[논문리뷰] Token Merging for Fast Stable Diffusion
arXiv 2023. [Paper] [Github]
Daniel Bolya, Judy Hoffman
Georgia Tech
30 Mar 2023
Introduction
DALL-E 2, Imagen, Stable Diffusion과 같은 강력한 diffusion model의 등장으로 고품질 이미지 생성이 그 어느 때보다 쉬워졌다. 그러나 이러한 모델을 실행하면 특히 큰 이미지의 경우 비용이 많이 들 수 있다. 이러한 모든 방법은 Transformer backbone의 여러 평가를 통해 이미지의 noise를 제거하여 작동한다. 즉, 계산이 토큰 수의 제곱(따라서 픽셀의 제곱)으로 확장된다.
Transformer 속도를 높이는 몇 가지 기존 방법이 Stable Diffusion과 같은 오픈 소스 diffusion model에 이미 성공적으로 적용되었다. Flash Attention은 메모리 대역폭을 영리하게 설정하여 attention을 효율적으로 계산한다. XFormers에는 여러 가지 최적화된 Transformer 구성 요소 구현이 포함되어 있다. 그리고 PyTorch 2.0부터는 이러한 최적화를 기본적으로 사용할 수 있다.
그러나 이러한 접근 방식 중 어느 것도 필요한 작업량을 줄이지 않으며, 여전히 모든 토큰에서 Transformer를 평가한다. 대부분의 이미지는 중복성이 높기 때문에 모든 토큰에 대해 계산을 수행하는 것은 리소스 낭비이다. Token pruning과 token merging과 같은 토큰 감소에 대한 최근 연구들은 Transformer에서 이러한 중복 토큰을 제거하여 약간의 정확도 저하로 평가 속도를 높일 수 있는 능력을 보여주었다. 이러한 방법의 대부분은 모델을 재학습해야 하지만 Token Merging(ToMe)은 특히 추가 학습이 필요하지 않다는 점에서 두드러진다.
본 논문에서는 ToMe를 Stable Diffusion에 적용하여 테스트했다. 기본적으로 naive한 애플리케이션은 diffusion 속도를 최대 2배까지 높이고 메모리 소비를 4배까지 줄일 수 있지만, 그 결과 이미지 품질이 크게 저하된다. 이를 해결하기 위해 토큰 분할을 위한 새로운 기술을 도입하고 ToMe를 적용하는 방법을 결정하기 위해 여러 실험을 수행한다. 그 결과 원래 모델에 매우 가까운 이미지를 생성하면서 ToMe의 속도를 유지하고 메모리 이점을 개선할 수 있다.
Background
본 논문의 목표는 ToMe를 사용하여 재학습 없이 Stable Diffusion 모델의 속도를 높이는 것이다.
Stable Diffusion
Diffusion model은 여러 diffusion step에서 일부 초기 noise를 반복적으로 제거하여 이미지를 생성한다. 대부분의 최신 대형 diffusion model과 마찬가지로 Stable Diffusion은 Transformer 기반 블록이 있는 U-Net을 사용한다. 따라서 먼저 noise가 있는 이미지를 토큰 집합으로 인코딩한 다음 일련의 Transformer 블록을 통해 전달한다. 각 Transformer 블록에는 표준 self-attention 및 MLP 모듈이 있으며, 프롬프트 조건에 cross-attention 모듈이 추가된다.
Token Merging
Token Merging (ToMe)은 각 블록에서 r 토큰을 병합하여 변환기의 토큰 수를 점진적으로 줄인다. 이를 효율적으로 수행하기 위해 토큰을 source (src)와 destination(dst) 세트로 분할한다. 그런 다음 src에서 가장 유사한 $r$개 토큰을 dst로 병합하여 토큰 수를 $r$만큼 줄여 다음 블록을 더 빠르게 만든다.
Token Merging for Stable Diffusion
ToMe는 classification에 잘 작동하지만 diffusion과 같은 dense prediction task에 적용하는 것은 완전히 간단하지 않다. 분류는 예측을 위해 단일 토큰만 필요하지만 diffusion은 모든 토큰에 대해 제거할 noise를 알아야 한다. 따라서 병합 해제(Unmerging)의 개념을 도입해야 한다.
1. Defining Unmerging
Token pruning과 같은 다른 토큰 감소 방법은 토큰을 제거하지만 ToMe는 이를 병합한다는 점에서 다르다. 그리고 병합한 토큰에 대한 정보가 있으면 동일한 토큰을 병합 해제할 수 있는 충분한 정보가 있다. 이는 모든 토큰이 실제로 필요한 dense prediction task에 매우 중요하다.
