[논문리뷰] TryOnDiffusion: A Tale of Two UNets
CVPR 2023. [Paper] [Page]
Luyang Zhu, Dawei Yang, Tyler Zhu, Fitsum Reda, William Chan, Chitwan Saharia, Mohammad Norouzi, Ira Kemelmacher-Shlizerman
University of Washington | Google Research
14 Jun 2023

Introduction
가상 의상 시착은 사람의 이미지와 의상의 이미지를 기반으로 의상이 사람에게 어떻게 보일지 시각화하는 것을 목표로 한다. 가상 시착은 온라인 쇼핑 경험을 향상시킬 수 있는 잠재력이 있지만 대부분의 시착 방법은 신체 자세와 모양 변화가 적을 때만 효과가 좋다. 핵심 문제는 의상 패턴과 질감에 왜곡을 도입하지 않으면서 타겟 체형에 맞게 의상을 단단하게 뒤틀지 않는 것이다.
자세나 체형이 크게 다를 경우 새로운 모양이나 가려짐에 따라 주름이 생기거나 평평해지는 방식으로 의상을 뒤틀어야 한다. 관련 연구들은 픽셀 변위를 먼주 추정하여 워핑 문제를 접근해 왔다. 예를 들어 optical flow, pixel 워핑, perceptual loss를 사용하는 후처리를 순서대로 사용할 수 있다. 그러나 기본적으로 변위 찾기, 워핑, 블렌딩의 순서는 가려진 부분과 모양 변형이 픽셀 변위로 정확하게 모델링하기 어렵기 때문에 종종 아티팩트를 생성한다. 강력한 생성 모델을 사용하더라도 나중에 블렌딩 단계에서 이러한 아티팩트를 제거하는 것도 어렵다. 대안으로 TryOnGAN은 조건부 StyleGAN2 네트워크를 통해 변위를 추정하지 않고 생성된 latent space에서 최적화하는 방법을 보여주었다. 생성된 결과는 인상적인 품질이었지만 latent space의 낮은 표현력으로 인해 특히 패턴이 많은 의상의 경우 출력에서 디테일이 손실되는 경우가 많다.
본 논문에서는 1024$\times$1024 해상도에서 의상 디테일을 유지하면서 큰 가려짐, 포즈 변경, 체형 변경을 처리할 수 있는 TryOnDiffusion을 제시한다. TryOnDiffusion은 타겟 인물 이미지와 다른 사람이 착용한 의상 이미지의 두 이미지를 입력으로 사용하며, 의상을 입은 타겟 인물을 출력으로 합성한다. 의상은 신체 부위나 다른 의상에 의해 부분적으로 가려질 수 있으며 상당한 변형이 필요하다. 본 논문의 방법은 400만 쌍의 이미지로 학습되었다. 각 쌍에는 같은 옷을 입은 같은 사람이 있지만 다른 포즈로 나타난다.
TryOnDiffusion은 cross attention을 통해 통신하는 두 개의 하위 UNet으로 구성된 Parallel-UNet이라는 새로운 아키텍처를 기반으로 한다. 두 가지 핵심 디자인 요소는 암시적 워핑과 순차적 방식이 아닌 단일 패스에서의 워핑과 블렌딩의 조합이다. 타겟 인물과 원본 의상 사이의 암시적 워핑은 장거리 대응을 설정할 수 있는 여러 피라미드 레벨에서 feature에 대한 cross attention을 통해 달성된다. 장거리 대응은 특히 심한 가려짐과 극단적인 포즈 차이에서 잘 수행된다. 또한 동일한 네트워크를 사용하여 워핑과 블렌딩을 수행하면 두 프로세스가 색상 픽셀 레벨이 아닌 feature 레벨에서 정보를 교환할 수 있으며 이는 perceptual loss와 style loss에 필수적인 것이다.
1024$\times$1024 해상도에서 고품질 결과를 생성하기 위해 Imagen을 따르고 cascaded diffusion model을 만든다. 특히 Parallel-UNet 기반 diffusion은 12$\times$128과 256$\times$256 해상도에 사용돤다. 그런 다음 256$\times$256 결과는 super-resolution diffusion network에 공급되어 최종 1024$\times$1024 이미지를 생성한다.
