[논문리뷰] TRIPS: Trilinear Point Splatting for Real-Time Radiance Field Rendering
Eurographics 2024. [Paper] [Page] [Github]
Linus Franke, Darius Rückert, Laura Fink, Marc Stamminger
Friedrich-Alexander-Universität Erlangen-Nürnberg
11 Jan 2024

Introduction
Novel view synthesis 방법들 중 다수는 메쉬나 점과 같은 명시적인 표현에 의존한다. 일반적으로 명시적 모델은 3D 재구성 프로세스에서 파생되며 최신 GPU 능력에 잘 맞는 rasterization을 통해 효율적으로 렌더링될 수 있다. 그럼에도 불구하고 이러한 재구성된 모델은 종종 완벽성에 미치지 못하며 아티팩트를 완화하기 위한 추가 단계가 필요하다.
이러한 아티팩트를 처리하는 일반적인 전략은 inverse rendering이라고 알려진 장면별 최적화 방법을 사용하는 것이다. 이를 통해 장면의 텍스처, 형상, 카메라 파라미터를 조정하여 렌더링을 사진과 일치시킬 수 있다. 포인트 기반 inverse neural rendering 기술 분야에서 최근 성공한 두 가지 접근 방식은 3D Gaussian Splatting과 ADOP이다.
3D Gaussian Splatting은 각 포인트가 3D Gaussian 분포로 렌더링되는 독특한 전략을 사용하여 포인트의 모양과 크기를 직접 최적화할 수 있다. 이 프로세스는 큰 splat을 활용하여 글로벌 좌표 공간 내 포인트 클라우드의 갭을 효과적으로 채운다. 놀랍게도 이 접근 방식은 재구성을 위해 신경망을 통합할 필요 없이 고품질 이미지를 생성한다. 그러나 단점은 선명도가 잠재적으로 손실된다는 점이다. 특히 사용 가능한 관찰이 제한된 경우 Gaussian은 흐릿함을 도입하는 경향이 있기 때문이다.
이와 대조적으로 ADOP는 여러 해상도에서 깊이 테스트를 통해 radiance field를 하나의 픽셀 포인트로 rasterize한다. 그 후, 신경망을 사용하여 갭을 해결하고 화면 공간의 텍스처 디테일을 향상시킨다. 이 접근 방식은 원래 포인트 클라우드의 해상도를 능가하는 텍스처 디테일을 재구성하는 능력을 보유하고 있지만 신경망은 계산 오버헤드를 추가하고 큰 구멍을 채우는 데 약점을 보여준다.
본 논문에서는 실시간 렌더링 능력을 잃지 않으면서 ADOP와 3D Gaussian의 장점을 모두 활용하려는 새로운 접근 방식인 TRIPS를 소개한다. 3D Gaussian Splatting과 유사하게 TRIPS는 다양한 크기의 splat을 rasterize하지만 ADOP와 마찬가지로 재구성 네트워크를 적용하여 구멍이 없고 선명한 이미지를 생성한다. 보다 정확하게는 먼저 포인트 클라우드를 2$\times$2$\times$2 trilinear splat으로 이미지 피라미드로 rasterize하고 이를 앞에서 뒤로의 alpha blending을 사용하여 블렌딩한다. 그 후, 작고 효율적인 재구성 신경망을 통해 이미지 피라미드를 제공하며, 다양한 레이어를 조화시키고 남은 공백을 해결하며 렌더링 아티팩트를 숨긴다. 특히 까다로운 입력 시나리오에서 높은 수준의 디테일을 보존하기 위해 spherical harmonics(SH) 모듈과 tone mapping 모듈을 파이프라인에 통합한다.
본 논문의 접근 방식은 3D Gaussian과 거의 동일한 성능으로 더 선명한 이미지를 생성할 수 있다. 또한 렌더링 프로세스 전반에 걸쳐 상당한 갭을 메우고 시간적 일관성을 유지하는 task에서 ADOP를 능가한다.
Method

