[논문리뷰] VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
CVPR 2024. [Paper] [Page]
Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, Youliang Yan, Wenming Yang
Tsinghua University | Huawei Noah’s Ark Lab | Chinese Academy of Sciences
27 Feb 2024

Introduction
대규모 장면 재구성은 자율 주행, 항공 측량, VR 등 사실적인 시각적 품질과 실시간 렌더링이 필요한 다양한 애플리케이션에 필수적이다. NeRF를 대규모 장면으로 확장하면 디테일이 부족하고 렌더링 속도가 느리다. 최근 3D Gaussian Splatting (3DGS)는 시각적 품질과 렌더링 속도 측면에서 인상적인 성능을 제공하여 1080p 해상도에서 사진처럼 사실적인 실시간 렌더링을 가능하게 하는 유망한 접근 방식으로 떠오르고 있다. 그러나 3DGS는 소규모 및 물체 중심 장면에 중점을 둔다. 대규모 환경에 적용할 경우 몇 가지 확장성 문제가 있다.
- 큰 장면의 풍부한 디테일에는 수많은 3D Gaussian이 필요하며, 3D Gaussian의 수는 주어진 VRAM에 의해 제한된다. 대규모 장면에 3DGS를 그냥 적용하면 재구성 품질이 떨어지거나 메모리 부족 오류가 발생한다. 32GB GPU를 사용하면 약 1,100만 개의 3D Gaussian을 최적화할 수 있으며, Mip-NeRF 360 데이터셋의 작은 정원 장면에 이미 약 580만 개의 3D Gaussian이 필요하다.
- 전체 대규모 장면을 전체적으로 최적화하려면 충분한 iteration이 필요하다. 이는 시간이 많이 걸리고 적절한 정규화가 없으면 불안정할 수 있다.
- 아래 그림과 같이 대규모 장면에서 조명은 일반적으로 고르지 않으며 캡처된 이미지에 눈에 띄는 외형 변화가 있다. 3DGS는 다양한 뷰 간의 이러한 차이를 보상하기 위해 불투명도가 낮은 대규모 3D Gaussian을 생성하는 경향이 있다. 예를 들어, 노출이 높은 이미지에서는 카메라 가까이 밝은 얼룩이 나타나는 경향이 있고, 노출이 낮은 이미지에서는 어두운 얼룩이 나타나는 경향이 있다. 이 얼룩은 새로운 시점에서 관찰할 때 공중에 떠다니는 불쾌한 floater로 변한다.

본 논문은 이러한 문제를 해결하기 위해 3D Gaussian Splatting을 기반으로 한 대규모 장면 재구성을 위한 Vast 3D Gaussian (VastGaussian)을 제안하였다. 분할 정복(divide-and-conquer) 방식으로 대규모 장면을 재구성한다. 대규모 장면을 여러 셀로 분할하고 각 셀을 독립적으로 최적화한 다음 최종적으로 전체 장면으로 병합한다. 공간 규모가 더 작고 데이터 크기가 더 작기 때문에 이러한 셀을 최적화하는 것이 더 쉽다. 자연스럽고 단순한 분할 전략은 학습 데이터를 위치에 따라 지리적으로 분포시키는 것이다. 이로 인해 몇몇 공통된 카메라로 인해 인접한 두 셀 사이에 경계 아티팩트가 발생할 수 있으며 충분한 supervision 없이는 공중에 floater가 생성될 수 있다.
따라서 본 논문은 더 많은 학습 카메라와 포인트 클라우드를 점진적으로 통합하기 위해 visibility 기반 데이터 선택을 제안하였다. 이를 통해 원활한 병합을 보장하고 공중에 떠 있는 floater를 제거할 수 있다. 본 논문의 접근 방식은 3DGS보다 더 나은 유연성과 확장성을 제공한다. 이러한 각 셀에는 더 적은 수의 3D Gaussian이 포함되어 있어 특히 여러 GPU와 병렬로 최적화할 때 메모리 요구 사항과 최적화 시간이 줄어든다. 병합된 장면에 포함된 3D Gaussian의 총 개수는 전체적으로 학습된 장면의 수를 크게 초과하여 재구성 품질을 향상시킬 수 있다. 게다가 전체 장면을 재학습하지 않고도 새로운 셀을 통합하여 장면을 확장하거나 특정 영역을 fine-tuning할 수 있다.
