[논문리뷰] Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
ICCV 2023. [Paper] [Page] [Github]
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou
National University of Singapore | ARC Lab | Tencent PCG | National University of Singapore
22 Dec 2022

Introduction
인터넷에서 크롤링된 수십억 개의 텍스트-이미지 쌍으로 구성된 대규모 멀티모달 데이터셋은 Text-to-Image (T2I) 생성의 획기적인 발전을 가능하게 했다. Text-to-Video (T2V) 생성에서 이러한 성공을 복제하기 위해 최근 연구들은 공간적인 T2I 생성 모델을 시공간 도메인으로 확장했다. 이러한 모델은 일반적으로 대규모 텍스트-동영상 데이터셋 (ex. WebVid-10M)에 대한 표준 학습 패러다임을 채택한다. 이 패러다임은 T2V 생성에 대한 유망한 결과를 생성하지만 비용과 시간이 많이 소요되는 대형 하드웨어 가속기에 대한 광범위한 학습이 필요하다.
인간은 기존 지식과 제공된 정보를 활용하여 새로운 개념, 아이디어 또는 사물을 창조하는 능력을 가지고 있다. 예를 들어, “눈 위에서 스키를 타는 남자”라는 텍스트 설명이 있는 동영상을 제시하면 팬더가 어떻게 생겼는지에 대한 지식을 바탕으로 팬더가 어떻게 눈 위에서 스키를 타는지 상상할 수 있다. 대규모 이미지-텍스트 데이터로 사전 학습된 T2I 모델은 이미 개방형 도메인 개념에 대한 지식을 캡처하므로 다음과 같은 직관적인 질문이 떠오른다.
사람처럼 단일 동영상 예제에서 다른 새로운 동영상을 추론할 수 있는가?
따라서 새로운 T2V 생성 설정, 즉 단일 텍스트-동영상 쌍만 T2V generator를 학습하는 데 사용되는 One-Shot Video Tuning이 도입되었다. Generator는 입력 동영상에서 필수 모션 정보를 캡처하고 편집된 프롬프트로 새로운 동영상을 합성할 것으로 예상된다.
직관적으로 성공적인 동영상 생성의 핵심은 일관된 물체의 연속적인 움직임을 보존하는 데 있다. 따라서 저자들은 SOTA T2I diffusion model에 대해 다음을 관찰하였다.
- 모션: T2I 모델은 동사 용어를 포함하여 텍스트와 잘 일치하는 이미지를 생성할 수 있다. 예를 들어 “a man is running on the beach”라는 텍스트 프롬프트가 주어지면 T2I 모델은 반드시 연속적인 방식은 아니지만 남자가 달리는 스냅샷을 생성한다. 이는 T2I 모델이 정적 동작 생성을 위해 cross-modal attention을 통해 동사에 적절하게 attend할 수 있다는 증거로 사용된다.
- 일관된 개체: 하나의 이미지에서 여러 이미지로 T2I 모델의 공간 self-attention을 확장하기만 하면 프레임 전체에서 일관된 콘텐츠가 생성된다. 같은 예에서, 확장된 시공간 attention으로 병렬로 연속 프레임을 생성하면 모션이 여전히 연속적이지 않지만 결과 시퀀스에서 동일한 사람과 동일한 해변을 관찰할 수 있다. 이는 T2I 모델의 self-attention 레이어가 픽셀 위치가 아닌 공간적 유사성에 의해서만 구동된다는 것을 의미한다.

저자들은 Tune-A-Video라는 간단하면서도 효과적인 방법으로 이 발견을 구현하였다. 본 논문의 방법은 시공간 차원에 대한 SOTA T2I 모델의 간단한 구현을 기반으로 한다. 그러나 시공간에서 완전한 attention을 사용하면 필연적으로 계산이 2차적으로 증가한다. 따라서 프레임이 증가하는 동영상을 생성하는 것은 불가능하다. 또한 모든 파라미터를 업데이트하는 순진한 fine-tuning 전략을 사용하면 T2I 모델에 대한 기존 지식을 위태롭게 하고 새로운 개념의 동영상 생성을 방해할 수 있다.
