[논문리뷰] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E)
arXiv 2023. [Paper] [Page]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, Furu Wei
Microsoft
5 Jan 2023
Introduction
현재 계단식 TTS (text to speech) 시스템은 일반적으로 중간 표현으로 mel spectrogram을 사용하는 음향 모델과 vocoder가 있는 파이프라인을 활용한다. 고급 TTS 시스템은 한 명 또는 여러 멍의 고품질 음성을 합성할 수 있지만 여전히 녹음 스튜디오에서 녹음한 고품질의 깨끗한 데이터가 필요하다. 인터넷에서 크롤링되는 대규모 데이터는 요구 사항을 충족하지 못하고 항상 성능 저하로 이어진다. 학습 데이터가 상대적으로 작기 때문에 현재 TTS 시스템은 여전히 일반화가 좋지 않다. Zero-shot 시나리오에서 처음 보는 speaker에 대한 speaker 유사성과 음성의 자연스러움은 극적으로 감소한다. Zero-shot TTS 문제를 해결하기 위해 기존 연구들은 speaker adaptation과 speaker encoding 방법을 활용하므로 추가 fine-tuning, 복잡한 사전 설계된 feature, 무거운 구조 엔지니어링이 필요하다.
이 문제에 대해 복잡하고 구체적인 네트워크를 설계하는 대신 텍스트 합성 분야에서 성공한 것과 같이 다양한 데이터로 모델을 학습시키는 것이 궁극적인 해결책이다. 최근 몇 년 동안 16GB에서 160GB, 570GB, 마지막으로 약 1TB로 텍스트 언어 모델의 데이터 증가에 대한 눈에 띄는 성능 향상이 있었다. 본 논문은 이 성공을 음성 합성 분야로 옮기고, 크고 다양한 multi-speaker 음성 데이터를 활용하는 최초의 언어 모델 기반 TTS 프레임워크인 VALL-E를 소개한다.
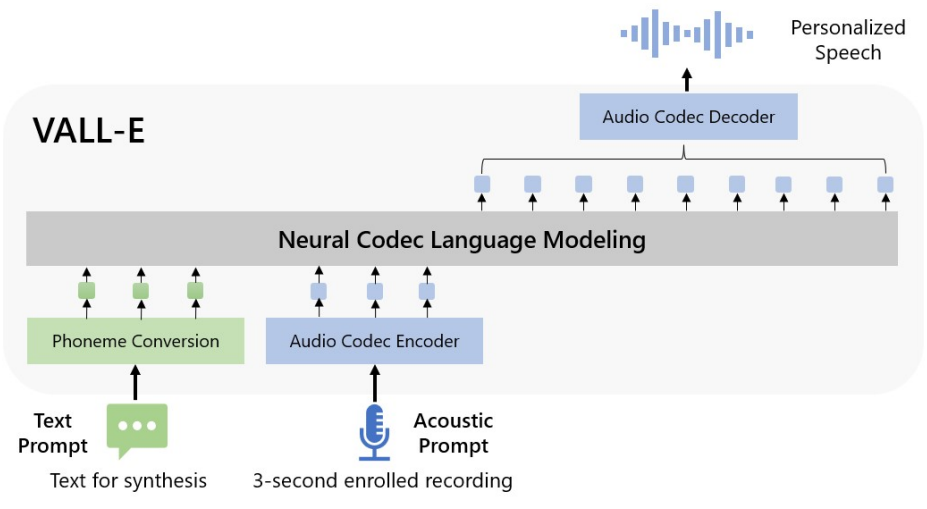
위 그림에서 볼 수 있듯이 개인화된 음성(ex. zero-shot TTS)을 합성하기 위해 VALL-E는 3초 등록 녹음의 음향 토큰과 음소 프롬프트으로 컨디셔닝된 음향 토큰을 생성하여 speaker와 콘텐츠 정보를 각각 제한한다. 마지막으로 생성된 음향 토큰은 코덱 디코더와 최종 waveform을 합성하는 데 사용된다. 오디오 코덱 모델에서 파생된 개별 음향 토큰을 통해 TTS를 조건부 코덱 언어 모델링으로 취급할 수 있으며 고급 프롬프트 기반 대형 모델 기술을 TTS에 활용할 수 있다. 음향 토큰을 사용하면 inference 중에 다양한 샘플링 전략을 사용하여 TTS에서 다양한 합성 결과를 생성할 수 있다.
