[논문리뷰] VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control
ICLR 2025. [Paper] [Page]
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, David B. Lindell, Sergey Tulyakov
University of Toronto | Vector Institute | Snap Inc. | SFU
17 Jul 2024

Introduction
Text-to-video foundation model은 방대한 이미지와 동영상 컬렉션에서 학습하였으며, 놀라울 정도로 일관되고 물리적으로 그럴듯한 동영상을 생성한다. 그러나 합성 프로세스 중에 명시적인 3D 제어를 위한 기본 제공 메커니즘이 부족하여 사용자가 프롬프트 엔지니어링과 시행착오를 통해 출력을 조작해야 한다. 예를 들어, SOTA 동영상 모델은 텍스트 프롬프트 guidance를 사용하여 간단하게 카메라를 줌인 또는 줌아웃하는 데도 어려움을 겪는다. 본 논문은 카메라의 위치와 방향을 제어하여 텍스트 프롬프트에 비해 세밀한 제어를 제공하는 것을 목표로 하였다.
여러 연구들에서는 SOTA 오픈소스 동영상 diffusion model의 카메라 제어 방법을 제안하였다. 이러한 방법들은 고품질의 카메라 주석이 있는 데이터셋에서 U-Net 기반 동영상 생성 모델의 temporal conditioning layer를 fine-tuning하여 카메라 제어를 추가하였다.
동영상 transformer는 동영상을 압축된 토큰 시퀀스로 표현하여 모든 토큰에 self-attention layer를 공동으로 적용한다. 결과적으로, 현재 카메라 컨디셔닝 방식에서 시점 정보를 통합하는 데 필수적인 독립적인 temporal layer가 없으므로 Sora, SnapVideo, Lumina-T2X와 같은 transformer 기반 아키텍처에 적용할 수 없다.
최근 데이터의 시공간적 의존성을 공동으로 모델링하기 위해 대형 동영상 transformer로 패러다임이 전환됨에 따라 카메라 제어 능력을 제공하는 방법을 개발하는 것이 중요하다. 본 논문은 대형 동영상 transformer에서 사용되는 공동 시공간적 계산에 맞게 조정된 카메라 컨디셔닝 방법을 설계하고 제어 가능한 동영상 합성을 위해 이를 길들이는 방법을 제안하였다.
압축된 latent space에서 효율적인 동영상 모델링을 위해 FIT block을 사용하는 SOTA 동영상 diffusion model인 SnapVideo를 기반으로 하였다. 저자들은 fine-tuning 시나리오에서 다양한 카메라 컨디셔닝 메커니즘을 조사하고 시각적 품질 보존 및 제어 능력 측면에서 trade-off를 탐구하였으며, 기존 접근 방식을 동영상 transformer에 적용하는 것만으로는 만족스러운 결과를 얻을 수 없음을 확인했다. 출력 동영상의 시각적 품질을 낮추는 동시에 제한된 양의 제어를 가능하게 하거나 카메라 모션을 전혀 제어하지 못한다. 따라서, 저자들은 시공간적 카메라 임베딩을 통해 카메라 모션 제어를 가능하게 하였으며, 이는 별도로 학습된 cross-attention layer를 통해 Plucker 좌표와 네트워크 입력을 결합하여 달성되었다.
Method
1. Large text-to-video transformers
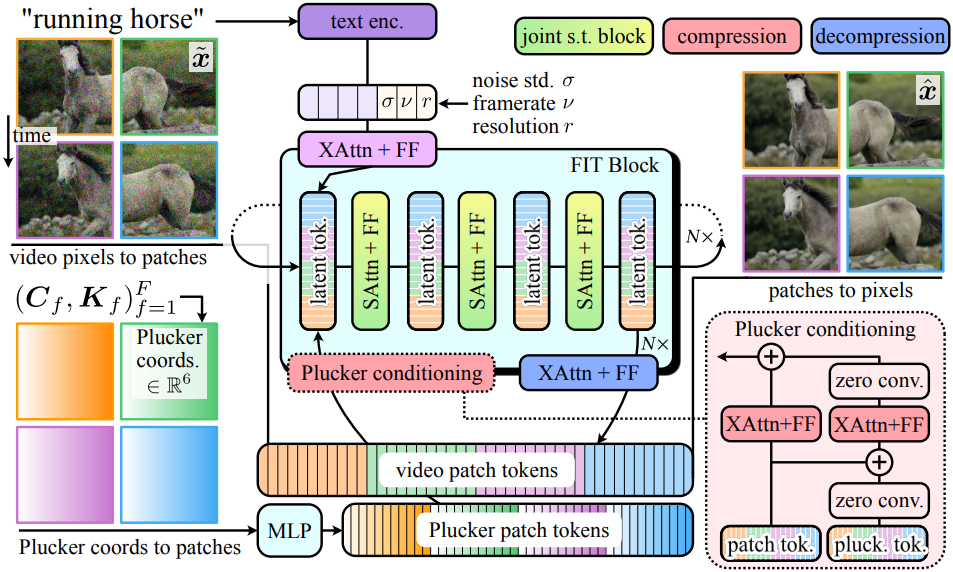
SnapVideo를 따라 동영상 생성기는 두 가지 모델로 구성된다.
