[논문리뷰] TokenCompose: Grounding Diffusion with Token-level Supervision
CVPR 2024. [Paper] [Page] [Github]
Zirui Wang, Zhizhou Sha, Zheng Ding, Yilin Wang, Zhuowen Tu
Princeton University | Tsinghua University | University of California, San Diego
6 Dec 2023

Introduction
최근 text-to-image (T2I) diffusion model의 엄청난 발전에도 불구하고 텍스트 프롬프트와 생성된 이미지 콘텐츠 사이에는 여전히 일관성 문제가 존재한다. 특히 현실에서 일반적으로 동시에 나타나지 않는 카테고리가 텍스트 프롬프트에 포함되면 모델의 합성 능력이 떨어지며, 개체가 이미지에 나타나지 않거나 합성 결과가 보기에 좋지 않을 수 있다.
생성 모델에 조건부 학습 신호를 추가하면 모델링 능력과 적용 범위가 크게 확장된다. Latent diffusion model (LDM)의 맥락에서 가장 일반적으로 적용되는 조건 중 하나인 텍스트는 cross-attention을 통해 denoising U-Net의 레이어에 주입된다.
그러나 diffusion model을 학습시키는 데 사용되는 텍스트인 캡션과 생성에 사용되는 텍스트인 프롬프트 간에는 자연스러운 불일치가 존재한다. 캡션은 일반적으로 실제 이미지를 충실하게 설명하는 반면, 프롬프트는 실제 이미지의 시각적 장면과 일치하지 않는 이미지 feature를 캡슐화할 수 있다. 조건부 텍스트에 대한 세분화된 목적 함수가 없으면 T2I diffusion model이 프롬프트에 있는 임의의 구성으로 일반화되지 못하는 경우가 많다. 이는 T2I LDM의 denoising 목적 함수가 텍스트 프롬프트에 대한 noise를 예측하는 데에만 최적화되어 텍스트 조건을 denoising 기능 최적화를 촉진하는 용도로만 남겨두기 때문일 수 있다.
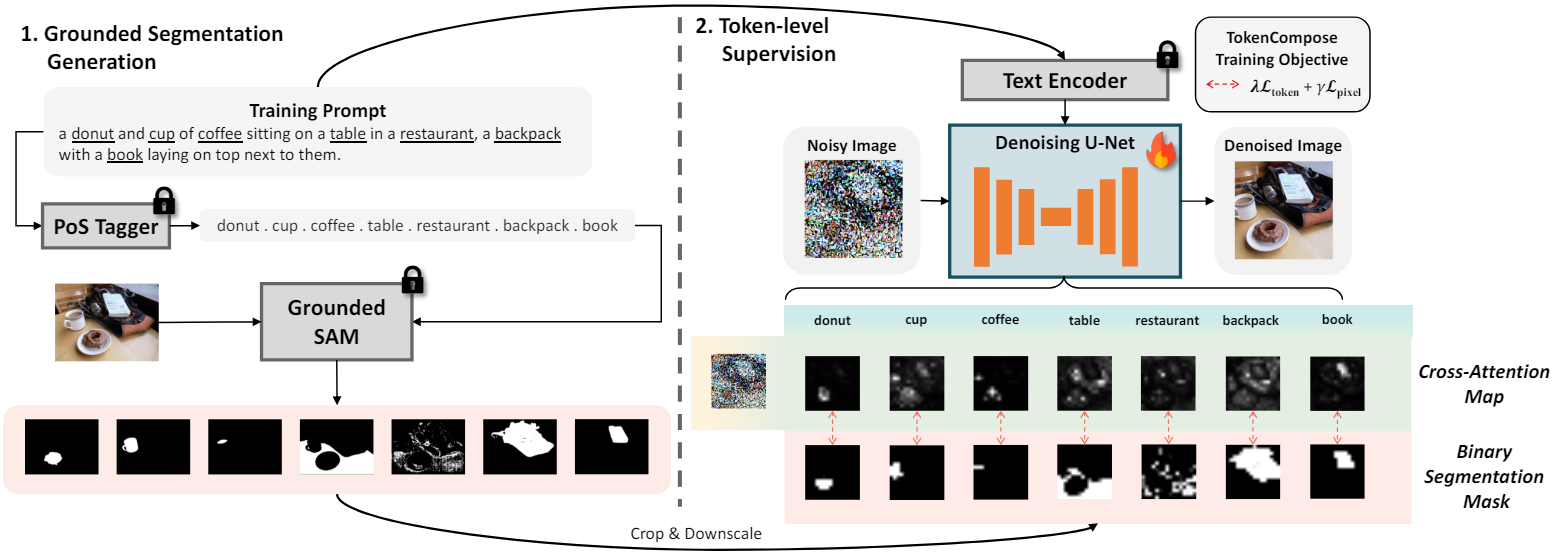
Diffusion model은 조건부 텍스트의 토큰 수준에서 작동하는 목적 함수를 부과함으로써 텍스트의 각 토큰이 이미지의 맥락에서 무엇을 의미하는지를 개별적으로 학습한다. 결과적으로 inference 중에 단어, 구문 등의 다양한 조합을 합성하는 것이 더 나을 수 있다. 그러나 해당 텍스트 토큰에 대해 인간이 segmentation map과 같은 ground-truth 레이블을 얻는 것은 비용이 많이 든다. 특히 대규모 생성 모델을 학습시키는 데 사용되는 텍스트-이미지 쌍의 경우 더욱 그렇다. 최근 vision foundation model인 Grounding DINO나 Segment Anything (SAM) 덕분에 텍스트 토큰에 대한 segmentation map을 자동으로 쉽게 얻을 수 있다.
