[논문리뷰] Track Anything: Segment Anything Meets Videos (TAM)
arXiv 2023. [Paper] [Github]
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, Feng Zheng
SUSTech VIP Lab
24 Apr 2023
Introduction
Video Object Tracking (VOT)는 컴퓨터 비전에서 근본적인 task이며, 일반적인 장면에서 임의의 객체를 추적하는 것이 중요하다. VOT와 유사하게 Video Object Segmentation (VOS)는 동영상 시퀀스에서 타겟(관심 영역)을 배경에서 분리하는 것을 목표로 하며, 이는 보다 세밀한 객체 추적으로 볼 수 있다. 저자들은 현재 state-of-the-art 동영상 trackers/segmenter가 수동으로 주석을 단 대규모 데이터셋에서 학습되고 boundary box 또는 segmentation mask로 초기화된다는 것을 확인했다. 한편으로 엄청난 양의 라벨이 붙은 데이터 뒤에는 막대한 노동력이 숨어 있다. 더욱이, 현재 초기화 세팅, 특히 semi-supervised VOS는 모델 초기화를 위해 특정 객체 마스크 ground-truth가 필요하다. 노동 비용이 많이 드는 주석 및 초기화에서 연구원을 벗어나게 하는 방법은 매우 중요하다.
최근에는 image segmentation을 위한 대규모 foundation model인 Segment-Anything Model (SAM)이 제안되었다. 유연한 프롬프트를 지원하고 마스크를 실시간으로 계산하므로 상호 작용이 가능하다. 저자들은 SAM이 상호 작용하는 추적을 지원할 수 있는 다음과 같은 이점이 있다고 결론지었다.
- 강력한 image segmentation 능력: 1,100만 개의 이미지와 11억 개의 마스크에 대해 학습된 SAM은 고품질 마스크를 생성하고 일반 시나리오에서 zero-shot segmentation을 수행할 수 있다.
- 다양한 종류의 프롬프트와의 높은 상호작용성: 사용자에게 친숙한 점, 상자 또는 언어 입력 프롬프트를 통해 SAM은 특정 이미지 영역에 만족스러운 segmentation mask를 제공할 수 있다.
그러나 동영상에서 직접 SAM을 사용하는 것은 시간적 correspondence가 부족하여 인상적인 성능을 제공하지 못했다.
반면 동영상의 tracking 또는 segmentation은 크기 변화, 대상 변형, 동작 흐림, 카메라 동작, 유사한 개체 등의 문제에 직면한다. State-of-the-art 모델조차도 실제 애플리케이션은 말할 것도 없고 공용 데이터셋의 복잡한 시나리오로 인해 어려움을 겪는다. 따라서 저자들은 다음과 같은 질문을 고려한다.
상호 작용 방식을 통해 동영상에서 고성능 tracking과 segmentation을 할 수 있는가?
본 논문에서는 동영상에서 고성능 객체 tracking 및 segmentation을 위한 효율적인 툴킷을 개발하는 Track-Anything 프로젝트를 소개한다. 사용자 친화적인 인터페이스를 갖춘 Track Anything Model (TAM)은 단 한 번의 inference로 주어진 동영상의 모든 개체를 추적하고 분할할 수 있다. 세부적으로 TAM은 대규모 segmentation model인 SAM과 고급 VOS 모델인 XMem을 상호 작용 방식으로 통합한다. 먼저, 사용자는 SAM을 상호 작용 방식으로 초기화할 수 있다. 즉, 개체를 클릭하여 대상 개체를 정의할 수 있다. 그런 다음 XMem은 시간적 및 공간적 correspondence에 따라 다음 프레임에서 객체의 마스크 예측을 제공하는 데 사용된다. 다음으로 SAM을 활용하여 보다 정확한 마스크 설명을 제공한다. Tracking 프로세스 중에 사용자는 tracking 실패를 발견하는 즉시 일시 중지하고 수정할 수 있다.
Track Anything Task
본 논문은 Segment Anything task에서 영감을 받아 임의의 동영상에서 유연한 객체 tracking을 목표로 하는 Track Anything task를 제안한다. 여기서 타겟 객체가 사용자의 관심에 따라 어떤 방식으로든 유연하게 선택, 추가 또는 제거될 수 있음을 정의한다. 또한 동영상 길이와 유형은 동영상에 제한되지 않고 임의적일 수 있다. 이러한 설정을 통해 단일/다중 객체 tracking, 단기/장기 객체 tracking, unsupervised VOS, semi-supervised VOS, referring VOS, interactive VOS, long-term VOS 등 다양한 하위 task를 수행할 수 있다.