본 논문은 LibriLight로 VALL-E를 학습시킨다. LibriLight는 오디오 전용이므로 음성 인식 모델을 사용하여 transcription를 생성한다. LibriTTS와 같은 이전 TTS 학습 데이터셋과 비교할 때 이 데이터에는 더 시끄러운 음성과 부정확한 필사본이 포함되어 있지만 다양한 speaker와 운율을 제공한다. VALL-E는 잡음에 강하고 대용량 데이터를 활용하여 잘 일반화한다. 기존 TTS 시스템은 항상 수십 시간의 단일 speaker 데이터 또는 수백 시간의 multi-speaker 데이터로 학습되며 이는 VALL-E보다 수백 배 이상 작다. 아래 표는 오디오 코덱 코드를 중간 표현으로 사용하고 크고 다양한 데이터를 활용하여 강력한 in-context 학습 능력을 제공하는 TTS용 언어 모델 접근 방식인 VALL-E의 혁신을 요약한 것이다.

Background: Speech Quantization
오디오는 일반적으로 16비트 정수 값의 시퀀스로 저장되므로 오디오를 합성하기 위해 timestep당 $2^{16} = 65536$개의 확률들을 출력하는 생성 모델이 필요하다. 또한 오디오 샘플 속도가 10,000을 초과하면 시퀀스 길이가 엄청나게 길어져 오디오 합성이 더 어려워진다. 이를 위해서는 정수 값과 시퀀스 길이를 압축하기 위한 음성 양자화가 필요하다.
$\mu$-law 변환은 각 timestep을 256개 값으로 양자화하고 고품질 오디오를 재구성할 수 있다. WaveNet과 같은 음성 생성 모델에서 널리 사용되지만 시퀀스 길이가 줄어들지 않기 때문에 여전히 inference 속도가 느리다. 최근 벡터 양자화는 vq-wav2vec와 HuBERT와 같은 feature 추출을 위한 self-supervised 음성 모델에 널리 적용되었다. Self-supervisd 모델의 코드도 콘텐츠를 재구성할 수 있으며 inference 속도가 WaveNet보다 빠르다. 그러나 spekaer identity가 폐기되었으며 재구성 품질이 낮다. AudioLM은 self-supervisd 모델의 k-mean 토큰과 코덱 모델의 음향 토큰 모두에서 speech-to-speech 언어 모델을 학습시켜 고품질 speech-to-speech 생성으로 이어진다.
본 논문에서는 AudioLM을 따라 코덱 모델을 활용하여 개별 토큰으로 음성을 표현한다. 네트워크 전송을 위해 오디오를 압축하기 위해 코덱 모델은 waveform을 개별 음향 코드로 인코딩하고 학습 중에 보지 못한 speaker에 대해서도 고품질 waveform을 재구성할 수 있다. 기존의 오디오 코덱 접근 방식과 비교하여 신경망 기반 코덱은 낮은 비트 전송률에서 훨씬 우수하며 양자화된 토큰에는 speaker와 녹음 조건에 대한 충분한 정보가 포함되어 있다고 생각할 수 있다. 다른 양자화 방법과 비교하여 오디오 코덱은 다음과 같은 장점을 보인다.
- Speaker 정보와 음향 정보가 풍부하여 HuBERT code와 비교하여 재구성 시 speaker identity를 유지할 수 있다.
- 스펙트럼에서 작동하는 VQ 기반 방법과 같이 vocoder 학습에 대한 추가 노력 없이 개별 토큰을 waveform으로 변환하는 상용 코덱 디코더가 있다.
- 효율성을 위하여 timestep 길이를 줄여 $\mu$-law 변환의 문제를 해결할 수 있다.
