[논문리뷰] Upsample Anything: A Simple and Hard to Beat Baseline for Feature Upsampling
arXiv 2025. [Paper] [Page] [Github]
Minseok Seo, Mark Hamilton, Changick Kim
KAIST | MIT | Microsoft
20 Nov 2025

Introduction
본 논문에서는 feature 업샘플링을 위한 test-time optimization (TTO) 프레임워크인 Upsample Anything을 제안하였다. 데이터셋 수준의 학습을 필요로 하는 기존 방식과 달리, Upsample Anything은 이미지 단위로 가벼운 최적화를 수행하며, 224$\times$224 크기의 이미지를 약 0.419초 만에 처리한다. 입력 이미지가 주어지면, Upsample Anything은 RGB 가이드의 크기를 저해상도(LR) feature map 크기에 맞게 조정하고, 최적화를 통해 고해상도(HR) 컬러 이미지를 재구성하며, 픽셀 단위의 anisotropic Gaussian 파라미터 \((\sigma_x, \sigma_y, \theta, \sigma_r)\)을 학습한다. 이렇게 최적화된 커널은 foundation model 인코더에서 생성된 LR feature map에 적용되어 원본 이미지 그리드에 정렬된 HR feature map을 생성한다.
최적화는 색상 재구성만을 기반으로 하지만, 학습된 커널은 기하학적 정보와 semantic 정보를 암시적으로 포착한다. 결과적으로 Upsample Anything은 2D feature 해상도를 향상시킬 뿐만 아니라 재학습 없이 다른 픽셀 수준 또는 voxel 수준 신호에도 일반화된다. 이러한 특성은 2D 및 3D 영역 전반에 걸쳐 통합되고, 가볍고, 해상도에 구애받지 않는 업샘플링 연산자로서의 잠재력을 보여준다.
데이터셋 수준의 학습이 필요하지 않음에도 불구하고, semantic segmentation 및 깊이 추정을 포함한 여러 픽셀 수준 벤치마크에서 일관되게 SOTA 또는 SOTA에 가까운 성능을 달성하였다.
Methods
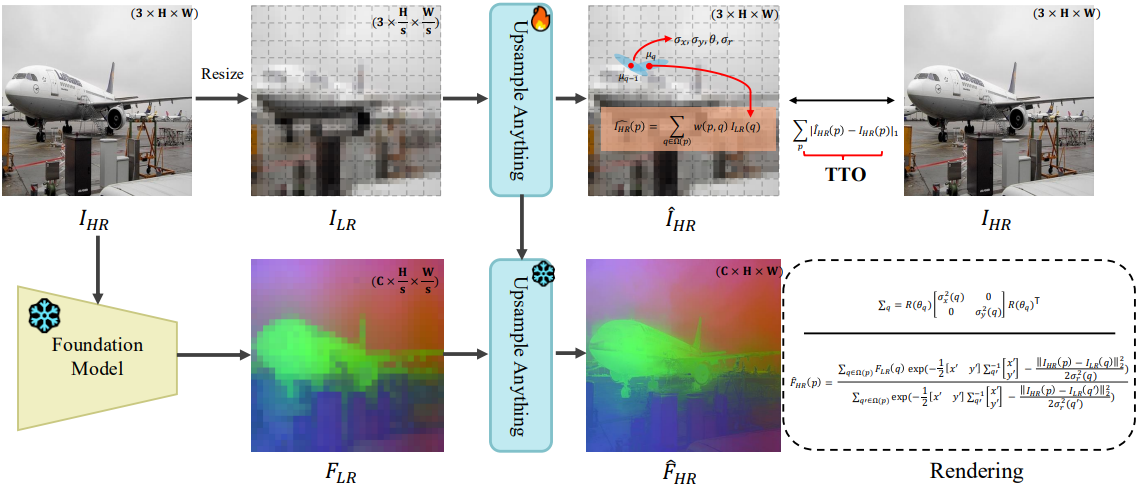
1. Overview
본 논문에서 제안하는 Upsample Anything은 test-time optimization (TTO)와 feature 렌더링의 두 단계로 구성된다. TTO 단계에서는 패치 단위로 다운샘플링된 이미지 \(I_\textrm{lr}\)로부터 고해상도 이미지 \(I_\textrm{hr}\)을 재구성하여 픽셀 단위의 anisotropic Gaussian 파라미터 \(\{\sigma_x, \sigma_y, \theta, \sigma_r\}\)을 학습한다. 이 과정을 통해 각 픽셀은 유사한 이웃 픽셀들을 어떻게 혼합해야 하는지 학습하게 되며, 이미지 도메인을 넘어 일반화될 수 있는 로컬 혼합 가중치를 효과적으로 발견한다. 최적화된 Gaussian 커널은 feature space로 직접 전달되어, 학습된 anisotropic 가중치 메커니즘을 사용하여 저해상도 feature map \(F_\textrm{lr}\)을 고해상도 feature \(F_\textrm{hr}\)로 변환한다.
