[논문리뷰] UnitSpeech: Speaker-adaptive Speech Synthesis with Untranscribed Data
INTERSPEECH 2023. [Paper] [Page] [Github]
Heeseung Kim, Sungwon Kim, Jiheum Yeom, Sungroh Yoon
Seoul National University
28 Jun 2023
Introduction
최근 TTS (text-to-speech) 모델이 상당한 발전을 보임에 따라 타겟 speaker의 레퍼런스 음성을 사용하여 개인화된 음성을 생성하는 적응형 TTS 모델에 대한 연구들도 진행되고 있다. 적응형 TTS 모델은 대부분 사전 학습된 multi-speaker TTS 모델을 사용하며 타겟 speaker 임베딩을 사용하거나 적은 데이터로 모델을 fine-tuning하는 등의 방법을 활용한다. 전자는 후자에 비해 더 쉽게 적응할 수 있지만 speaker 유사성이 상대적으로 낮다.
대부분의 fine-tuning 기반 접근 방식에는 소량의 타겟 speaker 음성 데이터가 필요하며 해당 음성과 쌍을 이루는 전사(transcript)가 필요할 수도 있다. AdaSpeech 2는 전사되지 않은 음성으로 사전 학습된 TTS 모델을 fine-tuning하기 위해 플러그형 mel-spectrogram 인코더 (mel encoder)를 제안한다. Fine-tuning 중에 텍스트 인코더를 대체하기 위해 mel encoder가 도입되었으므로 AdaSpeech 2는 타겟 speaker에서 디코더를 fine-tuning할 때 전사가 필요하지 않다. 그러나 그 결과는 적응적 TTS에만 국한되며 deterministic한 피드포워드 디코더로 인해 상대적으로 많은 양의 타겟 speaker 데이터를 요구하는 등의 한계를 보인다.
Diffusion model에 대한 최근 연구는 몇 개의 이미지만으로 text-to-image 생성과 개인화에 강력한 결과를 보여주고 있으며 이러한 추세는 음성 합성과 적응형 TTS로 확장되고 있다. Guided-TTS 2는 diffusion mdoel의 fine-tuning 능력과 classifier guidance 기술을 활용하여 10초 길이의 전사되지 않은 음성만으로 고품질 적응형 TTS를 구축한다. 그러나 Guided-TTS 2는 unconditional 생성 모델의 학습이 필요하므로 일반적인 TTS 모델에 비해 학습이 더 어렵고 시간이 많이 걸린다.
본 논문에서는 소량의 전사되지 않은 음성에 대해 사전 학습된 diffusion 기반 TTS 모델을 fein-tuning하여 개인화된 음성 합성을 수행하는 UnitSpeech를 제안한다. Fine-tuning을 위해 전사된 데이터가 필요한 spekaer 적응을 위한 backbone TTS 모델로 multi-speaker Grad-TTS를 사용한다. 마찬가지로 AdaSpeech 2에서는 전사 없이 음성 콘텐츠를 diffusion 기반 디코더에 제공하는 새로운 인코더 모델을 도입한다. AdaSpeech 2는 mel-spectrogram을 인코더의 입력으로 직접 사용하지만, 텍스트 인코더를 더 잘 대체하기 위해 speaker ID와 분리된 음성 콘텐츠를 포함하는 self-supervised unit 표현을 사용한다.
새로 도입된 인코더인 unit encoder는 음성 콘텐츠를 입력 unit을 사용하여 diffusion 기반 디코더에 컨디셔닝하도록 학습된다. Speaker 적응을 위해 타겟 speaker의 $\langle$unit, speech$\rangle$ 쌍을 사용하여 unit encoder 출력으로 컨디셔닝된 사전 학습된 diffusion model을 fine-tuning한다. Diffusion 디코더를 타겟 speaker에 맞춤화함으로써 UnitSpeech는 전사 또는 unit을 입력으로 받는 여러 개의 적응형 음성 합성 task를 수행할 수 있다.