외형 변형으로 인해 발생하는 floater를 줄이기 위해 NeRF 기반 방법에 외형 임베딩을 사용하는 Generative Latent Optimization (GLO)가 제안되었다. 이 접근 방식은 ray-marching을 통해 포인트를 샘플링하고 포인트 feature들은 외형 임베딩과 함께 MLP에 입력되어 최종 색상을 얻는다. 렌더링 프로세스는 최적화와 동일하며 여전히 입력으로 외형 임베딩이 필요하다. 렌더링은 MLP 없이 프레임 단위 rasterization으로 수행되므로 3DGS에는 적합하지 않다. 따라서 본 논문은 최적화에만 적용되는 새로운 분리형 외형 모델링을 제안하였다. 렌더링된 이미지에 픽셀 단위로 외형 임베딩을 첨부하고 이를 CNN에 입력하여 렌더링된 이미지에 외형 조정을 적용하기 위한 변환 맵을 얻는다. 일정한 정보를 학습하기 위해 렌더링된 이미지와 실제 정보 간의 구조적 차이에 페널티를 적용하는 한편, 학습 이미지의 외형 변화에 맞게 조정된 이미지에서 photometric loss를 계산한다. 일관된 렌더링만이 필요하므로 이 외형 모델링 모듈은 최적화 후에 제거될 수 있고 실시간 렌더링 속도가 느려지지 않는다.
Preliminaries
본 논문에서는 3DGS 기반의 대규모 장면 재구성 및 렌더링을 위해 VastGaussian을 제안하였다. 3DGS는 3D Gaussian의 집합 $\textbf{G}$를 통해 형상과 외형을 나타낸다. 각 3D Gaussian은 위치, 공분산, 불투명도, 뷰에 따른 색상에 대한 spherical harmonics 계수로 특징 지어진다. 렌더링 프로세스 중에 각 3D Gaussian은 2D Gaussian으로 이미지 공간에 투영된다. 투영된 2D Gaussian은 다양한 타일에 할당되고, 포인트 기반 볼륨 렌더링 방식으로 렌더링된 이미지로 정렬 및 알파 블렌딩된다.
장면을 최적화하는 데 사용되는 데이터셋에는 sparse한 포인트 클라우드 $\textbf{P}$와 학습 뷰 \(\textbf{V} = \{(\mathcal{C}_i, \mathcal{I}_i)\}\)가 포함되어 있다. 여기서 \(\mathcal{C}_i\)는 $i$번째 카메라이고 \(\mathcal{I}_i\)는 해당 이미지이다. $\textbf{P}$와 \(\{\mathcal{C}_i\}\)는 \(\{\mathcal{I}_i\}\)로부터 Structure-from-Motion(SfM)에 의해 추정된다. $\textbf{P}$는 3D Gaussian을 초기화하는 데 사용되고 $\textbf{V}$는 3D Gaussian의 미분 가능한 렌더링 및 기울기 기반 최적화에 사용된다. 카메라 \(\mathcal{C}_i\)의 경우 렌더링된 이미지 \(\mathcal{I}_i^r = \mathcal{R}(\textbf{G}, \mathcal{C}_i)\)는 미분 가능한 rasterizer $\mathcal{R}$에 의해 획득된다. 3D Gaussian의 속성은 \(\mathcal{I}_i^r\)과 \(\mathcal{I}_i\) 사이의 loss function으로 최적화된다.
\[\begin{equation} \mathcal{L} = (1 - \lambda) \mathcal{L}_1 (\mathcal{I}_i^r, \mathcal{I}_i) + \lambda \mathcal{L}_\textrm{D-SSIM} (\mathcal{I}_i^r, \mathcal{I}_i) \end{equation}\]여기서 $\lambda$는 hyperparameter이고 \(\mathcal{L}_\textrm{D-SSIM}\)은 D-SSIM loss이다. 이 프로세스는 포인트의 누적 기울기가 특정 threshold에 도달할 때 발동되는 적응형 densification과 인터리브된다.