Splatting 가중치는 공간-범위 유사성에만 의존하기 때문에, 이 전송은 자연스럽게 도메인에 구애받지 않으며, 학습된 커널이 범용 업샘플링 연산자로 작동할 수 있도록 한다. Feature 추출 시간을 제외하면, 224$\times$224 이미지에 대한 전체 최적화 및 inference에는 약 0.419초가 소요된다.
2. Algorithm Design
본 논문의 디자인은 고전적인 Joint Bilateral Upsampling (JBU)에서 영감을 받았다. JBU의 핵심 장점은 새로운 값을 만들어내는 것이 아니라, 인접한 샘플을 얼마나 혼합할지 결정하는 혼합 가중치를 학습하여 자연스럽게 모델과 task에 독립적이다. 그러나 표준 JBU는 글로벌하고 isotropic한 커널에 의해 제한되어 복잡한 구조 근처에서 표현력이 감소한다.
Per-pixel anisotropic kernels
이러한 한계를 극복하기 위해 Upsample Anything은 각 저해상도 위치 $q$에 대해 파라미터 \(\{\sigma_x(q), \sigma_y(q), \theta(q), \sigma_r(q)\}\)를 갖는 저해상도 픽셀 단위의 anisotropic Gaussian을 할당한다. 공간 공분산을 다음과 같이 정의한다.
\[\begin{equation} \Sigma_q = R(\theta_q) \begin{bmatrix} \sigma_x^2 (q) & 0 \\ 0 & \sigma_y^2 (q) \end{bmatrix} R^\top (\theta_q), \quad R(\theta_q) = \begin{bmatrix} \cos \theta_q & -\sin \theta_q \\ \sin \theta_q & \cos \theta_q \end{bmatrix} \end{equation}\]HR 좌표 $p$에 대해 정규화되지 않은 공간 가중치와 범위 가중치는 다음과 같다.
\[\begin{aligned} \log w_{p \leftarrow q}^s &= - \frac{1}{2} (p - \mu_q)^\top \Sigma_q^{-1} (p - \mu_q) \\ \log w_{p \leftarrow q}^r &= - \frac{\| I (p) - I (q) \|^2}{2 \sigma_r^2 (q)} \end{aligned}\](\(\mu_q\)는 LR 중심을 HR 좌표계로 projection한 것, $I(\cdot)$는 HR 가이드 이미지)
최종 정규화된 혼합 가중치는 다음과 같다.
\[\begin{equation} w_{p \leftarrow q} = \frac{\exp \left( \log w_{p \leftarrow q}^s + \log w_{p \leftarrow q}^r \right)}{\sum_{q^\prime \in \Omega (p)} \exp \left( \log w_{p \leftarrow q^\prime}^s + \log w_{p \leftarrow q^\prime}^r \right)} \end{equation}\]Feature 렌더링
저해상도 feature \(F_\textrm{lr} \in \mathbb{R}^{C \times H \times W}\)와 scale $s$가 주어졌을 때, 순수 혼합을 통해 고해상도 feature \(F_\textrm{hr} \in \mathbb{R}^{C \times sH \times sW}\)를 렌더링한다.
