[논문리뷰] Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models
NeurIPS 2023. [Paper] [Page] [Github]
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, Kwan-Yee K. Wong
University of Hong Kong | Microsoft
25 May 2023

Introduction
최근 2년 동안 diffusion model은 이미지 합성 task에서 뛰어난 성능으로 인해 상당한 주목을 받았다. 따라서 T2I (text-to-image) diffusion model은 텍스트 입력을 기반으로 고품질 이미지를 합성하기 위한 대중적인 선택으로 부상했다. 이러한 T2I diffusion model은 대형 모델이 포함된 대규모 데이터셋에 대한 학습을 통해 텍스트 설명에 설명된 콘텐츠와 매우 유사한 이미지를 생성하는 탁월한 능력을 보여주고 텍스트와 시각적 도메인 간의 연결을 용이하게 한다. 복잡한 텍스처 디테일과 객체 간의 복잡한 관계를 캡처할 때 생성 품질이 크게 향상되어 다양한 실제 애플리케이션에 매우 적합하다.
그러나 텍스트 설명은 이러한 모델에 대한 복잡한 텍스트 설명을 이해하는 데 어려움은 말할 것도 없고 예를 들어 여러 객체의 세분화된 semantic 레이아웃을 제어하는 것과 같이 최종 생성 결과에 대한 세부 제어를 정확하게 전달하기에는 비효율적이거나 불충분하다. 결과적으로 이러한 T2I diffusion model에 텍스트 설명과 함께 더 많은 추가 제어 모드 (ex. 사용자가 그린 스케치, semantic 마스크)를 통합해야 할 필요성이 커지고 있다. 이러한 필요성은 단일 함수에서 포괄적인 시스템으로 T2I 생성 범위를 확장함에 따라 상당한 관심을 불러일으켰다.
최근에는 제어 가능한 T2I diffusion model을 연구하려는 시도가 있었다. 대표적으로 Composer는 텍스트 설명과 함께 여러 제어 신호의 통합을 탐색하고 수십억 규모의 데이터셋에서 모델을 처음부터 학습하였다. 결과는 유망하지만 막대한 GPU 리소스가 필요하고 막대한 학습 비용이 발생하여 이 분야의 많은 연구자들이 감당할 수 없는 비용이 든다. 공개적으로 사용할 수 있는 강력한 사전 학습된 T2I diffusion model (ex. Stable Diffusion)이 있다는 점을 고려하여 ControlNet과 T2I-Adapter는 가벼운 어댑터를 고정된 T2I diffusion model에 직접 통합하여 추가 조건 신호를 활성화한다. 이 방법은 fine-tuning을 더 저렴하게 만든다. 그러나 한 가지 단점은 각 단일 조건에 대해 하나의 독립적인 어댑터가 필요하므로 많은 조건이 유사한 특성을 공유하더라도 제어 조건의 수가 증가함에 따라 fine-tuning 비용과 모델 크기가 선형적으로 증가한다는 것이다. 또한 이로 인해 서로 다른 조건 간의 결합 가능성이 만만치 않은 과제로 남아 있다.

본 논문에서는 사전 학습된 T2I diffusion model을 정밀하게 제어할 수 있도록 경량 어댑터를 활용하는 새로운 프레임워크인 Uni-ControlNet을 제안한다. 위 표에서 볼 수 있듯이 Uni-ControlNet은 이전 방법과 달리 다양한 조건을 로컬 조건과 글로벌 조건의 두 가지 그룹으로 분류한다. 따라서 관련된 로컬 제어와 전역 제어의 수에 관계없이 두 개의 추가 어댑터만 추가한다. 이 디자인 선택은 전체 fine-tuning 비용과 모델 크기를 모두 크게 줄여 배포에 매우 효율적일 뿐만 아니라 다양한 조건의 결합 가능성을 용이하게 한다. 이를 달성하기 위해 로컬 및 글로벌 제어용 어댑터를 전용으로 설계했다. 특히 로컬 제어의 경우 공유 로컬 조건 인코더 어댑터를 사용하는 멀티스케일 조건 주입 전략을 도입한다. 이 어댑터는 먼저 로컬 제어 신호를 변조 신호로 변환한 다음 들어오는 noise feature를 변조하는 데 사용된다. 그리고 글로벌 제어를 위해 다른 공유 글로벌 조건 인코더를 사용하여 조건부 토큰으로 변환한다. 이 토큰은 텍스트 토큰과 concat되어 확장된 프롬프트를 형성하고 cross-attention 메커니즘을 통해 들어오는 feature와 상호 작용한다. 흥미롭게도 저자들은 이 두 어댑터가 추가 공동 학습 없이 개별적으로 학습될 수 있는 동시에 여러 제어 신호의 결합을 계속 지원한다는 사실을 발견했다. 이 발견은 Uni-ControlNet이 제공하는 유연성과 사용 편의성을 추가한다.
