[논문리뷰] Tora: Trajectory-oriented Diffusion Transformer for Video Generation
CVPR 2025. [Paper] [Page] [Github]
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, Weizhi Wang
Alibaba Group | Fudan University
31 Jul 2024

Introduction
Diffusion model은 다양한 고품질의 이미지나 동영상을 생성하는 능력을 입증했다. 이전에 video diffusion model은 주로 U-Net 아키텍처를 사용하여 일반적으로 약 2초 정도의 제한된 길이의 동영상을 합성하는 데 중점을 두었으며 고정된 해상도와 종횡비로 제한되었다. 최근 Diffusion Transformer (DiT)를 활용하는 text-to-video 생성 모델인 Sora는 현재 SOTA 방법을 크게 능가하는 동영상 생성 능력을 선보였다. Sora는 10~60초 범위의 고품질 동영상을 제작하는 데 탁월할 뿐만 아니라 다양한 해상도, 다양한 종횡비, 실제 물리 법칙을 준수하는 능력을 통해 차별화된다.
동영상 생성에는 이미지 시퀀스 전체에서 일관된 모션이 필요하므로 모션 제어의 중요성이 강조된다. 이전 방법들의 유망한 제어 가능한 모션 품질에도 불구하고 U-Net 방법은 고정된 낮은 해상도에서 16프레임의 동영상만 생성하는 데 제한된다. 이러한 제한은 특히 제공된 궤적에서 상당한 위치 이동 중에 모션을 부드럽게 묘사하는 것을 방해하여 비자연스러운 움직임으로 이어져 실제 역학에서 벗어난다. 결과적으로 robust한 모작 제어 및 자세한 물리적 표현으로 더 긴 동영상을 제작할 수 있는 모델이 필요하다.
본 논문은 이러한 과제를 해결하기 위해 텍스트, 이미지, 궤적을 동시에 통합하여 견고한 모션 제어를 통해 확장 가능한 동영상 생성이 가능한 최초의 DiT 모델인 Tora를 제시하였다. 특히, Sora의 오픈소스 버전인 OpenSora를 기본 DiT 모델로 채택하였다. 모션 제어를 DiT 프레임워크의 확장성과 일치시키기 위해 두 가지 새로운 모듈을 제안하였다.
- Trajectory Extractor (TE): 임의의 궤적을 계층적 시공간 모션 패치로 변환
- Motion-guidance Fuser (MGF): 이러한 패치를 DiT 블록 내에서 원활하게 통합
TE는 flow 시각화 기술을 통해 궤적에 대한 위치 변위를 RGB 도메인으로 변환한다. 이러한 시각화된 변위는 산발적인 문제를 완화하기 위해 Gaussian filtering을 거친다. 그 후, 3D VAE는 궤적을 시공간 모션 latent 데이터로 인코딩하는데, 이는 동영상 패치와 동일한 latent space를 공유한다. 모션 latent 데이터는 경량 모듈을 통해 여러 레벨의 모션 조건으로 분해된다. VAE 아키텍처는 MAGVIT-v2에서 영감을 받았지만 codebook dependency를 포기하여 단순화되었다.
MGF는 adaptive normalization layer를 통합하여 여러 레벨의 모션 조건을 해당 DiT 블록에 주입한다. 여러 방법 중에서 adaptive normalization layer가 궤적을 따라 일관된 동영상을 생성하는 데 가장 효과적인 것으로 나타났다.
학습하는 동안, OpenSora의 워크플로를 조정하여 고품질 동영상-텍스트 쌍을 생성하고 궤적 추출을 위해 optical flow estimator를 활용한다. 또한 camera detector와 motion segmentor를 통합하여 카메라 모션이 지배적인 인스턴스를 필터링하여 특정 궤적 추적을 개선한다. 이 신중한 선택 프로세스를 통해 일관된 모션이 있는 63만개의 고품질 동영상 데이터셋이 생성되었다. T2I-Adapter와 같은 전략을 사용하여 TE, MGF와 함께 시간 블록만 학습시킨다. 이 전략은 DiT의 고유한 생성 지식을 외부 모션 신호와 완벽하게 통합한다.