Method
본 논문의 목표는 전사되지 않은 데이터만 사용하여 기존 diffusion 기반 TTS 모델을 개인화하는 것이다. 전사 없이 diffusion model을 개인화하기 위해 fine-tuning 중에 텍스트 인코더를 교체하며, 이를 위해 음성 콘텐츠를 인코딩하는 방법을 학습하는 unit encoder를 도입한다. 학습된 unit encoder를 사용하여 사전 학습된 TTS 모델을 다양한 task의 타겟 speaker에 적응시킨다.
1. Diffusion-based Text-to-Speech Model
Single-speaker TTS에서 Grad-TTS의 성공에 따라 multi-speaker Grad-TTS를 사전 학습된 diffusion 기반 TTS 모델로 채택한다. Grad-TTS와 마찬가지로 텍스트 인코더, duration predictor, diffusion 기반 디코더로 구성되며, Multi-speaker TTS를 위한 spaker 정보를 추가로 제공한다. Spekaer 정보를 제공하기 위해 speaker encoder에서 추출한 speaker 임베딩을 사용한다.
Diffusion 기반의 TTS 모델은 mel-spectrogram $X_0$를 점진적으로 Gaussian noise $z = X_T \sim \mathcal{N} (0, I)$로 변환하는 forward process를 정의하고, forward process를 reverse하여 데이터를 생성한다. Grad-TTS는 mel-spectrogram-aligned text encoder 출력을 사용하여 prior 분포를 정의하지만 표준 정규 분포를 prior 분포로 사용한다. Diffusion model의 forward process는 다음과 같다.
\[\begin{equation} dX_t = -\frac{1}{2} X_t \beta_t dt + \sqrt{\beta_t} dW_t, \quad t \in [0, T] \end{equation}\]여기서 $\beta_t$는 미리 정의된 noise schedule이고, $W_t$는 Wiener process이다. $T$는 1로 설정된다.
사전 학습된 diffusion 기반 디코더는 reverse process를 통해 샘플링 시 필요한 score를 예측한다. 사전 학습을 위해 데이터 $X_0$는 forward process를 통해 noisy한 데이터
\[\begin{equation} X_t = \sqrt{1 - \lambda_t} X_0 + \sqrt{\lambda_t} \epsilon_t \end{equation}\]로 손상되고, 디코더는 정렬된 텍스트 인코더 출력 $c_y$와 speaker 임베딩 $e_S$가 주어지면 조건부 score를 추정하는 방법을 다음과 같은 목적 함수로 학습한다.
\[\begin{equation} L_\textrm{grad} = \mathbb{E}_{t, X_0, \epsilon_t} [\| \sqrt{\lambda_t} s_\theta (X_t, t \vert c_y, e_S) + \epsilon_t \|_2^2] \\ \lambda_t = 1 - \exp \bigg(- \int_0^t \beta_s ds \bigg), \quad t \in [0, 1] \end{equation}\]Diffusion 기반 디코더의 출력인 추정 score $s_\theta$를 사용하여 모델은 다음과 같은 discretize된 reverse process를 사용하여 전사와 speaker 임베딩이 주어지면 mel-spectrogram $X_0$을 생성할 수 있다.
\[\begin{equation} X_{t - \frac{1}{N}} = X_t + \frac{\beta_t}{N} \bigg( \frac{1}{2} X_t + s_\theta (X_t, t \vert c_y, e_S) \bigg) + \sqrt{\frac{\beta_t}{N}} z_t \end{equation}\]사전 학습된 TTS 모델은 \(L_\textrm{grad}\) 외에도 GlowTTS에서 제안한 monotonic alignment search (MAS)을 사용하여 텍스트 인코더의 출력을 mel-spectrogram과 정렬한다. 또한 encoder loss \(L_\textrm{enc} = \textrm{MSE}(c_y, X_0)\)를 사용하여 정렬된 텍스트 인코더 출력 $c_y$와 mel-spectrogram $X_0$ 사이의 거리를 최소화한다. Speaker ID로 텍스트 인코더 출력을 분리하기 위해 텍스트 인코더에 $e_S$를 포함하는 speaker를 제공하지 않고 spekaer에 독립적인 표현 $c_y$와 $X_0$ 사이의 거리를 최소화한다.