Uni-ControlNet은 1 epoch으로 천만 개의 텍스트-이미지 쌍에 대해서만 학습함으로써 충실도와 제어 가능성 측면에서 매우 유망한 결과를 보여준다. 추가 통찰력을 얻기 위해 저자들은 ablation study를 수행하고 새로 제안된 어댑터 디자인을 ControlNet과 T2I-Adapter의 디자인과 비교하였다.
Method
1. Preliminary
일반적인 diffusion model에는 $T$ step에서 샘플에 소량의 Gaussian noise를 점진적으로 추가하는 forward process와 noise를 추정 및 제거하여 입력 이미지를 복구하기 위한 reverse process의 두 가지 프로세스가 포함된다. 본 논문에서는 SD를 예제 기본 모델로 사용하여 Uni-ControlNet으로 다양한 제어를 활성화하는 방법을 설명한다. SD는 인코더, 중간 블록, 디코더로 구성된 denoising model로 UNet과 같은 구조를 통합하며 각 인코더 및 디코더 모듈에는 12개의 해당 블록이 있다. 간결함을 위해 인코더를 $F$, 중간 블록을 $M$, 디코더를 $G$로 표시하고 $f_i$와 $g_i$는 각각 인코더와 디코더에서 $i$번째 블록의 출력을 나타내고 $m$은 중간 블록의 출력을 나타낸다. UNet의 skip connection 채택으로 인해 디코더의 $i$번째 블록에 대한 입력은 다음과 같다는 점에 유의해야 한다.
\[\begin{equation} \begin{cases} \textrm{concat} (m, f_j) & \quad \textrm{where} \; i = 1, \; i + j = 13 \\ \textrm{concat} (g_{i-1}, f_j) & \quad \textrm{where} \; 2 \le i \le 12, \; i + j = 13 \\ \end{cases} \end{equation}\]Skip connection을 통해 디코더는 인코더의 feature를 직접 활용하여 정보 손실을 최소화할 수 있다. SD에서는 입력 텍스트 설명에서 semantic 정보를 캡처하기 위해 cross-attention layer가 사용된다. 여기에서 $Z$를 사용하여 들어오는 noise feature를 나타내고 $y$를 사용하여 언어 인코더로 인코딩된 텍스트 토큰 임베딩을 나타낸다. Cross-attention의 $Q$, $K$, $V$는 다음과 같이 표현될 수 있다.
\[\begin{equation} Q = W_q (Z), \quad K = W_k (y), \quad V = W_v (y) \end{equation}\]여기서 $W_q$, $W_k$, $W_v$는 projection matrix이다.
2. Control Adapter
본 논문에서는 다음과 같은 7가지 예제 로컬 조건을 고려한다.
- Canny edge
- MLSD edge
- HED boundary
- sketch
- Openpose
- Midas depth
- segmentation mask
또한 하나의 예시 글로벌 조건, 즉 CLIP 이미지 인코더에서 추출된 하나의 레퍼런스 콘텐츠 이미지의 글로벌 이미지 임베딩을 고려한다. 이 글로벌 조건은 단순한 이미지 feature를 넘어 조건 이미지의 semantic 내용에 대한 보다 미묘한 이해를 제공한다. 로컬 조건과 글로벌 조건을 모두 사용하여 생성 프로세스에 대한 포괄적인 제어를 제공하는 것을 목표로 한다. 아래 그림은 파이프라인의 개요이다.