이러한 문제를 해결하기 위해 첫 번째와 이전 프레임만 방문하는 sparse한 시공간 attention 메커니즘과 attention 블록의 projection 행렬만 업데이트하는 효율적인 튜닝 전략을 도입한다. 경험적으로 이러한 디자인은 모든 프레임에서 일관된 개체를 유지하지만 지속적인 모션이 부족하다. 따라서 inference에서는 DDIM 샘플링의 reverse process인 DDIM inversion을 통해 입력 동영상에서 structure guidance를 추가로 찾는다. 반전된 latent를 초기 noise로 사용하여 부드러운 모션을 특징으로 하는 시간적으로 일관된 동영상을 생성한다. 특히, 본 논문의 방법은 개인화되고 제어 가능한 사용자 인터페이스를 제공하는 DreamBooth와 T2I-Adapter와 같은 기존의 개인화되고 사전 학습된 조건부 T2I 모델과 본질적으로 호환된다.
Method
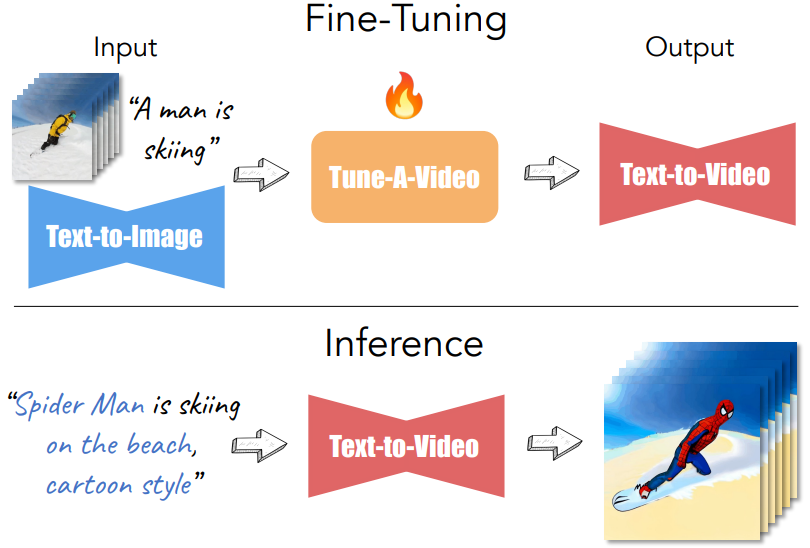
\(\mathcal{V} = \{v_i \vert i \in [1, m] \}\)는 $m$개의 프레임을 포함하는 동영상이고, $\mathcal{P}$는 $\mathcal{V}$를 설명하는 소스 프롬프트이다. 편집된 텍스트 프롬프트 $\mathcal{P}^ast$에 의한 새로운 동영상 $\mathcal{V}^\ast$를 생성하는 것이 목표이다. 예를 들어 “a man is skiing”이라는 동영상과 소스 프롬프트를 고려하고, 원본 동영상의 모션을 유지하면서 사용자가 옷의 색상을 변경하거나 스키어에게 카우보이 모자를 통합하거나 심지어 스키어를 스파이더맨으로 바꾼다고 가정하자. 사용자는 스키어의 외모를 추가로 설명하거나 다른 단어로 대체하여 소스 프롬프트를 직접 수정할 수 있다.
직관적인 솔루션은 대규모 동영상 데이터셋에서 T2V 모델을 학습하는 것이지만 계산 비용이 많이 든다. 본 논문에서는 공개적으로 사용 가능한 T2I 모델과 단일 텍스트-동영상 쌍을 사용하여 동일한 목표를 달성하는 One-Shot Video Tuning이라는 새로운 설정을 제안한다.
본 논문의 접근 방식에 대한 개요는 아래 그림과 같다.
