[논문리뷰] All are Worth Words: A ViT Backbone for Diffusion Models (U-ViT)
CVPR 2023. [Paper] [Github]
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, Jun Zhu
Tsinghua University | Renmin University of China | Beijing Key Laboratory of Big Data Management and Analysis Methods | Beijing Academy of AI
25 Sep 2022
Introduction
알고리즘의 발전과 함께 backbone의 혁명은 diffusion model에서 중심적인 역할을 한다. 대표적인 예가 CNN 기반의 U-Net이다. CNN 기반의 UNet은 이미지 생성 task를 위한 diffusion model을 지배하며, 다운샘플링 블록들의 그룹, 업샘플링 블록들의 그룹, 두 그룹 간의 긴 skip connection이 특징이다. 한편, ViT는 다양한 비전 task에서 가능성을 보여주었으며 ViT는 CNN 기반 접근 방식과 비슷하거나 심지어 우수하다. 따라서 diffusion model에서 CNN 기반 U-Net의 의존성이 필요한지 여부에 대한 자연스러운 질문을 할 수 있다.
본 논문에서는 U-ViT라는 단순하고 일반적인 ViT 기반 아키텍처를 설계한다. Transformer의 설계 방법론에 따라 U-ViT는 시간, 조건, noisy한 이미지 패치를 포함한 모든 입력을 토큰으로 처리한다. 결정적으로 U-ViT는 U-Net에서 영감을 받은 얕은 레이어와 깊은 레이어 사이에 긴 skip connection을 사용한다. 직관적으로 낮은 레벨의 feature는 diffusion model의 픽셀 레벨 예측에 중요하며 이러한 연결은 해당 예측 네트워크의 학습을 쉽게 할 수 있다. 또한 U-ViT는 더 나은 시각적 품질을 위해 출력 전에 3$\times$3 convolution block을 선택적으로 추가한다.
Method
U-ViT는 이미지 생성에서 diffusion model을 위한 간단하고 일반적인 backbone이다. 특히, U-ViT는 noise 예측 네트워크 $\epsilon_\theta (x_t, t, c)$를 parameterize한다. 시간 $t$, 조건 $c$, noise가 주입된 이미지 $x_t$를 입력으로 사용하고 $x_t$에 주입된 noise를 예측한다. ViT의 설계 방법론에 따라 이미지를 패치로 분할하고 U-ViT는 시간, 조건, 이미지 패치를 포함한 모든 입력을 토큰 (단어)으로 처리한다.
Diffusion model에서 CNN 기반 U-Net의 성공에 영감을 받은 U-ViT는 또한 얕은 레이어와 깊은 레이어 간에 유사한 긴 skip connection을 사용한다. 직관적으로 목적 함수
\[\begin{equation} \min_\theta \mathbb{E}_{t, x_0, c, \epsilon} [\| \epsilon - \epsilon_\theta (x_t, t, c) \|_2^2] \end{equation}\]는 픽셀 레벨의 예측 task이며 낮은 레벨의 feature에 민감하다. 긴 skip connection은 낮은 레벨의 feature에 대한 shortcut을 제공하므로 noise 예측 네트워크의 학습을 용이하게 한다.
또한 U-ViT는 선택적으로 출력 전에 3$\times$3 convolution block을 추가한다. 이것은 transformer에 의해 생성된 이미지의 잠재적 아티팩트를 방지하기 위한 것이다. 이 블록은 U-ViT에서 생성된 샘플의 시각적 품질을 향상시킨다.
1. Implementation Details
U-ViT는 개념적으로 단순하지만 구현을 신중하게 설계한다. 이를 위해 저자들은 U-ViT의 핵심 요소에 대한 체계적인 실증 연구를 수행하였다. 특히, 저자들은 CIFAR10에서 ablation study를 수행하고, 1만 개의 생성 샘플에 대해 5만 학습 iteration마다 FID 점수를 평가하고 기본 구현 디테일을 결정하였다.
긴 skip connection 분기를 결합하는 방법
$h_m, h_s \in \mathbb{R}^{L \times D}$를 각각 메인 분기와 긴 skip 분기로부터의 임베딩이라고 하자. 저자들은 $h_m$와 $h_s$를 다음 transformer 블록에 공급하기 전에 그것들을 결합하는 몇 가지 방법을 고려하였다.