위 그림은 렌더링 파이프라인의 개요이다. 입력 데이터는 카메라 파라미터와 dense한 포인트 클라우드가 포함된 이미지로 구성되며, 이는 multi-view stereo 또는 LiDAR sensing과 같은 방법을 통해 얻을 수 있다. 특정 뷰를 렌더링하기 위해 TRIPS 기술을 사용하여 각 포인트의 color descriptor를 이미지 피라미드에 투영하고 혼합한다. 그런 다음, 소형 재구성 네트워크는 계층화된 표현을 통합한 다음 결과 feature들을 RGB 색상으로 변환하는 spherical harmonics(SH) 모듈과 tone mapper를 적용한다.
본 논문의 방법의 핵심은 trilinear point renderer이다. 이는 투영된 포인트 크기에 따라 결정되는 두 개의 해상도 레이어에 선형적으로 뿐만 아니라 화면 공간 위치에 포인트를 이중선형으로(bilinearly) 표시한다. 이 렌더러는 이전의 point-rasterizing 접근 방식에서 영감을 받았다. 이미지 $I$는 렌더링 함수 $\Phi$의 출력이다.
\[\begin{equation} I = \Phi (C, R, t, x, E, \upsilon, \tau, \gamma) \end{equation}\]여기서 $C$는 camera intrinsics, $(R, t)$는 타겟 뷰의 extrinsic pose, $x$는 포인트들의 위치, $E$는 환경 맵, $\upsilon$은 포인트들의 world space 크기, $\tau$는 neural point descriptor, $\gamma$는 각 포인트들의 불투명도이다.
다른 접근 방식들과 달리 점점 더 낮은 해상도로 여러 render pass를 사용하지 않는다. 이는 낮은 해상도 레이어에서 심각한 오버드로를 유발하기 때문이다. 대신, 포인트의 투영된 크기와 가장 잘 일치하는 두 레이어를 계산하고 이를 2$\times$2 splat으로 이러한 레이어에만 렌더링한다. 이를 통해 다양한 splat 크기를 모방하지만 효과적으로 2$\times$2 splat만 렌더링한다. 그런 다음 레이어는 나중에 작은 재구성 네트워크에서 U-Net의 디코더 부분과 유사하게 최종 이미지로 병합된다.
1. Differentiable Trilinear Point Splatting
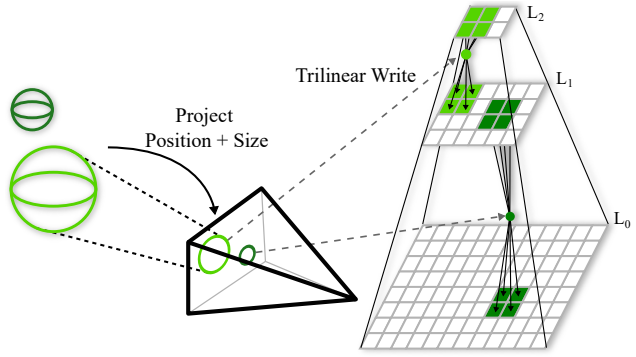
$C$와 $(R,t)$를 사용하여 각 포인트 위치 $(x_w, y_w, z_w)$를 반올림되지 않은 연속적인 화면 공간 좌표 $(x, y, z)$에 투영하고 각 world space 포인트 크기 $s_w$를 화면 공간 크기 $s$에 투영한다. (초점 거리: $f$)
다음으로, 이 포인트들을 이중선형으로 2$\times$2$\times$2 splat으로 렌더링하고 위 그림과 같이 $L_\textrm{lower} = \lfloor \log(s) \rfloor$와 $L_\textrm{upper} = \lceil \log(s) \rceil$을 사용하여 두 개의 인접한 해상도 레이어 $L$로 splatting하여 포인트 크기를 처리한다. $s_i = \lfloor 2^L \rfloor$인 픽셀 $(x_i, y_i, s_i)$에 대한 이미지 피라미드에 기록되는 최종 불투명도 값 $\gamma$는 다음과 같다.