2. Unit Encoder Training
최소한의 전사되지 않은 레퍼런스 데이터가 주어지면 고품질 적응을 위해 사전 학습된 TTS 모델을 fine-tuning하는 것을 목표로 하지만 사전 학습된 TTS 모델만으로는 구조적으로 그렇게 하기가 어렵다. 사전 학습된 TTS 모델은 전사된 음성 데이터를 사용한 학습으로만 제한되는 반면, 현실에서 음성 데이터의 대부분은 전사되지 않은 데이터이다. 이 문제에 대한 해결책으로 unit encoder와 사전 학습된 TTS 모델을 결합하여 적응을 위한 생성 능력을 확장한다.
Unit encoder는 TTS 모델의 텍스트 인코더와 아키텍처와 역할 모두 동일한 모델이다. 전사를 사용하는 텍스트 인코더와 달리 unit encoder는 unit으로 알려진 discretize된 표현을 사용하여 모델의 생성 능력을 확장하고, 이를 통해 전사되지 않은 음성에 적응할 수 있다.
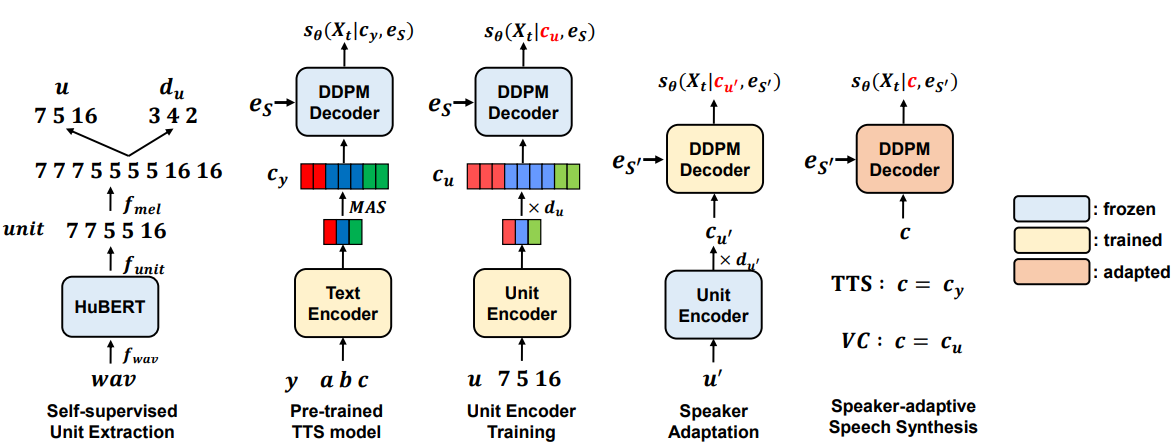
구체적으로 unit은 음성에 대한 self-supervised 모델인 HuBERT에서 얻은 discretize된 표현이다. 위 그림의 가장 왼쪽 부분은 음성 파형을 HuBERT의 입력으로 사용하고 출력 표현을 K-mean 클러스터링을 통해unit 클러스터로 discretize하여 unit 시퀀스를 생성하는 unit 추출 프로세스를 보여준다. 적절한 수의 클러스터를 설정하면 주로 원하는 음성 콘텐츠를 포함하도록 unit을 제한할 수 있다. HuBERT에서 얻은 unit 시퀀스는 mel-spectrogram 길이로 업샘플링된 다음 unit duration $d_u$와 squeeze된 unit 시퀀스 $u$로 압축된다.
위 그림의 가운데는 unit encoder의 학습 과정을 보여준다. Squeeze된 unit 시퀀스 $u$를 입력으로 사용하여 사전 학습된 TTS 모델에 연결된 unit encoder는 텍스트 인코더와 동일한 역할을 한다. Unit encoder는 동일한 목적 함수
\[\begin{equation} L = L_\textrm{grad} + L_\textrm{enc} \end{equation}\]로 학습되며, $c_y$만 $c_u$로 대체되고 ground-truth duration $d_u$를 사용하는 확장된 unit encoder 출력이다. 그 결과 $c_u$가 $c_y$와 같은 space에 배치되어 모델이 fine-tuning 중에 텍스트 인코더를 unit encoder로 대체할 수 있다. Diffusion 디코더는 고정되어 있으며 unit encoder만 학습된다.