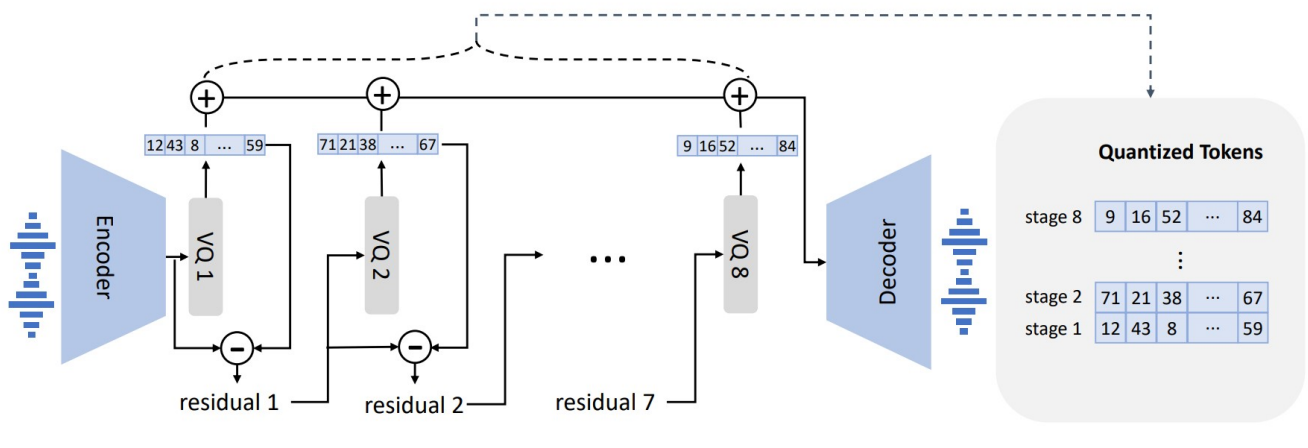
사전 학습된 오디오 코덱 모델인 EnCodec을 tokenizer로 채택한다. EnCodec은 가변 비트레이트에서 입력 및 출력이 모두 24kHz 오디오인 convolutional encoder-decoder 모델이다. 인코더는 24kHz의 입력 waveform에 대해 75Hz에서 임베딩을 생성하며, 이는 샘플링 속도가 320배 감소한 것이다. 각 임베딩은 Residual Vector Quantization (RVQ)로 모델링되며 위 그림과 같이 각각 1024개의 entry가 있는 8개의 hierarchy quantizer를 선택한다. 이 설정은 24kHz 오디오 재구성을 위한 6K 비트레이트의 EnCodec에 해당한다. 이 설정에서 주어진 10초 waveform에서의 이산 표현은 750$\times$8 행렬이다. 여기서 $750 = 24000 \times 10 / 320$은 downsampling된 timestep이고 8은 quantizer의 수이다. 다른 비트레이트 설정을 선택해도 좋다. 더 큰 비트레이트는 더 많은 quantizer와 더 나은 재구성 품질에 해당한다. 예를 들어, 12K 비트레이트에서 EnCodecc를 선택하면 16개의 quantizer가 필요하고 10초 waveform은 750$\times$16 행렬에 해당한다. 모든 quantizer의 개별 코드를 사용하여 EnCodec의 convolutional decoder는 실제 값 임베딩을 생성하고 24kHz에서 waveform을 재구성한다.
VALL-E
1. Problem Formulation: Regarding TTS as Conditional Codec Language Modeling
데이터셋 \(D = \{x_i, y_i\}\)가 주어지면 $y$는 오디오 샘플이고 \(x = \{x_0, x_1, \cdots, x_L\}\)은 해당 음소 transcription이며 사전 학습된 코덱 모델을 사용하여 각 오디오 샘플을 $\textrm{Encodec} (y) = C^{T \times 8}$로 표시되는 이산 음향 코드로 인코딩한다. 여기서 $C$는 2차원 음향 코드 행렬을 나타낸다. $T$는 downsampling된 발화 길이이다. $C$의 각 행 벡터 $c_{t,:}$는 프레임 $t$에 대한 8개의 코드를 나타내고 $C$의 각 열 벡터 $c_{:,j}$는 $j$번째 codebook의 코드 시퀀스를 나타낸다 (\(j \in \{1, \cdots, 8\}\)). 양자화 후 코덱 디코더는 $\textrm{Decodec}(C) \approx \hat{y}$로 표시되는 waveform을 재구성할 수 있다.
Zero-shot TTS는 모델이 보지 못한 speaker의 고품질 음성을 합성해야 한다. 본 논문에서는 zero-shot TTS를 조건부 코덱 언어 모델링 작업으로 간주한다. 음소 시퀀스 $x$와 음향 프롬프트 행렬 $\tilde{C}^{T’ \times 8}$을 조건으로 $C$를 생성하도록 최적화 목적 함수 $\max p(C \vert x, \tilde{C})$로 언어 모델을 학습시킨다. 여기서 $\tilde{C}$는 등록된 녹음을 입력으로 하는 동일한 코덱 모델에 의해 획득된다. 언어 모델은 각각 음소 시퀀스와 음향 프롬프트에서 콘텐츠와 speaker 정보를 추출하도록 학습될 것으로 기대된다. Inference하는 동안 음소 시퀀스와 보지 못한 화자의 3초 등록 녹음이 주어지면 해당 콘텐츠와 speaker의 음성이 포함된 음향 코드 행렬이 사전 학습된 언어 모델에 의해 추정된다. 그런 다음 코덱 디코더가 고품질 음성을 합성한다.