Experiments
1. Tora
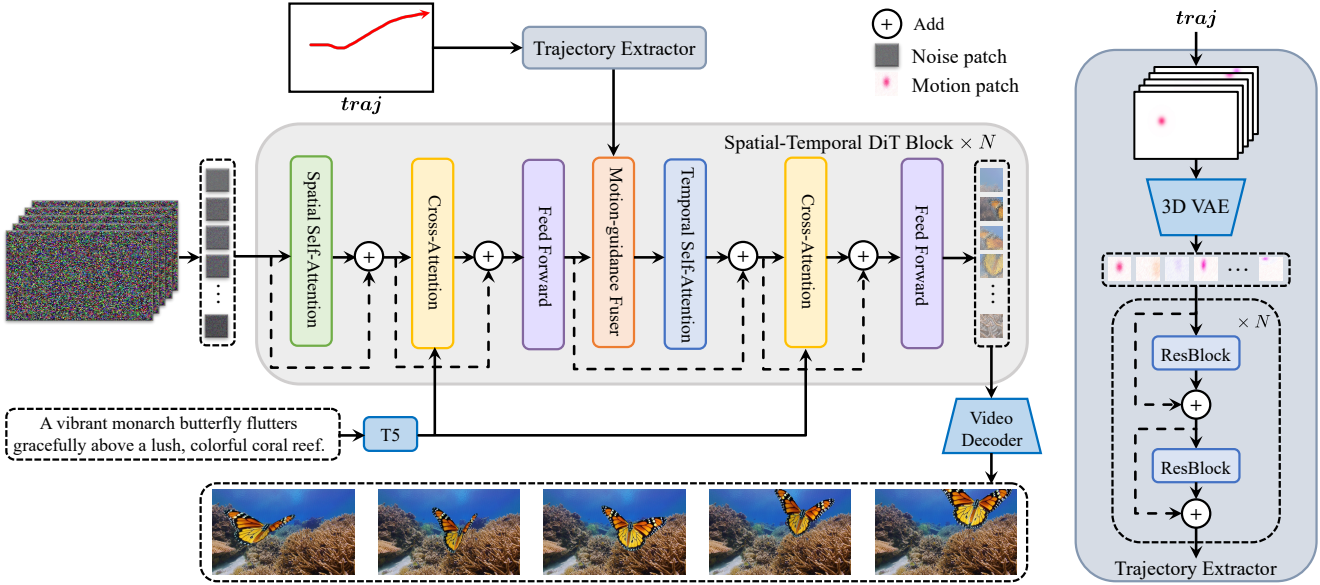
Tora는 OpenSora의 Spatial-Temporal Diffusion Transformer (ST-DiT)를 기본 모델로 사용한다. DiT의 확장성에 맞춰 사용자 친화적인 모션 제어를 위해 Tora는 두 가지 새로운 모션 처리 구성 요소인 Trajectory Extractor (TE)와 Motion-guidance Fuser (MGF)를 통합하였다.
Spatial-Temporal DiT
ST-DiT 아키텍처는 spatial DiT block (SDiT-B)과 temporal DiT block (T-DiT-B)을 교대로 배열하여 통합한다. S-DiT-B는 spatial self-attention (SSA)과 cross-attention을 순차적으로 수행하며, 그 뒤에 point-wise feed-forward layer가 인접한 T-DiT-B 블록을 연결한다. 특히, T-DiT-B는 SSA를 temporal self-attention(TSA)으로 대체하여 구조적 일관성을 유지한다. 각 블록 내에서 정규화를 거친 입력은 skip connection을 통해 블록의 출력으로 다시 연결된다. 가변 길이 시퀀스를 처리하는 능력을 활용하여 denoising ST-DiT는 가변 길이의 동영상을 처리할 수 있다.
동영상 오토인코더는 먼저 동영상의 공간적 차원과 시간적 차원을 모두 줄이는 데 사용된다. 입력 비디오 $X \in \mathbb{R}^{L \times H \times W \times 3}$을 video latent $z_0 \in \mathbb{R}^{l \times h \times w \times 4}$로 인코딩한다. 여기서 $l = \frac{L}{4}$, $h = \frac{H}{8}$, $w = \frac{W}{8}$이다. 다음으로 $z_0$는 patchify되어 입력 토큰의 시퀀스 $I \in \mathbb{R}^{l \times s \times d}$가 생성된다. 여기서 $s = \frac{hw}{p^2}$이고 $p$는 패치 크기이다. SSA와 TSA 모두에서 표준 attention은 query, key, value 행렬을 사용하여 수행된다.
\[\begin{equation} Q = W_Q \cdot I_\textrm{norm}, \quad K = W_K \cdot I_\textrm{norm}, \quad V = W_V \cdot I_\textrm{norm} \end{equation}\]여기서, \(I_\textrm{norm}\)은 정규화된 $I$이며, $W_Q$, $W_K$, $W_V$는 학습 가능한 행렬이다. 텍스트 프롬프트는 T5 인코더로 임베딩되며 cross-attention 메커니즘을 사용하여 통합된다.