3. Speaker-Adaptive Speech Synthesis
사전 학습된 TTS 모델과 플러그형 unit encoder를 결합하여 타겟 speaker의 전사되지 않은 단일 음성을 사용하여 적응형 방식으로 다양한 음성 합성 task를 수행할 수 있다. 레퍼런스 음성에서 추출한 squeeze된 unit $u’$과 unit duration $d_{u’}$를 이용하여 unit encoder를 사용하여 TTS 모델의 디코더를 fine-tuning한다. 이때 발음 열화를 최소화하기 위해 unit encoder를 고정하고, $c_y$를 $c_{u’}$으로 바꾼 목적 함수만을 사용하여 diffusion 디코더만 학습시킨다.
학습된 모델은 전사 또는 unit을 입력으로 사용하여 적응형 음성을 합성할 수 있다. TTS의 경우 fine-tuning된 디코더에 조건으로 $c_y$를 제공하여 주어진 전사와 관련하여 개인화된 음성을 생성한다. Voice Conversion (VC)이나 speech-to-speech 등의 unit을 사용할 때, HuBERT를 사용하여 주어진 소스 음성에서 squeeze된 unit $u$와 unit duration $d_u$를 추출한다. 추출된 2개는 $c_u$를 출력하는 unit encoder에 입력되고 적응형 diffusion 디코더는 $c_u$를 조건으로 변환된 음성을 생성한다.
모델의 발음을 더욱 향상시키기 위해 샘플링 중에 classifier-free guidance를 활용하여 unconditional score를 사용하여 타겟 조건에 대한 컨디셔닝 정도를 증폭한다. Classifier-free guidance에는 unconditional score를 추정하기 위해 해당 unconditional embedding $e_\Phi$가 필요하다. Encoder loss는 mel-spectrogram에 가까운 인코더 출력 space를 구동하기 때문에 $e_\Phi$를 학습하는 대신 데이터셋의 mel-spectrogram 평균 \(c_\textrm{mel}\)로 설정한다. Classifier-free guidance를 위해 활용하는 수정된 score는 다음과 같다.
\[\begin{equation} \hat{s} (X_t, t \vert c_c, e_S) = s(X_t, t \vert c_c, e_S) + \gamma \cdot \alpha_t \\ \alpha_t = s(X_t, t \vert c_c, e_S) - s(X_t, t \vert c_\textrm{mel}, e_S) \end{equation}\]여기서 $c_c$는 텍스트 인코더 또는 unit encoder의 정렬된 출력을 나타내고 $\gamma$는 제공되는 조건 정보의 양을 결정하는 gradient scale을 나타낸다.
Experiments
- 데이터셋
- LibriTTS: multi-speaker TTS와 unit encoder 학습
- VoxCeleb 2: speaker encoder 학습
- 학습 디테일
- 사전 학습된 TTS 모델은 Grad-TTS와 동일한 아키텍처와 hyperparameter 사용
- Unit encoder의 아키텍처는 text encoder의 아키텍처와 동일
- NVIDIA RTX 8000 GPU 4개 사용
- Iteration: TTS 모델은 140만, unit encoder는 20만
- Optimizer: Adam
- Learning rate: $10^{-4}$
- Batch size: 64
- 전사는 g2pE를 사용하여 음소 시퀀스로 변환
- textless-lib을 사용하여 unit 시퀀스 추출
- GE2E loss로 speaker encoder를 학습하여 각 레퍼런스 음성에서 speaker embedding $e_S$ 추출
- Fine-tuning 디테일
- Optimizer: Adam
- Learning rate: $2 \times 10^{-5}$
- Fine-tuning step: 500
- NVIDIA RTX 8000 GPU 1개에서 1분 미만 소요
1. Adaptive Text-to-Speech
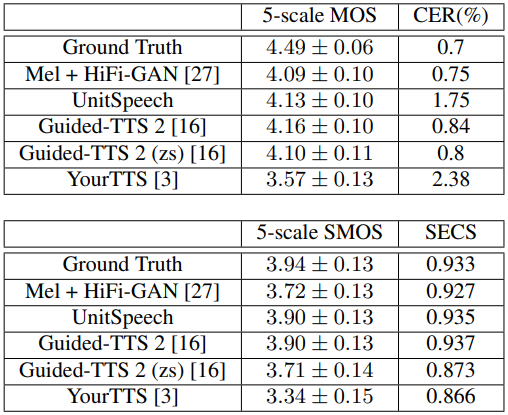
다음은 TTS 성능을 비교한 표이다. zs는 fine-tuning 없이 zero-shot 적응을 수행한 것을 나타낸다.
