[논문리뷰] A Closer Look at Parameter-Efficient Tuning in Diffusion Models
arXiv 2023. [Paper] [Github]
Chendong Xiang, Fan Bao, Chongxuan Li, Hang Su, Jun Zhu
BNRist Center | Tsinghua-Bosch Joint ML Center, THBI Lab | Gaoling School of Artificial Intelligence | Beijing Key Lab of Big Data Management & Analysis Methods | Pazhou Lab
12 Apr 2023
Introduction
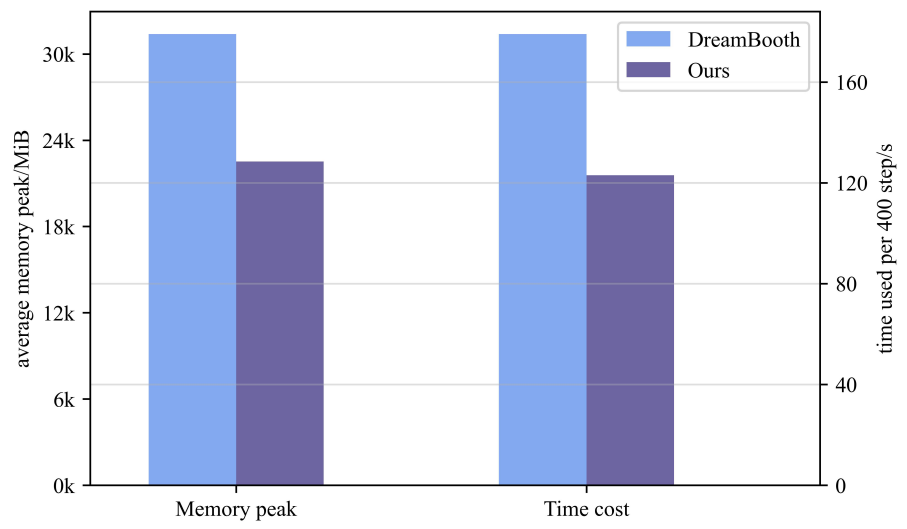
대규모 데이터에서 배운 지식을 통해 대규모 diffusion model은 하위 task에 대한 강력한 prior 역할을 한다. 그 중 DreamBooth는 대규모 diffusion model의 모든 파라미터를 튜닝하여 사용자가 원하는 특정 개체를 생성한다. 그러나 전체 모델을 fine-tuning하는 것은 계산, 메모리, 저장 비용 측면에서 비효율적이다.
대안은 자연어 처리(NLP) 영역에서 비롯된 parameter-efficient transfer learning 방법이다. 이 방법은 학습 가능한 작은 모듈(어댑터라고 함)을 모델에 삽입하고 원래 모델을 고정한다. 그럼에도 불구하고, parameter-efficient transfer learning은 diffusion model 분야에서 충분히 연구되지 않았다. NLP의 Transformer 기반 언어 모델과 달리 diffusion model에서 널리 사용되는 U-Net 아키텍처에는 업/다운샘플링 연산자가 있는 residual block, self-attention, cross-attention과 같은 더 많은 구성 요소가 포함된다. 이는 Transformer 기반 언어 모델보다 parameter-efficient transfer learning의 더 큰 디자인 공간으로 이어진다.
본 논문에서는 대규모 diffusion model에서 파라미터 효율적인 튜닝의 디자인 공간에 대한 첫 번째 체계적인 연구를 제시한다. Stable Diffusion은 현재 유일한 오픈 소스 대규모 diffusion model이기 때문에 구체적인 사례로 간주한다. 특히 어댑터의 디자인 공간을 input position, output position, function form과 같은 직교 요소로 분해한다. 이러한 요인에 대한 ANOVA(Analysis of Variance)라는 그룹 간의 차이를 분석하기 위한 강력한 도구를 수행하여 input position이 하위 task의 성능에 영향을 미치는 중요한 요소임을 확인했다. 그런 다음 input position의 선택을 신중하게 연구하고 cross-attention 블록 뒤에 input position을 배치하면 네트워크가 입력 프롬프트의 변화를 인식하도록 최대한 장려할 수 있으므로 최상의 성능으로 이어질 수 있음을 발견했다.