Methodology
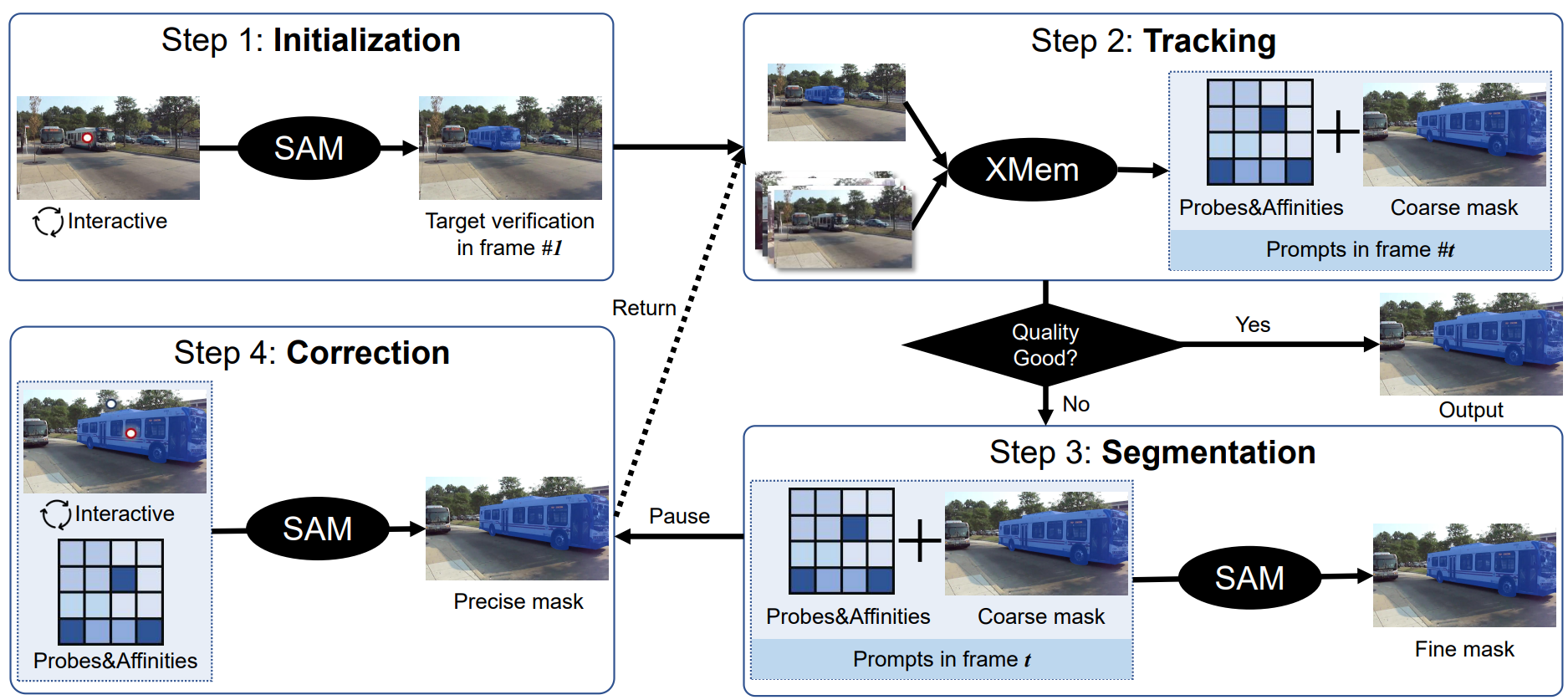
SAM에서 영감을 받아 동영상의 모든 것을 추적하는 것을 고려한다. 저자들은 높은 상호작용성과 사용 편의성으로 이 task를 정의하는 것을 목표로 하였다. 그것은 사용의 용이성으로 이어지며 인간의 상호 작용 노력이 거의 없이 높은 성능을 얻을 수 있다. 위 그림은 Track Anything Model (TAM)의 파이프라인을 보여준다. 그림과 같이 Track-Anything 프로세스를 다음 네 단계로 나눈다.
Step 1: Initialization with SAM
SAM은 약한 프롬프트(ex. 점과 boundary box)로 관심 영역을 분할할 수 있는 기회를 제공하므로 이를 사용하여 대상 개체의 초기 마스크를 제공한다. SAM에 이어 사용자는 클릭 한 번으로 관심 있는 개체의 마스크 설명을 얻거나 몇 번의 클릭으로 개체 마스크를 수정하여 만족스러운 초기화를 얻을 수 있다.