본 논문은 이미지 이해를 위해 사전 학습된 foundation model을 활용하여 T2I 생성 모델에 토큰 수준 supervision을 제공하는 새로운 알고리즘인 TokenCompose를 개발하여 합성 문제를 완화하려고 하였다. 학습 중 해당 이미지에 대한 segmentation 기반 목적 함수를 사용하여 T2I 모델의 텍스트 프롬프트에서 각 명사 토큰을 보강하였다. 이를 통해 모델이 개체 정확도, 다중 카테고리 인스턴스 합성, 향상된 포토리얼리즘의 상당한 개선을 나타낼 수 있으며 생성된 이미지에 대한 추가 inference 비용이 없다. 추가로 저자들은 하나의 이미지에서 여러 카테고리의 인스턴스를 합성하는 T2I 생성 모델의 기능을 검사하는 MultiGen 벤치마크도 제시하였다.
Method
1. Token-level Attention Loss
길이가 $L_{\tau_\theta (y)}$인 텍스트 임베딩으로 변환되는 텍스트 프롬프트를 생각해 보자. Denoising 목적 함수인 \(\mathcal{L}_\textrm{LDM}\)은 noise를 예측하여 latent 이미지를 재구성하도록 함수를 최적화하기만 하므로 각 토큰의 임베딩 $e_i$와 noisy한 이미지 latent $z_t$는 명시적으로 최적화되지 않는다. 이로 인해 LDM에서 토큰 수준의 이해가 부족해지며, 이는 토큰 임베딩 $K \in \mathbb{R}^{H \times L_{\tau_\theta (y)} \times d_k}$과 noisy image latent $Q \in \mathbb{R}^{H \times L_{z_t} \times d_k}$ 사이의 multi-head cross-attention map의 activation을 통해 시각화될 수 있다. 각 cross-attention layer $m \in M$에 대한 cross-attention map $\mathcal{A} \in \mathbb{R}^{L_{z_t} \times L_{\tau_\theta (y)}}$는 다음과 같이 계산된다.
\[\begin{equation} Q^{(h)} = W_Q^{(h)} \cdot \phi (z_t), \quad K^{(h)} = W_K^{(h)} \cdot \tau_\theta (y) \\ \mathcal{A} = \frac{1}{H} \sum_{h=1}^H \textrm{softmax} \bigg( \frac{Q^{(h)} (K^{(h)})^\top}{\sqrt{d_k}} \bigg) \end{equation}\]여기서 $h$는 multi-head cross-attention의 각 head를 나타내고, $\phi$는 2차원 이미지 latent를 1차원으로 flatten하는 함수이다.