2. Training: Conditional Codec Language Modeling
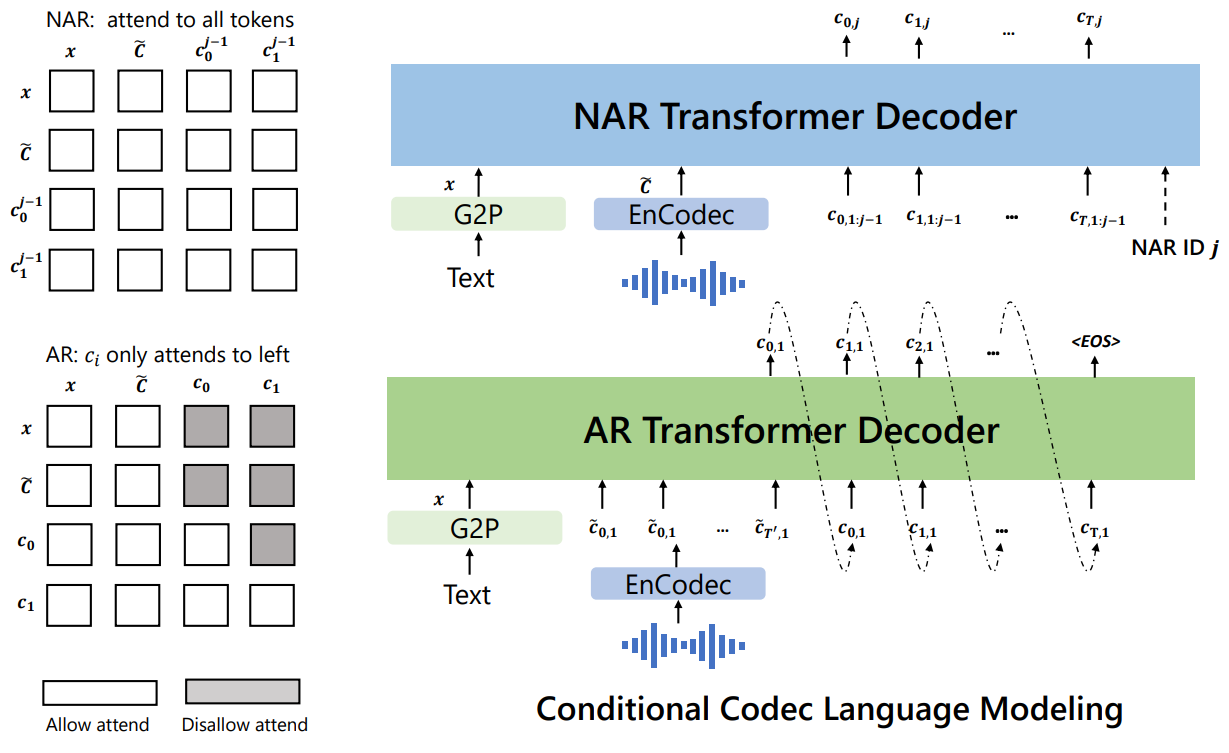
음성 코덱 모델을 사용하면 개별 오디오 표현에서 작동할 수 있다. 코덱 모델의 residual quantization으로 인해 토큰은 계층 구조를 갖는다. 이전 quantizer의 토큰은 speaker 식별과 같은 음향 속성을 복구하는 반면, 이어지는 quantizer는 미세한 음향 디테일을 학습한다. 각 양자화기는 이전 quantizer의 residual을 모델링하도록 학습된다. 이에 동기를 부여받아 두 가지 조건부 언어 모델을 계층적으로 디자인한다.
첫 번째 quantizer $c_{:,1}$의 개별 토큰에 대해 autoregressive (AR) 디코더 전용 언어 모델을 학습시킨다. 음소 시퀀스 $x$와 음향 프롬프트 $\tilde{C}_{:,1}$로 컨디셔닝되어 다음과 같이 공식화된다.
\[\begin{equation} p(c_{:,1} \vert x, \tilde{C}_{:,1} ; \theta_{AR}) = \prod_{t=0}^T p(c_{t,1} \vert c_{<t,1}, \tilde{c}_{:,1}, x; \theta_{AR}) \end{equation}\]VALL-E는 디코더 전용 LM이므로 \(\tilde{c}_{:,1}\)과 $c_{:,1}$의 concatenation은 전체 시퀀스이며 이를 구별하거나 학습에 특정 토큰을 삽입하지 않는다. $c_{:,1}$만 예측하고 inference하는 동안 \(\tilde{c}_{:,1}\)이 제공된다.