\[\begin{aligned} \gamma &= \beta \cdot \iota \cdot \alpha \\ \beta &= (1 - \vert x - x_i \vert) \cdot (1 - \vert y - y_i \vert) \\ \iota &= \begin{cases} 1 - \vert s - s_i \vert & \; s \ge 1 \\ \epsilon + (1-\epsilon) s & \; s_i = 0, s < 1 \end{cases} \end{aligned}\]여기서 $\beta$는 이미지 레이어 내부의 이중선형 가중치, $\iota$는 선형 레이어 가중치, $\alpha$는 포인트의 불투명도 값이다. 레이어 가중치 $\iota$는 포인트 크기 $s$가 이미지 피라미드 내부에 있는 경우 linear interpolation이다. $\iota$의 두 번째 케이스는 픽셀 크기가 1보다 작은 멀리 있는 포인트를 처리한다. 이를 놓치지 않기 위해 항상 가장 높은 레벨 0에 추가한다. 가중치가 사라지는 것을 방지하기 위해 기여도가 최소한 $\epsilon = 0.25$인지 확인한다.
2. Multi Resolution Alpha Blending
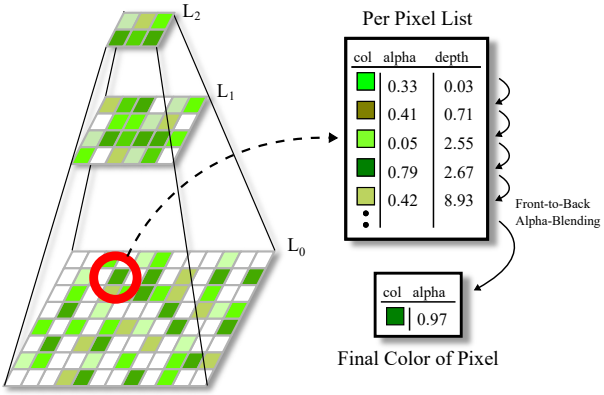
각 포인트는 여러 픽셀에 기록되고 여러 포인트가 동일한 픽셀에 속할 수 있으므로 픽셀별 목록 \(\Lambda_{l_i, x_i, y_i}\)에서 모든 조각을 수집한다. 이러한 목록은 깊이별로 정렬되며 최대 16개의 element를 가진다. 색상 $C_\Lambda$는 앞에서 뒤로 alpha-blending을 사용하여 계산된다.
3. Neural Network
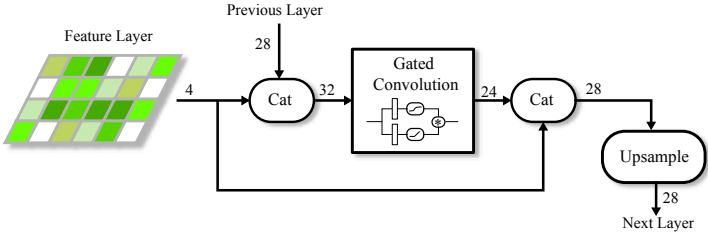
렌더러가 생성한 결과는 $n$개의 레이어로 구성된 feature image pyramid로 구성된다. 이러한 개별 레이어는 소형 신경망을 통해 최종적으로 하나의 전체 해상도 이미지로 통합된다. 네트워크 아키텍처는 각 레이어에 하나의 gated convolution을 통합하고 자체 바이패스 연결과 32의 filter 크기를 특징으로 한다. 또한 최종 레이어를 제외한 모든 레이어에 대해 이중선형 업샘플링 연산을 포함하여 출력을 후속 레벨과 병합한다. 이 구성은 위 그림에 표시되어 있으며 제한된 수의 feature, 픽셀, convolution 연산으로 인해 효율적인 디코더 네트워크와 유사하다.
잘 확립된 hole-filling 신경망과 달리 본 논문의 접근 방식에는 훨씬 더 작고 효율적인 네트워크가 필요하다. 이렇게 줄어든 네트워크 크기는 렌더러가 자동으로 갭을 채우는 데 능숙하고 원활한 출력을 생성한다는 사실에서 비롯된다. 결과적으로 네트워크의 주요 task는 최소한의 hole-filling과 outlier 제거를 학습하여 고품질 텍스처 재구성에 노력을 집중할 수 있도록 하는 것이다.
4. Spherical Harmonics Module and Tone Mapping
뷰에 따른 효과와 카메라별 캡처 파라미터(ex. 노출 시간)를 모델링하기 위해 선택적으로 네트워크 출력을 spherical harmonics(SH) 계수로 해석하고 이를 RGB 색상으로 변환한 다음 최종적으로 결과를 물리 기반 tone mapper에 전달한다. 이를 통해 시스템은 명시적인 뷰 방향을 사용할 수 있다. SH 모듈은 27개의 입력 계수에 해당하는 3개의 band를 사용한다. Tone mapper는 노출 시간, 화이트 밸런스, 센서 반응, 비네팅을 모델링하는 ADOP를 따른다.