본 논문에서는 가장 간단한 방법으로 병합 해제를 정의한다. $x_1 \approx x_2$인 $c$ 채널의 두 개의 토큰 $x_1, x_2 \in \mathbb{R}^{c}$이 주어진다고 하자. 예를 들어 다음과 같이 단일 토큰 $x_{1,2}^\ast$로 병합하는 경우,
\[\begin{equation} x_{1,2}^\ast = \frac{x_1 + x_2}{2} \end{equation}\]$x’_1$와 $x’_2$로 다시 병합 해제할 수 있다.
\[\begin{equation} x'_1 = x_{1,2}^\ast, \quad x'_2 = x_{1,2}^\ast \end{equation}\]이것은 정보를 잃어버리지만 토큰은 이미 비슷했기 때문에 오차가 작다. 이 방법이 잘 작동하지만 다른 병합 해제 방법을 탐색할 가치가 있을 수 있다.
2. An Initial Naive Approach
토큰을 병합한 다음 즉시 병합 해제해도 도움이 되지 않는다. 그 대신 토큰을 병합하고 일부 계산을 수행한 다음 토큰을 잃지 않도록 나중에 병합을 해제한다. 간단하게, 각 블록의 각 구성 요소 전에 ToMe를 적용한 다음 skip connection을 추가하기 전에 출력을 병합 해제할 수 있다. (아래 그림 참조)
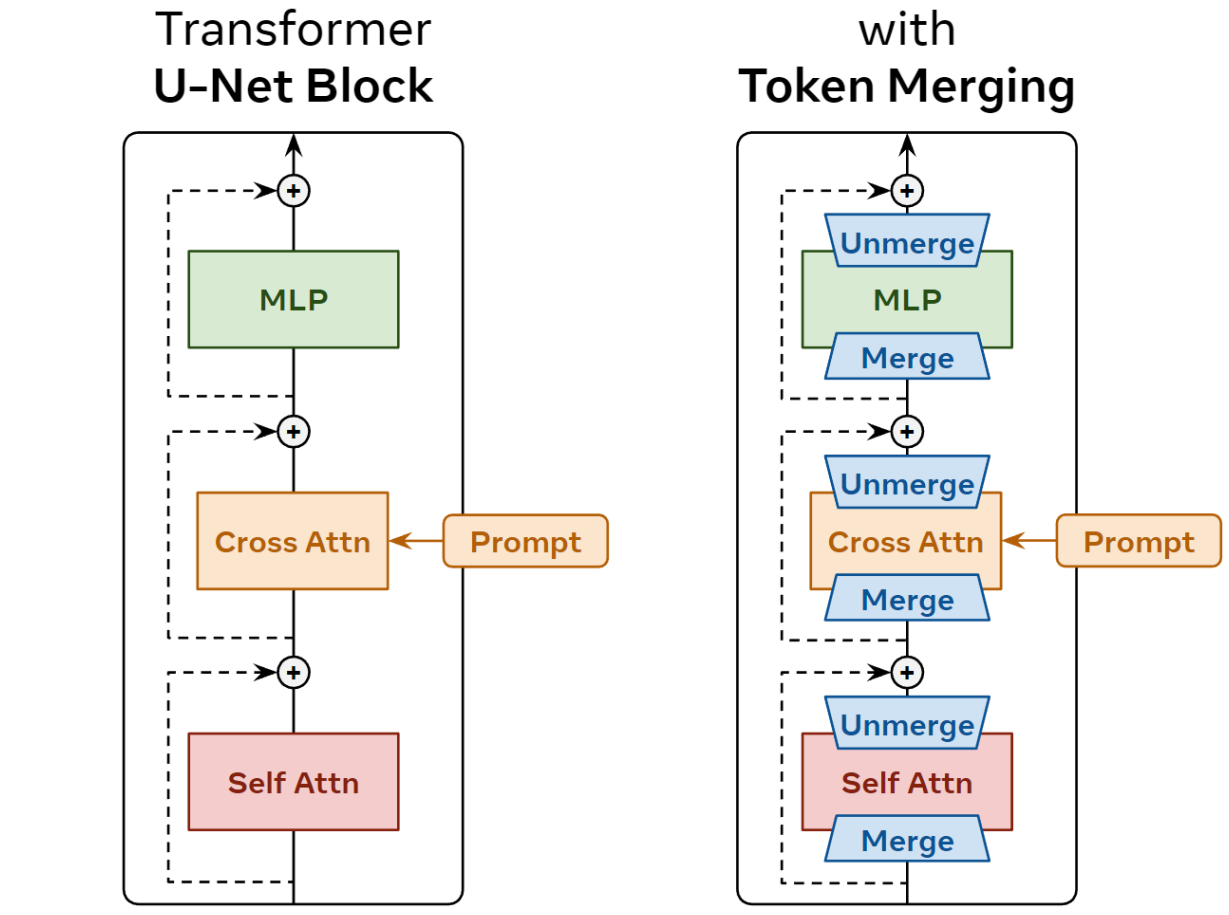
Details
토큰 감소를 누적하지 않기 때문에(병합된 토큰은 빠르게 병합 해제됨) 원래 ToMe보다 훨씬 더 많이 병합해야 한다. 따라서 토큰의 수량 $r$을 제거하는 대신 모든 토큰의 $r$%를 제거한다. 또한 병합을 위한 토큰 유사성 계산은 비용이 많이 들기 때문에 각 블록 시작 시 한 번만 수행한다. 마지막으로, 비례적인 attention을 사용하지 않고 attention key $k$ 대신 유사하게 블록 $x$에 대한 입력을 사용한다.