두 번째에서 마지막 quantizer $c_{:,j \in [2, 8]}$의 이산 토큰에 대해 non-autoregressive (NAR) 언어 모델을 시킨한다. 토큰은 NAR 방식으로 서로 액세스할 수 없으므로 spekaer 신원을 제한하기 위해 음향 프롬프트 행렬 $\tilde{C}$를 음향 프롬프트로 사용한다. 따라서 모델은 음소 시퀀스 $x$, 음향 프롬프트 $\tilde{C}$, 예측된 음향 토큰이 이전 codebook $C_{:,< j}$에 속한다.
\[\begin{equation} p(C_{:,2:8} \vert x, \tilde{C}; \theta_{NAR}) = \prod_{j=2}^8 p(c_{:,j} \vert C_{:,< j}, x, \tilde{C}; \theta_{NAR}) \end{equation}\]AR 모델과 NAR 모델의 조합은 음성 품질과 inference 속도 사이에 적절한 절충안을 제공한다. 한편으로, 생성된 음성의 속도는 등록된 녹음과 일치해야 하며, 말하는 속도가 매우 다양할 수 있기 때문에 여러 speaker에 대한 duration predictor를 학습하는 것은 어렵다. 이 경우 AR 모델은 음향 시퀀스 길이 예측을 위한 유연성을 갖춘 보다 자연스러운 선택이다. 반면 이어지는 stage의 경우 출력 슬롯의 수가 첫 번째 stage의 시퀀스 길이를 따르므로 NAR은 시간 복잡도를 $O(T)$에서 $O(1)$로 줄일 수 있다. 전반적으로 $C$의 예측은 다음과 같이 모델링할 수 있다.
\[\begin{equation} p(C \vert x, \tilde{C}; \theta) = p(c_{:,1} \vert \tilde{C}_{:,1}, X, \theta_{AR}) \prod_{j=2}^8 p(c_{:,j} \vert c_{:,< j}, x, \tilde{C}; \theta_{NAR}) \end{equation}\]Autoregressive Codec Language Modeling
AR 언어 모델은 첫 번째 quantizer에서 토큰을 생성한다. 음소 임베딩 $W_x$, 음향 임베딩 $W_a$, transformer 디코더, 예측 layer로 구성된다. 특정 내용으로 음성을 생성하기 위해 언어 모델의 음소 프롬프트로 음소 시퀀스를 사용한다. 따라서 모델 입력은 $x$와 $c_{:,1}$의 concatenation이며 두 개의 $\langle \textrm{EOS} \rangle$ 토큰이 각각 뒤에 추가된다. 프롬프트와 입력 토큰에 대해 별도로 sinuous position embedding을 계산한다. Causal Transformer 모델의 경우 각 토큰 $c_{t,1}$은 $(x, c_{\le t,1})$에 attention 연산을 할 수 있다. 모델은 첫 번째 codebook에서 다음 토큰의 확률을 최대화하도록 최적화된다. 음향 임베딩 $W_a$의 파라미터와 출력 projection layer의 파라미터를 공유한다.
AR 모델에서는 학습 시 프롬프트로 오디오 클립을 명시적으로 추출하지 않는다. 학습 과정은 순수 casual 언어 모델의 학습이다. 이러한 방식으로 모든 prefix 시퀀스 $c_{< t,1}$은 시퀀스 $c_{\ge t,1}$의 후반부에 대한 프롬프트로 처리된다. Inference하는 동안 등록된 녹음이 주어지면 등록된 녹음의 음소 시퀀스와 합성을 위한 음소 시퀀스를 함께 concat해야 한다. 한편 등록된 녹음의 음향 토큰 시퀀스는 AR 디코딩의 prefix로 사용된다.