\[\begin{equation} F_\textrm{hr} (p) = \sum_{q \in \Omega (p)} w_{p \leftarrow q} F_\textrm{lr} (q) \end{equation}\]이는 콘텐츠 생성 없이 기존 LR feature의 가중치를 엄격하게 재조정하는 방식이며, 따라서 backbone 및 task 간에 전송이 가능하다.
왜 일반화되는가
데이터셋 수준의 학습이 필요한 feed-forward 업샘플러와 달리, Upsample Anything은 TTO 프로세스를 통해 HR 가이드로부터 이미지별, 픽셀 단위의 혼합 가중치만을 학습하고, 이러한 가중치를 재사용하여 \(F_\textrm{lr}\)을 \(F_\textrm{hr}\)로 변환한다. 이 메커니즘은 값 합성 방식이 아닌 edge 및 범위 기반 interpolation 방식이므로, Upsample Anything은 본질적으로 해상도에 구애받지 않고, 모델에 구애받지 않으며, 미지의 도메인에 대해서도 robust하다.
3. Test-Time Optimization
다음 단계는 픽셀 단위 파라미터 \(\{\sigma_x, \sigma_y, \theta, \sigma_r\}\)을 최적화하는 것이다. 핵심 아이디어는 최신 vision foundation model (VFM)의 패치 처리 방식에서 영감을 얻었다. VFM은 고정된 stride로 이미지를 다운샘플링하여 저해상도 feature를 추출하는데, 저자들은 최적화 과정에서 이 과정을 모방하였다.
구체적으로, 고해상도 이미지 \(I_\textrm{hr}\)은 stride $s$를 갖는 bilinear interpolation을 통해 \(I_\textrm{lr}\)로 다운샘플링되고, GSJBU 파라미터는 \(I_\textrm{lr}\)에서 \(I_\textrm{hr}\)로의 재구성 loss로 최적화된다.
\[\begin{equation} \mathcal{L}_\textrm{TTO} = \| \textrm{GSJBU} (I_\textrm{lr}) - I_\textrm{hr} \| \end{equation}\]이 TTO는 guidance 신호를 가장 잘 재구성하는 이미지별 per-pixel kernel을 찾는다.
TTO 프로세스 후, 학습된 커널은 고해상도 feature map을 렌더링하는 데 재사용된다.
\[\begin{equation} F_\textrm{hr} = \textrm{GSJBU}(F_\textrm{lr}; \hat{\sigma}_x, \hat{\sigma}_y, \hat{\theta}, \hat{\sigma}_r) \end{equation}\]최적화된 파라미터 \(\{\hat{\sigma}_x, \hat{\sigma}_y, \hat{\theta}, \hat{\sigma}_r\}\)는 \(F_\textrm{lr}\)을 \(F_\textrm{hr}\)로 업샘플링하기 위해 feature space로 직접 전달된다.
Experiments
- 구현 디테일
- 파라미터 초기값: \(\sigma_x = \sigma_y = 16.0\), \(\sigma_r = 0.12\), $\theta = 0$
- optimizer: Adam
- learning rate: $1 \times 10^{-3}$
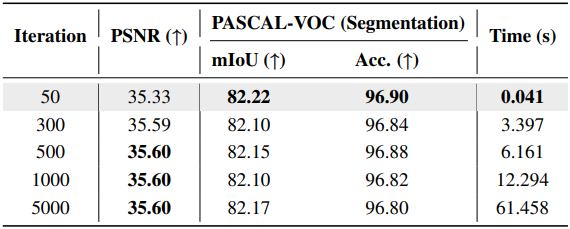
- TTO iteration: 50
1. Quantitative results
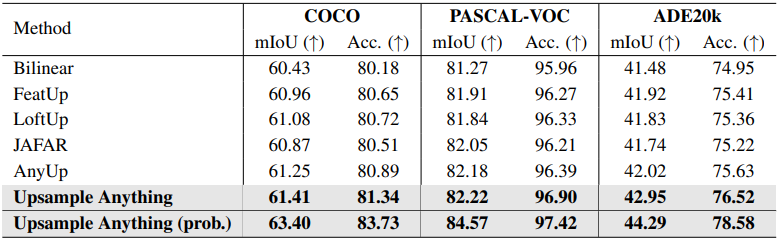
다음은 semantic segmentation에 대하여 다른 업샘플링 방법들과 비교한 결과이다.