- base generator: 16프레임, 36$\times$64 해상도 (파라미터: 4B)
- upsampler: 288$\times$512로 업샘플링
Upsampler는 diffusion model 자체로 base model에서 fine-tuning되고 저해상도 동영상으로 컨디셔닝된다. 각 모델은 효율적인 self-attention 연산을 위해 FIT transformer block을 사용한다. FIT 모델은 6개의 block으로 구성되며, 다음과 같이 작동한다.
- 입력 동영상의 각 프레임을 4$\times$4의 패치로 분할한다.
- 동영상 패치들은 feed-forward layer를 통해 독립적으로 projection되어 길이 $L = F \times (H/4) \times (W/4)$와 차원 $d$의 동영상 토큰 \([v_\ell]_{\ell=1}^L \in \mathbb{R}^{L \times d}\)의 시퀀스를 얻는다.
- 각 FIT block은 이 동영상 시퀀스의 정보를 훨씬 더 짧은 latent 토큰 시퀀스 \([z_m]_{m=1}^M\)로 만들기 위해 “read” cross-attention layer와 feed-forward layer를 거친다.
- 이 latent space에서 self-attention layer를 사용한 핵심 처리가 수행된 다음, 결과가 “write” cross-attention layer와 feed-forward layer를 통해 동영상 토큰에 다시 기록된다.
- 각 다음 FIT block의 latent 토큰은 이전 토큰에서 초기화되어 네트워크 전체에 계산 결과를 전파하는 데 도움이 된다.
이런 식으로 전체 계산은 공간 및 시간 축에서 공동으로 발생하여 뛰어난 확장성을 제공한다. 그러나 시각적 품질을 손상시키지 않고 카메라 모션을 제어하는 데 필수적인 현대 동영상 diffusion U-Net의 분해된 공간/시간 계산 특성을 포기한다.
2. Camera control for spatiotemporal transformers
시공간적 카메라 표현
동영상의 카메라 파라미터를 표현하는 표준 방법은 각 $f$번째 프레임에 대한 extrinsic $C_f$와 intrinsic $K_f$의 궤적 \((C_f, K_f)_{f=1}^F\)를 사용하는 것이다. 카메라 모션을 제어하기 위해 기존 방법에서는 U-Net 기반 동영상 생성기의 temporal attention layer를 이러한 카메라 파라미터에서 계산된 임베딩으로 컨디셔닝한다. 이러한 파이프라인은 분해된 공간/시간 계산을 사용하는 convolutional 동영상 생성기에 좋은 컨디셔닝 신호를 제공하지만, spatiotemporal transformer에 대해서는 제어에 실패하거나 시각적 품질을 저하시킨다. 이는 현대의 대규모 spatiotemporal transformer에 맞게 조정된 더 나은 카메라 컨디셔닝 체계의 필요성을 보여준다.
먼저, 카메라 파라미터를 첫 번째 프레임으로 정규화하여 첫 번째 프레임의 rotation을 단위 행렬 $R_1 = I$로, translation을 $t_1 = 0$으로 강제한다. 그런 다음 각 $f$번째 프레임의 extrinsic을 $C_f = [R_f; t_f]$로 다시 계산하여 동영상 전체에서 일관된 좌표계를 설정한다. 그런 다음, 프레임 레벨의 시간적 카메라 파라미터를 픽셀별 시공간적 카메라 파라미터로 전환하여 컨디셔닝 정보를 풍부하게 하기 위해, 각 픽셀에 대한 Plücker 좌표를 계산하여 세밀한 위치 표현을 제공한다.