Method
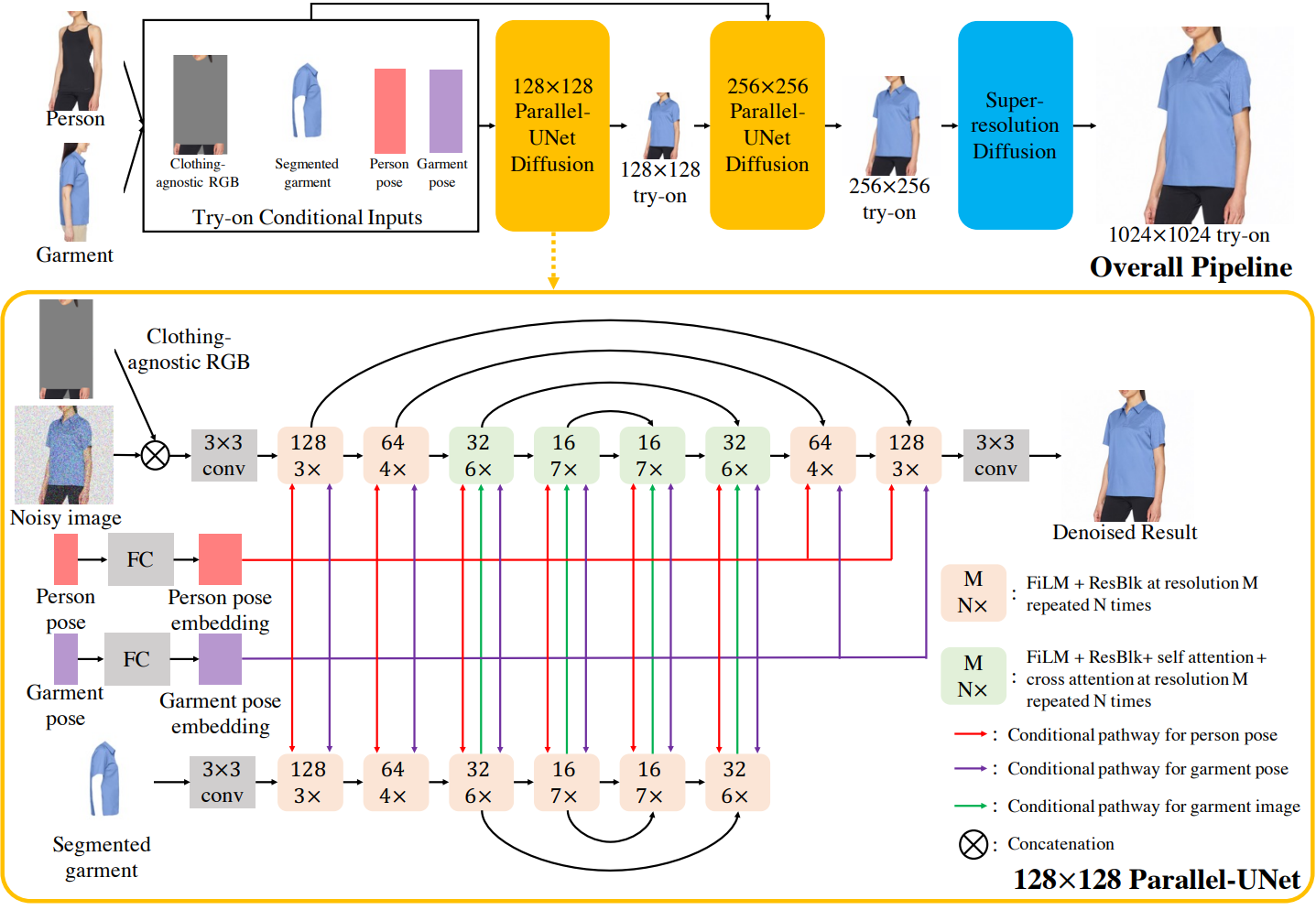
다음 그림은 가상 시착 방법의 개요이다. 사람 $p$의 이미지 $I_p$와 의상 $g$를 입은 다른 사람의 이미지 $I_g$가 주어지면 본 논문의 접근법은 의상 $g$를 입은 사람 $p$의 시착 결과 $I_\textrm{tr}$을 생성한다. $I_p$와 $I_g$는 같은 사람이 같은 옷을 입고 있지만 두 가지 포즈가 다른 이미지인 쌍 데이터에 대해 학습된다. Inference하는 동안 $I_p$와 $I_g$는 서로 다른 옷을 입고 서로 다른 포즈를 취하는 두 사람의 이미지로 설정된다.