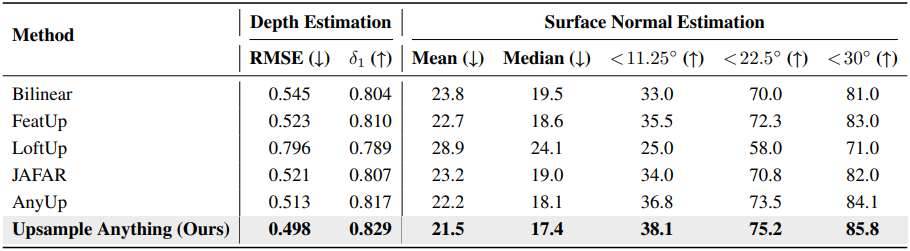
다음은 depth 및 normal 추정에 대하여 다른 업샘플링 방법들과 비교한 결과이다. (NYUv2)
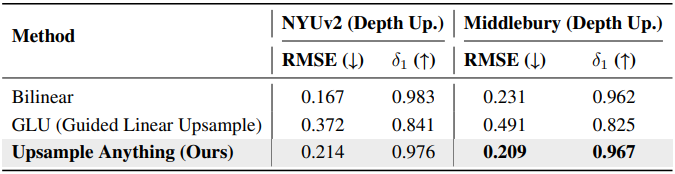
다음은 depth map 업샘플링에 대한 비교 결과이다.

2. Qualitative results
다음은 다양한 해상도에 대한 비교 결과이다.

다음은 다양한 backbone에 대한 비교 결과이다.

다음은 두 이미지의 feature 유사도를 비교한 결과이다.

3. Ablation Study
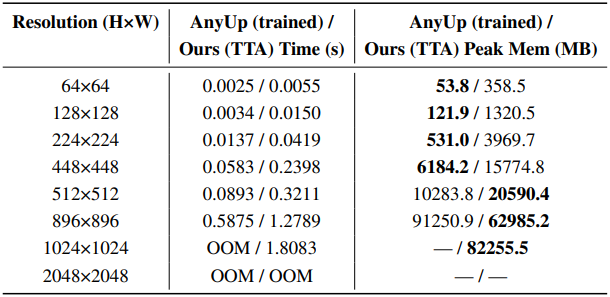
다음은 inference time과 GPU 메모리 사용량을 다양한 입력 해상도에 대해 비교한 결과이다.
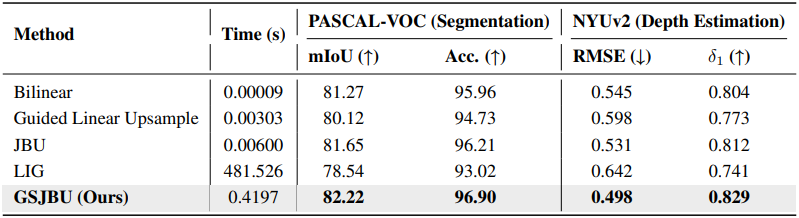
다음은 inference time, segmentation 성능, 깊이 추정 성능을 동시에 비교한 결과이다.
다음은 TTO iteration에 대한 ablation 결과이다.