1. Network Inflation
T2I diffusion model (ex. LDM)은 일반적으로 skip connection이 있는 업샘플링 패스가 뒤따르는 공간적 다운샘플링 패스를 기반으로 하는 신경망 아키텍처인 U-Net을 사용한다. 스택된 2D convolution residual block과 transformer 블록으로 구성된다. 각 transformer 블록은 spatial self-attention 레이어, cross-attention 레이어, feed-forward network (FFN)로 구성된다. spatial self-attention은 유사한 상관관계를 위해 feature map의 픽셀 위치를 활용하는 반면, cross-attention은 픽셀과 조건부 입력 (ex. 텍스트) 사이의 관련성을 고려한다. 동영상 프레임 $v_i$의 latent 표현 $z_{v_i}$가 주어졌을 때, spatial self-attention 메커니즘은 다음과 같다.
\[\begin{equation} \textrm{Attention}(Q, K, V) = \textrm{Softmax} ( \frac{QK^\top}{\sqrt{d}} ) \cdot V \\ Q = W^Q z_{v_i}, \quad K = W^K z_{v_i}, \quad V = W^V z_{v_i} \end{equation}\]여기서 $W^Q$, $W^K$, $W^V$는 입력을 query, key, value로 각각 project하는 학습 가능한 행렬이다. $d$는 key feature와 query feature의 출력 차원이다.
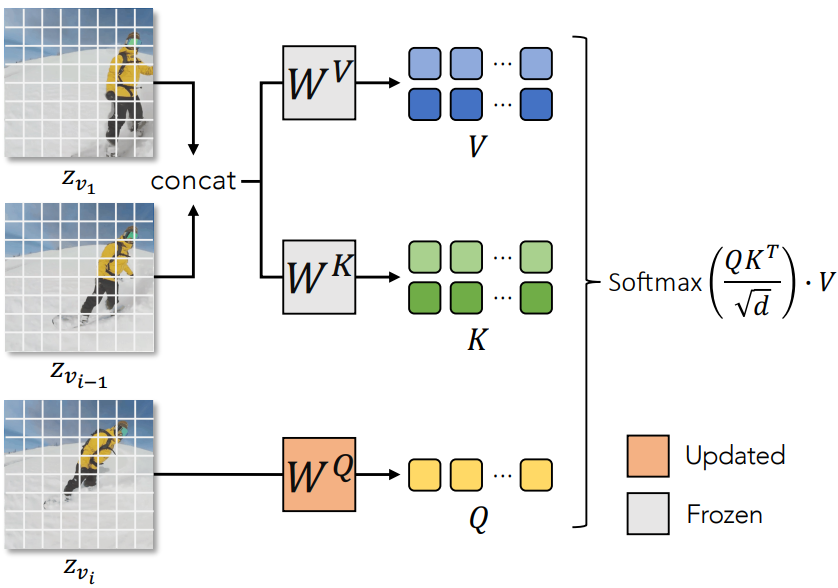
2D LDM을 시공간 영역으로 확장한다. VDM과 유사하게 2D convolution layer를 pseudo 3D convolution layer로 확장하고 3$\times$3 커널을 1$\times$3$\times$3 커널로 대체하고 시간 모델링을 위해 각 transformer 블록에 temporal self-attention 레이어를 추가한다. 시간적 일관성을 향상시키기 위해 spatial self-attention 메커니즘을 시공간 도메인으로 확장한다. 전체 attention과 시공간 일관성을 캡처하는 causal attention을 포함하여 시공간 attention (ST-Attn) 메커니즘에 대한 대체 옵션이 있다. 그러나 이러한 간단한 선택은 계산 복잡도가 높기 때문에 프레임이 증가하는 동영상을 생성하는 데 실제로 적합하지 않다. 구체적으로, 주어진 $m$개의 프레임과 각 프레임에 대한 $N$개의 시퀀스, 전체 attention과 causal attention 모두에 대한 복잡도는 $O((mN)^2)$이다. $m$ 값이 큰 긴 동영상을 생성해야 하는 경우에는 저렴하지 않다.