Method
1. Progressive Data Partitioning
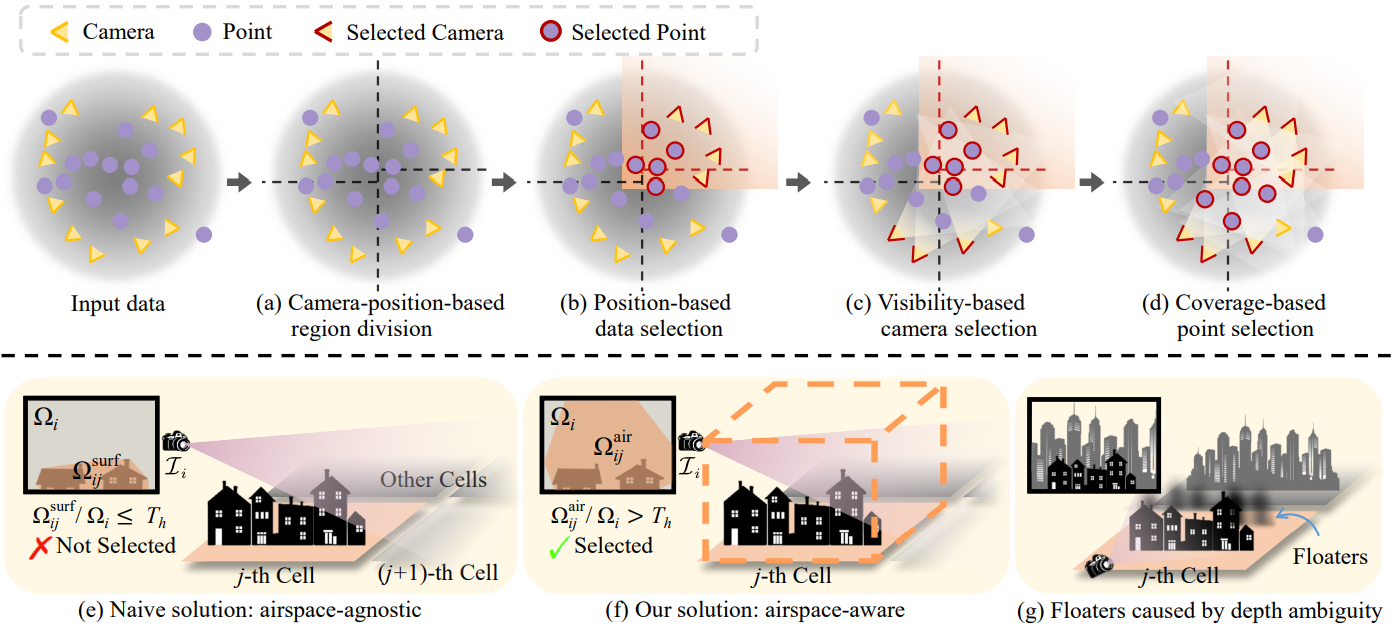
대규모 장면을 여러 셀로 분할하고 포인트 클라우드 $\textbf{P}$의 일부를 할당하고 $\textbf{V}$를 이러한 셀에 할당하여 최적화한다. 이러한 각 셀에는 더 적은 수의 3D Gaussian이 포함되어 있어 메모리 용량이 낮은 최적화에 더 적합하고 병렬로 최적화할 때 학습 시간이 덜 필요하다. 점진적인 데이터 분할 전략의 파이프라인은 위 그림에 나와 있다.
Camera-position-based region division
(a)에서 볼 수 있듯이 지면에 투영된 카메라 위치를 기반으로 장면을 분할하고 각 셀에 비슷한 수의 학습 뷰를 포함시켜 동일한 iteration 수에서 서로 다른 셀 간의 균형 잡힌 최적화를 보장한다. 일반성을 잃지 않고 $m \times n$ 셀의 그리드가 문제의 장면에 잘 맞는다고 가정하면 먼저 지면을 하나의 축을 따라 $m$개의 섹션으로 분할한다. 각각은 대략 $\vert \textbf{V} \vert / m$개의 뷰를 포함한다. 그런 다음 이러한 각 섹션은 다른 축을 따라 $n$개의 세그먼트로 더 세분화되며, 각각은 대략 $\vert \textbf{V} \vert / (m \times n)$개의 뷰를 포함한다. 여기서는 그리드 기반 분할을 예로 들었지만 데이터 분할 전략은 sectorization이나 쿼드트리와 같은 다른 분할 방법에도 적용 가능하다.