Design Space of Parameter-Efficient Learning in Diffusion Models
NLP에서 parameter-efficient transfer learning의 성공에도 불구하고 이 기술은 residual block과 cross-attention과 같은 더 많은 구성 요소의 존재로 인해 diffusion model 영역에서 완전히 이해되지 않았다. Diffusion model의 parameter-efficient tuning에 대한 분석 전에 어댑터의 디자인 공간을 input position, output position, function form의 세 가지 직교 요소로 분해한다.
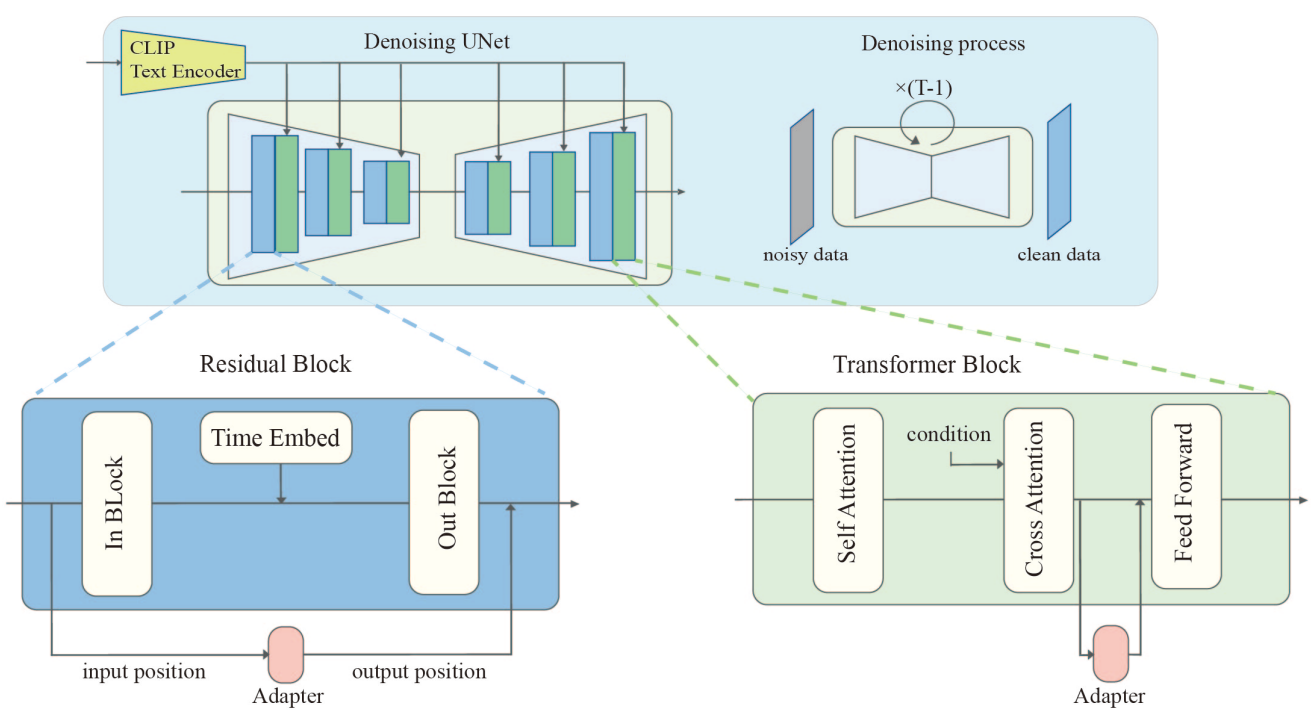
본 논문은 현재 유일한 오픈 소스 대규모 diffusion model인 Stable Diffusion을 고려한다 (U-Net 기반 아키텍처에 대한 위 그림 참조).