Trajectory Extractor
궤적은 생성된 동영상의 모션을 제어하는 데 더 사용자 친화적인 방법으로 입증되었다. 구체적으로, 궤적 \(\textrm{traj} = \{(x_i, y_i)\}_{i=0}^{L-1}\)이 주어지며, 여기서 $(x_i, y_i)$는 궤적이 통과하는 $i$번째 프레임의 공간적 위치 $(x, y)$를 나타낸다. 이전 연구들은 주로 수평 offset $u(x_i, y_i)$와 수직 offset $v(x_i, y_i)$를 모션 조건으로 인코딩하였다.
\[\begin{equation} u (x_i, y_i) = x_{i+1} - x_i, \quad v (x_i, y_i) = y_{i+1} - y_i \end{equation}\]그러나 DiT 모델은 동영상을 패치로 변환한다. 여기서 각 패치는 여러 프레임에 걸쳐 파생되므로 프레임 간 offset을 직접 사용하는 것은 부적절하다.
이를 해결하기 위해 TE는 궤적을 동영상 패치와 동일한 latent space에 있는 모션 패치로 변환한다.
- $\textrm{traj}$를 궤적 맵 $g \in \mathbb{R}^{L \times H \times W \times 2}$로 변환한다. 첫 번째 프레임은 모든 값이 0이다.
- Scatter를 완화하기 위해 Gaussian filter로 강화한다.
- Flow 시각화 기술을 통해 궤적 맵 $g$를 RGB 색 공간으로 변환하여 $g_\textrm{vis} \in \mathbb{R}^{L \times H \times W \times 3}$를 생성한다.
- 3D VAE를 사용하여 궤적 맵을 압축한다. OpenSora 프레임워크와 일치하도록 공간적으로 8배, 시간적으로 4배 압축한다.
3D VAE는 MAGVIT-v2 아키텍처를 기반으로 하며, SDXL의 VAE로 공간 압축을 초기화하여 수렴을 가속화한다. 재구성 loss만을 사용하여 모델을 학습시켜 $g_\textrm{vis}$에서 컴팩트한 모션 latent 표현 $g_m \in \mathbb{R}^{l \times h \times w \times 4}$를 얻는다.
동영상 패치의 크기를 맞추기 위해 $g_m$에 동일한 패치 크기를 사용하고 일련의 convolutional layer를 사용하여 인코딩하여 시공간 모션 패치 $f \in \mathbb{R}^{l \times s \times d^\prime}$를 생성한다. 여기서 $d^\prime$은 모션 패치의 차원이다. 각 convolutional layer의 출력은 다음 레이어의 입력에 skip connection되어 multi-level motion feature를 추출한다.
\[\begin{equation} f_i = \textrm{Conv}^i (f_{i-1}) + f_{i-1} \end{equation}\]($f_i$는 $i$번째 ST-DiT 블록을 위한 모션 조건)
Motion-guidance Fuser
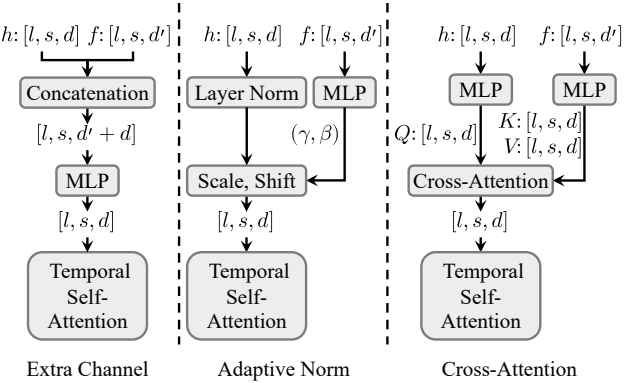
DiT 기반 동영상 생성을 궤적과 통합하기 위해, 저자들은 각 STDiT 블록에 모션 패치를 주입하는 퓨전 아키텍처의 세 가지 변형을 탐구하였다.
- 추가 채널 연결: $h_i = \textrm{Conv} ([h_{i-1}, f_i]) + h_{i-1}$
- Adaptive norm: $h_i = \gamma_i \cdot h_{i-1} + \beta_i + h_{i-1}$
- Cross-attention: $h_i = \textrm{CrossAttn}([h_{i-1}, f_i]) + h_{i-1}$
($h_i \in \mathbb{R}^{l \times s \times d}$는 ST-DiT의 $i$번째 블록의 출력)
저자들은 세 가지 유형의 퓨전 아키텍처를 평가하였고 adaptive norm이 가장 좋은 성능과 계산 효율성을 제공한다는 것을 발견했다.