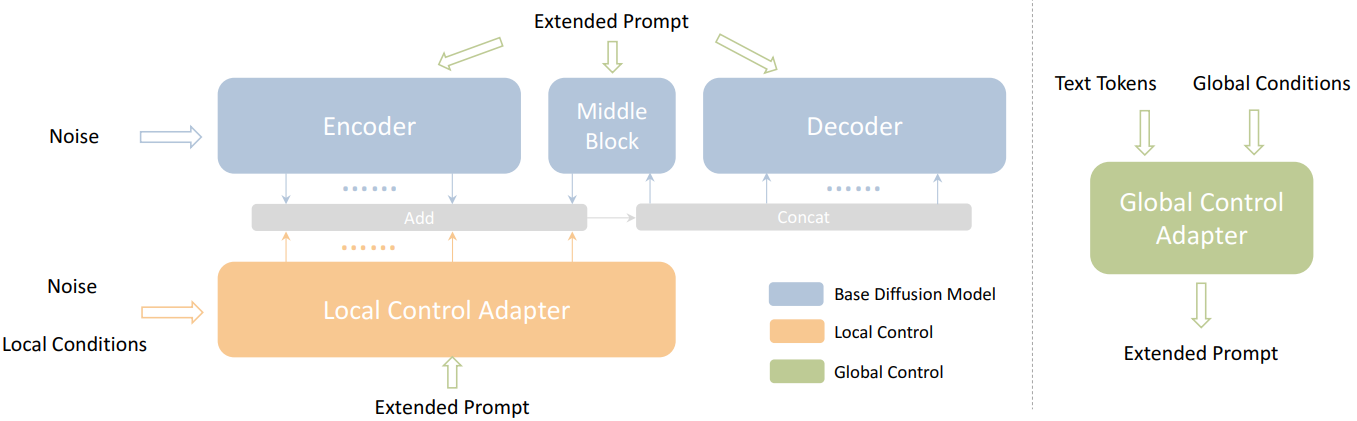
아래 그림은 로컬 제어 어댑터와 전역 제어 어댑터의 디테일이다.
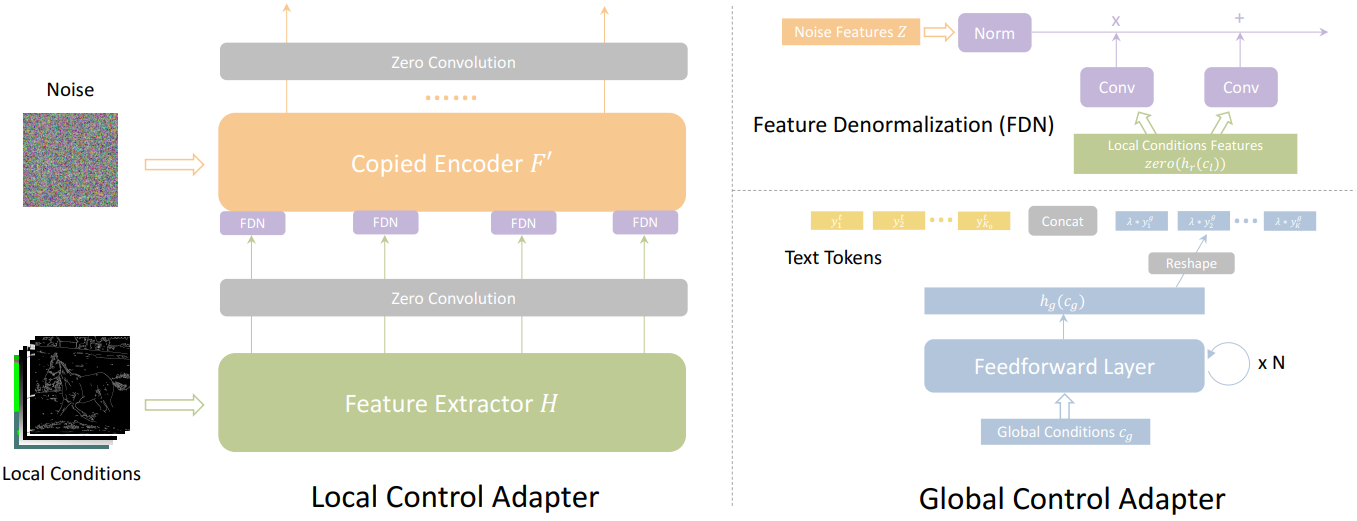
Local Control Adapter
로컬 제어 어댑터의 경우 ControlNet에서 영감을 얻었다. 구체적으로, SD의 가중치를 고정하고 각각 $F’$과 $M’$으로 지정된 인코더 및 중간 블록의 구조와 가중치를 복사한다. 그런 다음 디코딩 프로세스 중에 로컬 제어 어댑터의 정보를 통합한다. 이를 위해 디코더의 $i$번째 블록의 입력을 다음과 같이 수정하면서 다른 모든 요소가 변경되지 않도록 한다.