Preprocessing of inputs
먼저 기존 방법을 사용하여 사람 이미지와 의상 이미지 모두에 대한 인간 파싱 맵 $(S_p, S_g)$와 2D 포즈 키포인트 $(J_p, J_g)$를 예측한다. 의상 이미지의 경우 파싱 맵을 사용하여 의상 $I_c$를 추가로 분할한다. 사람 이미지의 경우 원래 의상을 제거하지만 사람의 정체성을 유지하는 옷에 구애받지 않는 RGB 이미지 $I_a$를 생성한다. VITON-HD에 설명된 의상에 구애받지 않는 RGB는 도전적인 인간 포즈와 헐렁한 의복에 대해 원래 의복의 정보를 흘린다. 따라서 의상 정보를 제거하기 위해 보다 공격적인 방법을 채택한다. 구체적으로 먼저 전경 사람의 boundary box 영역 전체를 마스킹한 다음 그 위에 머리, 손, 하체 부분을 복사하여 붙여넣는다. $S_p$와 $J_p$를 사용하여 의상에 해당하지 않는 신체 부위를 추출한다. 또한 포즈 키포인트를 네트워크에 입력하기 전에 $[0, 1]$로 정규화한다. 시착 조건 입력은 $c_\textrm{tryon} = (I_a, J_p, I_c, J_g)$로 표시된다.
1. Cascaded Diffusion Models for Try-On
Cascaded diffusion model은 하나의 기본 diffusion model과 두 개의 super-resolution (SR) diffusion model로 구성된다.
기본 diffusion model은 128$\times$128 Parallel-UNet으로 parameterize된다. 시착 조건 입력 $c_\textrm{tryon}$을 사용하여 128$\times$128 시착 결과 \(I_\textrm{tr}^{128}\)을 예측한다. $I_a$와 $I_c$는 부정확한 인간 파싱 추정과 포즈 추정으로 인해 noisy할 수 있으므로 noise conditioning augmentation을 적용한다. 특히 랜덤 Gaussian noise가 다른 처리 전에 $I_a$와 $I_c$에 추가된다. Noise augmentation 레벨도 조건부 입력으로 처리된다.
128$\times$128 $\rightarrow$ 256$\times$256 SR diffusion model은 256$\times$256 Parallel-UNet으로 parameterize된다. 256$\times$256 해상도에서 128$\times$128 시착 결과 \(I_\textrm{tr}^{128}\)과 시착 조건부 입력 \(c_\textrm{tryon}\) 모두를 컨디셔닝하여 256$\times$256 시착 결과 \(I_\textrm{tr}^{256}\)을 생성한다. \(I_\textrm{tr}^{128}\)은 학습 중에 ground-truth에서 직접 다운샘플링되며, 테스트 시 기본 diffusion model의 예측으로 설정된다. \(I_\textrm{tr}^{128}\), $I_a$, $I_c$를 포함하여 이 단계에서 모든 조건부 입력 이미지에 noise conditioning augmentation이 적용된다.
256$\times$256$ \rightarrow$ 1024$\times$1024 SR diffusion model은 Imagen이 도입한 Efficient-UNet으로 parameterize된다. 이 단계는 시착 컨디셔닝이 없는 순수한 SR model이다. 학습을 위해 1024$\times$1024에서 256$\times$256 random crop이 ground-truth 역할을 하고 입력은 crop에서 다운샘플링된 64$\times$64 이미지로 설정된다. Inference하는 동안 모델은 이전 Parallel-UNet 모델의 256$\times$256 시착 결과를 입력으로 취하고 최종 시착 결과 \(I_\textrm{tr}\)을 1024$\times$1024 해상도로 합성한다. 이 설정을 용이하게 하기 위해 모든 attention 레이어를 제거하여 네트워크를 fully convolutional로 만든다. 이전의 두 모델과 마찬가지로 조건부 입력 이미지에 noise conditioning augmentation이 적용된다.