Further Exploration
다음은 naive한 접근 방식의 정성적 결과이다.

다음은 naive한 접근 방식의 정량적 결과이다.
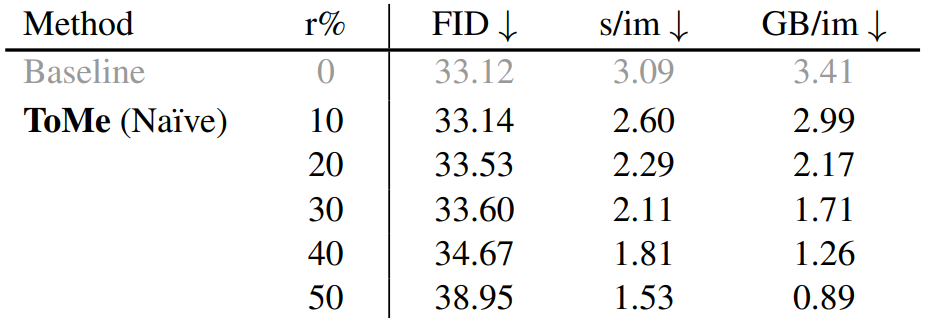
놀랍게도 앞서 언급한 간단한 접근 방식은 많은 양의 토큰 감소에 대해서도 학습 없이도 즉시 사용할 수 있다.
다음은 token pruning과 Token Merging을 비교한 것이다.

단순히 토큰을 잘라내면 결과 이미지가 급격히 손상된다.
ToMe가 적용된 이미지는 괜찮아 보이지만 각 이미지의 콘텐츠는 크게 변경된다. 따라서 Naive ToMe를 시작점으로 50% 감소를 사용하여 추가 개선을 수행한다.
1. A New Partitioning Method
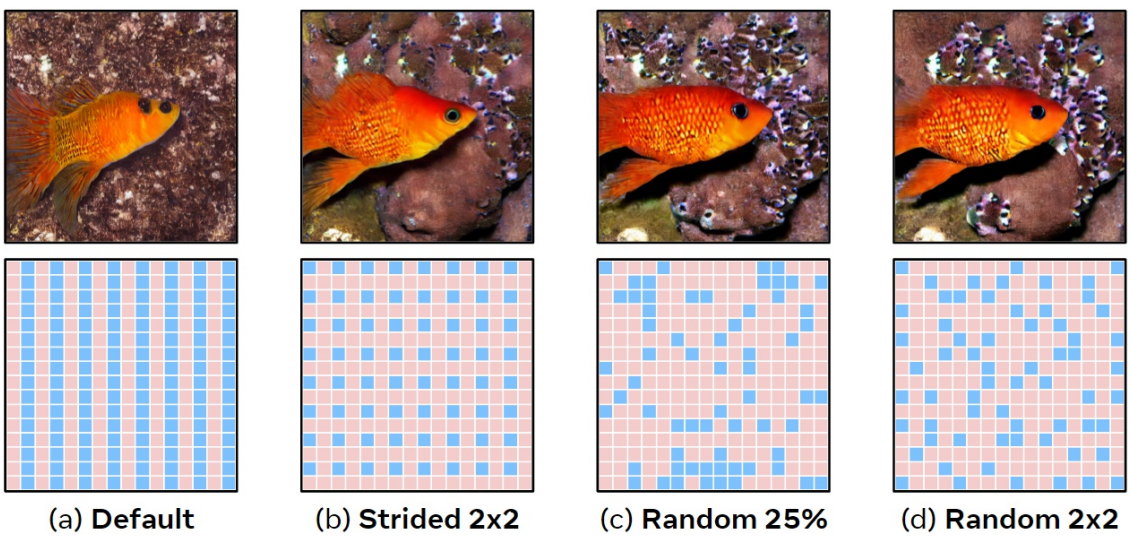
Default(a)의 경우 ToMe는 둘 사이를 번갈아 가며 토큰을 src와 dst로 분할한다. 이것은 병합되지 않은 ViT에 대해 작동하지만 Stable Diffusion의 경우에는 이로 인해 src와 dst가 교대로 열을 형성하게 된다. 모든 토큰의 절반이 src에 있으므로 모든 토큰의 50%를 병합하면 src 전체가 dst로 병합되므로 행을 따라 이미지의 해상도를 효과적으로 절반으로 줄인다.