Step 2: Tracking with XMem
초기화된 마스크가 주어지면 XMem은 다음 프레임에서 semi-supervised VOS를 수행한다. XMem은 간단한 시나리오에서 만족스러운 결과를 출력할 수 있는 고급 VOS 방법이므로 대부분의 경우 XMem의 예측된 마스크를 출력한다. 마스크 품질이 좋지 않은 경우 XMem 예측과 해당 중간 파라미터(ex. probe, affinity)를 저장하고 Step 3로 건너뛴다.
Step 3: Refinement with SAM
VOS 모델을 inference하는 동안 일관되고 정확한 마스크를 계속 예측하는 것은 어렵다. 실제로 대부분의 state-of-the-art VOS 모델은 inference 중에 시간이 지남에 따라 점점 더 거칠게 segment되는 경향이 있다. 따라서 품질 평가가 만족스럽지 않을 때 SAM을 사용하여 XMem이 예측한 마스크를 개선한다. 구체적으로 probe와 affinity를 SAM에 대한 점 프롬프트로 예상하고 Step 2에서 예측된 마스크를 SAM에 대한 마스크 프롬프트로 사용한다. 그런 다음 이러한 프롬프트를 사용하여 SAM은 세밀한 segmentation mask를 생성할 수 있다. 이러한 정제된 마스크는 XMem의 시간적 correspondence에 추가되어 이후의 모든 객체 식별을 정제한다.
Step 4: Correction with human participation
위의 세 단계 후에 TAM은 이제 몇 가지 일반적인 문제를 성공적으로 해결하고 segmentation mask를 예측할 수 있다. 그러나 특히 긴 동영상을 처리할 때 일부 극도로 어려운 시나리오에서 개체를 정확하게 구별하는 것이 여전히 어렵다. 따라서 inference 중에 사람의 수정을 추가한다. 이는 아주 작은 사람의 노력만으로 성능의 질적 도약을 가져올 수 있다. 세부적으로 사용자는 TAM 프로세스를 강제로 중지하고 positive 및 negative click으로 현재 프레임의 마스크를 수정할 수 있다.
Experiments
1. Quantitative Results
TAM을 평가하기 위해 DAVIS-2016의 validation set과 DAVIS-2017의 test-development set를 활용한다. 결과는 아래 표와 같다.

TAM은 DAVIS-2016-val과 DAVIS-2017-test-dev 데이터셋에서 각각 88.4 및 73.1의 $J$&$F$ 점수를 얻었다. TAM은 클릭으로 초기화되고 한 번에 평가된다. 특히 TAM은 어렵고 복잡한 시나리오에 대해 잘 작동한다.
2. Qualitative Results
다음은 DAVIS-16과 DAVIS-17의 동영상 시퀀스에 대한 정성적 결과이다.

3. Applications
다음은 영화 ‘캡틴 아메리카 : 시빌 워’에 대한 실제 프레임, 객체 마스크, inpainting 결과이다.

4. Failed Cases
다음은 실패한 케이스의 예시이다.

전반적으로 실패한 케이스는 일반적으로 다음 두 경우에 나타난다.
- 현재 VOS 모델은 대부분 짧은 동영상용으로 설계되어 장기 기억보다 단기 기억 유지에 더 중점을 둔다. 이는 seq (a)에 표시된 것처럼 긴 동영상에서 마스크 축소 또는 개선 부족으로 이어진다. 본질적으로 SAM의 개선 능력으로 Step 3에서 이를 해결하는 것을 목표로 하지만 실제 적용에서는 그 효과가 예상보다 낮다. 인간의 참여/상호작용은 이러한 어려움을 해결하는 접근이 될 수 있지만 너무 많은 상호작용은 효율성을 떨어뜨리는 결과를 낳는다.
- 오브젝트 구조가 복잡한 경우, 예를 들어 seq (b)의 자전거 바퀴는 ground-truth 마스크에 많은 구멍을 포함한다. 클릭을 전파하여 세밀한 초기화 마스크를 얻는 것이 매우 어렵다. 따라서 대략적으로 초기화된 마스크는 후속 프레임에 부작용을 일으켜 잘못된 예측으로 이어질 수 있다. 이것은 또한 SAM이 여전히 복잡하고 정밀한 구조와 씨름하고 있음을 보여준다.