2. Parallel-UNet
128$\times$128 Parallel-UNet은 다음과 같이 표현될 수 있다.
\[\begin{equation} \epsilon_t = \epsilon_\theta (z_t, t, c_\textrm{tryon}, t_\textrm{na}) \end{equation}\]여기서 $t$는 diffusion timestep이고, $z_t$는 $t$에서 ground-truth로부터 손상된 noisy한 이미지이다. \(c_\textrm{tryon}\)은 시착 조건부 입력이고, \(t_\textrm{na}\)는 다양한 조건부 이미지에 대한 noise augmentation 레벨 세트이다. $\epsilon_t$는 예측된 noise이며 $z_t$에서 ground-truth를 복구하는 데 사용할 수 있다. 256$\times$256 Parallel-UNet은 256$\times$256 해상도에서 시착 조건 입력 \(c_\textrm{tryon}\) 외에 시착 결과 \(I_\textrm{tr}^{128}\)을 입력으로 받는다. Parallel-UNet은 다음의 두 가지 핵심 설계 요소를 가진다.
- Implicit warping
- Combining warp and blend in a single pass
Implicit warping
첫 번째 질문은 다음과 같다.
신경망에서 암시적 워핑을 어떻게 구현할 수 있는가?
자연스러운 솔루션 중 하나는 전통적인 UNet을 사용하고 채널 차원을 따라 분할된 의상 $I_c$와 noisy한 이미지 $z_t$를 concat하는 것이다. 그러나 channel-wise concatenation은 의상 워핑과 같은 복잡한 변환을 처리할 수 없다. 이는 전통적인 UNet의 연산이 spatial convolution과 spatial self-attention이고 이는 픽셀 단위의 구조적 편향이 강하기 때문이다. 이 문제를 해결하기 위해 정보 스트림 $I_c$와 $z_t$ 사이의 cross attention 메커니즘을 사용하여 암시적 워핑을 달성한다. Cross attention은 스케일링된 내적 attention을 기반으로 한다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = \textrm{softmax} (\frac{QK^\top}{\sqrt{d}}) V \end{equation}\]$Q \in \mathbb{R}^{M \times d}$, $K \in \mathbb{R}^{N \times d}$, $V \in \mathbb{R}^{N \times d}$는 각각 query, key, value이다. $M$은 query 벡터의 수, $N$은 key 벡터와 value 벡터의 수, $d$는 벡터의 차원이다. 본 논문의 경우 query와 key-value 쌍은 서로 다른 입력에서 나온다. 구체적으로, $Q$는 $z_t$의 flatten된 feature이고 $K$와 $V$는 $I_c$의 flatten된 feature이다. 내적을 통해 계산된 attention map $\frac{QK^\top}{\sqrt{d}}$는 타겟 인물과 소스 의상 간의 유사성을 알려주고 시착 task에 대한 대응을 나타내는 학습 가능한 방법을 제공한다. 또한 모델이 다양한 표현 subspace에서 학습할 수 있도록 cross attention multi-head를 만든다.
Combining warp and blend in a single pass
이전 연구들처럼 의상을 타겟 신체에 워핑한 다음 타겟 인물과 혼합하는 대신 두 task를 단일 pass로 결합한다. 의상과 사람을 각각 처리하는 두 개의 UNet을 통해 이를 달성한다.
Person-UNet은 의상에 구애받지 않는 RGB $I_a$와 noisy한 이미지 $z_t$를 입력으로 사용한다. $I_a$와 $z_t$는 픽셀 단위로 정렬되어 있으므로 UNet 처리 시작 시 채널 차원을 따라 직접 concat한다.