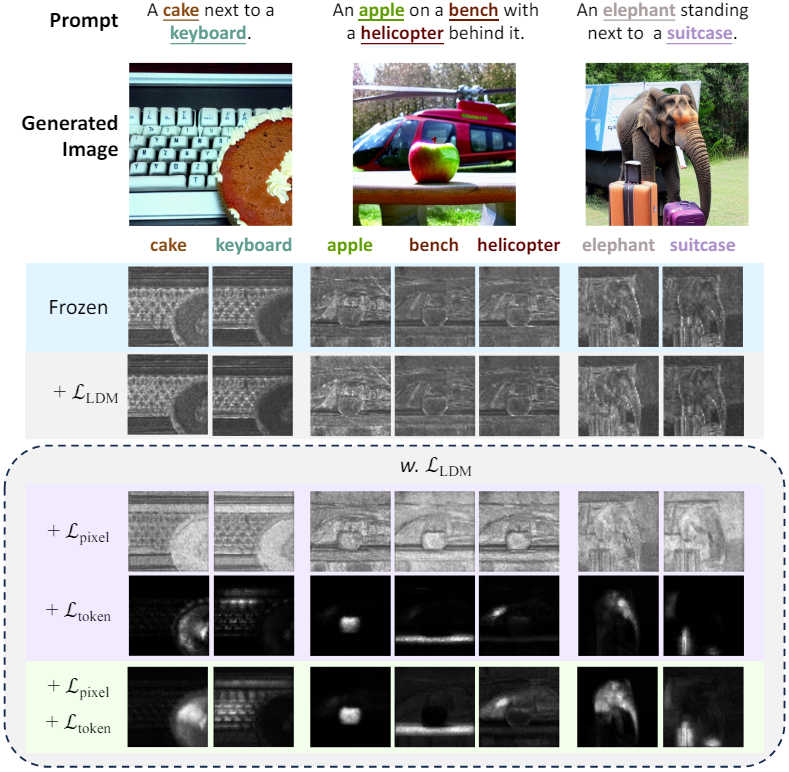
저자들은 \(\mathcal{L}_\textrm{LDM}\)만 사용하여 diffusion model을 학습시키면 개별 인스턴스 토큰의 cross-attention map activation이 이미지에 나타나는 해당 인스턴스에 초점을 맞추지 못하고 결과적으로 inference 중에 다중 인스턴스 합성 능력이 저하되는 경우가 많다는 것을 관찰했다. 이 문제를 완화하기 위해 cross-attention map의 activation 영역을 supervise하는 학습 제약 조건을 추가한다.