2. Any-to-Any Voice Conversion
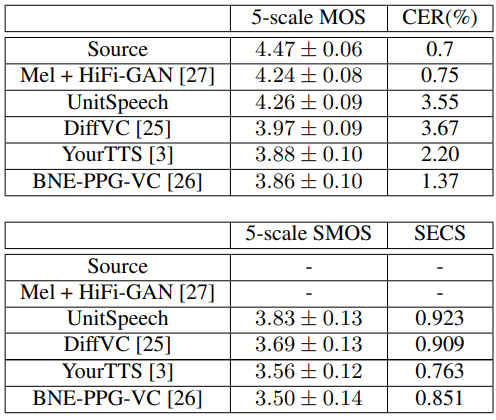
다음은 Voice Conversion 성능을 비교한 표이다.
3. Analysis
다음은 unit 클러스터의 수 $K$, fine-tuning iteration, fine-tuning에 사용된 음성의 길이, gradient scale $\gamma$의 효과를 보여주는 표이다.
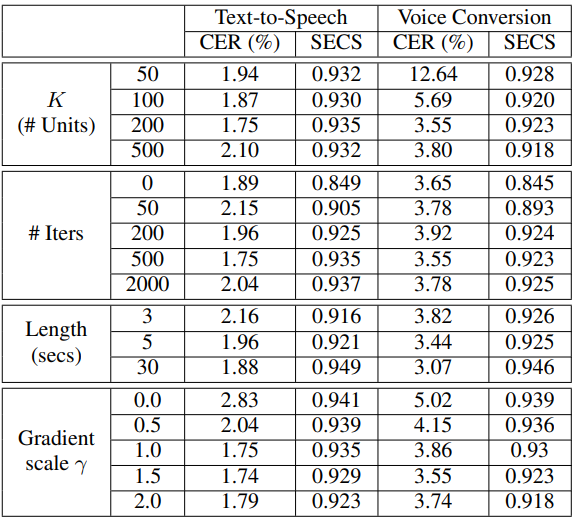
- 클러스터 $K$의 수는 TTS 결과에 큰 영향을 미치지 않는다. 그러나 unit을 직접 입력으로 사용하는 VC의 경우 $K$가 증가하면 발음이 보다 정밀하게 세분화되어 발음 정확도가 향상된다.
- 더 많이 fine-tuning할수록 speaker 유사성이 점차 증가하고 결국 약 500 iteration으로 수렴된다. 또한 2,000 iteration 이상 fine-tuning하면 발음 정확도가 감소한다.
- Fine-tuning에 사용된 레퍼런스 음성의 길이가 증가함에 따라 발음 정확도와 speaker 유사성이 모두 향상된다. 또한 5초 길이의 짧은 레퍼런스 음성으로도 충분한 발음 정확도와 speaker 유사성을 달성할 수 있다.
- 제안된 guidance 방법은 speaker 유사성이 약간 감소하는 대신 발음을 향상시킨다. Spekaer 유사성 감소를 최소화하면서 발음 향상을 최대화하는 gradient sclae $\gamma$는 TTS의 경우 1, VC의 경우 1.5이다.