간단한 수정은 일부 2d stride로 dst에 대한 토큰을 선택하는 것이다. 이는 이미지를 질적으로 양적으로 크게 개선하고 원하는 경우 더 많은 토큰을 병합할 수 있는 기능을 제공하지만 dst 토큰은 여전히 같은 위치에 있다. stride에 따른 성능 변화는 아래 표와 같다.
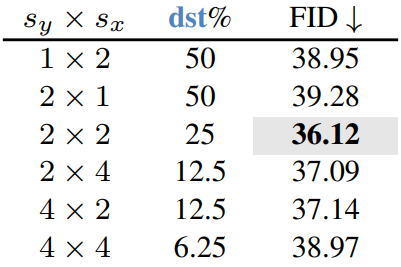
이를 해결하기 위해 랜덤성을 도입할 수 있다. 그러나 dst를 임의로 샘플링하면 FID가 엄청나게 증가한다 (아래 표의 w/o fix). 결정적으로 classifier-free guidance를 사용할 때 프롬프트된 샘플과 프롬프트되지 않은 샘플은 동일한 방식으로 dst 토큰을 할당해야 한다. 배치 전체에서 임의성을 수정하여 이 문제를 해결하고 2d stride를 사용하여 과거의 결과를 개선한다 (위 그림의 (c), 아래 표의 w/ fix). 각 2$\times$$2 영역에서 하나의 dst 토큰을 무작위로 선택하여 두 가지 방법을 결합하면 훨씬 더 잘 수행되므로 (위 그림의 (d)) 앞으로 이를 기본값으로 설정한다.

2. Design Experiments
무엇에 ToMe를 적용해야 하는가?
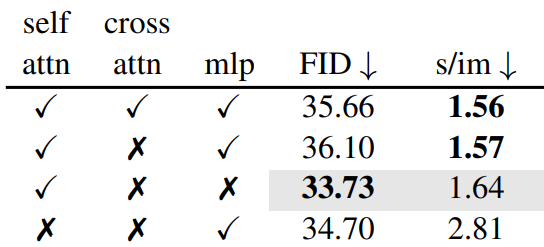
속도와 FID trade-off 측면에서 ToMe를 self attention에 적용하는 것이 확실한 승자이다. FID는 프롬프트 준수를 고려하지 않으므로 cross attention 모듈을 병합하면 실제로 FID가 감소한다.
어디에 ToMe를 적용해야 하는가?
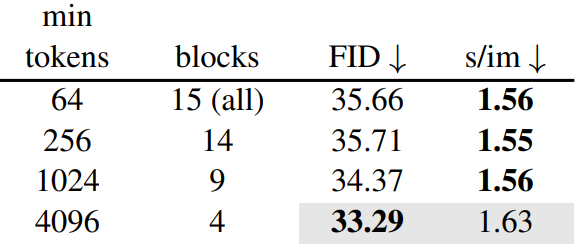
대부분의 토큰을 가진 블록에만 ToMe를 적용하면 대부분의 속도 향상을 얻을 수 있다.
언제 ToMe를 적용해야 하는가?
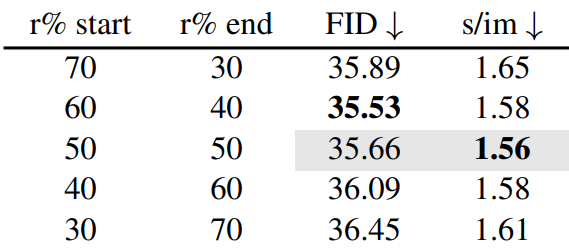
더 많은 토큰을 더 일찍 병합하고 나중에 더 적은 토큰을 병합하는 것이 약간 더 좋지만 가치가 충분하지 않다.