여기서, attention 행렬이 프레임 $z_{v_i}$와 두 개의 이전 프레임 $z_{v_1}$과 $z_{v_{i-1}}$ 사이에서 계산되고 $O(2mN^2)$에서 낮은 계산 복잡도를 유지하는 causal attention 메커니즘의 sparse 버전을 사용할 것을 제안한다. 구체적으로 프레임 $z_{v_i}$에서 query feature를, 첫 번째 프레임 $z_{v_1}$과 이전 프레임 $z_{v_{i-1}}$에서 key feature과 value feature를 파생하고 $\textrm{Attention}(Q, K, V)$을 다음과 같이 구현한다.
\[\begin{equation} \textrm{Attention}(Q, K, V) = \textrm{Softmax} ( \frac{QK^\top}{\sqrt{d}} ) \cdot V \\ Q = W^Q z_{v_i}, \quad K = W^K [z_{v_1}, z_{v_{i-1}}], \quad V = W^V [z_{v_1}, z_{v_{i-1}}] \end{equation}\]여기서 $[\cdot]$는 concatenation 연산을 나타낸다. Porjection 행렬 $W^Q$, $W^K$, $W^V$는 공간과 시간에 걸쳐 공유된다. 시각적 묘사는 아래 그림과 같다.
2. Fine-Tuning and Inference
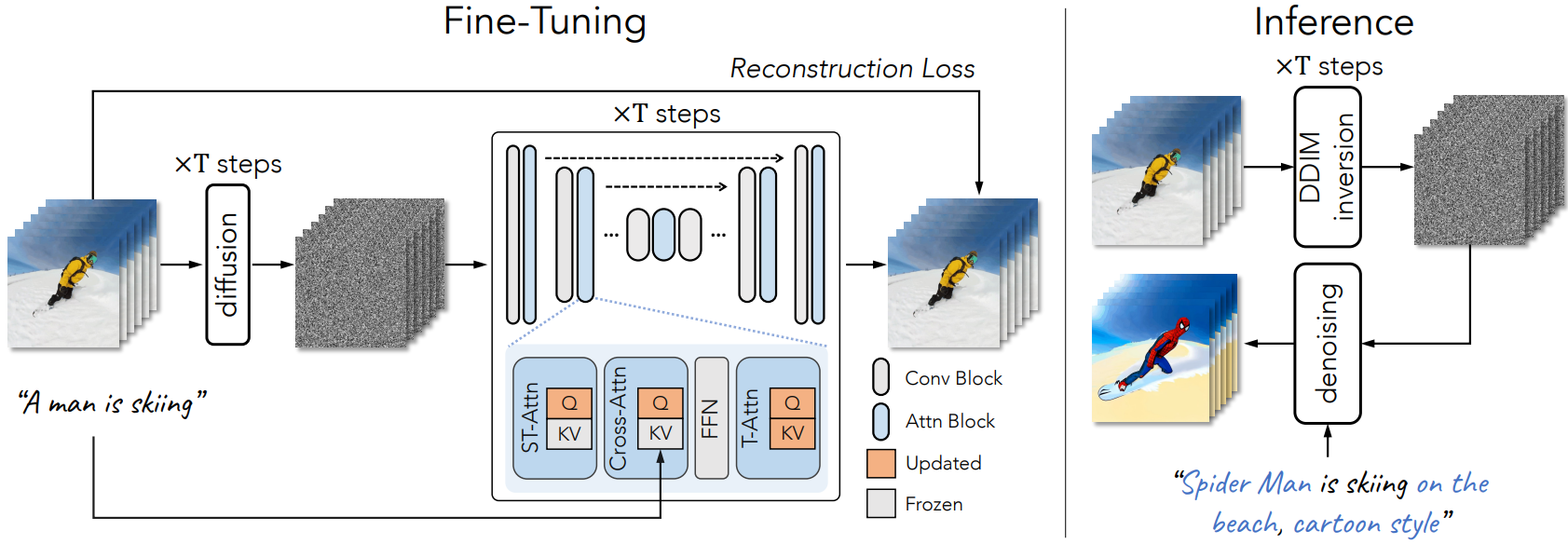
Model fine-tuning
이제 시간 모델링을 위해 주어진 입력 동영상에서 네트워크를 fine-tuning한다. 시공간 attention (ST-Attn)은 이전 프레임에서 관련 위치를 쿼리하여 시간적 일관성을 모델링하도록 설계되었다. 따라서 파라미터 $W^K$와 $W^V$를 고정하고 ST-Attn layer에서만 $W^Q$를 업데이트한다. 대조적으로 새로 추가되는 전체 temporal self-attention (T-Attn) 레이어를 fine-tuning한다. 또한 cross-attention (Cross-Attn)에서 query projection을 업데이트하여 텍스트-동영상 정렬을 개선한다. 실제로 attention 블록을 fine-tuning하는 것은 전체 튜닝에 비해 계산적으로 효율적이며 사전 학습된 T2I diffusion model의 원래 속성을 유지한다. 표준 LDM과 동일한 목적 함수를 사용한다.