Non-Autoregressive Codec Language Modeling
NAR 모델을 사용하여 나머지 7개의 quantizer 코드를 생성한다. NAR 모델은 8개의 개별 음향 임베딩 layer를 포함한다는 점을 제외하면 AR 모델과 유사한 아키텍처를 가지고 있다. 각 학습 step에서 학습 stage $i \in [2, 8]$을 랜덤하게 샘플링한다. 모델은 $i$번째 codebook의 음향 토큰을 최대화하도록 학습된다. 1단계에서 $i-1$단계까지의 음향 토큰이 임베딩되고 모두 더해 모델 입력으로 사용된다.
\[\begin{equation} e_{c_{t, j}} = W_a^j \odot c_{t, j} \\ e_{c_t} = \sum_{j=1}^{i-1} e_{c_{t,j}} \end{equation}\]$\odot$은 index 선택을 나타낸다. 음소 시퀀스도 언어 모델의 프롬프트로 간주된다. 또한 주어진 speaker의 고유한 음성을 복제하기 위해 등록된 음성의 음향 토큰을 음향 프롬프트로 사용한다. 구체적으로 먼저 코덱 모델을 사용하여 등록된 음성을 $\tilde{C}^{T \times 8}$로 토큰화한다. 8개 codebook 모두에서 포함된 표현은 음향 프롬프트
\[\begin{equation} e_{\tilde{c}_t} = \sum_{j=1}^8 e_{\tilde{c}_{t, j}} \end{equation}\]로 합쳐진다. $i$번째 codebook에서 음향 토큰을 예측하기 위해 transformer 입력은 $(e_x, e_{\tilde{c}}, e_{c:,< i})$의 concatenation이다. Positional embedding도 프롬프트와 음향 시퀀스에 대해 별도로 계산된다. 현재 stage $i$는 Adaptive Layer Normalization 연산자, 즉
\[\begin{equation} \textrm{AdaLN}(h, i) = a_i \textrm{LayerNorm}(h) + b_i \end{equation}\]를 사용하여 네트워크에 주입된다. 여기서 $h$는 중간 activation이고, $a_i$와 $b_i$는 stage 임베딩의 linear projection에서 얻는다. AR과 달리 NAR 모델에서는 각 토큰이 self-attention layer의 모든 입력 토큰과 attention 연산을 할 수 있다. 또한 음향 임베딩 layer와 출력 예측 layer의 파라미터를 공유한다. 즉, $j$번째 예측 layer의 가중치는 $(j + 1)$번째 음향 임베딩 layer와 동일하다.
3. Inference: In-Context Learning via Prompting
In-context 학습은 추가 파라미터 업데이트 없이 보지 못한 입력에 대한 레이블을 예측할 수 있는 텍스트 기반 언어 모델의 놀라운 능력이다. TTS의 경우 모델이 fine-tuning 없이 보지 못한 speaker의 고품질 음성을 합성할 수 있다면 해당 모델은 in-context 학습 능력이 있는 것으로 간주된다. 그러나 기존 TTS 시스템의 in-context 학습 능력은 fine-tuning이 필요하거나 보지 못한 speaker에 대해 크게 저하되기 때문에 강력하지 않다.
언어 모델의 경우 zero-shot 시나리오에서 상황 내 학습을 활성화하려면 프롬프트가 필요하다. 저자들은 프롬프트와 inference를 다음과 같이 디자인하였다. 먼저 텍스트를 음소 시퀀스로 변환하고 등록된 녹음을 음향 행렬로 인코딩하여 음소 프롬프트와 음향 프롬프트를 형성한다. 두 프롬프트 모두 AR 및 NAR 모델에서 사용된다. AR 모델의 경우 beam search가 LM을 무한 루프로 이끌 수 있기 때문에 프롬프트들로 컨디셔닝된 샘플링 기반 디코딩을 사용한다. 또한 샘플링 기반 방법은 출력의 다양성을 크게 높일 수 있다. NAR 모델의 경우 greedy 디코딩을 사용하여 확률이 가장 높은 토큰을 선택한다. 마지막으로 코덱 디코더를 사용하여 8개의 코드 시퀀스를 조건으로 waveform을 생성한다. 음향 프롬프트는 합성할 음성과 의미론적으로 관련될 수도 있고 그렇지 않을 수도 있으며 결과적으로 두 가지 경우가 있다.
VALL-E
본 논문의 주요 관심사는 보지 못한 speaker에 대한 주어진 콘텐츠를 생성하는 것이다. 모델에는 텍스트 문장, 등록된 음성 세그먼트, 해당 transcription이 제공된다. 등록된 음성의 transcription 음소를 주어진 문장의 음소 시퀀스에 음소 프롬프트로 추가하고 등록된 음성 $\tilde{c}_{:,1}$의 첫 번째 layer 음향 토큰을 음향 prefix로 사용한다. 음소 프롬프트와 음향 prefix를 사용하여 VALL-E는 이 speaker의 음성을 복제하는 주어진 텍스트에 대한 음향 토큰을 생성한다.