Putting It All Together
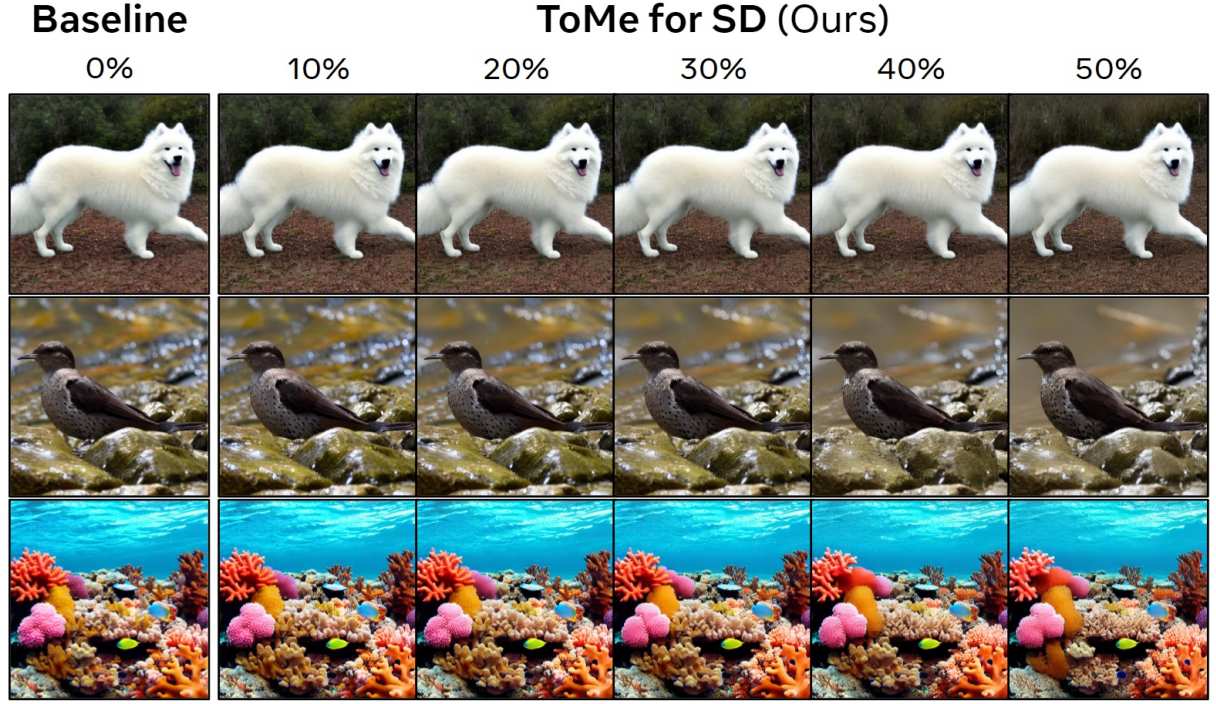
다음은 최종 버전의 정성적 결과이다.
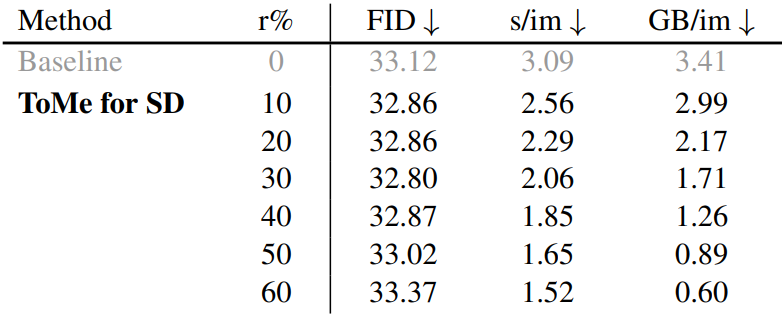
다음은 최종 버전의 정량적 결과이다.
ToMe + xFormers

ToMe는 토큰 수를 줄이기만 하므로 기존 고속 Transformer를 사용하여 위 그림과 같이 더 많은 이점을 얻을 수 있다.

더 많은 시각적 품질을 희생해도 괜찮다면 위 그림과 같이 속도를 더 높일 수 있다. 이미지가 작을수록 이 속도 향상이 덜 뚜렷하다. 또한 메모리 이점은 xFormers와 겹치지 않는다.