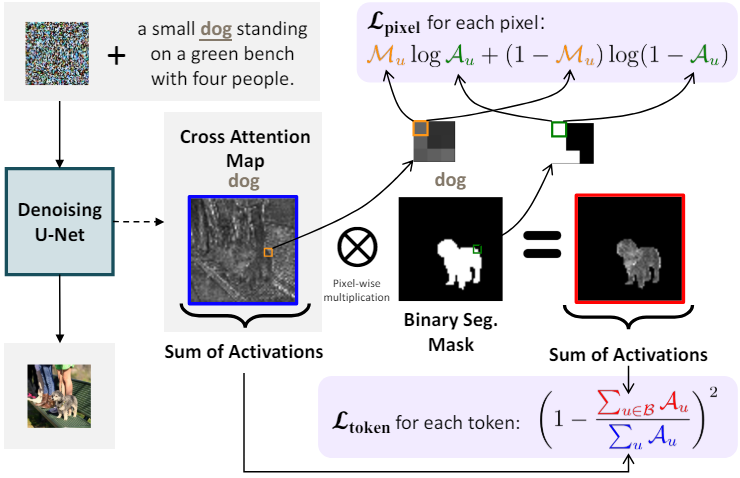
텍스트 캡션 내의 명사에 속하는 각 텍스트 토큰 $i$에 대해 이미지 이해를 위해 학습된 foundation model을 활용하여 해당 이미지에서 바이너리 segmentation map \(\mathcal{M}_i\)를 획득한다. U-Net의 각 레이어 $m$에 있는 cross-attention map은 해상도가 다르기 때문에 해상도를 bilinear interpolation으로 축소하여 \(\mathcal{A}_i^{(m)}\)의 차원과 일치시킨 다음 모든 값을 이진화하여 \(\mathcal{M}_i^{(m)}\)을 만든다. \(\mathcal{L}_\textrm{LDM}\)에 추가로 예측된 공간 영역 \(\mathcal{B}_i = \{u \in \mathcal{M}_i \vert u = 1\}\)에 대한 cross-attention activation을 집계하는 loss function \(\mathcal{L}_\textrm{token}\)을 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{token} = \frac{1}{N} \sum_{i=1}^N \bigg( 1 - \frac{\sum_{u \in \mathcal{B}_i}^{L_{z_t}} \mathcal{A}_{(i,u)}}{\sum_u^{L_{z_t}} \mathcal{A}_{(i,u)}} \bigg) \end{equation}\]여기서 \(\mathcal{A} (i,u) \in \mathbb{R}\)은 latent 토큰과 $i$번째 토큰의 임베딩에 의해 형성된 cross-attention map \(\mathcal{A}_i \in \mathbb{R}^{L_{z_t}}\)의 공간 위치 $u$에서의 스칼라 attention activation이다. 모든 head에 대한 평균으로 loss를 계산하며, 이 접근 방식이 cross-attention map의 개별 영역에서 서로 다른 head를 활성화하도록 장려하여 합성 성능과 이미지 품질을 약간 향상시킨다고 한다.
2. Pixel-level Attention Loss
\(\mathcal{L}_\textrm{token}\)의 부작용은 모델이 cross-attention map의 activation을 대상 영역의 특정 하위 영역으로 과도하게 집계하는 경향이 있다는 것이다. 이 문제를 극복하기 위해 \(\mathcal{L}_\textrm{pixel}\)을 사용한다. \(\mathcal{L}_\textrm{token}\)으로 최적화된 모든 레이어 $m$의 cross-attention map $\mathcal{A}$에 대해 다음과 같은 픽셀 레벨 cross-entropy loss를 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{pixel} = - \frac{1}{L_{\tau_\theta (y)} L_{z_t}} \sum_i^{L_{\tau_\theta (y)}} \sum_u^{L_{z_t}} (\mathcal{M}_{(i,u)} \log (\mathcal{A}_{(i,u)})) + (1 - \mathcal{M}_{(i,u)}) \log (1 - \mathcal{A}_{(i,u)}) \end{equation}\]Scaling factor $\lambda$를 \(\mathcal{L}_\textrm{token}\)에 곱해주어 \(\mathcal{L}_\textrm{LLM}\)을 최소한으로 손상시키면서 충분한 토큰 레벨 기울기를 사용하여 토큰 이미지 일관성을 최적화할 수 있도록 한다. 또한 최적화 과정에서 \(\mathcal{L}_\textrm{pixel}\)이 대략 일정하게 유지되도록 scaling factor $\gamma$를 추가한다. 전체 loss function은 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{TokenCompose} = \mathcal{L}_\textrm{LDM} + \sum_m^M ( \lambda \mathcal{L}_\textrm{token}^{(m)} + \gamma \mathcal{L}_\textrm{pixel}^{(m)}) \end{equation}\]전체 학습 파이프라인은 아래와 같다.