VALL-E-continual
이 설정에서 전체 transcription과 발화의 처음 3초를 각각 음소 프롬프트와 음향 프롬프트로 사용하고 모델에 continuation을 생성하도록 요청한다. Inference 과정은 등록된 음성과 생성된 음성이 의미적으로 연속적이라는 점을 제외하면 VALL-E와 동일하다.
Experiments
- 데이터셋: LibriLight, LibriSpeech (ASR 모델 학습)
- Model: AR 모델과 NAR 모델 모두 동일한 transformer 아키텍처 사용
- layer: 12개
- attention head: 16개
- 임베딩 차원: 1024
- feed-forward layer 차원: 4096
- dropout: 0.1
- 학습 디테일
- 평균 60초의 waveform을 10~20초로 crop
- GPU: NVIDIA TESLA V100 32GB GPU 16개
- batch size: GPU당 음향 토큰 6000개
- optimizer: AdamW
- learning rate: $5 \times 10^{-4}$, linear warm-up 32k update, linear decay
- Automatic metrics
- Speaker 유사성: SOTA speaker verification model인 WavLM-TDNN로 speaker 유사성 평가
- Robustness: 생성된 오디오에 HuBERT-Large로 ASR을 수행하여 word error rate (WER) 측정되는
- Human evaluation
- Comparative mean option score (CMOS)
- Similarity mean option score (SMOS)
1. LibriSpeech Evaluation
다음은 오디오 생성에 대한 평가 결과이다.
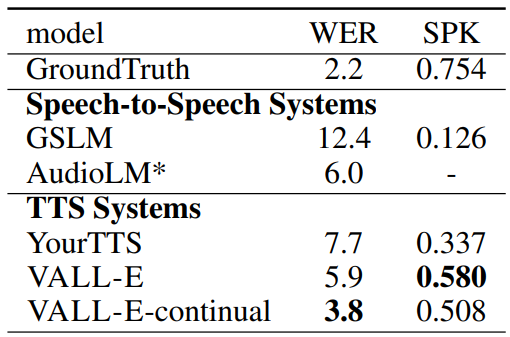
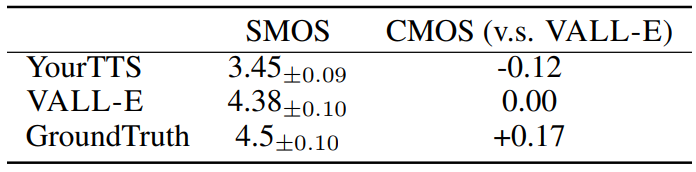
다음은 human evaluation 결과이다.
Ablation study
다음은 NAR 모델에 대한 ablation study 결과이다.

- NAR-no prompt: 어떠한 프롬프트도 사용하지 않고 학습
- NAR-phn prompt: 음소 프롬프트만 사용하여 학습
- NAR-2 prompts: 음소 프롬프트와 음향 토큰 프롬프트를 모두 사용하여 학습
다음은 AR 모델에 대한 ablation study 결과이다.

2. VCTK Evaluation
다음은 VCTK의 speaker 108명에 대한 spekaer 유사성을 평가한 결과이다. YourTTS는 학습 중에 97명의 speaker를 보았지만, VALL-E는 모든 speaker를 보지 못하였다.
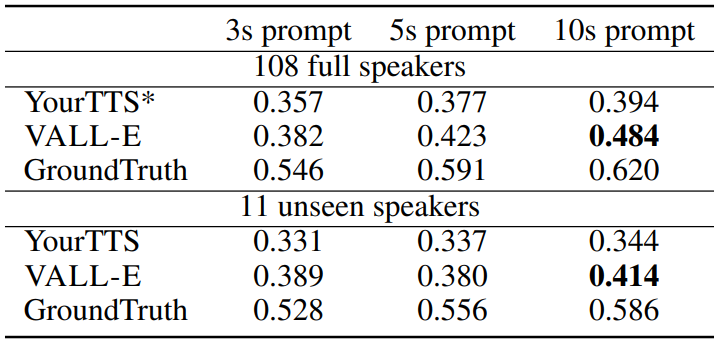
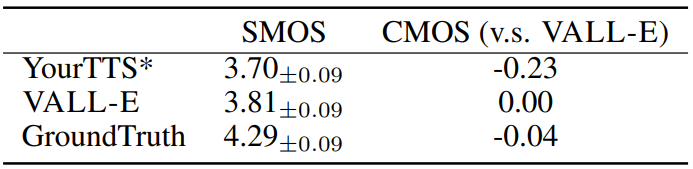
다음은 VCTK의 speaker 60명에 대한 human evaluation 결과이다.