\[\begin{equation} \begin{cases} \textrm{concat} (m + m', f_j + \textrm{zero} (f_j')) & \quad \textrm{where} \; i = 1, \; i + j = 13 \\ \textrm{concat} (g_{i-1}, f_j + \textrm{zero} (f_j')) & \quad \textrm{where} \; 2 \le i \le 12, \; i + j = 13 \\ \end{cases} \end{equation}\]여기서 $\textrm{zero}$는 제어 정보를 기본 SD 모델에 점진적으로 통합하기 위해 가중치가 0에서 증가하는 하나의 zero convolutional layer를 나타낸다. 조건을 입력 noise에 직접 추가하고 복사된 인코더로 보내는 ControlNet과 달리 멀티스케일 조건 주입 전략을 선택한다. 본 논문의 접근 방식은 모든 해상도에서 조건 정보를 주입하는 것이다.
먼저 채널 차원을 따라 서로 다른 로컬 조건을 concat한 다음 feature 추출기 $H$ (stacked convolutional layer)를 사용하여 다른 해상도에서 조건 feature를 추출한다. 그런 다음 조건 주입을 위해 복사된 인코더에서 각 해상도의 첫 번째 블록을 선택한다. 주입 모듈의 경우 SPADE에서 영감을 얻어 조건 feature를 사용하여 정규화된 입력 noise feature를 변조하는 Feature Denormalization (FDN)를 구현한다.
\[\begin{equation} \textrm{FDN}_r (Z_r, c_l) = \textrm{norm} (Z_r) \cdot (1 + \textrm{conv}_\gamma (\textrm{zero} (h_r (c_l)))) + \textrm{conv}_\beta (\textrm{zero} (h_r (c_l))) \end{equation}\]여기서 $Z_r$은 해상도 $r$의 noise feature를 나타내고, $c_l$은 concat된 로컬 조건이고, $h_r$은 해상도 $r$에서 feature 추출기 $H$의 출력을 나타내며, \(\textrm{conv}_\gamma\) 및 \(\textrm{conv}_\beta\)는 조건 feature를 공간에 민감한 scale 변조 계수와및 shift 변조 계수로 변환하는 학습 가능한 convolution layer를 나타낸다.
Global Control Adapter
글로벌 제어를 위해 CLIP 이미지 인코더에서 추출한 하나의 조건 이미지의 이미지 임베딩을 예로 사용한다. T2I diffusion model의 텍스트 설명이 명시적인 공간적 guidance 없이도 일종의 글로벌 제어로 볼 수 있다는 사실에 영감을 받아 조건 인코더 $h_g$를 사용하여 글로벌 제어 신호를 조건 임베딩에 project한다. 조건 인코더는 누적된 feedforward layer로 구성되어 글로벌 제어 신호를 SD의 텍스트 임베딩과 정렬한다. 다음으로, project된 조건 임베딩을 $K$개의 글로벌 토큰 (기본적으로 $K = 4$)으로 재구성하고 $K_0$개의 원본 텍스트 토큰과 concat하여 확장된 프롬프트 $y_\textrm{ext}$를 생성한다 (총 토큰 수는 $K + K_0$). 이는 기본 SD 모델과 제어 어댑터 모두에서 모든 cross-attention layer에 대한 입력 역할을 한다.
\[\begin{equation} y_\textrm{ext} = [y_1^t, y_2^t, \ldots, y_{K_0}^t, \lambda y_1^g, \lambda y_2^g, \ldots, \lambda y_K^g] \\ \textrm{where} \quad y_i^g = h_g (c_g) [(i - 1) \cdot d \sim i \cdot d], \quad i \in [1, K] \end{equation}\]여기서 $y^t$와 $y^g$는 각각 원본 텍스트 토큰과 글로벌 조건 토큰을 나타내고 $\lambda$는 글로벌 조건의 가중치를 제어하는 hyperparameter이다. $c_g$는 글로벌 조건을 나타내고 $d$는 텍스트 토큰 임베딩의 차원이다. $h_g(\cdot) [i_s \sim i_e]$는 $i_s$번째 위치부터 $i_e$번째 위치까지의 요소를 포함하는 $h_g (\cdot)$의 하위 텐서를 나타낸다. 마지막으로 모든 cross-attention layer에서 $Q$, $K$, $V$ cross-attention 연산이 다음과 같이 변경된다.