- $\textrm{Linear} (\textrm{Concat} (h_m, h_s))$
- $h_m + h_s$
- $h_m + \textrm{Linear} (h_s)$
- $\textrm{Linear} (h_m + h_s)$
- 긴 skip connection이 끊어진 경우
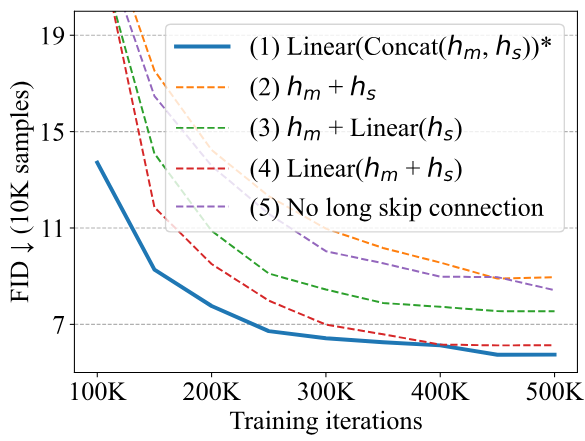
결과는 위 그래프와 같다. Transformer 블록은 내부에 더하기 연산자를 통해 skip connection이 있기 때문에 $h_m$은 이미 $h_s$의 정보를 선형 형식으로 포함하고 있다. 결과적으로 $h_m + h_s$의 유일한 효과는 $h_s$의 계수를 선형 형태로 증가시키는 것뿐이며 이는 네트워크의 특성을 변경하지 않는다. 대조적으로, $h_s$를 결합하는 다른 모든 방법은 $h_s$에서 linear projection을 수행하고 긴 skip connection이 없는 것과 비교하여 성능을 향상시킨다. 그 중에서 concatenation을 사용하는 첫 번째 방법이 가장 잘 수행된다.
네트워크에 시간을 공급하는 방법
저자들은 네트워크에 $t$를 공급하는 두 가지 방법을 고려하였다.
- 토큰으로 취급
- Adaptive Layer Normalization (AdaLN): Transformer 블록에서 layer normalization 이후에 시간을 통합
여기서 $h$는 transformer 블록 내부의 임베딩이고 $y_s$와 $y_b$는 시간 임베딩의 linear projection에서 얻는다.
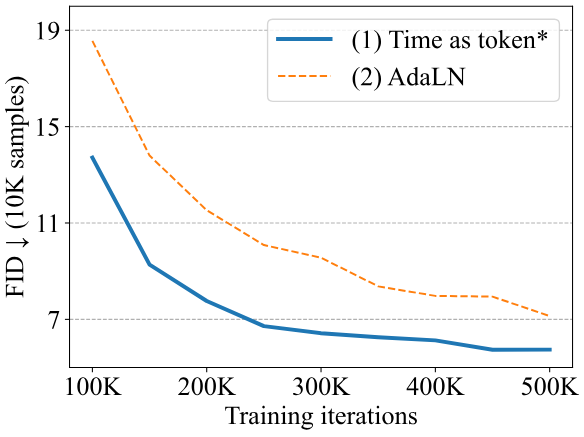
위 그래프에서 볼 수 있듯이 간단하지만 시간을 토큰으로 취급하는 첫 번째 방법이 AdaLN보다 성능이 좋다.
Transformer 뒤에 convolution block을 추가하는 방법
저자들은 transformer 뒤에 convolution block을 추가하는 세 가지 방법을 고려하였다.
- 토큰 임베딩을 이미지 패치에 매핑하는 linear projection 후에 3$\times$3 convolution block을 추가
- linear projection 이전에 3$\times$3 convolution block을 추가
- 추가 convolution block을 추가하지 않는 경우
이 linear projection은 먼저 토큰 임베딩 $h \in \mathbb{R}^{L \times D}$의 1D 시퀀스를 $H/P \times W/P \times D$ 모양의 2D feature로 재정렬해야 한다. 여기서 $P$는 패치 크기이다.
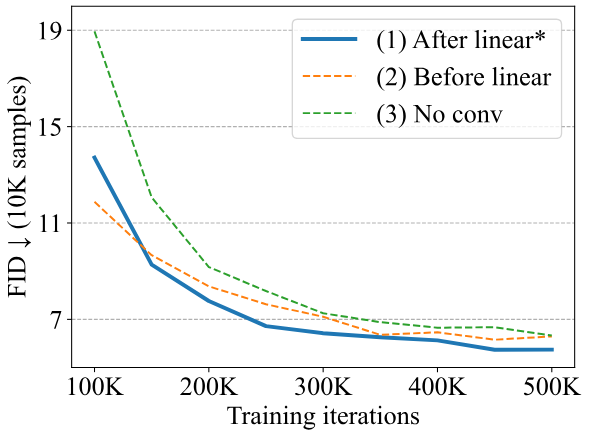
위 그래프에서 볼 수 있듯이 linear projection 후에 3$\times$3 convolution block을 추가하는 첫 번째 방법이 다른 두 가지 선택보다 약간 더 나은 성능을 보인다.