2. Data Processing and Training Strategy
데이터 처리
저자들은 일관된 모션을 가진 고품질의 학습 동영상을 얻기 위해 구조화된 데이터 처리 방법을 사용하였다.
- PySceneDetect를 기반으로 동영상을 더 짧은 클립으로 분할한다.
- 인코딩 오류, 길이가 0인 동영상, 낮은 해상도 등 잘못된 동영상을 제거한다.
- 미적 점수와 optical flow 점수를 사용하여 품질이 낮은 동영상을 필터링한다.
- 주요 물체의 모션에 집중하기 위해 모션 분할 및 카메라 감지의 결과를 사용하여 카메라 모션 필터링을 구현하여 주로 카메라 움직임을 보이는 인스턴스를 제외한다.
특정 동영상에서 극적인 모션은 상당한 optical flow 편차로 이어질 수 있으며, 이는 궤적 학습을 방해할 수 있다. 이를 해결하기 위해 (1 - 점수/100)의 확률에 따라 이러한 동영상을 보관한다. 적합한 동영상의 경우 PLLaVA 모델을 사용하여 캡션을 생성한다. Inference 시에는 GPT4o로 프롬프트를 정제하여 학습 프로세스와 일치시킨다.
모션 조건 학습
저자들은 궤적 학습을 위해 2단계 학습 방식을 채택하였다. 첫 번째 단계에서는 학습 동영상에서 궤적으로 dense한 optical flow를 추출하여 모션 학습을 강화하기 위한 보다 풍부한 정보를 제공한다. 두 번째 단계에서는 motion segmentation의 결과와 optical flow 점수에 따라 1 ~ $N$개의 물체 궤적을 무작위로 선택하여 보다 사용자 친화적인 궤적으로 모델을 조정한다. Sparse한 궤적의 산발적 특성을 개선하기 위해 Gaussian filter를 적용한다.
이미지 조건 학습