5. Optimization Strategy
새로운 뷰를 합성하기 전에 렌더링 파이프라인이 입력 사진을 재현하도록 최적화된다. 이 최적화에는 포인트 위치, 크기, feature는 물론 카메라 모델과 포즈, 신경망 가중치, tone mapper 파라미터도 포함된다. 600 epochs 동안 학습하는데 장면 크기에 따라 수렴하는 데 2~4시간이 필요하다.
고품질 결과를 제공하는 것으로 알려진 VGG-loss를 사용한다. 그러나 VGG 네트워크는 평가 속도가 느린 경향이 있으므로 MSE loss에 비해 학습 시간이 크게 늘어난다. 따라서 VGG의 장점을 무시할 수 있는 처음 50 epochs에서 MSE와 SSIM의 조합을 사용한다. 이렇게 하면 학습 시간이 약 5% 단축된다.
저자들은 20 epochs의 “warm-up” 기간을 사용하였으며, 이 기간 동안 절반의 이미지 해상도로 학습된다. 그런 다음 각 epoch을 무작위로 확대 및 축소하여 모든 convolution이 최종 결과에 기여하도록 학습된다.
6. Implementation Details
렌더러는 collecting, splatting and accumulation의 세 단계로 구현된다. 비록 다른 SOTa 멀티레이어 블렌딩 전략과는 다르지만 이는 본 논문의 시나리오에서 가장 잘 작동한다. 먼저 각 포인트 $p_i$를 원하는 뷰에 투영하고 각 포인트의 $(x, y, z)$와 $s$를 버퍼에 수집하고 각 픽셀에 매핑된 element 수를 계산한다. 그런 다음 이 계산은 오프셋 스캔에 사용되어 결합된 모든 레이어에 연속적인 배열을 할당한다. 그런 다음 splatting pass는 각 포인트를 복제하고 각 픽셀 목록에 $(z,i)$ 쌍을 저장한다.
다음으로 하나로 결합된 sorting pass와 accumulation pass가 수행된다. 성능과 관련하여 이 부분은 매우 중요하다. 따라서 포인트를 혼합할 때 각 정렬된 목록에서 가장 앞에 있는 16개 element만 사용하도록 선택한다. 이후 포인트들의 혼합 기여도가 매우 낮기 때문에 이 근사치로 인한 품질 손실을 식별할 수 없다. 이러한 제한으로 인해 warp-local(thread 32개)과 셔플 기반 bitonic sort를 반복하고 목록이 빌 때까지 항상 후자의 16개 element들을 정렬되지 않은 새로운 element로 대체하므로 GPU 친화적인 정렬을 사용할 수 있다. Backward pass의 경우 정렬된 픽셀별 목록이 저장되어 있으므로 빠른 backpropagation이 가능하다. 모든 관련 element들이 이미 레지스터에 있기 때문에 앞에서 뒤로의 alpha-blending은 sorting pass와 동일한 pass에서 수행된다.
포인트 밀도의 편차가 큰 장면의 경우, 엣지 케이스에서 신경망이 가려진 부분을 올바르게 평가하지 못할 수 있다. 따라서 블렌딩 중에 더 coarse한 레이어의 포인트를 포함하는데, 이는 추가 비용은 매우 적다(< 0.5ms).
포인트 크기는 nearest neighbor 4개까지의 평균 거리로 초기화되며, 이는 학습 중에 효율적으로 최적화된다.
Evaluation
- 데이터셋
- Tanks&Temples, MipNeRF-360
- ADOP의 Boat와 Office (LiDAR 포인트 클라우드)
1. Quality Comparison
다음은 다른 방법들과 비교한 결과이다.