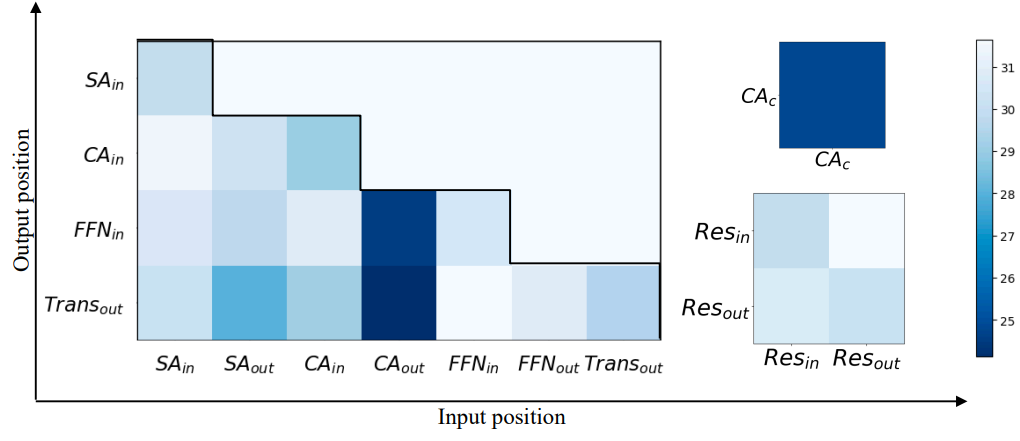
1. Input Position and Output Position
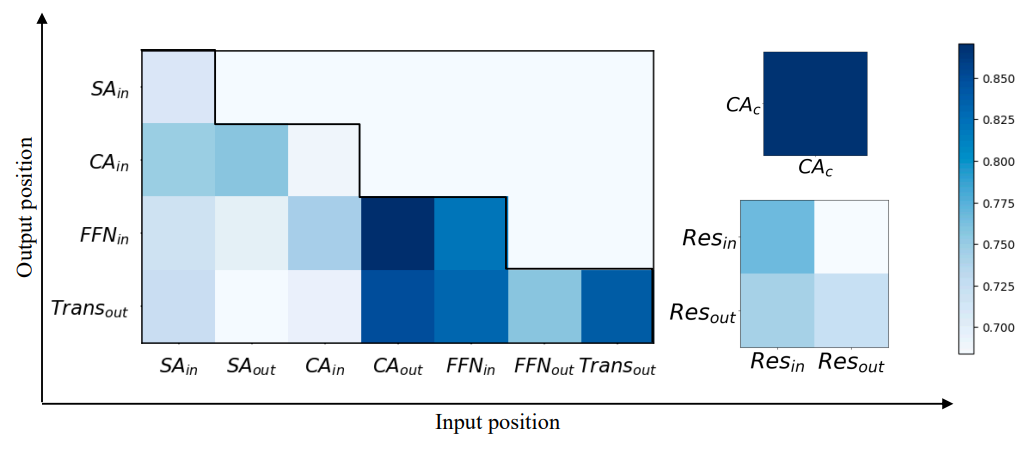
Input position은 어댑터의 입력이 들어오는 곳이고 output position은 어댑터의 출력이 나가는 곳이다. 깔끔한 표기를 위해 표시된 것처럼 position은 인접 레이어에 따라 이름이 지정된다. 예를 들어 \(\textrm{SA}_\textrm{in}\)은 self-attention layer의 input position에 해당하고, \(\textrm{Trans}_\textrm{out}\)은 Transformer 블록의 output position에 해당하며, \(\textrm{CA}_\textrm{c}\)는 cross attention layer의 조건 입력에 해당한다.