$f$번째 프레임의 extrinsic $R_f$, $t_f$와 intrinsic $K_f$가 주어지면, 각 $(h, w)$번째 픽셀을 카메라 위치에서 픽셀 중심까지 Plücker 임베딩 \(\ddot{p}_{f,h,w} \in \mathbb{R}^6\)으로 parametrize한다.
\[\begin{aligned} \ddot{p}_{f,h,w} &= (t_f \times \hat{d}_{f,h,w}, \hat{d}_{f,h,w}) \\ \hat{d}_{f,h,w} &= \frac{d_{f,h,w}}{\| d_{f,h,w} \|}, \quad d_{f,h,w} = R_f K_f [w, h, 1]^\top + t_f \end{aligned}\]Plücker 좌표를 사용하는 동기는 Plücker 공간에서의 기하학적 조작을 좌표에 대한 간단한 산술 연산을 통해 수행할 수 있기 때문에 네트워크가 표현에 저장된 위치 정보를 사용하기가 더 쉬워지기 때문이다.
각 픽셀에 대한 Plücker 좌표를 계산하면 동영상에 대한 시공간적 카메라 표현 $\ddot{P} \in \mathbb{R}^{6 \times F \times H \times W}$이 생성된다. 이를 모델에 입력하기 위해 먼저 ViT와 같은 4$\times$4 patchification 절차를 수행한다. 그 뒤에 학습 가능한 feed-forward layer \(\textrm{FF}_{\ddot{p}}\)를 통과시켜 동영상 토큰 시퀀스 \([v_\ell]_{\ell=1}^L\)과 길이 $L = F \times (H/4) \times (W/4)$와 차원 $d$가 같은 Plücker 카메라 토큰 시퀀스 \([\ddot{c}_\ell]_{\ell=1}^L \in \mathbb{R}^{L \times d}\)를 얻는다. 이 시공간적 표현은 동영상의 각 픽셀에 대한 세밀한 위치 정보를 전달하므로 생성기가 원하는 카메라 모션을 정확하게 따라가기가 더 쉬워진다.
카메라 컨디셔닝
풍부한 시공간적 카메라 정보를 Plücker 임베딩 형태로 동영상 생성기에 입력하기 위해, 저자들은 transformer 모델에 맞게 조정된 효율적인 ControlNet과 같은 메커니즘을 설계하였다. 이 메커니즘은 두 가지 주요 목표를 가지고 있다.
- 모델은 추정된 카메라 위치가 있는 작은 데이터셋에서 빠른 fine-tuning에 적합해야 한다.
- Fine-tuning 단계에서 시각적 품질이 손상되어서는 안 된다.
Spatiotemporal transformer의 경우 이러한 목표를 충족하는 것이 공간/시간 계산이 분해된 U-Net 기반 모델에 비해 더 어려우며, 그 핵심 이유는 동영상 transformer의 얽힌 공간/시간 계산이다. 시간적 역학(ex. 카메라 모션)을 변경하려는 시도는 토큰 간의 공간 통신에 영향을 미쳐 fine-tuning 단계에서 불필요한 신호 전파와 overfitting으로 이어진다.
이를 완화하기 위해, 카메라 정보를 해당 레이어의 원래 네트워크 파라미터로부터 0으로 초기화된 “read” cross-attention layer를 통해 점진적으로 입력한다. 구체적으로, 동영상 생성기의 각 $b$번째 FIT block에서 표준 “read” cross-attention 연산인
\[\begin{equation} [z_m^{(b)}]_{m=1}^M = \textrm{FF}^{(b)} (\textrm{XAttn} ([z_m^{(b)}]_{m=1}^M, [v_\ell^{(b)}]_{\ell=1}^L)) \end{equation}\]를 다음 식으로 대체한다.
\[\begin{aligned} \vphantom{1}[z_m^{(b)}]_{m=1}^M &= \textrm{FF}^{(b)} (\textrm{XAttn} ([z_m^{(b)}]_{m=1}^M, [v_\ell^{(b)}]_{\ell=1}^L)) \\ &+ \textrm{Conv}_\textrm{res}^{(b)} (\textrm{FF}_\textrm{cam}^{(b)} (\textrm{XAttn} ([z_m^{(b)}]_{m=1}^M, \textrm{Conv}_\textrm{plück}^{(b)} ([\ddot{c}_\ell]_{\ell=1}^L)))) \end{aligned}\]($\textrm{FF}(\cdot)$는 feed-forward layer, $\textrm{XAttn}(\cdot, \cdot)$은 cross-attention layer, \(\textrm{Conv}_\textrm{res}^{(b)}\)와 \(\textrm{Conv}_\textrm{plück}^{(b)}\)은 1D convolution)
모델 initialization을 보존하기 위해 convolution들의 가중치를 0으로 초기화한다. 또한, 원래 네트워크의 파라미터로 \(\textrm{FF}_\textrm{cam}^{(b)}\)과 \(\textrm{XAttn}_\textrm{cam}^{(b)}\)의 가중치를 초기화한다. 이는 초기화 시 시각적 품질을 보존하는 데 도움이 되고 작은 데이터셋에서 빠른 fine-tuning을 용이하게 한다.