2. Ablation Studies
다음은 장면의 큰 구멍을 채우기 위해 포인트 크기를 최적화하는 것을 보여준다.

다음은 수렴한 포인트 클라우드에 잡음을 더하고 위치에 대한 최적화만 다시 수행할 때의 결과를 비교한 것이다.

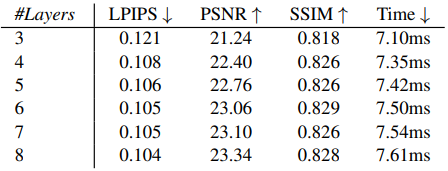
다음은 사용한 해상도 레이어의 수에 따른 성능을 비교한 표이다. (장면: HORSE)
다음은 뷰 의존성에 대한 ablation 결과이다.

다음은 포인트 당 feature 수에 따른 성능을 비교한 표이다. (장면: PLAYGROUND)
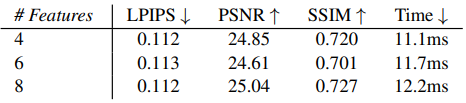
다음은 네트워크 구성에 대한 ablation 결과이다.
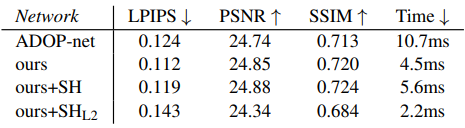
다음은 포인트 클라우드 수에 대한 효율성을 비교한 표이다.

3. Rendering Efficiency
다음은 학습 및 렌더링 시간을 다른 방법들과 비교한 표이다.

4. Outlier Robustness
다음은 outlier robustness를 다른 방법들과 비교한 것이다. (장면: FAMILY)

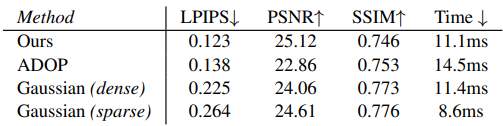
5. Comparison to Prior Work with Number of Points
다음은 이전 방법들과 성능을 비교한 표이다. Gaussian (dense)는 시작 포인트가 800만 개인 dense한 셋업이고 Gaussian (sparse)는 시작 포인트가 200만 개인 원래의 sparse한 셋업이다.

Limitations

- Gaussian Splatting과 달리 초기에 dense한 재구성을 가져야 한다는 전제 조건에서 발생하며, 이는 특정 시나리오에서는 실용적이지 않을 수 있다.
- 이방성(anisotropic) splat 공식이 부족하여 문제가 발생할 수 있다.
- 길고 가는 물체(ex. 기둥)의 강력한 구멍 채우기 작업을 수행할 때 실루엣 주변에 잡음이 있는 아티팩트가 관찰될 수 있다. 이에 대한 예시가 위 그림에 나와 있다. 이러한 경우 Gaussian Splatting이 선호되는 경우가 많다.
- 이전 포인트 렌더링 방식에 비해 시간적 일관성이 크게 향상되었음에도 불구하고 포인트가 너무 많거나 너무 적은 영역에서는 여전히 약간의 깜박임이 발생할 수 있다.