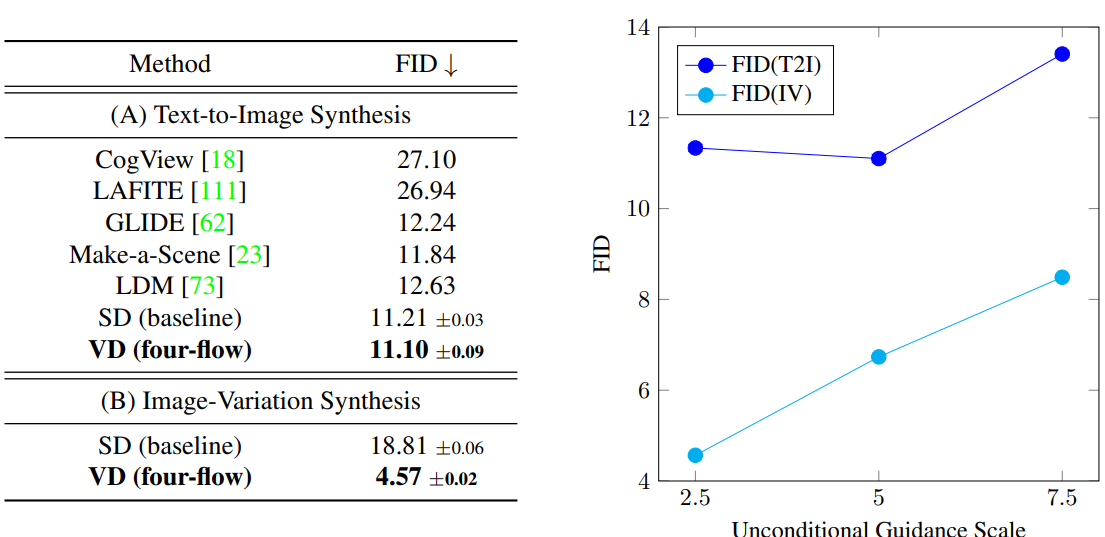
다음은 이전 방법들과 VD 모델의 결과를 비교한 것이다.

다음은 이전 방법들과 VD 모델을 정량적으로 비교한 것이다.
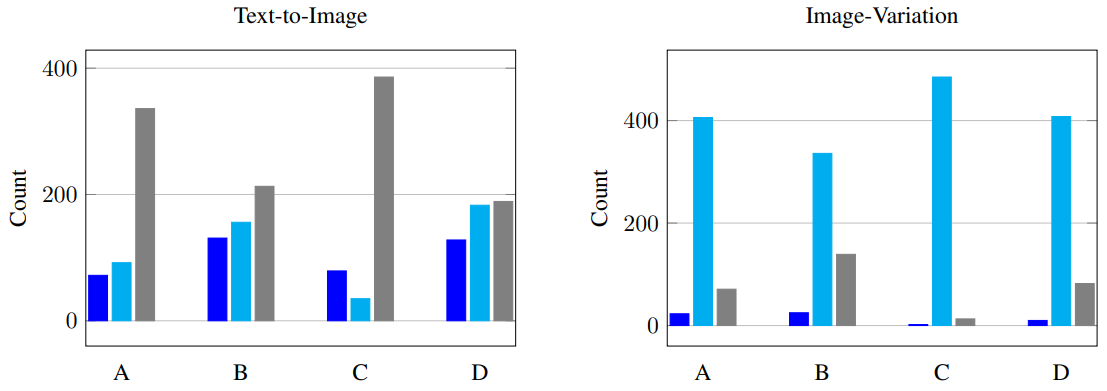
다음은 user study 결과이다. 심사자들은 SD, VD, 둘이 비슷함 중에 선택하였다.
2. Disentanglement of style and semantic
다음은 VD의 disentanglement 결과이다.

3. Dual- and multi-context blender
다음은 하나의 텍스트와 하나의 이미지를 사용하여 이중 컨텍스트 결과를 SD와 비교한 것이다.

다음은 VD의 multi-context blender로 생성한 이미지들이다.