패치 임베딩
저자들은 패치 임베딩의 두 가지 변형을 고려하였다.
- 패치를 토큰 임베딩에 매핑하는 linear projection을 채택
- 3$\times$3 convolution block 스택과 1$\times$1 convolution block을 사용하여 이미지를 토큰 임베딩을 매핑
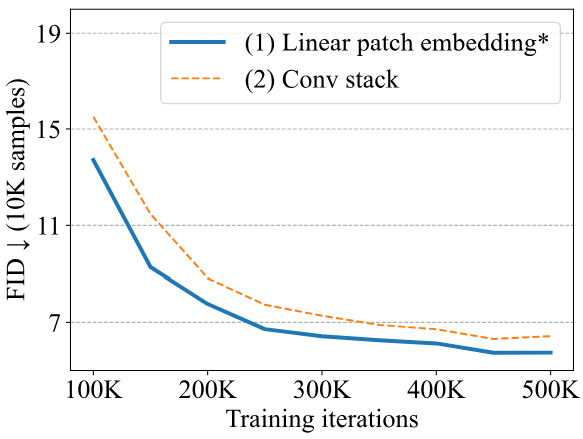
위 그래프에서 이를 비교하면 첫 번째 방법이 더 잘 수행된다.
위치 임베딩
저자들은 위치 임베딩의 두 가지 변형을 고려하였다.
- 원본 ViT에서 제안한 1차원 학습 가능한 위치 임베딩
- 위치 $(i, j)$의 패치에 대해 $i$와 $j$의 sinusoidal embedding을 concat하여 얻은 2차원 sinusoidal position embedding
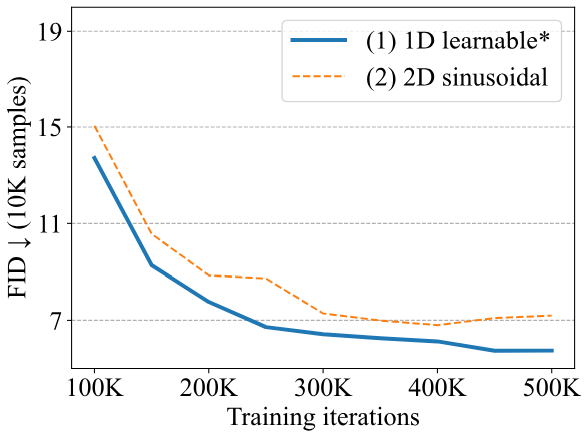
위 그래프에서 볼 수 있듯이 1차원 학습 가능 위치 임베딩이 더 잘 수행된다.
2. Effect of Depth, Width and Patch Size
저자들은 CIFAR10에서 깊이 (즉, 레이어 수), 너비 (즉, hidden size $D$), 패치 크기의 영향을 연구하여 U-ViT의 스케일링 속성을 제시하였다.