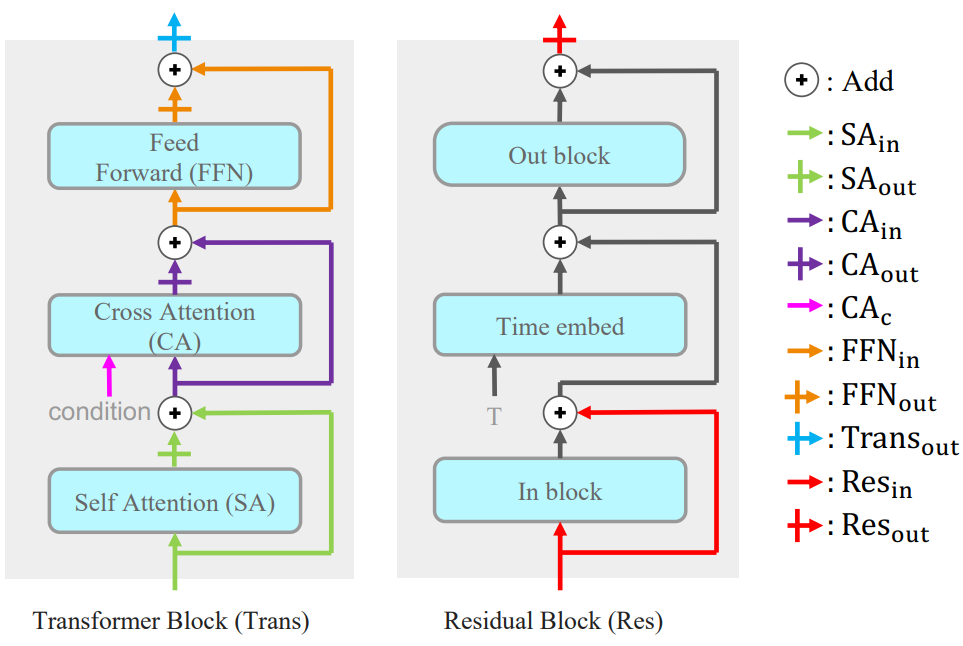
본 논문의 프레임워크에서 input position은 위 그림에 설명된 activation position 중 하나가 될 수 있다. 따라서 input position에 대한 총 10가지 옵션이 있다. 덧셈은 교환적이므로 일부 output position은 동일하다. 예를 들어 \(\textrm{SA}_\textrm{out}\)에 출력을 넣는 것은 \(\textrm{CA}_\textrm{in}\)에 출력을 넣는 것과 같다. 이에 따라 output position에 대한 옵션이 총 7개로 줄어든다. 또 다른 제약은 output position이 input position 뒤에 위치해야 한다는 것이다.
2. Function Form
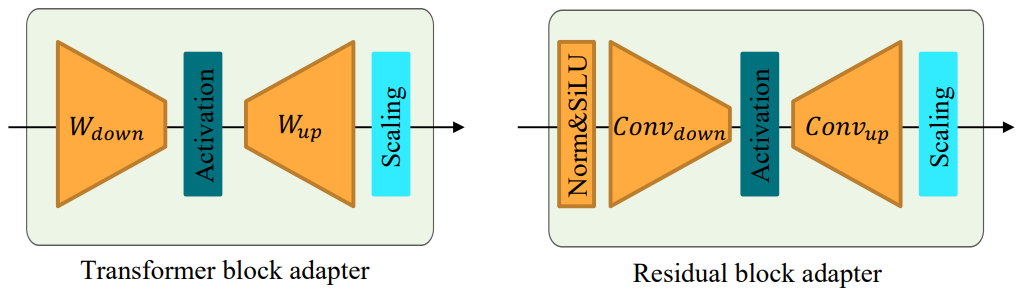
Function form은 어댑터가 입력을 출력으로 전송하는 방법을 설명한다. Transformer 블록과 residual block에 각각 어댑터의 function form을 제시하며 (위 그림 참조), 둘 다 다운샘플링 연산자, activation function, 업샘플링 연산자, scaling factor로 구성된다. 다운샘플링 연산자는 입력의 차원을 줄이고 업샘플링 연산자는 차원을 늘려 출력이 입력과 동일한 차원을 갖도록 한다. 원래 네트워크에 영향을 미치는 강도를 제어하기 위해 출력에 scaling factor $s$를 더 곱한다.
구체적으로 Transformer 블록 어댑터는 각각 다운샘플링 연산자와 업샘플링 연산자로 low-rank matrix $W_\textrm{down}$과 $W_\textrm{up}$을 사용하고 residual block 어댑터는 다운샘플링 연산자와 업샘플링 연산자로 각각 3$\times$3 convolution layer \(\textrm{Conv}_\textrm{down}\)과 \(\textrm{Conv}_\textrm{up}\)을 사용한다. 이러한 convolution layer는 공간 크기를 변경하지 않고 채널 수만 변경한다. 또한 residual block 어댑터는 group normalization 연산자로 입력을 처리한다.
디자인 선택에 다양한 activation function과 scaling factor를 포함한다. Activation function에는 ReLU, Sigmoid, SiLU, ID 연산자가 포함되며 scaling factor에는 0.5, 1.0, 2.0, 4.0이 포함된다.