Position-based data selection
(b)에서 볼 수 있듯이 경계를 확장한 후 학습 뷰 $\textbf{V}$와 포인트 클라우드 $\textbf{P}$의 일부를 각 셀에 할당한다. 구체적으로, $j$번째 영역을 $\ell_j^h \times \ell_j^w$의 직사각형으로 제한한다. 경계는 20%만큼 확장되어 크기가 더 큰 직사각형 $1.2 \ell_j^h \times 1.2 \ell_j^w$이 된다. 확장된 경계를 기준으로 학습 뷰 $\textbf{V}$를 \(\{\textbf{V}_j\}_{j=1}^{m \times n}\)로 분할하고 동일한 방식으로 포인트 클라우드 $\textbf{P}$를 \(\{\textbf{P}_j\}\)로 분할한다.
Visibility-based camera selection
저자들은 이전 단계에서 선택한 카메라는 충실도가 높은 재구성에 충분하지 않아 세부 묘사가 부족하거나 floater가 발생할 수 있음을 발견했다. 이 문제를 해결하기 위해 (c)와 같이 visibility 기준을 기반으로 관련성 있는 카메라를 더 추가한다. 아직 선택되지 않은 카메라 \(\mathcal{C}_i\)가 주어지면, \(\Omega_{ij}\)를 이미지 \(\mathcal{I}_i\)의 $j$번째 셀의 투영된 영역이라 하고 \(\Omega_i\)를 \(\mathcal{I}_i\)의 영역으로 두자. 이 때 visibility는 \(\Omega_{ij} / \Omega_i\)로 정의된다. 사전 정의된 threshold $T_h$보다 큰 visibility 값을 가진 카메라가 선택된다.
\(\Omega_{ij}\)를 계산하는 방법이 다르면 카메라 선택도 달라진다. (e)에서 볼 수 있듯이 naive한 솔루션은 물체 표면에 분포된 3D 점을 기반으로 한다. 점들은 \(\mathcal{I}_i\)에 투영되어 면적이 \(\Omega_{ij}^\textrm{surf}\)의 convex hull을 형성한다. 이 계산은 표면만 고려하기 때문에 영공(airspace)에 구애받지 않는다. 따라서 이 계산에서 $j$번째 셀의 visibility가 낮아 일부 관련 카메라가 선택되지 않았다. 이로 인해 영공에 대한 supervision이 부족해지고 공중에 떠 있는 floater를 억제할 수 없다.
(f)와 같이 airspace-aware visibility 계산을 도입한다. 구체적으로, 축에 정렬된 bounding box는 $j$번째 셀의 포인트 클라우드에 의해 형성되며, 높이는 가장 높은 점과 지면 사이의 거리로 선택된다. Bounding box를 \(\mathcal{I}_i\)에 투영하고 convex hull 면적 \(\Omega_{ij}^\textrm{air}\)를 얻는다. 이 airspace-aware인 솔루션은 모든 visibility 공간을 고려하여 적절한 visibility threshold가 주어지면 이 셀의 최적화에 크게 기여하는 뷰가 선택되고 영공에 대한 충분한 supervision을 제공한다.
Coverage-based point selection
$j$번째 셀의 카메라 세트 \(\textbf{V}_j\)에 관련성 높은 카메라를 추가한 후 (d)와 같이 \(\textbf{V}_j\)의 모든 뷰에 포함되는 점을 \(\textbf{P}_j\)에 추가한다. 새로 선택된 포인트는 이 셀의 최적화를 위해 더 나은 초기화를 제공할 수 있다. (g)에서 볼 수 있듯이 $j$번째 셀 외부의 일부 물체는 \(\textbf{V}_j\)의 일부 뷰에 의해 캡처될 수 있으며 적절한 초기화가 없으면 깊이 모호성으로 인해 잘못된 위치에 새로운 3D Gaussian이 생성된다. 그러나 초기화를 위해 물체의 포인트를 추가하면 $j$번째 셀에서 floater를 생성하는 대신 올바른 위치의 새로운 3D Gaussian을 이러한 학습 뷰에 맞게 쉽게 생성할 수 있다. 셀 외부에서 생성된 3D Gaussian은 셀 최적화 후에 제거된다.