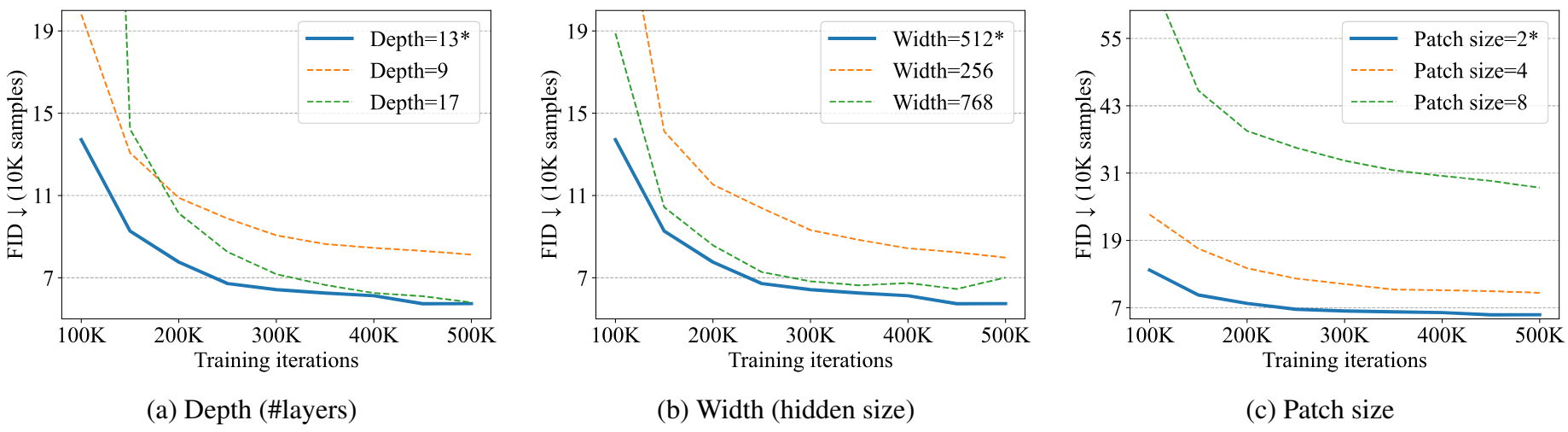
위 그림에서 볼 수 있듯이 깊이, 즉 레이어 수가 9에서 13으로 증가함에 따라 성능이 향상된다. 그럼에도 불구하고 U-ViT는 17과 같은 더 큰 깊이에서 이득을 얻지 못한다. 마찬가지로 너비, 즉 hidden size를 256에서 512로 늘리면 성능이 향상되고 768로 더 늘리면 이득이 없다. 패치 크기를 8에서 2로 줄이면 성능이 향상되고 추가로 1로 줄이면 이득이 없다. 좋은 성능을 위해서는 2와 같은 작은 패치 크기가 필요하다. 작은 패치 크기를 사용하는 것은 고해상도 이미지에 비용이 많이 들기 때문에 먼저 이미지를 저차원 latent 표현으로 변환하고 U-ViT를 사용하여 이러한 latent 표현을 모델링한다.
Experiments
- 데이터셋
- CIFAR10
- CelebA 64$\times$64