Discover the Key Factor with Analysis of Variance
앞서 언급한 바와 같이 이렇게 큰 이산 검색 공간에서 최적의 해를 찾는 것은 어려운 일이다. 디자인 공간에서 어떤 요소가 성능에 가장 큰 영향을 미치는지 알아보기 위해 여러 분야에서 널리 사용되는 analysis of variance (ANOVA) 방법을 활용하여 모델 성능과 요소 간의 상관 관계를 정량화한다.
ANOVA의 기본 아이디어는 데이터의 전체 변동을 그룹 내 변동(MSE)과 그룹 간 변동(MSB)의 두 가지 구성 요소로 분할하는 것이다. MSB는 그룹 평균 간의 차이를 측정하는 반면 그룹 내 변동은 개별 관측값과 해당 그룹 평균 간의 차이를 측정한다. ANOVA에 사용되는 통계 테스트는 그룹 간 변동과 그룹 내 변동의 비율(F-통계량)을 비교하는 F-분포를 기반으로 한다. F-통계량이 충분히 크면 그룹 평균 간에 유의미한 차이가 있음을 의미하며 이는 강한 상관관계를 나타낸다.
Experiments
- Task: DreamBooth task, fine-tuning task
- Tuning
- Optimizer: AdamW
- DreamBooth task
- Learning rate: $10^{-4}$
- 어댑터 크기: 1.5M (UNet 모델의 0.17%)
- 2,500 step
- Fine-tuning task
- Learning rate: $10^{-5}$
- 어댑터 크기: 6.4M (UNet 모델의 0.72%)
- 60,000 step
- Sampling
- DPM-Solver (25 sampling step)
- Classifier free guidance scale: 7.0
1. Analysis of Variance (ANOVA) on the Design Space
다음은 ANOVA의 F-통계량이다.
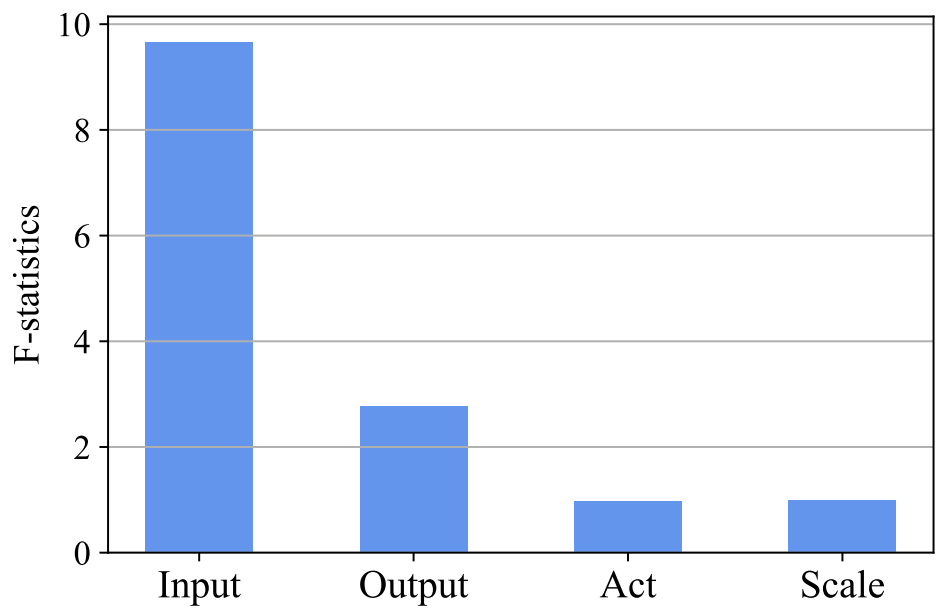
Input position에 대한 F-통계량이 가장 크며, 이는 input position이 모델의 성능에 중요한 요소임을 의미한다.
다음은 DreamBooth task에서 다양한 input position과 output position에 대한 성능을 시각화한 것이다.
다음은 fine-tuning task에서 다양한 input position과 output position에 대한 성능을 시각화한 것이다.
2. Ablate the Input Position
다음은 어댑터의 다양한 input position에 대하여 생성된 샘플들이다. 모든 샘플들은 “a photo of [$V$] $C_\textrm{class}$”로 컨디셔닝되었다.

저자들은 “a photo of [$V$] $C_\textrm{class}$”와 “a photo of $C_\textrm{class}$”라는 프롬프트가 주어질 때 noise 예측 간의 차이를 계산하였다. 파이프라인은 아래 그림과 같다.