Garment-UNet은 분할된 의상 이미지 $I_c$를 입력으로 사용한다. 의상 feature는 cross attention을 통해 타겟 이미지에 융합된다. 모델 파라미터를 저장하기 위해 32$\times$32 업샘플링 블록 이후에 garment-UNet을 일찍 중지한다. 여기서 person-UNet의 최종 cross attention 모듈이 완료된다.
워핑 프로세스와 블렌딩 프로세스를 가이드하려면 사람 포즈와 의상 포즈가 필요하다. 포즈 임베딩을 개별적으로 계산하기 위해 먼저 선형 레이어에 공급된다. 그런 다음 포즈 임베딩은 포즈 임베딩을 각 self-attention 레이어의 key-value 쌍에 concat하여 구현되는 attention 메커니즘을 통해 person-UNet에 융합된다. 게다가 포즈 임베딩은 CLIP 스타일 1D attention pooling을 사용하여 키포인트 차원을 따라 감소하고 timestep $t$와 noise augmentation 레벨 $t_\textrm{na}$의 위치 인코딩으로 합산된다. 결과로 나온 1D 임베딩은 모든 스케일에서 FiLM을 사용하여 두 UNet의 feature를 변조하는 데 사용된다.
Experiments
- 데이터셋: 400만 개의 쌍으로 된 데이터셋 (같은 사람의 다른 포즈 & 의상)
- 구현 디테일
- Batch size = 256, iteration = 500,000
- Optimizer: Adam
- Learning rate: $10^{-4}$ (처음 1만 iteration 까지 linear warmup)
- Classifier-free guidance 사용 (guidance weight = 2)
- Noise conditioning augmentation
- 학습 중에는 균등 분포 $\mathcal{U} ([0, 1])$에서 샘플링
- Inference 시에는 grid search를 기반으로 상수 값으로 고정
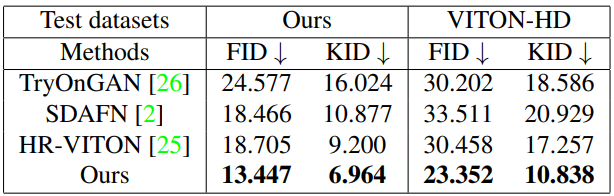
Quantitative comparison
다음은 3개의 baseline들과 정량적으로 비교한 표이다.
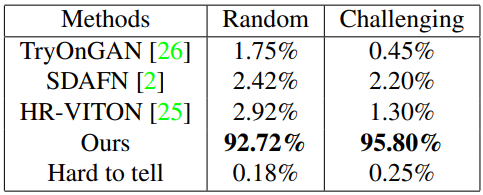
User study
다음은 2가지 user study에 대한 결과이다. “Random”은 2804개의 랜덤한 입력 쌍을 15명의 비전문가가 최고의 결과를 선택한 것이다. “Challenging”은 6천개의 쌍 중 2천개의 어려운 신체 포즈가 선택되어 같은 방법으로 평가된다.
Qualitative comparison
다음은 3개의 baseline들과 정성적으로 비교한 표이다.

다음은 VITON-HD 데이터셋에서 SOTA 방법들과 비교한 것이다.

Ablation
다음은 ablation study 결과이다. 왼쪽은 암시적 워핑에 사용한 방법에 따른 결과이다. 오른쪽은 워핑과 블렌딩을 위한 네트워크 수에 따른 결과이다.

Limitations
- 전처리 중 segmentation map과 포즈 추정에 오차가 있는 경우 의상 아티팩트가 나타난다.
- 의상에 구애받지 않는 RGB를 통해 정체성을 표현하는 것은 이상적이지 않다. 때로는 정체성의 일부만 보존할 수 있기 때문이다.
- 학습 및 테스트 데이터셋은 대부분 깨끗하고 균일한 배경을 가지고 있으므로 더 복잡한 배경에서 방법이 어떻게 수행되는지 알 수 없다.
- 본 논문은 상반신 의상에 초점을 맞추었고 전신 시착은 실험하지 않았다.
다음은 실패 케이스들이다.

Results on variety of people and garments
다음은 8명의 사람과 5개의 의상에 대한 TryOnDiffusion 결과이다.