2. Decoupled Appearance Modeling
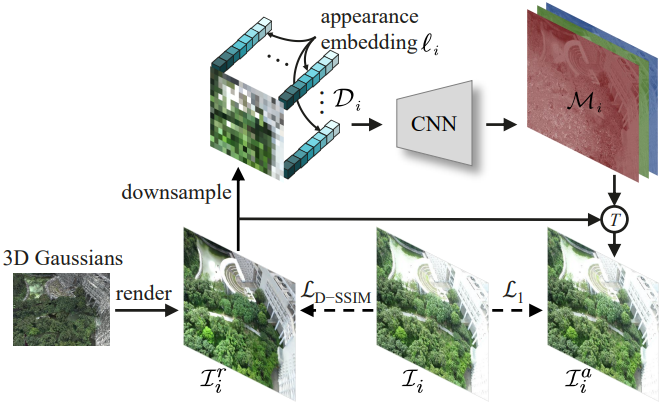
고르지 못한 조명에서 촬영된 이미지에는 명백한 외형 변화가 있으며, 3DGS는 다양한 뷰에서 이러한 변화를 보상하기 위해 floater를 생성하는 경향이 있다.
이 문제를 해결하기 위해 일부 NeRF 기반 방법은 픽셀 단위 ray-marching의 포인트 기반 feature에 외형 임베딩을 concatenate하고 이를 MLP에 공급하여 최종 색상을 얻는다. 이는 MLP 없이 프레임 단위 rasterization으로 렌더링이 수행되는 3DGS에는 적합하지 않다. 대신 본 논문은 위 그림과 같이 학습 이미지의 외형 변형에 맞게 렌더링된 이미지를 조정하기 위한 변환 맵을 생성하는 최적화 프로세스에 분리된 외형 모델링을 도입한다.
구체적으로, 먼저 렌더링된 이미지 \(\mathcal{I}_i^r\)을 다운샘플링하여 변환 맵이 고주파수 디테일을 학습하는 것을 방지하고 계산 부담과 메모리 소비도 줄인다. 그런 다음 3채널 다운샘플링된 이미지의 모든 픽셀에 길이 $m$의 임베딩 $\ell_i$를 concatenate하고 $3 + m$개의 채널을 가진 2D 맵 \(\mathcal{D}_i\)를 얻는다. \(\mathcal{D}_i\)는 CNN에 입력되며, CNN은 \(\mathcal{D}_i\)를 점진적으로 업샘플링하여 \(\mathcal{I}_i^r\)과 동일한 해상도의 \(\mathcal{M}_i\)를 생성한다. 마지막으로, \(\mathcal{M}_i\)를 사용하여 \(\mathcal{I}_i^r\)에 대한 픽셀별 변환 $T$를 수행하여 외형이 변형된 이미지 \(\mathcal{I}_i^a\)를 얻는다.
\[\begin{equation} \mathcal{I}_i^a = T (\mathcal{I}_i^r; \mathcal{M}_i) \end{equation}\]저자들의 실험에서는 간단한 픽셀별 곱셈이 잘 작동했다고 한다. 외형 임베딩과 CNN은 수정된 loss function을 사용하여 3D Gaussian과 함께 최적화된다.
\[\begin{equation} \mathcal{L} = (1 - \lambda) \mathcal{L}_1 (\mathcal{I}_i^a, \mathcal{I}_i) + \lambda \mathcal{L}_\textrm{D-SSIM} (\mathcal{I}_i^r, \mathcal{I}_i) \end{equation}\]\(\mathcal{L}_\textrm{D-SSIM}\)은 주로 구조적 차이점에 페널티를 주기 때문에 \(\mathcal{I}_i^r\)와 \(\mathcal{I}_i\) 사이에 이를 적용하면 \(\mathcal{I}_i^r\)의 구조 정보가 \(\mathcal{I}_i\)에 가까워지고 외형 정보는 $\ell_i$와 CNN이 학습하게 된다. \(\mathcal{L}_1\)은 \(\mathcal{I}_i^a\)와 \(\mathcal{I}_i\) 사이에 적용되며, 이는 다른 이미지와 외형 차이가 있을 수 있는 실제 이미지 \(\mathcal{I}_i\)를 피팅하는 데 사용된다. 학습 후, \(\mathcal{I}_i^r\)는 다른 이미지와 일관된 외형을 가질 것으로 예상되며, 이를 통해 3D Gaussian은 모든 입력 뷰의 평균 외형과 올바른 형상을 학습할 수 있다. 실시간 렌더링 속도를 늦추지 않고 최적화 후 이 외형 모델링을 삭제할 수 있다.