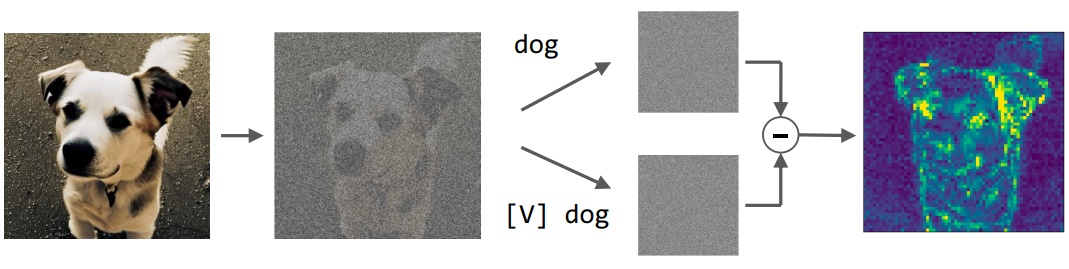
먼저 정규화 데이터에서 이미지에 noise를 추가하고 U-Net을 사용하여 두 프롬프트가 주어진 noise를 예측하고 예측된 두 noise 사이의 차이를 시각화한다.
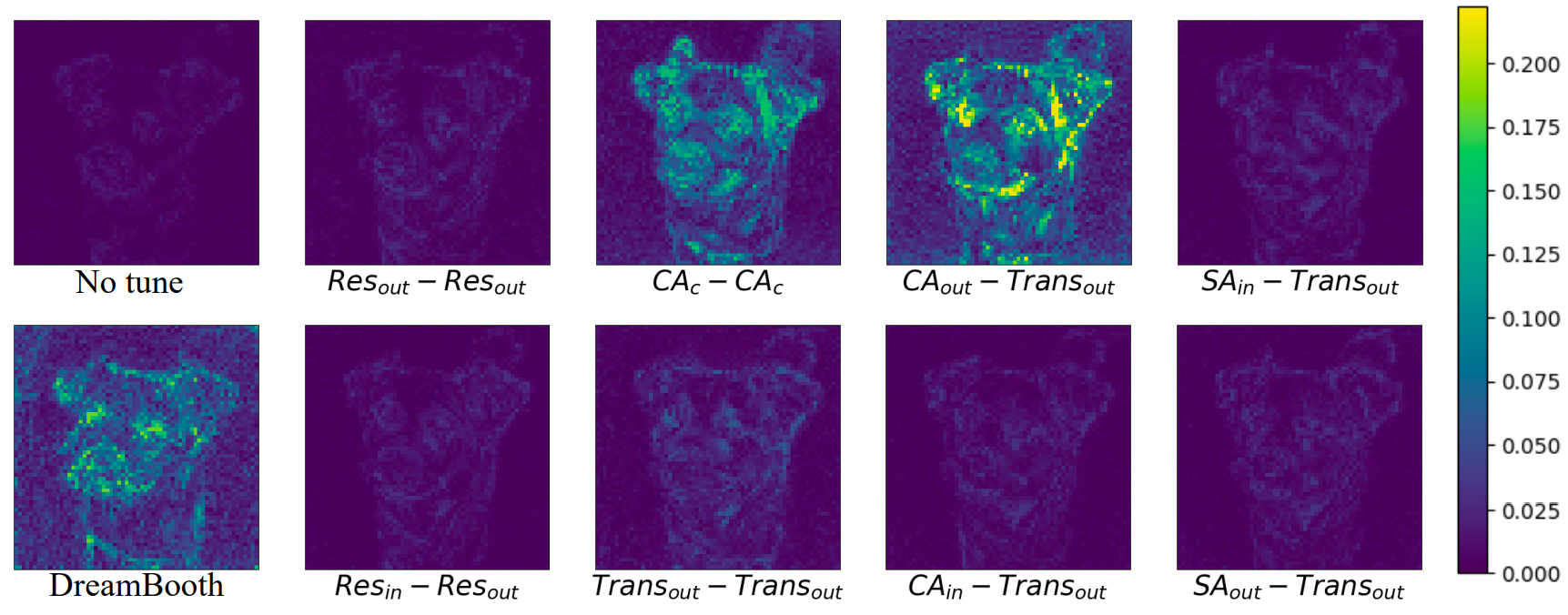
위 그림에서 볼 수 있듯이 input position이 \(\textrm{CA}_\textrm{c}\) 또는 \(\textrm{CA}_\textrm{out}\)인 어댑터는 noise 예측 간에 상당한 차이를 나타낸다.