Experiments
- 구현 디테일
- base model: Stable Diffusion v1.4 / v2.1
- optimizer: AdamW
- learning rate: $5 \times 10^{-6}$
- iteration: v1.4는 24,000 / v2.1은 32,000
- batch size: 1
- gradient accumulation step: 4
- U-Net의 인코더에는 \(\mathcal{L}_\textrm{token}\)와 \(\mathcal{L}_\textrm{pixel}\)을 적용하지 않음
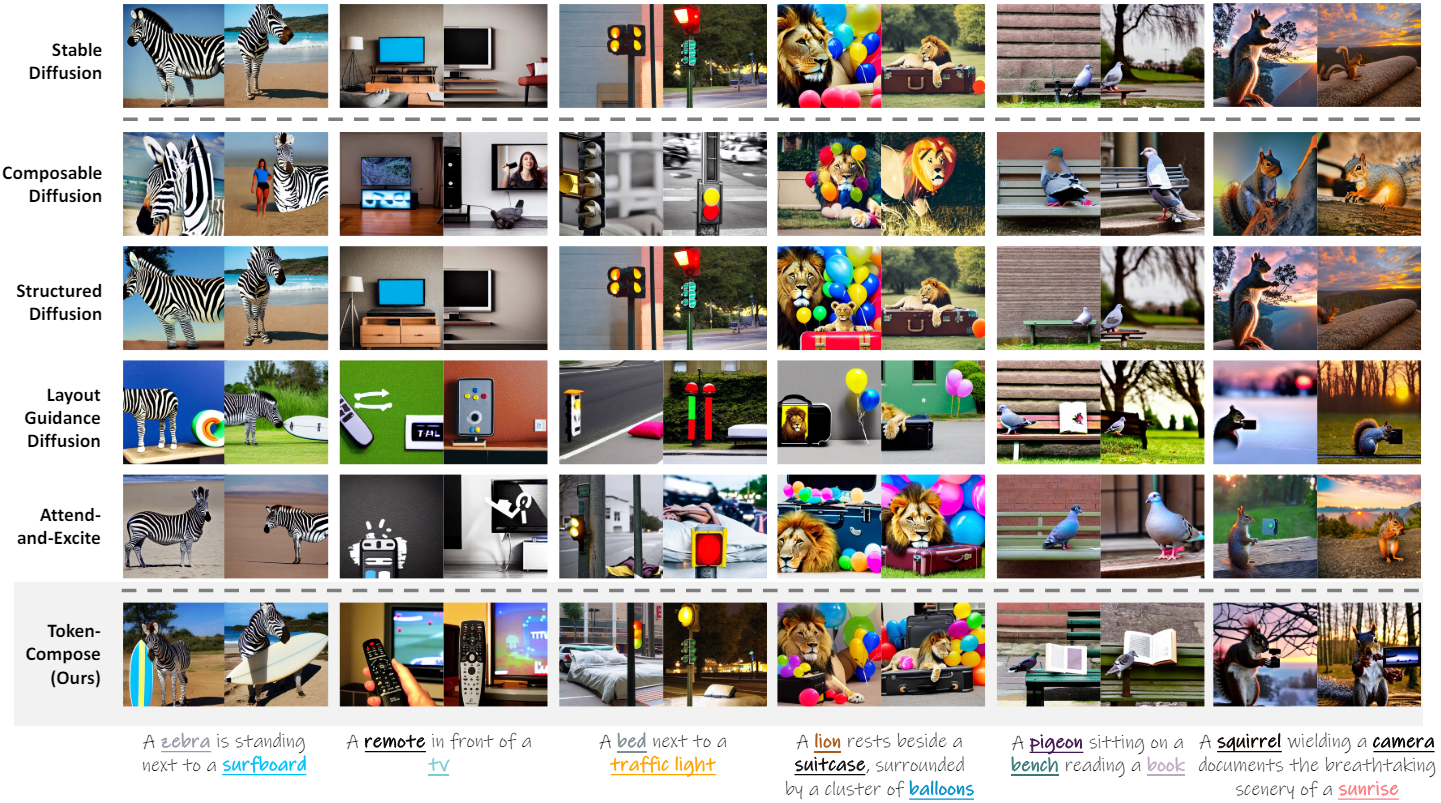
1. Main Results
다음은 다른 방법들과 성능을 비교한 결과이다.