- ImageNet 64$\times$64, 128$\times$128, 256$\times$256, 512$\times$512
- MS-COCO 256$\times$256
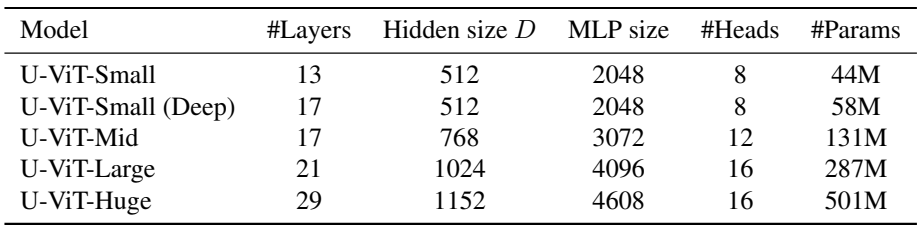
U-ViT configuration
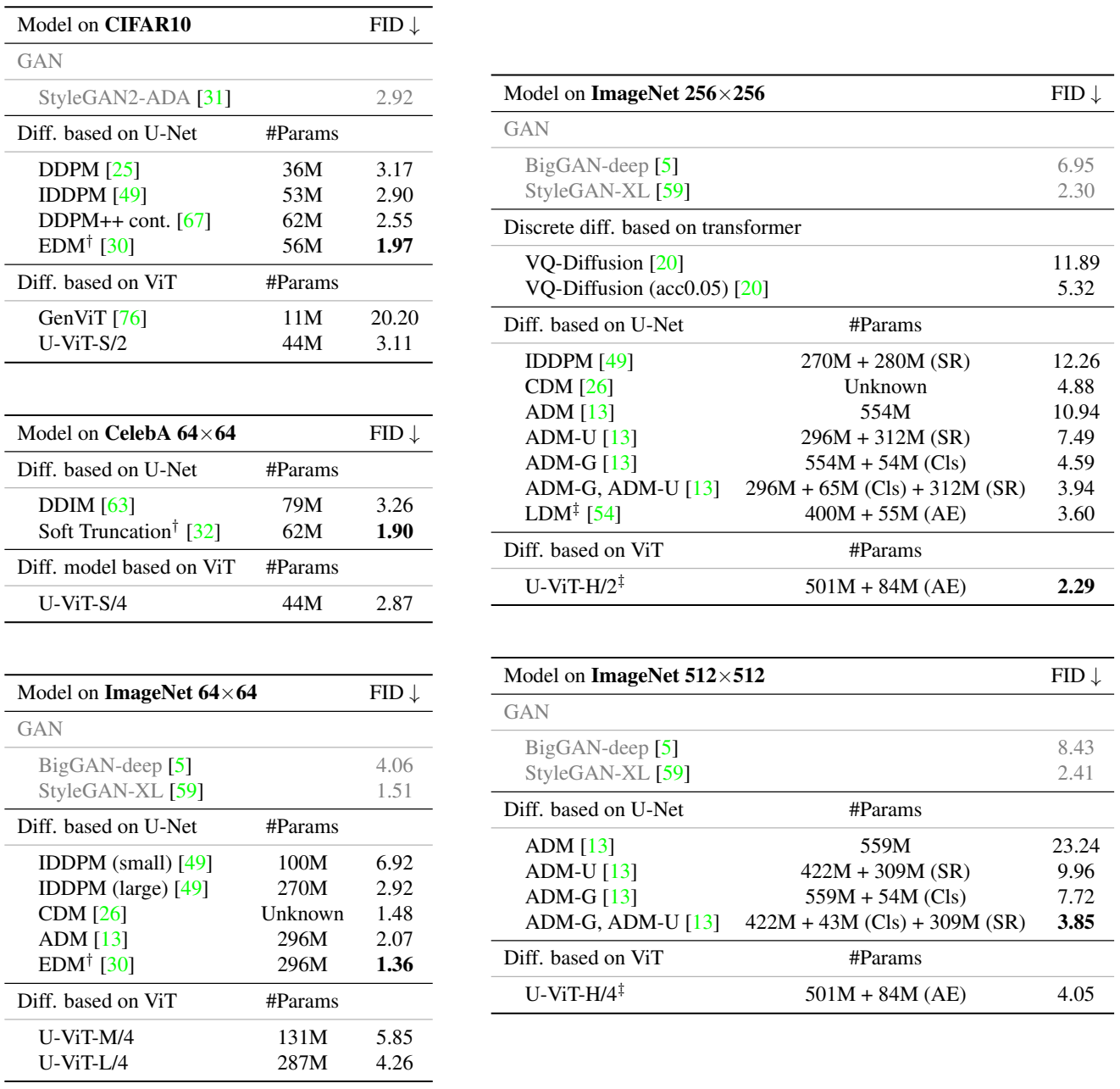
1. Unconditional and Class-Conditional Image Generation
다음은 CIFAR10과 CelebA에서의 이미지 생성 결과와 ImageNet에서의 조건부 이미지 생성 결과를 나타낸 표이다.
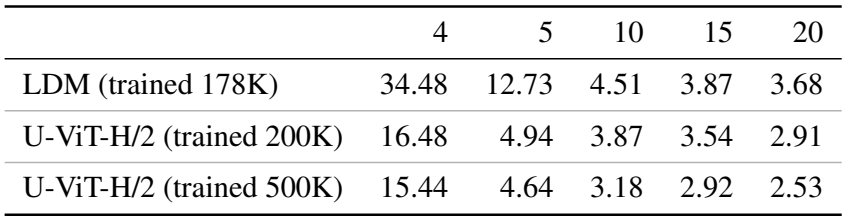
다음은 다양한 샘플링 step 수에 대한 FID를 비교한 표이다. (Image 256$\times$256, DPM-Solver 샘플러 사용)
다음은 U-ViT의 이미지 생성 결과이다.