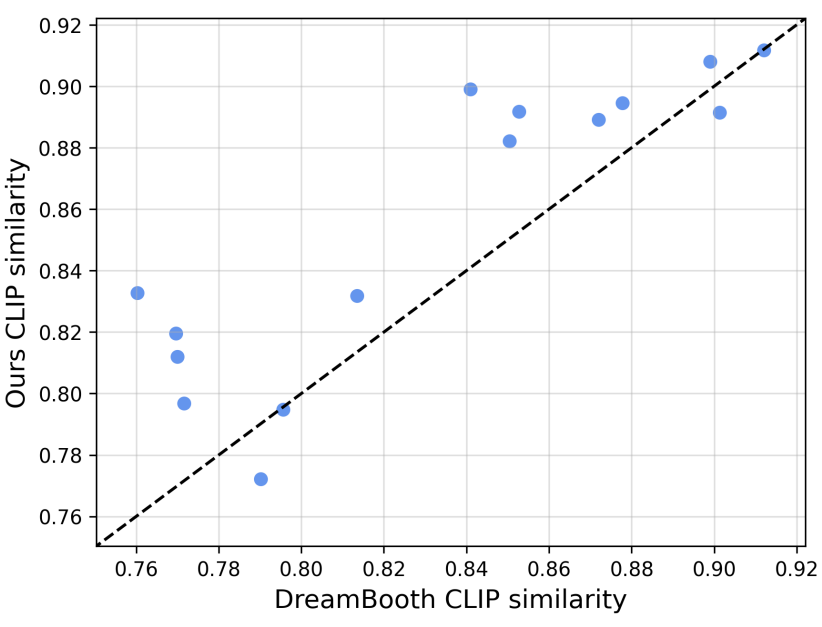
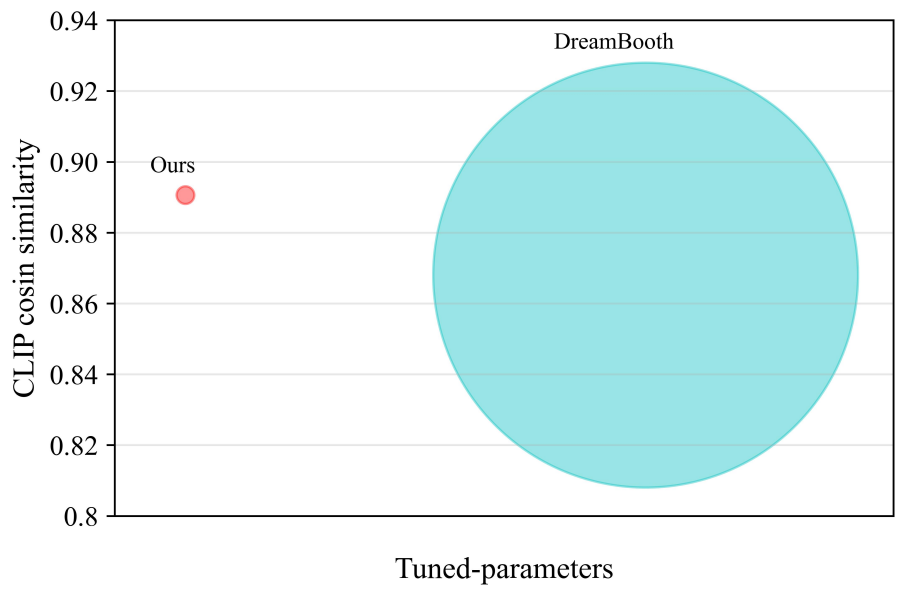
3. Compare with DreamBooth
다음은 본 논문의 최고의 세팅(input position이 \(\textrm{CA}_\textrm{out}\), output position이 \(\textrm{FFN}_\textrm{in}\))과 DreamBooth를 CLIP similarity로 비교한 결과들이다.