Experiments
- 데이터셋: RealEstate10k
- 학습 디테일
- 새로 추가된 파라미터, 즉 \(\textrm{FF}_{\ddot{p}}\), \((\alpha^{(b)}, \textrm{FF}^{(b)}, \textrm{XAttn}^{(b)})_{b=1}^B\)만 학습하고 나머지는 고정
- 36$\times$64 base model만 학습
- optimizer: LAMB / batch size: 256 / iteration: 5만
- learning rate: 처음 1만 iteration은 0부터 0.005로 warm-up, 나머지 iteration동안 0.0015로 선형적으로 감소
- 텍스트 컨디셔닝: T5-11B (길이: 128, 임베딩 차원: 1024)
- GPU: 700M 모델은 A100 40GB 8개로 1일, 4B 모델은 A100 40GB 64개로 1.5일 소요
1. Assessment
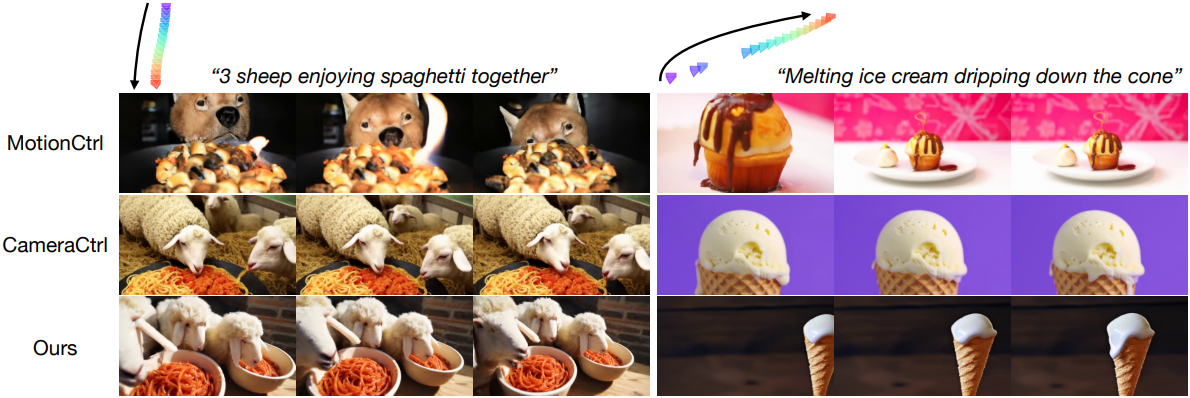
다음은 다른 방법들과 동영상 생성 결과를 비교한 것이다.
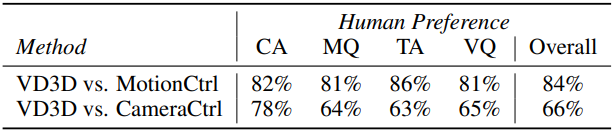
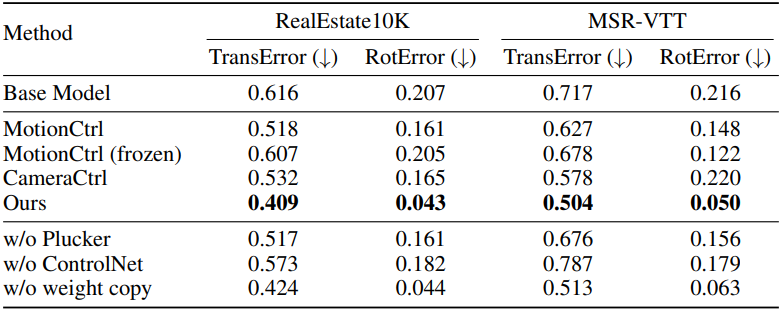
다음은 카메라 포즈를 평가한 결과이다. (ParticleSfM으로 추정한 카메라 포즈를 기반으로 평가)
2. Applications
다음은 실제 이미지에 대한 멀티뷰 생성 결과이다.

Limitations
- 여러 카메라 시점에서 렌더링된 동적 장면은 일관되지 않은 모션을 가질 수 있다.
- 저해상도 base model에만 카메라 컨디셔닝을 적용하고 upsampler 모델은 카메라 컨디셔닝 없이 고정하였다.
- SnapVideo 모델의 디자인 및 학습 체계를 기반으로 비교적 짧은 동영상(16프레임)를 생성하는 것으로 제한되어 있다.