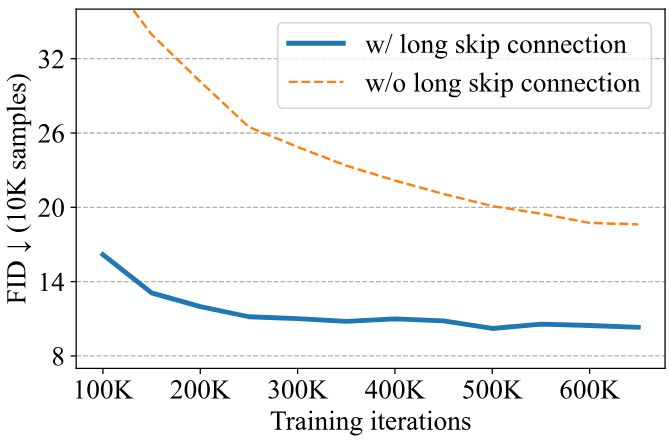
다음은 ImageNet 256$\times$256애서의 긴 skip connection에 대한 ablation 결과이다. (classifier-free guidance 사용하지 않음)
2. Text-to-Image Generation on MS-COCO
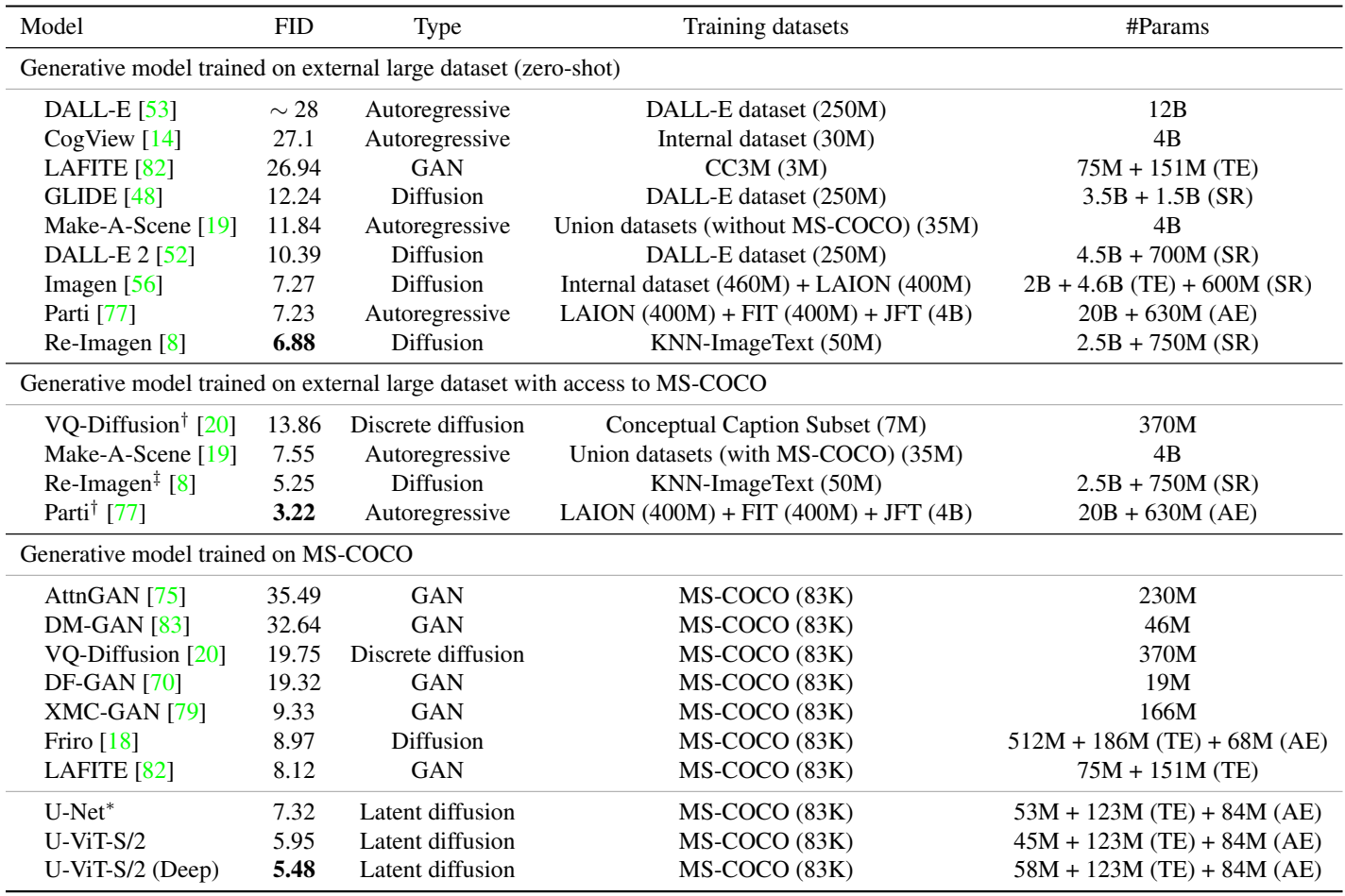
다음은 MS-COCO validation에서의 FID를 비교한 표이다.
다음은 MS-COCO에서의 text-to-image 생성 결과를 비교한 것이다.