OpenSora가 시각적 컨디셔닝을 지원하기 위해 사용하는 마스킹 전략을 따른다. 구체적으로, 학습 중에 프레임을 무작위로 마스킹하지 않고, 마스킹되지 않은 프레임의 동영상 패치는 어떠한 noise에도 노출되지 않는다. 이를 통해 Tora 모델은 텍스트, 이미지, 궤적을 통합된 모델로 원활하게 통합할 수 있다.
Experiments
- 데이터셋: Panda-70M, Mixkit, 내부 동영상들
- 구현 디테일
- OpenSora v1.2로 초기화
- 해상도: 144p ~ 720p
- 프레임 수: 51 ~ 204
- optimizer: Adam
- batch size: 1 ~ 50
- learning rate: $2 \times 10^{-5}$
- GPU: NVIDIA A100 4개
1. Results
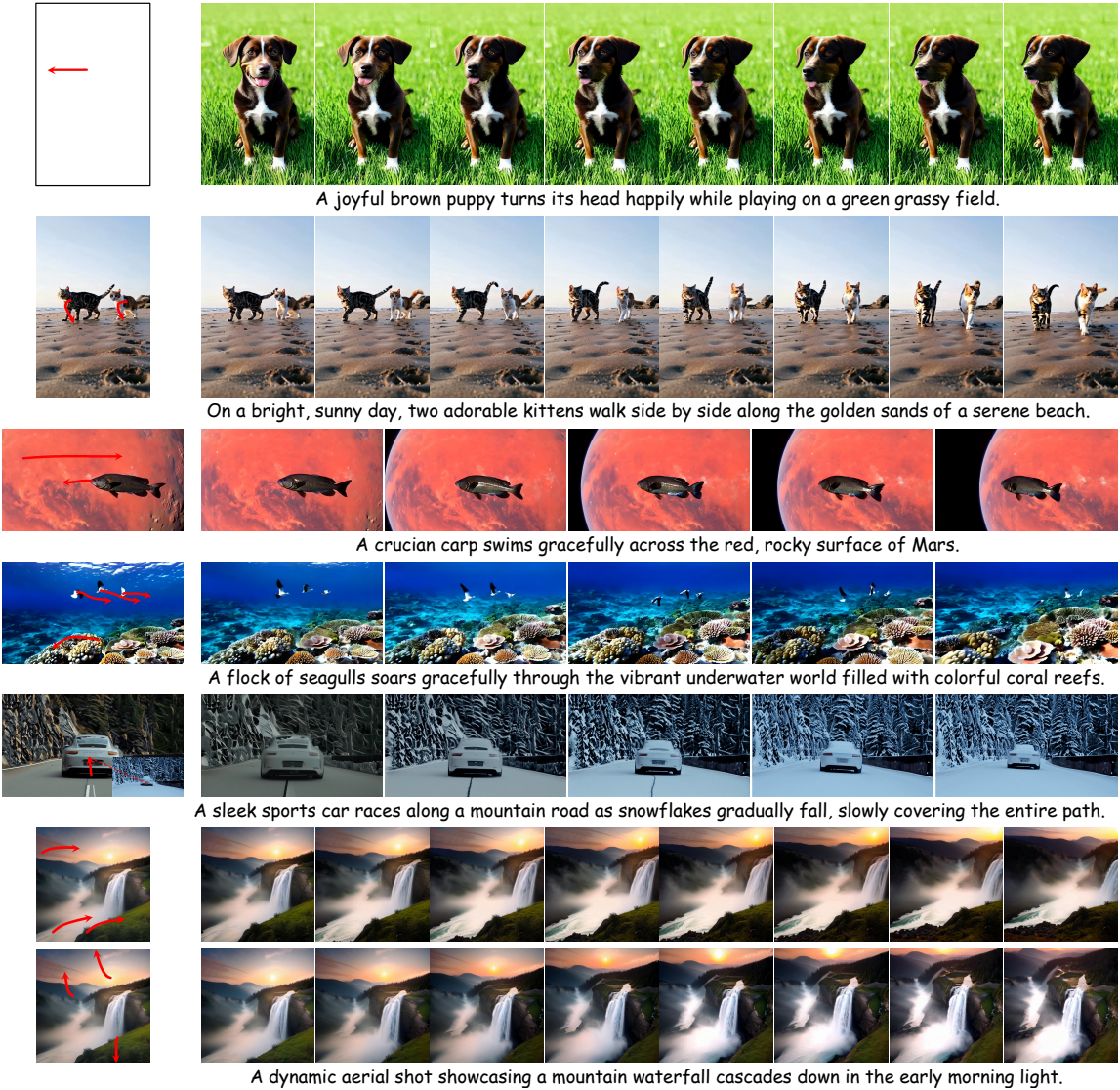
다음은 생성 예시들이다.
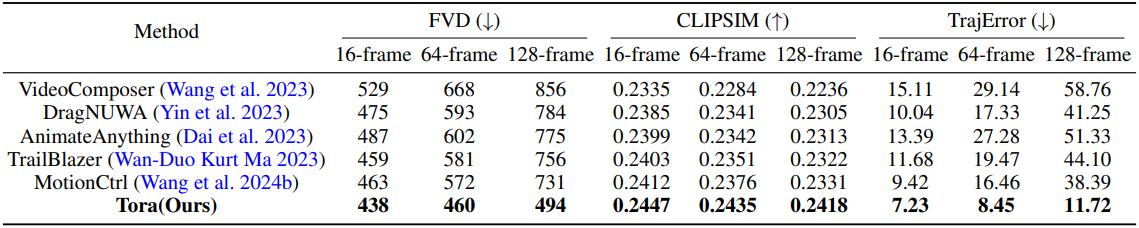
다음은 모션을 제어 가능한 동영상 생성 모델들과 성능을 비교한 표이다.
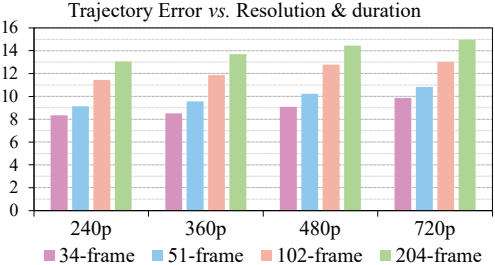
다음은 동영상의 해상도와 길이에 따른 궤적 오차를 비교한 그래프이다.
다음은 궤적 제어 결과를 비교한 것이다.

2. Ablation study
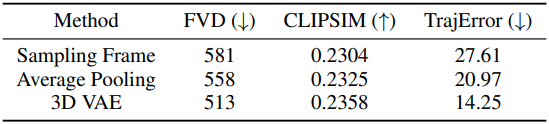
다음은 궤적 압축 방법에 대한 ablation 결과이다.
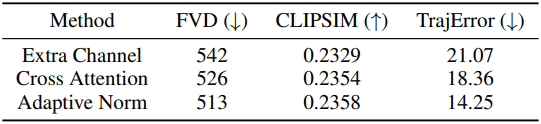
다음은 MGF의 motion fusion block에 대한 ablation 결과이다.
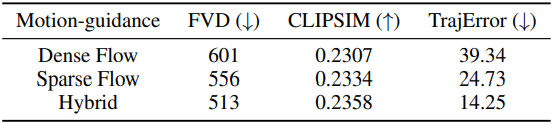
다음은 학습 궤적에 대한 ablation 결과이다.