Structure guidance via DDIM inversion
Attention 레이어를 fine-tuning하는 것은 모든 프레임에서 공간적 일관성을 보장하는 데 필수적이다. 그러나 픽셀 이동에 대한 많은 제어 기능을 제공하지 않아 루프에서 정체된 동영상이 발생한다. 이 문제를 해결하기 위해 Inference 단계에서 소스 동영상의 structure guidance를 통합한다. 구체적으로, 텍스트 조건 없이 DDIM inversion을 통해 소스 동영상 $\mathcal{V}$의 latent noise를 얻는다. 이 noise는 편집된 프롬프트 $\mathcal{T}^\ast$ 에 의해 가이드되는 DDIM 샘플링의 시작점 역할을 한다. 출력 동영상 $\mathcal{V}^\ast$는 다음과 같다.
\[\begin{equation} \mathcal{V}^\ast = \mathcal{D} (\textrm{DDIM-samp} (\textrm{DDIM-inv} (\mathcal{E}(\mathcal{V})), \mathcal{T}^\ast)) \end{equation}\]동일한 입력 동영상에 대해 DDIM inversion을 한 번만 수행하면 된다.
Applications of Tune-A-Video
다음은 Tune-A-Video의 샘플 결과이다.

- 개체 편집: 텍스트 프롬프트 편집을 통해 개체를 수정할 수 있다. 이를 통해 개체를 쉽게 교체, 추가 또는 제거할 수 있다.
- 배경 변경: 사용자가 개체 움직임의 일관성을 유지하면서 동영상 배경 (즉, 개체가 있는 위치)을 변경할 수 있다.
- 스타일 전송: 사전 학습된 T2I 모델의 open-domain 지식 덕분에 동영상 데이터만으로는 배우기 어려운 다양한 스타일로 동영상을 전송할 수 있다.
- 개인화되고 제어 가능한 생성: 직접 fine-tuning하여 개인화된 T2I 모델 (ex. DreamBooth)과 쉽게 통합할 수 있다. 또한 T2I-Adapter와 ControlNet과 같은 조건부 T2I 모델과 통합되어 추가 학습 비용 없이 생성된 동영상에 대한 다양한 제어를 가능하게 한다.
Experiments
- 구현 디테일
- Stable Diffusion과 사전 학습된 가중치를 기반으로 함
- 입력 동영상에서 512$\times$512 해상도로 32개의 균일한 프레임을 샘플링하고 fine-tuning
- Fine-tuning: batch size = 1, learning rate = $3 \times 10^{-5}$, 500 steps
- Inference 시 classifier-free guidance와 함께 DDIM sampler를 사용
- 동영상 1개를 fine-tuning하는 데 10분 소요, 샘플링에 1분 소요 (NVIDIA A100 GPU 1개)
1. Baseline Comparisons


2. Ablation Study

Limitations

위 그림은 입력 동영상이 여러 객체를 포함하고 가려짐이 있을 때의 실패 사례를 나타낸다. 이는 여러 개체 간의 상호 작용을 처리할 때 T2I 모델의 고유한 제한 때문일 수 있다.