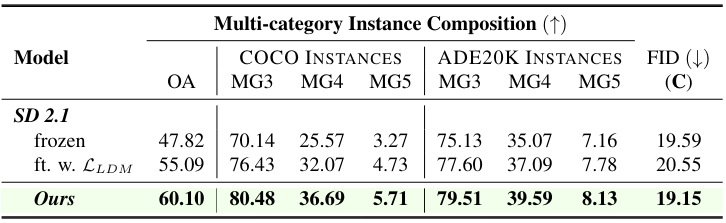
2. Generalization
다음은 모델 일반화 능력을 비교한 표이다.
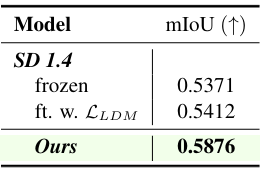
3. Knowledge Transfer
다음은 segmentation model로부터의 knowledge transfer
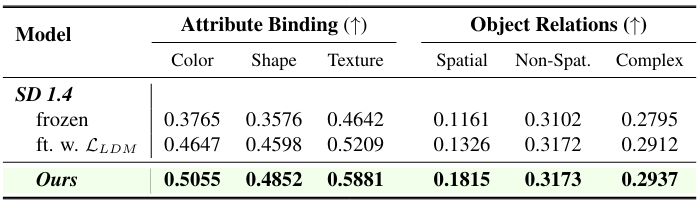
4. Downstream Metrics
다음은 downstream metric에 대한 성능 개선을 보여주는 표이다.
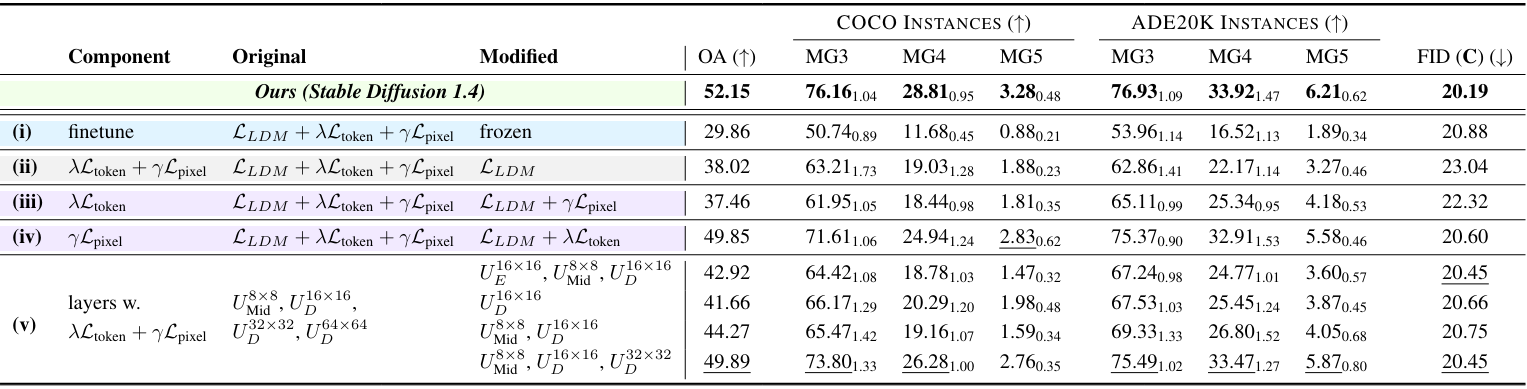
Ablations
다음은 ablation 결과이다.