3. Seamless Merging
모든 셀을 독립적으로 최적화한 후 이를 병합하여 완전한 장면을 만들어야 한다. 각 최적화된 셀에 대해 경계 확장 전에 원래 영역 외부에 있는 3D Gaussian을 삭제한다. 그렇지 않으면 다른 셀에서 floater가 될 수 있다. 그런 다음 겹치지 않는 셀의 3D Gaussian을 병합한다. 병합된 장면은 데이터 분할에서 인접한 셀 간에 일부 학습 뷰가 공통적으로 사용되기 때문에 명백한 경계 아티팩트 없이 모양과 형상이 매끄러워진다. 따라서 Block-NeRF와 같은 추가 외형 조정을 수행할 필요가 없다. 병합된 장면에 포함된 3D Gaussian의 총 개수는 한번에 학습된 장면의 Gaussian 수를 크게 초과할 수 있으므로 재구성 품질이 향상된다.
Experiments
- 데이터셋: Mill-19, UrbanScene3D
- 구현 디테일
- 셀 개수: 8
- visibility threshold: 0.25
- 외형 임베딩 길이: 64
- 렌더링된 이미지는 32배로 다운샘플링됨
- 각 셀은 60,000 iteration으로 최적화됨
- densification은 1,000 iteration에서 시작되어 200 iteration 간격으로 30,000 iteration에서 종료
- 외형 임베딩과 CNN의 learning rate는 0.001
- Manhattan world alignment를 수행하여 월드 좌표계의 $y$축이 지면과 수직이 되도록 함
1. Result Analysis
다음은 이전 방법들과 비교한 결과이다.


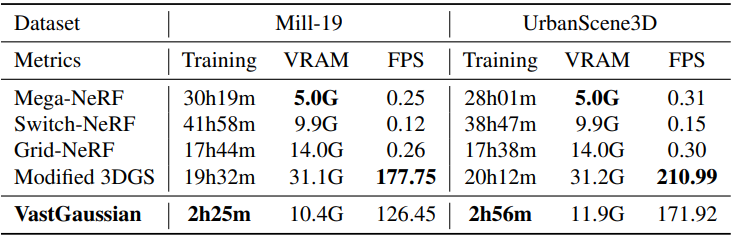
다음은 학습 시간과 학습 시 사용하는 VRAM, 렌더링 속도를 비교한 표이다.
2. Ablation Study
다음은 visibility 기반 카메라 선택(VisCam)과 coverage 기반 카메라 선택(CovPoint)에 대한 ablation 결과이다.

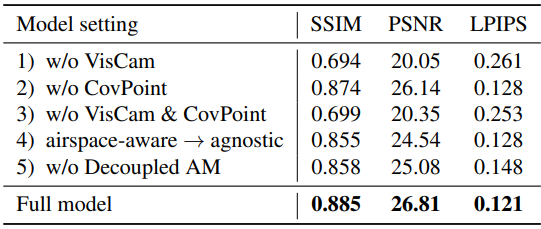
다음은 visibility 기반 카메라 선택(VisCam)에 대한 ablation 결과이다.

다음은 airspace-aware visibility 계산에 대한 ablation 결과이다.

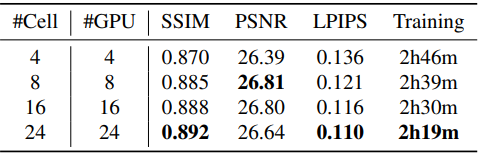
다음은 셀 개수에 대한 성능을 비교한 표이다.
Limitation
- 모든 형태의 공간 분할에 적용될 수 있지만 장면 레이아웃, 셀 개수, 학습 카메라 분포를 고려해야 하는 최적의 분할 솔루션을 제공하지는 않는다.
- 장면이 클 경우 3D Gaussian이 많아 큰 저장 공간이 필요하고 렌더링 속도가 크게 느려질 수 있다.