3. Qualitative Analysis
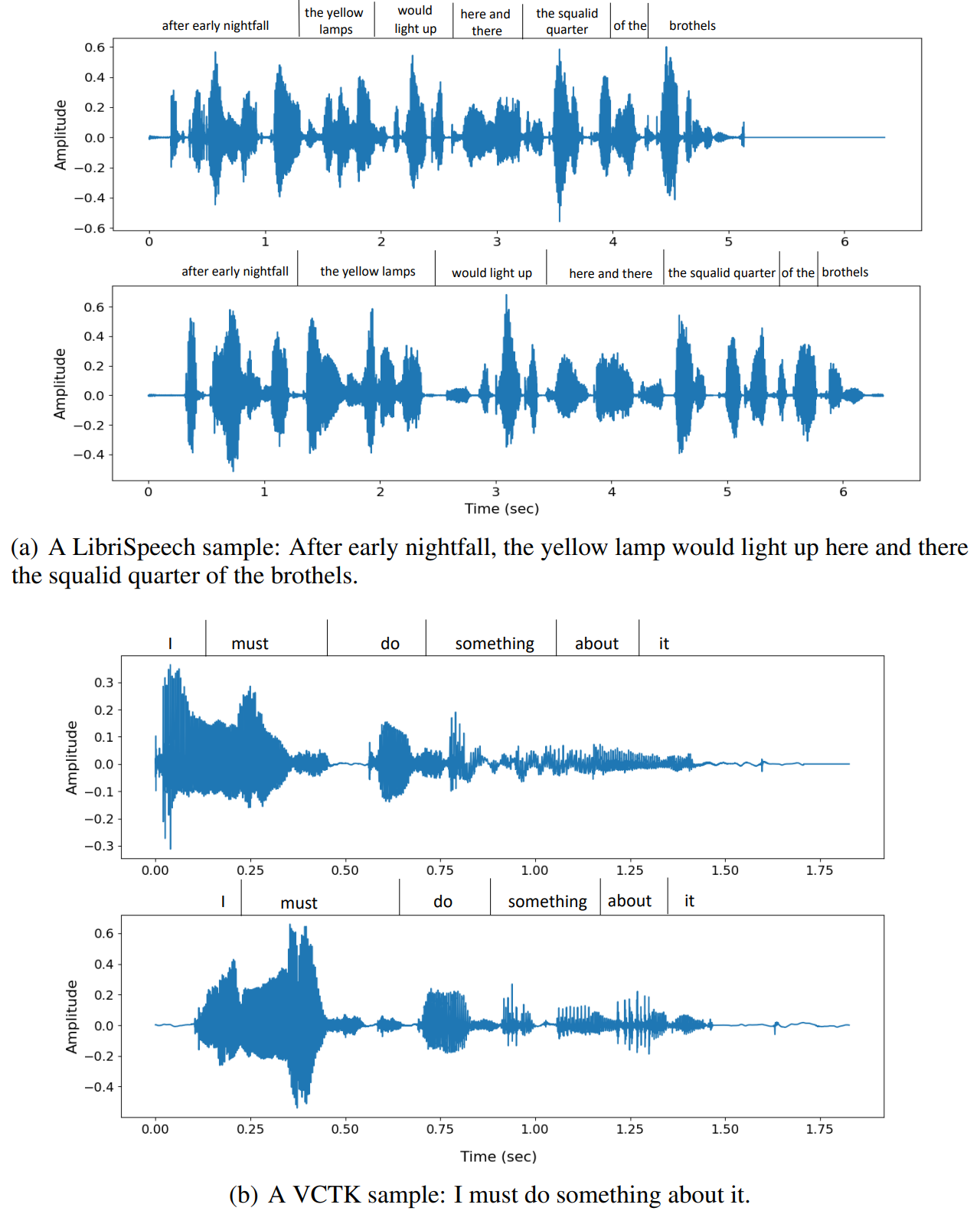
다음은 VALL-E의 다양성을 보여주는 LibriSpeech 샘플과 VCTK 샘플들이다.