\[\begin{equation} Q = W_q (Z), \quad K = W_k (y_\textrm{ext}), \quad V = W_v (y_\textrm{ext}) \end{equation}\]3. Training Strategy
로컬 제어 신호와 글로벌 제어 신호는 종종 서로 다른 양의 조건 정보를 포함하므로 경험적으로 이 두 가지 유형의 어댑터를 직접 공동으로 fine-tuning하면 제어 가능한 생성 성능이 저하된다. 따라서 이 두 가지 유형의 어댑터를 개별적으로 fine-tuning하여 둘 다 충분히 학습되고 최종 생성 결과에 효과적으로 기여할 수 있도록 한다. 각 어댑터를 fine-tuning할 때 사전 정의된 확률을 사용하여 각 조건을 임의로 삭제하고 모든 조건을 의도적으로 유지하거나 삭제할 추가 확률을 사용한다. 이렇게 하면 모델이 하나 또는 여러 조건을 기반으로 동시에 결과를 생성하는 학습을 용이하게 할 수 있다. 흥미롭게도, inference 중에 별도로 학습된 이 두 어댑터를 직접 통합함으로써 Uni-ControlNet은 추가적인 공동 fine-tuning 없이 이미 글로벌 조건과 로컬 조건을 잘 결합할 수 있다.
Experiments
- 데이터셋: LAION (1000만 개의 이미지-텍스트 쌍)
- 구현 디테일
- epoch: 1
- optimizer: AdamW
- learning rate: $1 \times 10^{-5}$
- 입력 이미지와 조건 맵을 512$\times$512로 resize
- inference 시 DDIM으로 샘플링 (timestep 수 = 50, classifier-free guidance scale = 7.5)
- $\lambda$: 텍스트 프롬프트가 없으면 1, 있으면 0.75
1. Controllable Generation Results
다음은 Uni-ControlNet의 시각적 결과이다.

2. Comparison with Existing Methods
다음은 여러 제어 가능한 diffusion model을 FID로 비교한 표이다.

다음은 여러 단일 조건에서 기존의 제어 가능한 diffusion model들을 비교한 것이다.

다음은 여러 조건에서 제어 가능한 다양한 diffusion model들을 비교한 것이다.

3. Ablation Analysis
- Injection-S1: 조건을 삽입하기 위해 SPADE를 직접 사용 (보간을 사용하여 조건을 해당 해상도로 크기 조정하는 연산이 포함됨)
- Injection-S2: 조건은 입력 레이어의 어댑터 또는 기본 모델로만 전송됨
- Injection-S3: 글로벌 조건을 제어 어댑터에만 추가하고 기본 SD 모델에는 추가하지 않음
- Training-S1: 로컬 제어 어댑터와 글로벌 제어 어댑터를 공동으로 fine-tuning
- Training-S2: 각각 fine-tuning 후 추가로 공동으로 fine-tuning
다음은 조건 주입 방법과 학습 전략에 따른 FID를 비교한 표이다.
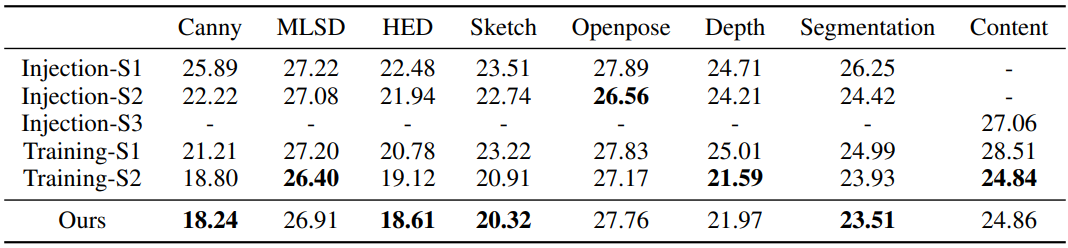
다음은 여러 조건 주입 방법에 대한 결과이다.

다음은 여러 학습 전략에 대한 결과이다.
